Migrate your custom ML models to Google Cloud in 3 steps
Stefan Hosein
AI Engineer
Michael Hu
AI Engineer
Building end-to-end pipelines is becoming more important as many businesses realize that having a machine learning model is only one small step towards getting their ML-driven application into production.
Google Cloud offers a tool for training and deploying models at scale, Cloud AI Platform, which integrates with multiple orchestration tools like TensorFlow Extended and KubeFlow Pipelines (KFP). However, it is often the case that businesses have models which they have built in their own ecosystem using frameworks like scikit-learn and xgboost, and porting these models to the cloud can be complicated and time consuming.
Even for experienced ML practitioners on Google Cloud Platform (GCP), migrating a scikit-learn model (or equivalent) to AI Platform can take a long time due to all the boilerplate that is involved. ML Pipeline Generator is a tool that allows users to easily deploy existing ML models on GCP, where they can then benefit from serverless model training and deployment and a faster time to market for their solutions.
This blog will provide an overview of how this solution works and the expected user journey, and instructions for orchestrating a TensorFlow training job on AI Platform.
Overview
ML Pipeline Generator allows users with pre-built scikit-learn, xgboost, and TensorFlow models to quickly generate and run an end-to-end ML pipeline on GCP using their own code and data.
In order to do this, users must fill in a config file describing their code's metadata. The library takes this config file and generates all the necessary boilerplate for the user to train and deploy their model on the cloud in an orchestrated fashion using a templating engine. In addition, users who train TensorFlow models can use the Explainable AI feature to better understand their model.
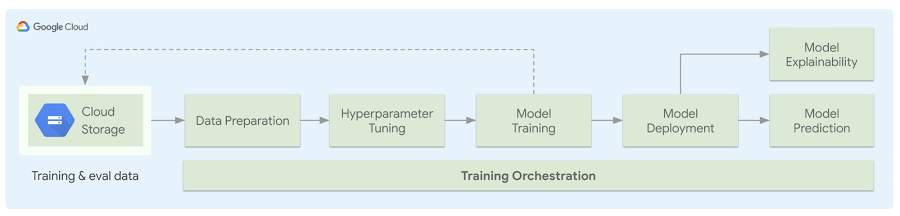
In the figure below, we highlight the architecture of the generated pipeline. The user will bring their own data, define how they perform data preprocessing, and add their ML model file. Once the user fills out the config file, they use a simple python API to generate self-contained boilerplate code which takes care of any preprocessing specified, uploads their data to Google Cloud Storage (GCS), and launches a training job with hyperparameter tuning. Once this is completed, the model is then deployed to be served and, depending on the model type, model explainability is performed. This whole process can be orchestrated using Kubeflow Pipelines.
Step-by-step instructions
We’ll demonstrate how you can build an end-to-end Kubeflow Pipeline for training and serving a model, given the model config parameters and the model code. We will build a pipeline to train a shallow TensorFlow model on the Census Income Data Set. The model will be trained on Cloud AI Platform and can be monitored in the Kubeflow UI.
Before you begin
To ensure that you are able to fully use the solution, you need to set up a few items on GCP:
1. You’ll need a Google Cloud project to run this demo. We recommend creating a new project and ensure the following APIs are enabled for the project:Compute Engine
AI Platform Training and Prediction
Cloud Storage
2. Install the Google Cloud SDK so that you can access required GCP services via the command line. Once the SDK is installed, set up application default credentials with the project ID of the project you created above.
3. If you’re looking to deploy your ML model on Kubeflow Pipelines using this solution, create a new KFP instance on AI Platform Pipelines in your project. Note down the instance’s hostname (Dashboard URL of the form [vm-hash]-dot-[zone].pipelines.googleusercontent.com).
4. Lastly, create a bucket so that data and the models can be stored on GCS. Note down the bucket ID.
Step 1: Setting up the environment
Clone the github repo for the demo code, and create a Python virtual environment.
Install the ml-pipeline-gen package.
The following files are of interest to us to be able to get our model up and running:
1. The examples/ directory contains sample code for sklearn, Tensorflow and XGBoost models. We will use the examples/kfp/model/tf_model.py to deploy a TensorFlow model on Kubeflow Pipelines. However, if you are using your own model you can modify the tf_model.py file with your model code.
2. The examples/kfp/model/census_preprocess.py downloads the Census Income dataset and preprocesses it for the model. For your custom model, you can modify the preprocessing script as required.
3. The tool relies on a config.yaml file for the required metadata to build artifacts for the pipeline. Open the examples/kfp/config.yaml.example template file to see the sample metadata parameters and you can find the detailed schema here.
4. If you’re looking to use Cloud AI Platform’s hyperparameter tuning feature, you can include the parameters in a hptune_config.yaml file and add its path in config.yaml. You can check out the schema for hptune_config.yaml here.
Step 2: Setting up required parameters
1. Make a copy of the kfp/ example directory
2. Create a config.yaml file using the config.yaml.example template and update the following parameters with the project ID, bucket ID, the KFP hostname you noted down earlier, and a model name.
Step 3: Building the pipeline and training the model
With the config parameters in place, we’re ready to generate modules that will build the pipeline to train the TensorFlow model. Run the demo.py file.
The first time you run the Kubeflow Pipelines demo, the tool provisions Workload Identity for the GKE cluster which modifies the dashboard URL. To deploy your model, simply update the URL in config.yaml and run the demo again.
The demo.py script downloads the census dataset from a public Cloud Storage bucket, prepares the datasets for training and evaluation as per examples/kfp/model/census_preprocess.py, uploads the dataset to the Cloud Storage URLs specified in config.yaml, builds the pipeline graph for training and uploads the graph on the Kubeflow Pipelines application instance as an experiment.
Once the graph has been submitted for a run, you can monitor the progress of the run in the Kubeflow Pipelines UI. Open the Cloud AI Platform Pipelines page and open the Dashboard for your Kubeflow Pipelines cluster.
Note:
If you would like to use the Scikit-learn or XGBoost examples, you can follow the same steps above, but modify the examples/sklearn/config.yaml with similar changes as above without the additional step of creating a Kubeflow Pipelines instance. For more details, refer to the instructions in the public repo or follow our end-to-end tutorial written in a Jupyter notebook.
Conclusion
In this post we showed you how to migrate your custom ML model for training and deployment to Google Cloud in three easy steps. Most of the heavy-lifting is done by the solution, where the user simply needs to bring their data, model definition and state how they would like the training and serving to be handled.
We went through one example in detail and the public repository includes examples for other supported frameworks. We invite you to utilize the tool and start realizing one of the many benefits of Cloud for your Machine Learning workloads. For more details, check out the public repo. To learn more about Kubeflow Pipelines and its features, check out this session from Google Cloud Next ‘19.
Acknowledgements
This work would not have been possible without the hard work of the following people (in alphabetical order of last name): Chanchal Chatterjee, Stefan Hosein, Michael Hu, Ashok Patel and Vaibhav Singh.