Build enterprise gen AI apps with Google Cloud databases
Sean Rhee
Product Management, Google Cloud
Trained on an enormous corpus of publicly available data from a broad range of topics, large language models (LLMs) are powerful in many ways but can be improved in other areas.
Due to the size of the training data, it can be resource-intensive to train them frequently. As a result, they may not have the most up-to-date information. Moreover, because they are trained on available data, anything behind a corporate firewall is unknown to them. Ask an LLM who won the latest sports game or what the premium is for your health insurance, and it will likely not know the answer. These limitations may be fine for general knowledge questions, but enterprises are looking to leverage LLMs to create generative AI apps that offer high accuracy, can access real-time information, and support complex conversational experiences.
An increasingly popular approach to this problem is to “ground” LLMs by utilizing a technique called Retrieval Augmented Generation (RAG). This opens up new opportunities for enterprises to build gen AI apps that can leverage fresh or proprietary data by enriching LLM prompts to deliver relevant and accurate information. This is especially crucial for companies and industries that are bound by regulations on sensitive information.
The RAG approach
Let’s take a look at how RAG works, using a customer service chatbot example that can answer a wide range of questions including availability, pricing, and return policies. If you asked a typical LLM a generic question such as “what are some popular toys for kids under 5 years old?” it would likely be able to respond with an answer — but since the LLM has no idea about current inventory in stores, the answer is not going to be relevant for shoppers. To make the customer support chatbot use the latest data and policies for the answers, the RAG approach may prove to be effective.
Composed of a pre-step and four steps, this simplified RAG example flows through the process of how an app can provide grounded answers by utilizing the similarity search feature of a database that supports vector indexing.
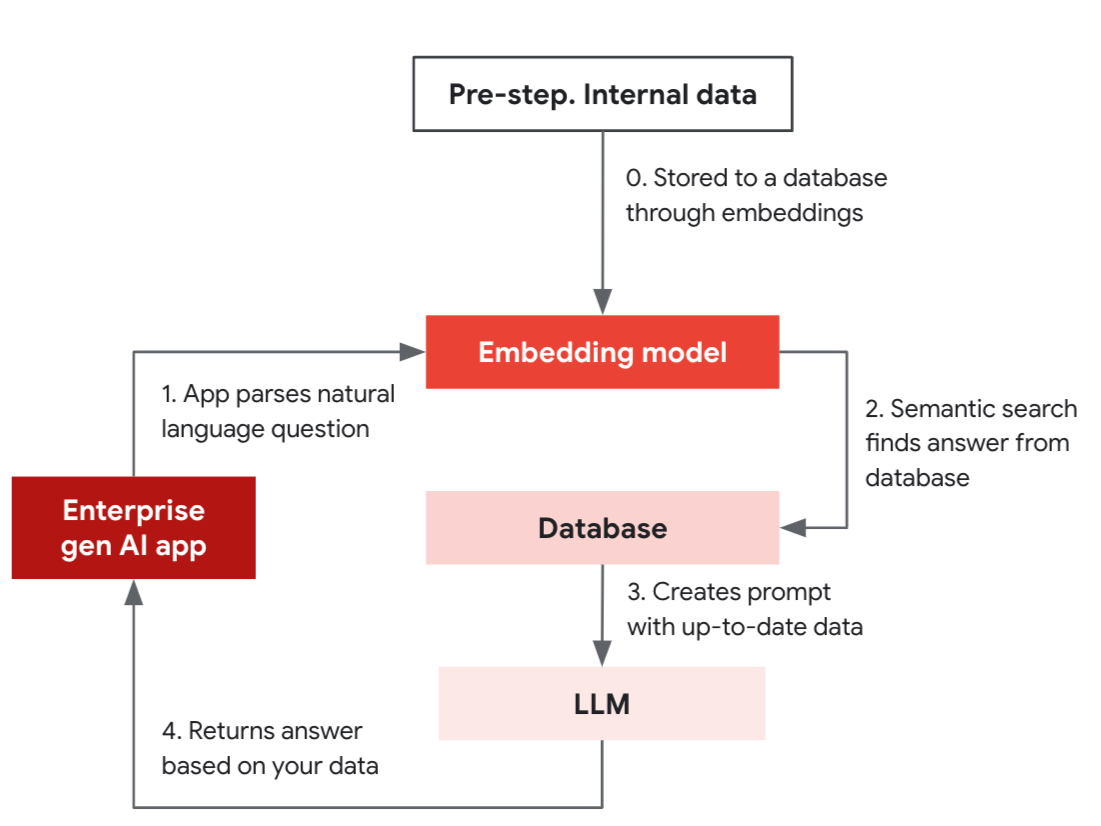
Pre-step: Internal data is stored in a database through the embedding model.
- Gen AI app uses the embedding model to convert a natural language question (“Do you have product X with features A, B, C?”) to a vector.
- Embedding model is used to convert the question into a vector and make a semantic search on the database.
- Database returns the data to be used as part of the prompt for the LLM.
- LLM constructs an accurate answer based on the data.
LLMs and databases work together to provide real-time results. In the initial setup, you will store your internal data such as product descriptions through an embedding model into your operational database as a vector. This allows your app to search and provide fresh, accurate results based on your data. Once this is set up, your app can now answer questions by using a similarity search from the database, which then combines the prompt for the LLM to provide relevant answers.
Embeddings let you filter data based on similarity using approximate nearest neighbor predicates. These types of queries enable experiences like product recommendations, which allows you to search for products that are similar to those that they have previously interacted with. As such, they make LLMs more powerful when used to construct prompts. This is because LLMs themselves have input size limits and no concept of state, so it is not always possible to provide the full context within the prompt. Therefore, embeddings allow us to search through large contexts such as databases, documentation, and chat histories — enabling the capability to simulate long-term memory and understand business-specific knowledge.
Vector databases
A key component of the RAG approach is the use of vector embeddings. Google Cloud provides a few options to store them. Vertex AI Vector Search is a purpose-built tool for storing and retrieving vectors at high volume and low latency. If you’re familiar with PostgreSQL, the pgvector extension provides an easy way to add vector queries in the database to support gen AI applications. Cloud SQL and AlloyDB support pgvector, with AlloyDB AI supporting up to 4x larger vector sizes and up to 10x faster performance compared to standard PostgreSQL when using the IVFFlat index mode.
Building an enterprise gen AI app might seem difficult, but by utilizing open source-compatible tools such as LangChain and leveraging the resources of Google Cloud, you can easily start your journey with the concepts and tools we described in this post. To learn more about pgvector in Cloud SQL and AlloyDB, head to this blog.


