Unlock personalized web experiences: Enhancing user context with Vertex AI embeddings
Shuhei Kondo
Data Science Engineer, PLAID, Inc.
Miki Katsuragi
AI Consultant, Google Cloud Japan
In our fast-paced digital world, grasping user context is crucial for platforms like KARTE by PLAID, Inc., which offers real-time analytics on user behaviors on websites and applications to enhance the customer experience. Recently, PLAID and Google Cloud embarked on a project to leverage generative AI, including large language models (LLMs) and embedding techniques on Vertex AI, to improve KARTE's customer support. Embeddings help KARTE better understand user intent, so that KARTE’s customer support feature can then provide relevant recommendations to answer customer queries faster and boost customer satisfaction.
Capturing user intent with pre-trained embeddings
Our project aims to train a model that recommends appropriate help content by leveraging embeddings on Vertex AI. This recommendation system operates on two key data types: Query and Corpus, focusing on capturing user intent from the Query to match against a Corpus of recommendations.
In practice, when users engage with web service content via KARTE and seek assistance on the KARTE help page, they often have trouble finding the right content. Our model interprets users' web event logs as queries, matching them with helpful content that addresses their challenges within the context. To design our recommendations, we utilized KARTE web logs, content from KARTE help pages, and KARTE's management screen. We designed recommendations using embeddings using the following flow:
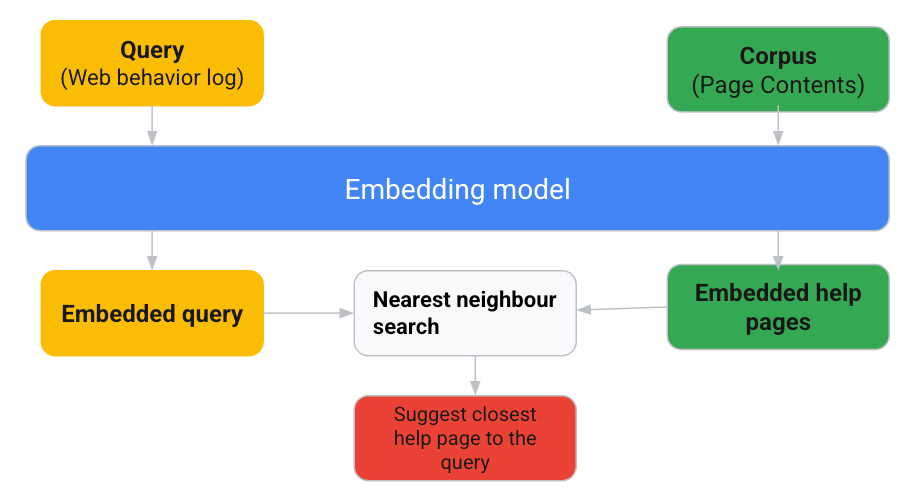
The Query component is derived from user interaction data, notably the titles of visited pages, reflecting users' recent interests and needs. This methodology extends to creating text prompts based on page titles to enhance the model's understanding of user intent. In addition to simply using the title of the page visited, we also created text as a prompt like the one below:
We also created the following four types of prompts to verify performance with various variations:
-
Prompt1: contains all user behavior in the current session (until the visited help page)
-
Prompt2: not only contains the user behavior in the session, but also the 50 most frequent pages visited in the past 30 days
-
Prompt3: similar to prompt 2 but only top 5 pages
-
Prompt4: this is to test with very little information — only the last 3 pages encountered in the current session
By transforming both the user's text (Query) and website content (Corpus) into embeddings, we capture the essence of user intent for semantic analysis. This process allows for meaningful comparisons between the Query and Corpus embeddings, ensuring recommendations are both relevant and aligned with the user's contextual needs.
Creating a benchmark with pre-trained embeddings
Benchmarking with pre-trained embeddings is key to evaluating our model’s performance improvements. We started by testing the 'textembedding-gecko-multilingual@latest' model as our benchmark. To measure performance, we used the Normalized Discounted Cumulative Gain (NDCG) metric to assess search and recommendation system effectiveness. NDCG considers the relevance of each item, discounting scores based on their list position to reflect decreasing importance further down the list, emphasizing the value of highly relevant items at the top.
The NDCG results from prompts 1 to 4 are as followed, using the pre-trained embeddings:
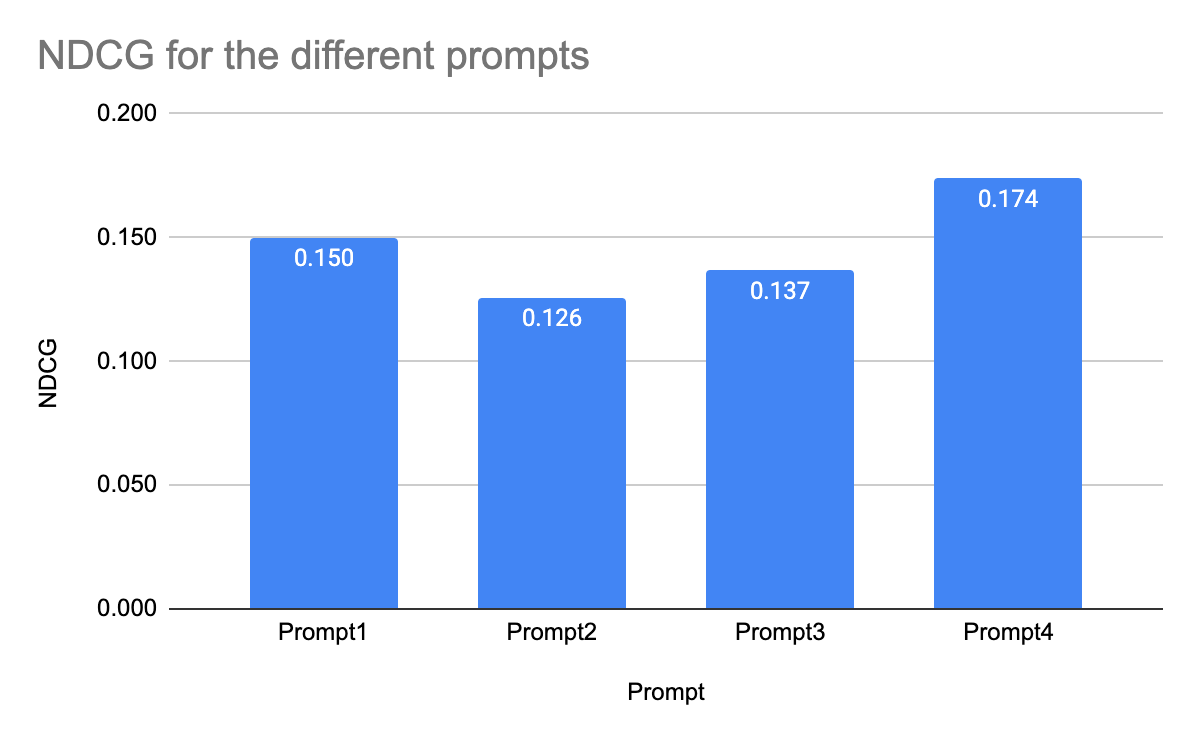
For pre-trained embeddings, simpler prompts yield higher NDCG scores. The simplest prompt, which includes the last three pages visited, scores highest, while the most complex prompt scores lowest. This suggests pre-trained embeddings perform better with concise information and struggle with complex prompts. Future steps include testing with tuned embeddings to see if this trend persists.
Improving performance with tuned embeddings
Next, we tuned the embeddings model and compared its performance with the pretrained model. We tuned the embeddings with the following steps:
-
Prepare the tuning dataset.
-
Upload the model tuning dataset to a Cloud Storage bucket.
-
Create a model tuning job.
-
Deploy the tuned model to a Vertex AI endpoint.
Dataset format for tuning an embeddings model
To tune an embeddings model, the training dataset in Cloud Storage needs four files: query, corpus, and training labels. Training labels match subsets of queries to the corpus, with query and corpus IDs linking to their respective files. Scores, which are non-negative integers, indicate relevance; higher scores suggest greater relevance, with a default score of 1 if omitted. The paths to these files are specified by parameters when initiating the tuning pipeline.
The files used for tuning looks as below:

Performance improvements from tuning embeddings
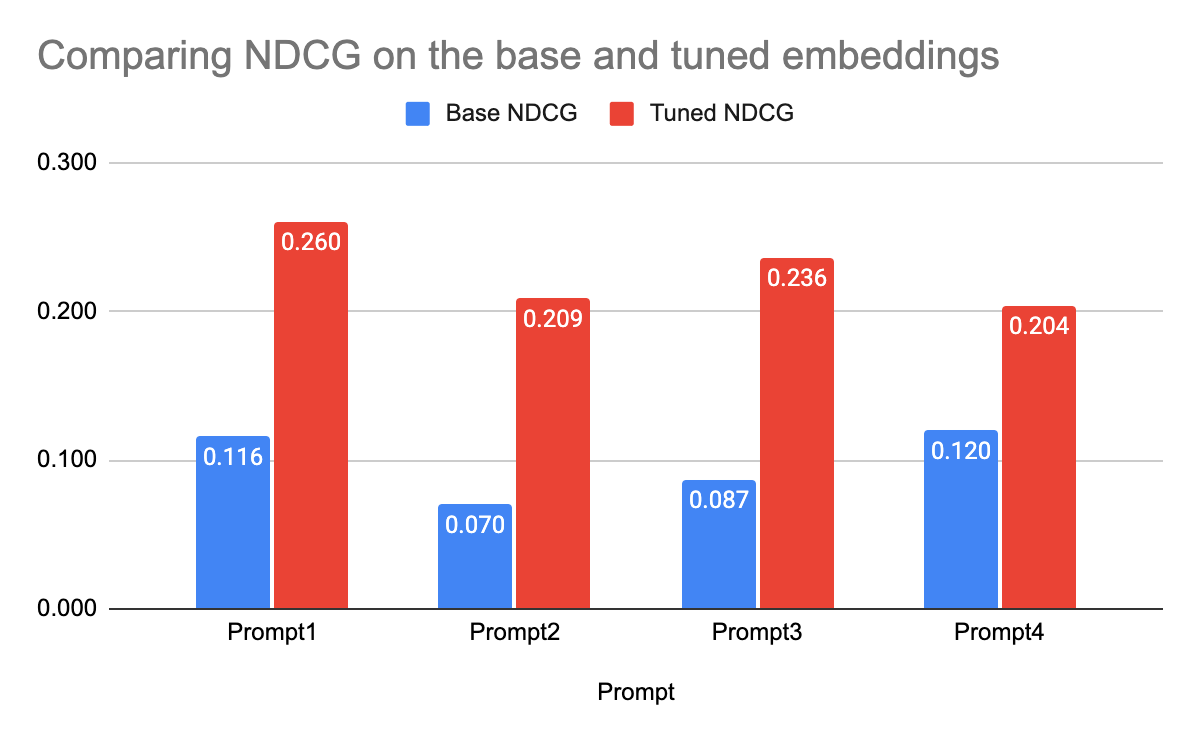
After creating four tuned embeddings models for each prompt, all showed significant NDCG improvements. Unlike with pre-trained embeddings where the simplest prompt (prompt 4) scored highest, it now scores lowest, indicating that tuned models use additional information from other prompts effectively. However, the most informative prompt (prompt 2) still had the second lowest NDCG, suggesting a need for balance in the amount of information provided in prompts when optimizing performance.
Key learnings and improvements as next steps
This project demonstrates the value of using embedding-based models on Vertex AI for web content recommendations that match user interests and behaviors, with recent actions playing a vital role in generating relevant suggestions. By tuning our embeddings model, we've seen significant improvements in NDCG scores, showcasing the method's effectiveness. But despite our progress, opportunities for further refinement exist, such as integrating expert manual labeling and evaluations to enhance recommendation accuracy and align with user needs. Future efforts will focus on combining human insights with algorithmic accuracy to improve recommendation systems in the dynamic digital environment.
To learn more about embeddings and Vertex AI, check out the documentation below to try out its capabilities:



