GenOps: the evolution of MLOps for gen AI
Sharmila Devi
AI Consultant, Google
Frederic Molina
ML Specialist, Google
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try nowAs organizations move to deploy Generative AI solutions at scale, they often face operational challenges. GenOps, or MLOps for Gen AI, addresses these challenges.
GenOps combines DevOps principles with ML workflows to deploy, monitor, and maintain Gen AI models in production. It ensures Gen AI systems are scalable, reliable, and continuously improving.
Why is MLOps challenging for Gen AI?
Gen AI models present unique challenges that make the traditional MLOps practices insufficient:
-
Scale: Billions of parameters require specialized infrastructure.
-
Compute: High resource demands for training and inference.
-
Safety: Need for robust safeguards against harmful content.
-
Rapid evolution: Constant updates to keep pace with new developments.
-
Unpredictability: Non-deterministic outputs complicate testing and validation.
In this blog, we'll explore how to adapt and extend MLOps principles to meet the unique demands of Gen AI.
Key capabilities of GenOps
Think of a Gen AI model as the tip of an iceberg. Generative AI systems are complex and contain numerous hidden interconnected elements. We’ve extended those elements in the below image from the original paper, Hidden Technical Debt in Machine Learning Systems.
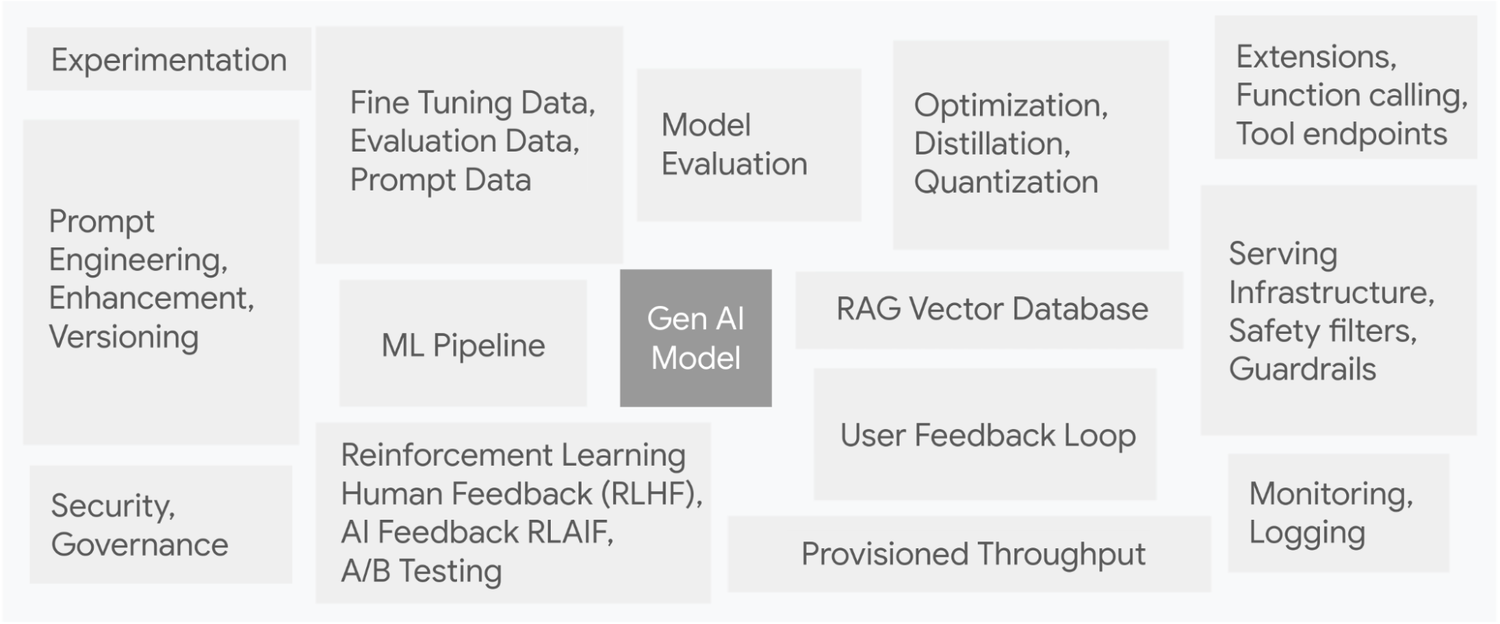
Hidden Technical Debt in Gen AI Systems
Below are the different elements in GenOps for pre-trained and fine-tuned models:
-
Gen AI experimentation and prototyping: Experiment and build prototypes using enterprise models like Gemini, Imagen and open-weight models like Gemma2, PaliGemma etc.
-
Prompt: Below are the various tasks involving prompts:
-
Prompt engineering: Design and refine prompts for GenAI models to generate desired outputs
-
Prompt versioning: Manage, track and control changes to prompts over time.
-
Prompt enhancement: Employ LLMs to generate an improved prompt that maximizes performance on a given task.
-
Evaluation: Evaluate the responses from the GenAI model for specific tasks using metrics or feedback
-
Optimization: Apply optimization techniques like quantization and distillation to make models more efficient for deployment.
-
Safety: Implement guardrails and filters. Models like Gemini have inbuilt Safety Filters to prevent harmful responses by the model.
-
Fine-tuning: Adapt pre-trained models to specific domains/tasks through additional tuning on specialized datasets.
-
Version control: Manage different versions of GenAI models, prompts and dataset versions.
-
Deployment: Serve GenAI models with scaling, containerization and integration.
-
Monitoring: Track model performance, output quality, latency and resource usage in real-time.
-
Security and governance: Protect models and data from unauthorized access or attacks and ensure compliance with regulations.
Now that we’ve seen the key components in GenOps, let’s take a look at the classic MLOps pipeline in VertexAI and see how it can be extended to GenOps. This MLOps pipeline automates the process of taking a ML model to deployment, incorporating continuous integration, continuous deployment and continuous training(CI/CD/CT).
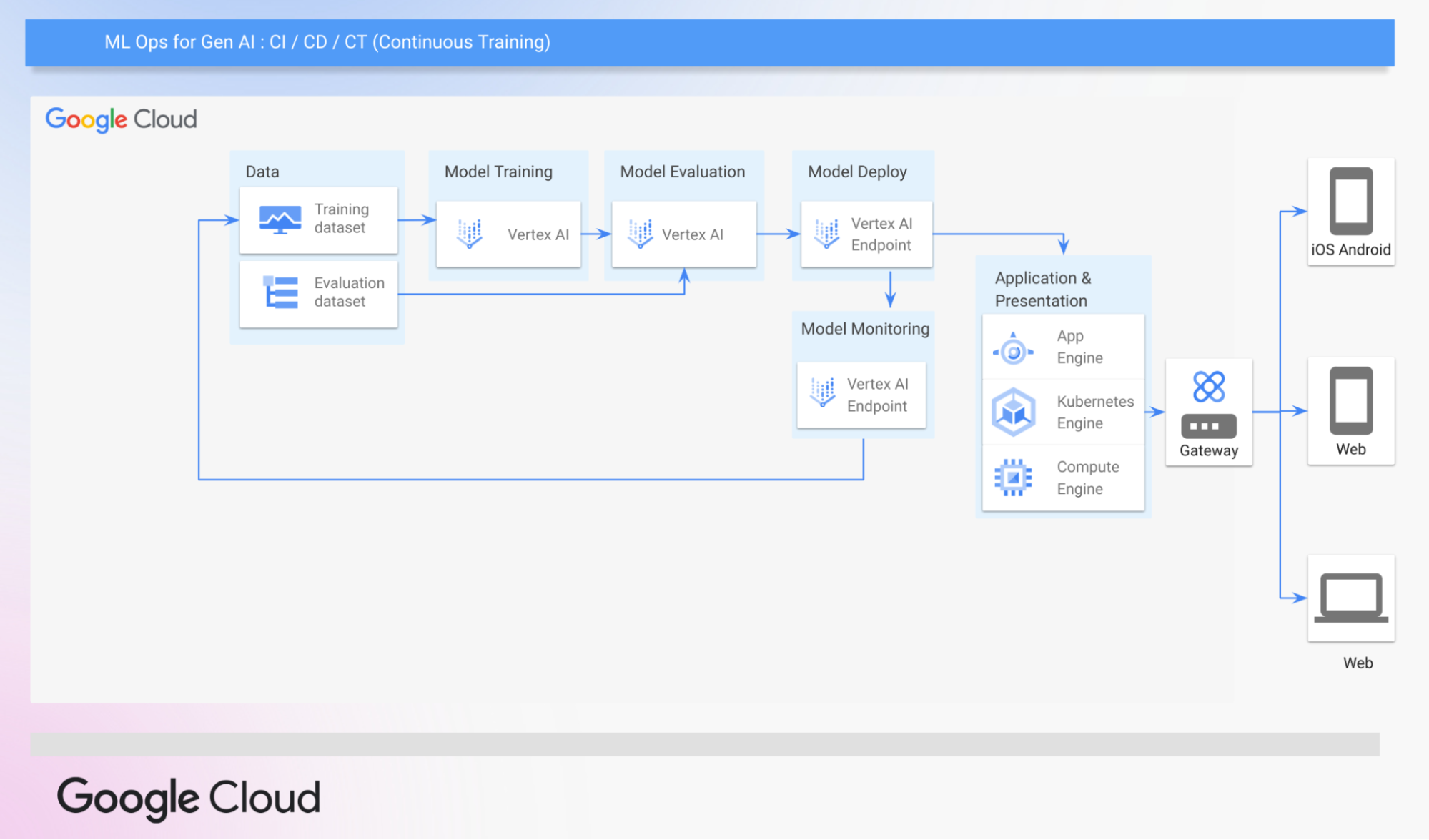
A Typical MLOps Pipeline in Google Cloud
Extend MLOps to support GenOps
Now let’s understand the key components of a robust GenOps pipeline on Google Cloud, from initial experimentation with powerful models across multiple modalities to the critical considerations of fine-tuning, safety and deployment. This blog focuses on leveraging pre-trained models that can be fine tuned.
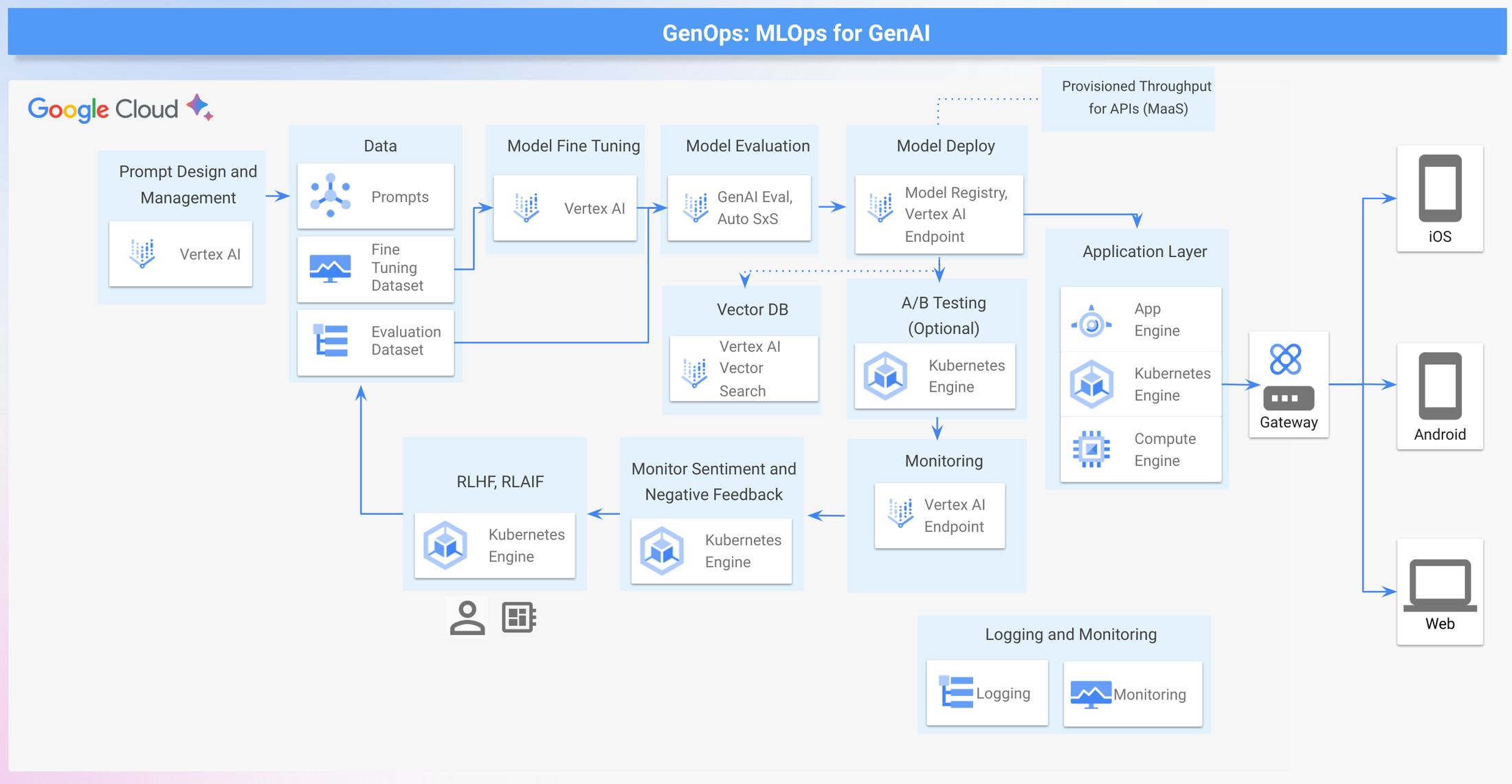
Sample architecture for GenOps
Let's explore how these key components of GenOps can be built in Google Cloud.
-
Data: The Generative AI journey starts with data.
-
Few shot examples: Few-shot prompts provide examples to guide the model's output format, phrasing, scope, and pattern.
-
Supervised fine-tuning dataset: This labeled dataset is used to fine-tune a pre-trained model to a specific task or domain.
-
Golden evaluation dataset: This is used to assess the performance of the model for a given task. This labeled dataset can be used for both manual and metric-based evaluation for that specific task.
2. Prompt management: Vertex AI Studio allows collaborative prompt creation, testing, and refinement. Teams can input text, select models, adjust parameters, and save finalized prompts within shared projects.
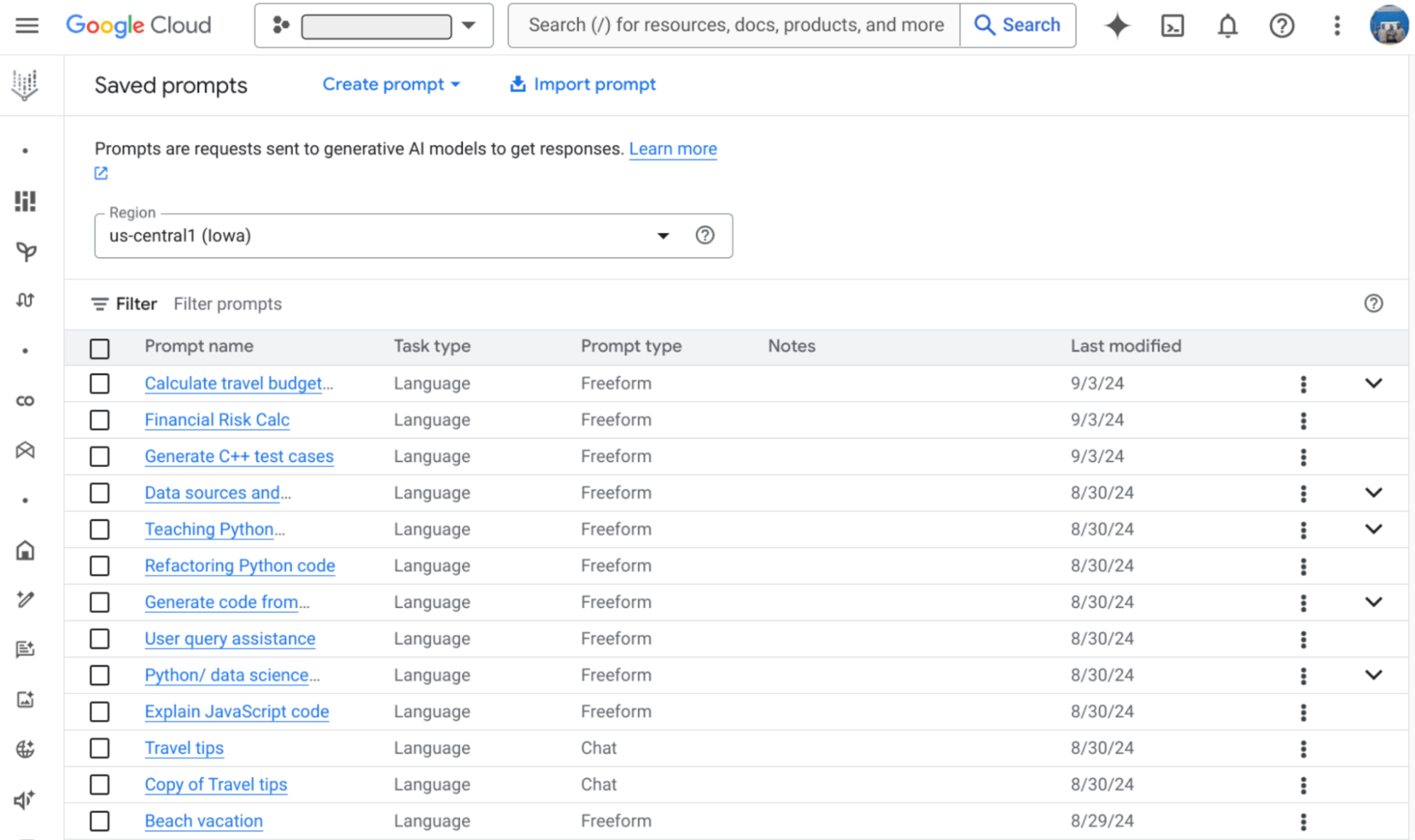
Saved prompts in Vertex AI Studio
3. Model fine-tuning: This step involves adjusting the pre-trained Gen AI model to specific tasks or domains using the fine-tuning data. Below are the two methods available in Vertex AI for fine tuning models in Google Cloud:
-
-
Supervised fine-tuning is a good option when the task is well-defined with available labeled data. It's particularly effective for domain-specific applications where the language or content significantly differs from the data the large model was originally trained on. Here are the configuration recommendations for tuning LLMs on VertexAI using Low-Rank Adaptation of Large Language Models(LoRA) and its more memory-efficient version, QLoRA.
-
Reinforcement Learning from human feedback(RLHF) uses feedback gathered from humans to tune a model. RLHF is recommended when the output of the model is complex and difficult to describe. If the output from the model isn't difficult to define, Supervised fine-tuning is recommended.
-
Visualization tools like TensorBoard and embedding projector can be used to detect unrelated prompts which can be further used for RLHF and RLAIF for preparing the answer for them, as shown below.

Prompt Visualization using TensorBoard
UI can also be created using open source solutions like Google Mesop that helps human evaluators to evaluate and update the LLMs responses, as shown below.
UI built using Google Mesop for RLHF
4. Model evaluation: The GenAI Evaluation Service in Vertex AI is used to evaluate GenAI models with explainable metrics. It provides two major types of metrics:
-
Model-based metrics: The model-based metrics use a proprietary Google model as a judge. It is used to measure model-based metrics pairwise or pointwise.
-
Computation-based metrics: These metrics(such as ROUGE and BLEU) are computed using mathematical formulas to compare the model's output against a ground truth or reference.
Automatic side-by-side(AutoSxS) is a pairwise model-based evaluation tool that is used to evaluate the performance of either GenAI models in VertexAI Model Registry or pre-generated predictions. It uses an autorater to decide which model gives the better response to a prompt.
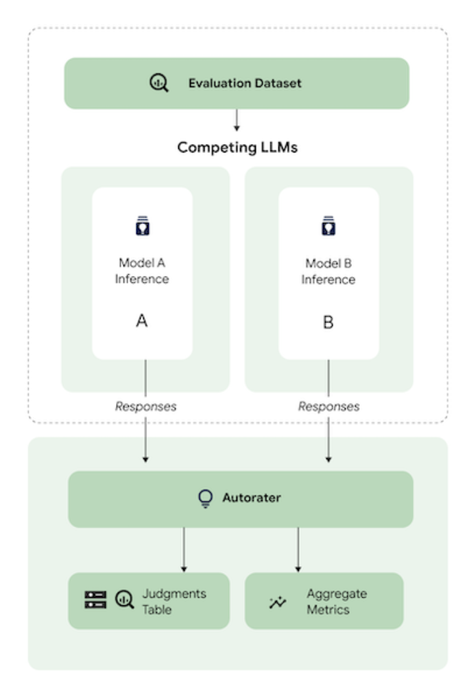
VertexAI AutoSxS Evaluation
5. Model deployment:
-
Models that have managed APIs and do not need deployment: Google’s foundational Gen AI models like Gemini, have managed APIs and can accept prompts without deployment.
-
Models that need deployment: Other Gen AI models must be deployed to a VertexAI Endpoint before they can accept prompts. To be deployable, the model must be visible in VertexAI Model Registry. There are two types of GenAI models that are deployed:
-
Fine-tuned models that are created by tuning a supported foundation model with custom data.
-
GenAI models that don't have managed APIs: Many models in VertexAI Model Garden like Gemma2, Mistral, Nemo etc are accessible via Deploy button or Open Notebook.
Some models support deployment to Google Kubernetes Engine for more control. Serving a model with a single GPU in GKE includes online serving frameworks such as NVIDIA Triton Inference Server and vLLM that are high-throughput and memory-efficient inference engines for LLMs.
6. Monitoring: Ongoing monitoring assesses the deployed models' real-world performance, analyzing key metrics, data patterns, and trends. Cloud Monitoring is used to monitor the Google Cloud services.
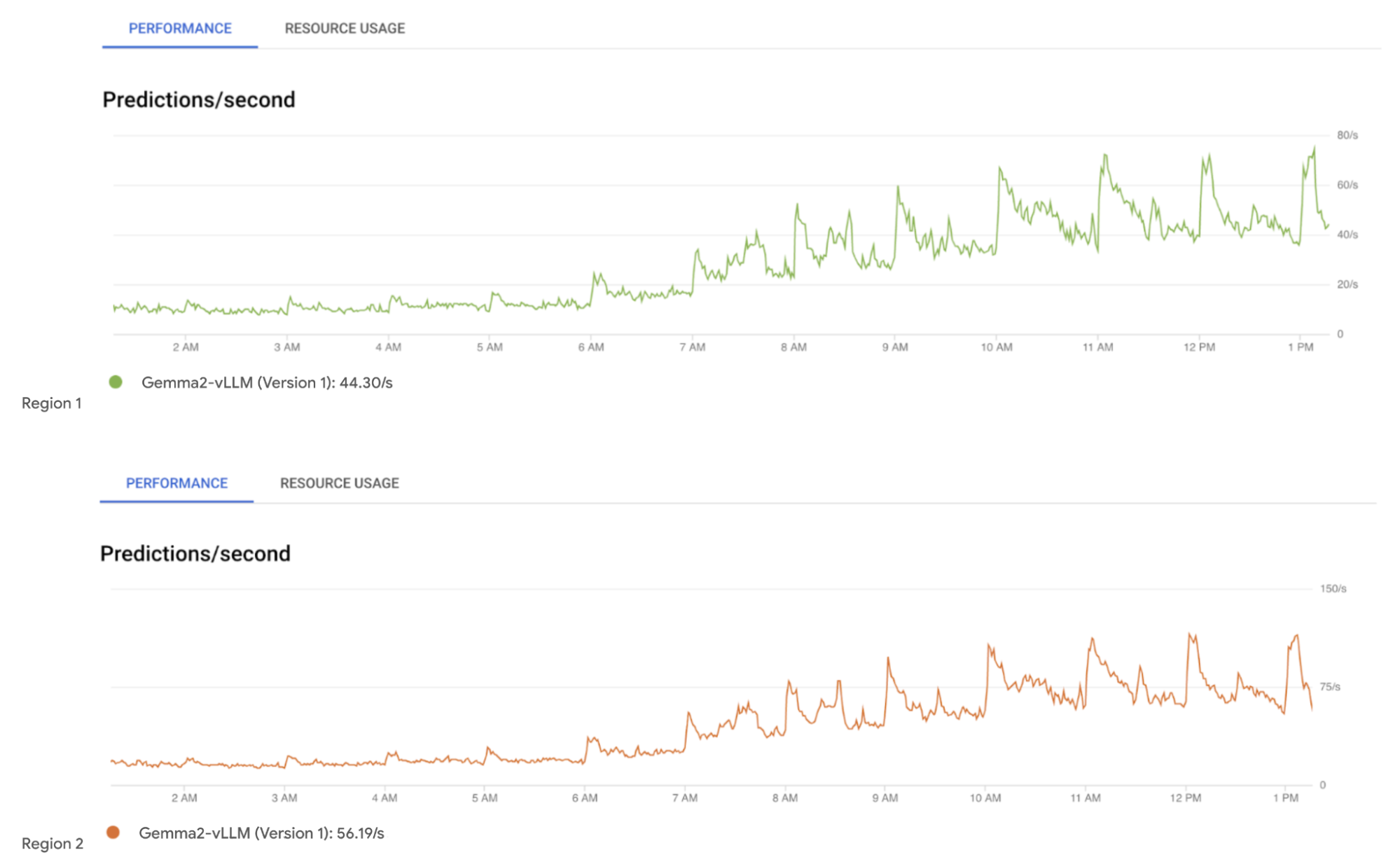
Monitoring Gemma2 Models deployed on VertexAI Endpoints
The adoption of GenOps practices helps organizations fully leverage Gen AI's potential by creating systems that are efficient and aligned with business objectives.



