Supervised Fine Tuning for Gemini: A best practices guide
Erwin Huizenga
AI engineering and evangelism manager
Bethany Wang
Staff Software Engineer and Manager, Google Cloud
Foundation models such as Gemini have revolutionized how we work, but sometimes they need guidance to excel at specific business tasks. Perhaps their answers are too long, or their summaries miss the mark. That's where supervised fine-tuning (SFT) comes in. When done right, it unlocks incredible precision to tailor Gemini for specialized tasks, domains, and stylistic nuances.
In an earlier blog, we covered when to embrace SFT and how it compares to other methods for optimizing your model’s output. In this blog, we’ll go deeper into how developers can streamline their SFT process, including:
-
Selecting the optimal model version
-
Crafting a high quality dataset
-
Best practices to evaluate the models, including tools to diagnose and overcome problems.
1. Establish a baseline and select your model
First, evaluate your foundation model on a representative dataset before fine-tuning to quantify improvements. This helps you understand its initial capabilities and identify areas for targeted improvement. Here are three key things to analyze:
-
Initial performance: Assess how the model performs without any training (zero-shot) and potentially with a few examples (few-shot).
-
Metrics: Select evaluation metrics aligned with your specific task, like exact match, BLEU or ROUGE.
-
Data: Ensure your evaluation dataset is diverse and representative of the real-world data the model will encounter.
Analyzing these baseline results, especially where the model struggles, is crucial for defining an effective fine-tuning strategy. When fine-tuning Gemini, you have a couple models to choose from:
-
Gemini 1.5 Pro: Google’s best model for general performance.
-
Gemini 1.5 Flash: Google’s model that is designed for cost-performance and low latency
Choosing the right model involves two key considerations:
-
Align the model with your use case: Before using SFT start with the model that most easily achieves your desired functionality. If your application requires high accuracy and complex reasoning, begin with Gemini Pro. If this works, then you can begin to look at cost. For example, you could try SFT on Flash, so that you have better latency and cheaper inference.
-
Efficiently improving the model with your data: Before fine-tuning a larger model like Gemini Pro, it's often beneficial to test your tuning data on a smaller, less expensive model like Gemini Flash first. This allows you to verify that your data is actually improving the model's performance. If the performance is not good enough you can always switch to a larger model. If your tuning data effectively improves the smaller model’s accuracy, then it indicates that your data has good quality, and there is a good chance that tuning the larger model with this data will be effective, too.
Consider your data
SFT isn't just about throwing labeled data at a model; it's a nuanced process where the right choices are crucial. To adapt a foundation model for specific tasks, we fine-tune it with a labeled dataset. This dataset contains inputs (like an earnings report) and their desired outputs (like a summary).
Machine learning thrives on data. The success of your supervised fine-tuning depends significantly on the quality of your tuning data. Here are some essential guidelines to follow.
Quality vs quantity
Quality vs. quantity in your training data is crucial. Vertex AI leverages Low-Rank Adaptation (LoRA) for efficient fine-tuning, freezing the original model weights and injecting trainable matrices to adjust model behavior effectively with a small number of trainable parameters. This means faster fine-tuning, fewer resources, and less reliance on massive datasets.
Focus on high-quality examples that are:
-
Relevant: Closely aligned with your specific fine-tuning task.
-
Diverse: Covering a wide range of potential inputs and scenarios.
-
Accurate: Featuring correct labels and outputs.
While more data can improve a model, it often needs fewer training epochs and at some point you might have diminishing returns. It's not worth tuning on the same cluster over and over again. A smaller, refined and representative dataset often outperforms a large, noisy one. Small datasets have the risk of overfitting, so you may want to control your number of epochs. You can start with around 100 examples to validate the effectiveness of tuning. Then scale up to cover more corner cases or categories.
Data pre-processing
Pre-processing is a critical step in preparing data for supervised fine-tuning of large language models (LLMs). Research has shown that one of the most crucial pre-processing steps is deduplication. which involves identifying and removing duplicate data points. Duplicate examples in training data can lead to several issues: memorization, which hinders generalization; and inefficient training, as the model redundantly learns from similar clusters. Duplicate or near-duplicate examples between training and validation/test sets causes data leakage, artificially inflating performance.
For deduplication, leverage techniques like exact and fuzzy matching, and clustering. Tools like ExactSubstr deduplication can efficiently handle larger datasets. Furthermore, explore data augmentation to enhance data diversity and model robustness.
Be aware that pre-processing can also help with evaluating the performance of your fine-tuned model. For example you might want to deal with letter cases, remove extra whitespace and deal with punctuation.
2. Add instructions to your dataset
Including instructions in your fine-tuning dataset helps boost the performance. The model learns to condition its output on the given instructions, improving its ability to perform the desired task and generalize to similar, unseen instructions. Reducing the need for lengthy and complex prompts during inference. There are two primary methods: system instructions and text prompts, both are optional but can improve the performance.
System instructions provide global directives, shaping the overall response style. For example, "Answer in JSON format" enforces structured outputs, while "You are an expert in bioinformatics" sets the response domain. ` .
Instance-level instructions offer example-specific guidance embedded within the model input. For instance, "Summarize the following research paper, focusing on the methodology and key findings:"directs the model to extract specific information.
Experimenting with different instruction styles, informed by resources like the Gemini prompting strategies, is important. You can experiment by prompting the Gemini model before adding the instruction to the dataset. Adding few-shot examples to your dataset will not give additional benefit. Crucially, ensure the prompts and instructions used in your fine-tuning dataset closely resemble those you plan to use in production. This alignment is vital for optimal performance.
Training-serving skew
A critical factor influencing fine-tuning effectiveness is the alignment between your tuning data and production data. Divergence in aspects like format, context, or example distribution can significantly degrade model performance. For instance, if your tuning data consists of formal language examples and your production data includes informal social media text, the model may struggle with sentiment analysis. To prevent this, carefully analyze your training and production data. Techniques like data augmentation and domain adaptation can further bridge the gap and enhance the model's generalization capabilities in production.
Focus on complex examples
When fine-tuning, it's tempting to throw all your data at the model and hope for the best. However, a more strategic approach focuses on examples that the base model finds difficult.
Instead, identify the specific areas where the model struggles. By curating a dataset of these challenging examples, you can achieve more significant improvements with less data. This targeted approach not only boosts performance but also makes your fine-tuning process more efficient. During the benchmarking process, analyze the model's performance on a diverse dataset. Identify examples where the model struggles with specific tasks, formats, or reasoning abilities. Then add these examples to your training dataset and you might want to find extra examples and add those to your evaluation dataset to prevent leakage.
The importance of a validation dataset
Always incorporate a well-structured validation dataset into your fine-tuning process. This separate set of labeled data serves as an independent benchmark to evaluate your model's performance during training, helping you to identify overfitting and choose the epochs to stop training at, and ensuring the model generalizes well to unseen data. The validation dataset should be representative of the real-world data that will be used during inference.
Data formatting
In supervised fine-tuning, the model learns from a labeled dataset of input-output pairs. To use SFT for Gemini your data needs to be in a specific format in a JSONL file. Adding instructions to your dataset helps guide the model during the fine-tuning process. You can add a systemInstruction and additional instructions to the contents fields, each containing role and parts to represent the conversation flow and content. You do this for each of the lines (sample) in your JSON file. For instance, a systemInstruction might specify the persona of the LLM, while the contents would include the user query and the desired model response. A well-structured dataset in the correct format is crucial for effective knowledge transfer and performance improvement during fine-tuning. Here's an example (datapoint) of the required format for your dataset:
3. Hyperparameters and performance
When you start with fine-tuning it’s important to choose the right hyperparameters. Hyperparameters are the external configuration settings that govern the training process of a large language model which ultimately determine the model's performance on a given task. When fine-tuning Gemini you can follow the guidance below to set the hyperparameters (epochs, learning rate multiplier and adapter size):
Gemini 1.5 Pro
-
Text fine-tuning: with a dataset size of <1000 examples and average context length <500, we recommend setting epochs = 20, learning rate multiplier = 10, adapter size = 4. With a dataset size >= 1000 examples or average context length >= 500, we recommend epochs = 10, learning rate multiplier = default or 5, adapter size = 4.
-
Image fine-tuning: with a dataset size of ~1000 examples start with epochs = 15, learning rate multiplier = 5 and adapter size = 4. Increase the number of epochs when you have <1000 samples and decrease when you have >1000 examples.
-
Audio fine-tuning: we recommend setting epochs = 20, learning rate = 1 and adapter size = 4.
Gemini 1.5 Flash
-
Text fine-tuning: with a dataset size of <1000 examples and average context length <500, we recommend setting epochs = default, learning rate multiplier = 10 and adapter size = 4. With a dataset size >= 1000 examples or average context length >= 500, we recommend epochs = default, learning rate multiplier = default and adapter size = 8.
-
Image fine-tuning: with a dataset size of <1000 examples and average context length <500, we recommend setting epochs >=15 (increase when you have less examples), learning rate multiplier = 5 and adapter size = 16. With a dataset size of >= 1000 examples or average context length >= 500, we recommend setting epochs <=15 (decrease when you have me examples), learning rate multiplier = default and adapter size = 4.
-
Audio fine-tuning: we recommend setting epochs = 20, learning rate = 1 and adapter size = 4.
Audio use cases like Automated Speech Recognition (ASR) use cases might need a higher epochs setting to reach optimal results. Start with the settings mentioned above and based on your evaluation metrics you can increase the number of epochs.
After your initial run, iterate by adjusting the hyperparameters and closely monitoring key training and evaluation metrics. key training metrics. Two primary metrics to monitor during fine-tuning are:
-
Total loss measures the difference between predicted and actual values. A decreasing training loss indicates the model is learning. Critically, observe the validation loss as well. A significantly higher validation loss than training loss suggests overfitting.
-
Fraction of correct next step predictions measures the model's accuracy in predicting the next item in a sequence. This metric should increase over time, reflecting the model's growing accuracy in sequential prediction.
Monitor these metrics for both your training and validation datasets to ensure optimal performance depending on the task, consider other relevant metrics. To monitor your fine-tuning job, use the Google Cloud Console or Tensorboard. An “ideal” scenario for the metrics would be something like this:
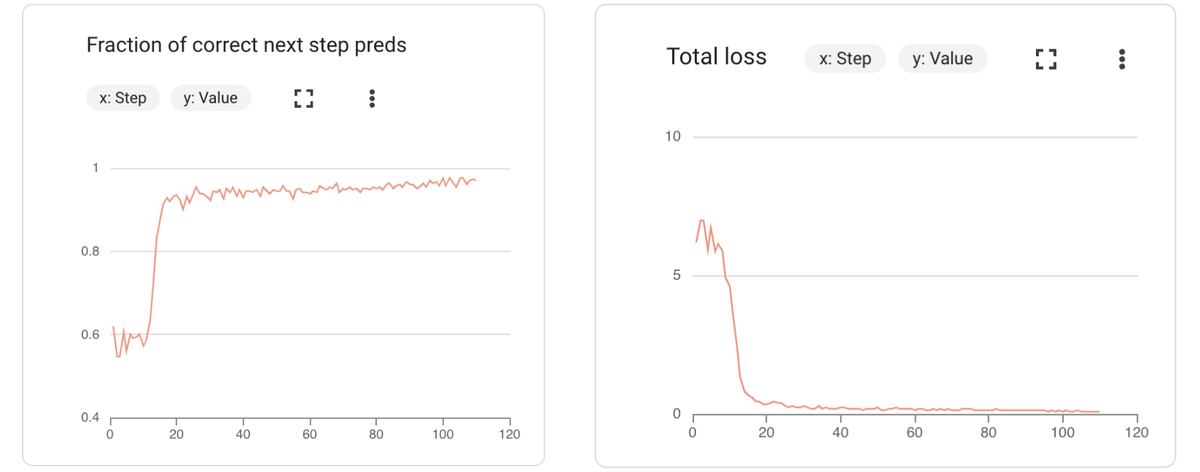
Remember: These are just starting points. Experimentation is key to finding the optimal hyperparameters for your specific fine-tuning task. You might also want to follow some of the best steps below based on the performance of your fine-tuning experiment.
Suboptimal performance
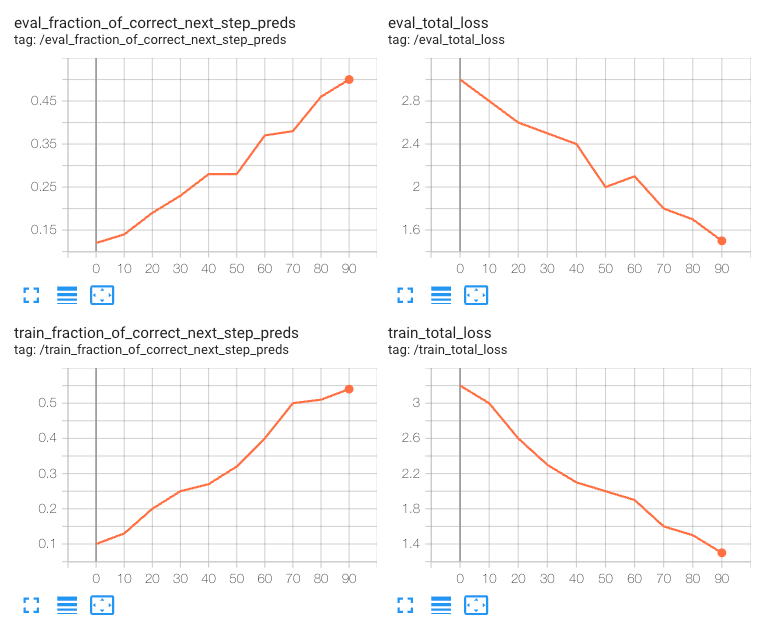
How to spot this: Training loss and validation loss decrease as training progresses, but the validation loss does not converge or reach a minimum.
Possible causes: The training dataset may be too small or lack sufficient diversity to represent the real-world scenarios the model will encounter.
How to alleviate: Increase the number of epochs or the learning rate multiplier to speed up the training. If that doesn’t work you can gather more data.
Overfitting
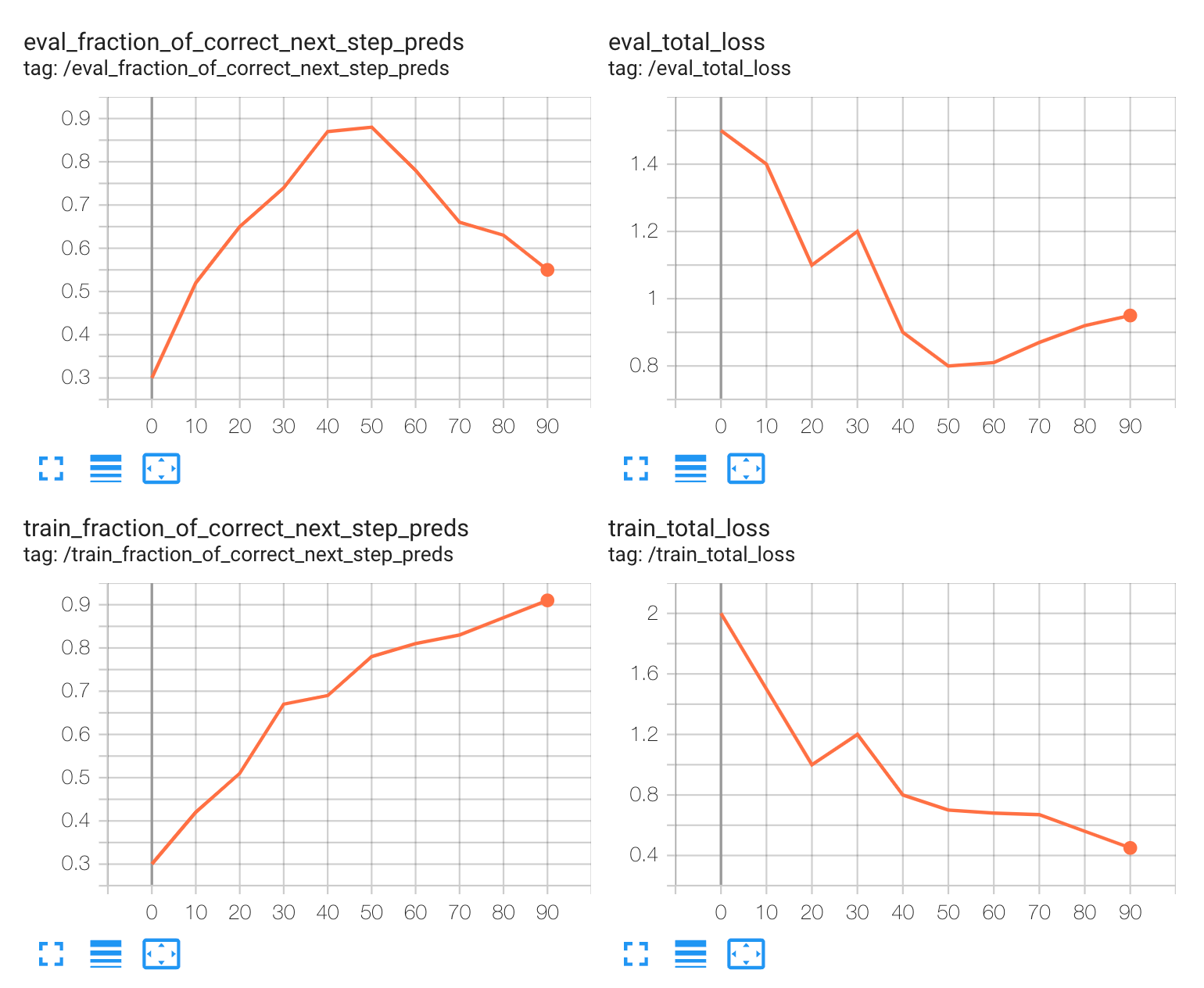
How to spot this: During training, the training loss decreases consistently, but the validation loss decreases initially and then starts to increase. This divergence indicates that the model is learning the training data too well and is failing to generalize to new data.
Cause: The model has too much capacity (e.g., too many layers or parameters) relative to the size and complexity of the training data.
How to alleviate: Decrease the number of epochs to the point where validation loss reaches the minimum. Or Increase the effective size and diversity of the training data.
Potential data issues
How to spot this: The initial loss of training data is very high (>10) indicates that the model’s prediction is very far from the label.
Cause: There could be issues with your training dataset. One typical example is that the input length exceeds the maximum context length, which leads to truncation.
How to alleviate: Double check your training dataset to make sure it follows the best practice from the previous section.
Evaluate your model
Evaluating the performance of fine-tuned language models is crucial for understanding its performance, checkpoint selection and hyperparameter optimization. Evaluation can be challenging for generative models, as their outputs are often open-ended and creative. To gain a holistic understanding of performance, it's best to combine different evaluation approaches, primarily utilizing a blend of auto-metrics and model-based evaluation, potentially calibrated with human evaluation.
Auto-metrics: These metrics provide quantitative measures by comparing the model's output to a ground truth. While they may not capture nuanced aspects like factuality, they remain valuable due to their:
-
Speed: Auto-metrics are computationally inexpensive and fast to calculate.
-
Objectivity: They offer consistent, objective measurements, enabling reliable progress tracking and model comparisons.
-
Interpretability: Metrics like accuracy, F1 score, or BLEU are widely understood and provide readily interpretable results.
It's crucial to select appropriate auto-metrics based on the task. For instance:
-
BLEU Score (translation and summarization): Measures n-gram overlap between generated and reference text, focusing on precision.
-
ROUGE (summarization): Evaluates n-gram overlap with an emphasis on recall.
Model-based metrics: These methods leverage a language model as a judge (Autorator) to assess the quality of generated output based on predefined criteria, aligning more closely with the task evaluation rubrics. For example, you might use model based evaluation to assess the factual accuracy or logical consistency of a response.
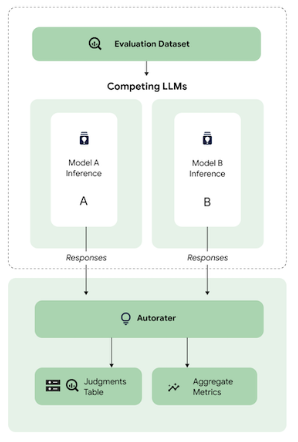
Human Evaluation: While human judgment remains the gold standard, its cost and scalability limitations make it less practical for continuous evaluation during fine-tuning. Instead, we can strategically use human evaluation to calibrate model-based evaluators (autoraters). This involves collecting a smaller but high-quality dataset of human judgments and training the autorater to mimic these judgments. We can then rely on the autorater during the tuning process and conduct a final round of validation with human raters to ensure the chosen checkpoint meets the desired quality standards.
What’s next?
Ready to get started? Dive into our Generative AI repository and explore notebooks like our how to use supervised fine tuning. Experience the transformative potential of SFT on Vertex AI, and tailor your AI applications for peak performance and customization.
Want to fine-tune a Gemini model? Head over to the Vertex AI documentation to see which ones you can customize.
If you want to learn more about Generative AI and fine-tuning please have a look at our 5-Day Gen AI Intensive Course.
A special thanks to May Hu, Yanhan Hou, Xi Xiong, Sahar Harati, Emily Xue and Mikhail Chrestkha from Google Cloud for their contributions.



