Is there life on other planets? Google Cloud is working with NASA's Frontier Development Lab to find out

Massimo Mascaro
Distinguished Technical Director, Applied AI, Google Cloud
NASA’s Frontier Development Lab (FDL, for short) is an applied research program established to answer challenging questions in the space sciences. Now in its third consecutive year, FDL hosts researchers from around our own planet to explore problems like detecting asteroids and mapping solar storms.
This past summer, Google Cloud partnered with FDL’s 2018 Astrobiology mission to simulate and classify the possible atmospheres of exoplanets—planets outside our sun's solar system—in the search for signs of life. Here’s more on what that means, what the teams did, and what’s possible in the future.
Two approaches to researching the biologies of distant planets
Astrobiology is a multii-disciplinary scientific field that includes the search for extraterrestrial life by examining the molecular composition of distant planets, typically through the use of hyperspectral and radio telescopes.
As you might imagine, the many possible permutations of temperature, atmospheric pressure, and elements present on a planet’s surface—as well as the physical state of these elements—can influence the life forms that might be able to survive in an environment. Each team sponsored by Google Cloud looked at a different facet of these problems.
Astrobiology 1 team: simulating possible atmospheres on distant planets
The first team focused on simulating the environmental and atmospheric properties of planets as they might diverge from those of Earth.
To build their simulation, they deployed a limited-use, legacy Fortran tool called Atmos in a Docker container that they managed via a Python interface. Google Compute Engine allowed the team to simulate multiple parameters like elemental composition and pressure for these planetary environments, all at the same time. In total, the team analyzed more than 270,000 simulated atmospheres on Compute Engine, generating planet densities as a function of temperature and a set of 12 fundamental (usually gaseous) compounds typically linked with biological function. The team was then able to experiment with a variety of alternative models by running iPython notebooks in Google Kubernetes Engine (GKE).
The following diagram shows a set of simulated atmospheres containing a few of these molecules, on the dimensions of carbon dioxide (CO2), methane (CH4), and (H2O) concentrations in the atmosphere: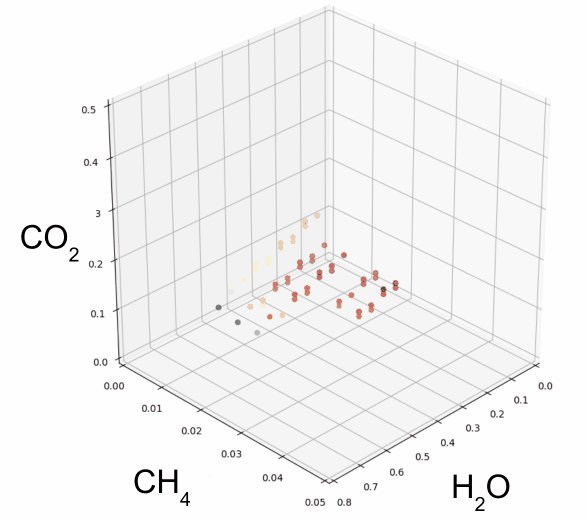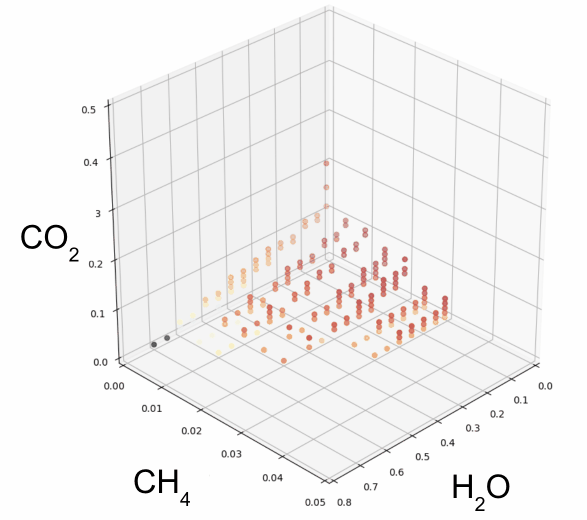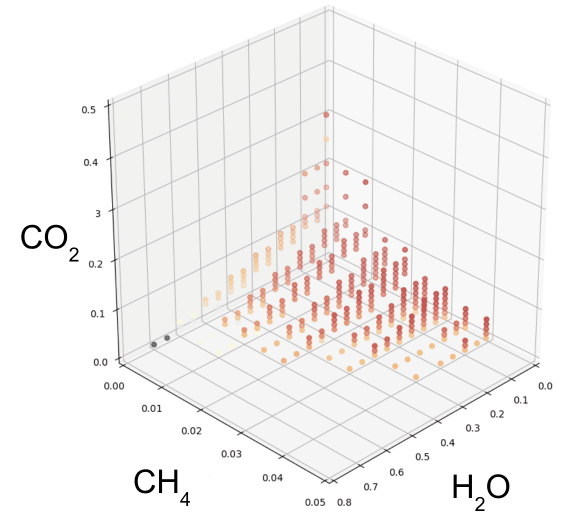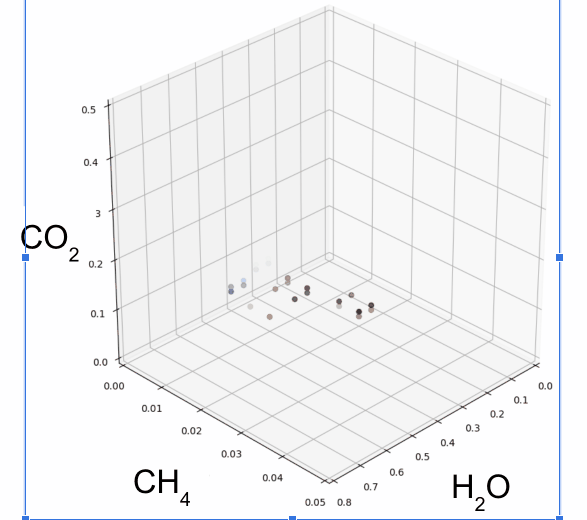
Interestingly, Atmos starts with the concentrations of these molecules found on Earth, and then adjusts the concentrations in small increments to simulate an effectively limitless number of permutations, within rational or physically stable bounds.
The goal here is to discern a generalized biological theory of atmosphere dynamics on planets similar to Earth that are outside our own solar system, to assess their potential to host biological life forms. Or, in other words, to simulate all chemically viable worlds, and see if any observed satellite data matches up.
You can find Astrobiology 1 team’s code, PyAtmos, on GitHub.
Astrobiology 2 team: generating a spectral dataset of over 3 million rocky terrestrial exoplanets with machine learning
A second team studying astrobiology in the Lab this past summer developed the first machine learning algorithm for analyzing rocky or “terrestrial” exoplanets, to infer the chemical composition of their atmospheres.
Astrobiology 2 team developed a process dubbed INARA that sifts through the massive high-resolution imagery datasets provided by telescopes to identify spectral signatures from planets’ atmospheres. This made it possible to analyze imagery and light curves from the Kepler satellite with machine learning to outperform prior leading methodologies used to analyze exoplanets.
Because there isn’t enough existing relevant data from current or historical satellites yet to build a machine learning model, the team developed three million hypothetical planetary spectra, or charts of wavelengths transmitted through each hypothetical planet’s atmosphere. To generate this data at scale, they used NASA Goddard Institute’s software tool, the Planetary Spectrum Generator, which offers a way to randomly generate possible values for atmospheric conditions. They then attempted to classify these spectra by the compounds upon which they were synthesized, using TensorFlow-, Keras-, and PyTorch-based machine learning models. Although the team ultimately decided to deploy PyTorch, TensorFlow and Keras facilitated experimentation, given their compatibility with iPython notebooks.
The team tested several different models, learning rates, and activation functions, to further improve the accuracy of their model, as tested on simulated data. They then iterated with linear regression, feed-forward neural networks, and convolutional neural networks (CNNs). It turned out that the most successful model, in terms of classification accuracy, was a CNN consisting mostly of ReLU layers, trained on just over 60 epochs.
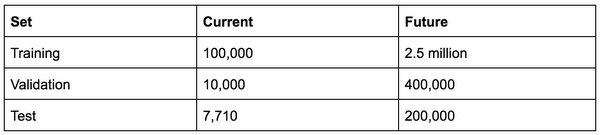
Here’s the dataset’s scale, today and in the future (with more compute time invested, to achieve higher accuracy levels):
Previous attempts by researchers to automate the detection of meaningful data in hyperspectral image data have not been as robust as INARA in terms of the number of molecules they can detect. Without the ability to scale to potentially thousands of Compute Engine instances, the detection process has historically taken much longer, whether it was performed manually or in a heuristic (algorithm-based) fashion.
Given the scale of the datasets produced by the Kepler telescopes, and the even greater volume of data that will return to Earth from the soon-to-be-launched Transiting Exoplanet Survey Satellite (TESS) satellite, minimizing analysis time per planet can accelerate this research and ensure we don’t miss any viable candidates.
A comparison of assessment speed between INARA and competing methodologies:
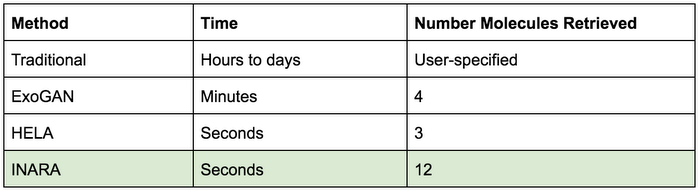
Because INARA can analyze more molecular spectra per planet, it can create more sophisticated analyses from its corresponding input spectral data. This helps define a more robust biological profile for that planet and the molecules that might be available to life living in its atmosphere.
The team plans to release both their dataset and their machine learning model as open-source software in the near future.
What’s next?
With the advent of even more capable telescopes such as TESS, scientists will face ever greater challenges processing the sheer magnitude of image and radio data sent back to Earth. Thus, it becomes even more important to have tools that can both analyze and interpret the locations of distant planets in all of this data. We’re thrilled to be partnering with NASA FDL to answer the fundamental question: are we alone?

Header photo courtesy of NASA/JPL-Caltech.
For more information about Google Cloud's collaboration with NASA FDL, check out the landing page here.



