Improved customer feedback management with Google Cloud AutoML
Michael W. Sherman
Machine Learning Engineer
Anastasiia Manokhina
Strategic Cloud Engineer
When it comes to customer satisfaction, the customer service experience can often be more important than the actual product. According to Forbes, companies lost about $75 billion in 2018 due to poor customer service, and 39% of customers who experienced poor customer service will not do business with the offending company again.
An important part of delivering a positive customer service experience is handling customer feedback, especially negative feedback, quickly and efficiently. But responding to and acting on customer feedback is a complex and time consuming process that’s usually done manually—making it a good fit for efficiency increases using AI. Integrating AI into a customer feedback management process can automate repetitive tasks, freeing up customer support agents to work on the most complex and time-sensitive cases. In this blog we’ll look at an example of how you can use AutoML to make your customer feedback management more efficient.
Automating complaint classification
Using AutoML Tables, we built an example solution (including code) to classify customer feedback. The AI-enabled classifications can then be used to send appropriate automated responses, to route complaints and other actionable feedback to the right support team, and to flag selected feedback as high priority. Automating these actions can reduce customer wait times, decrease the amount of feedback that needs to be handled manually, and bring critical issues to the surface.
AutoML offers several advantages over a manually-built machine learning model. AutoML uses more than 10 years of Google Research technology to create faster models that make more accurate predictions. AutoML automatically manages the training and deployment of custom models. Once your data is in the appropriate structure, AutoML can train and deploy your custom model behind a scalable API in a couple hours, saving days, weeks, or even months versus developing a machine learning model.
If you provide customer support, you probably already have the data you need to train your custom AutoML Tables model. Normal customer service workflow data—how feedback was resolved, what team feedback was routed to, what products the feedback addressed, what issues were identified, the resolution of negative feedback, the time to resolution, and the text of the feedback itself—are ingested by AutoML Tables, which learns from both structured data and text.
The provided code example trains a model on publicly-available customer complaint data collected by Consumer Financial Protection Bureau (CFPB), a United States government agency focused on consumer protection in the financial sector. The data includes variables like the product type, the subproduct, the issue, location data, and the complaint narrative (a text field), along with data about the resolution of the complaint. The data is ingested from BigQuery, cleaned and transformed into a form appropriate for machine learning, and then used to train an AutoML Tables model. From there, the code makes batch predictions (for evaluation), deploys an API endpoint used to make predictions, and makes a prediction using the API. The code uses configuration to find and parse the data and deploy the model, easing adaptation to new datasets.
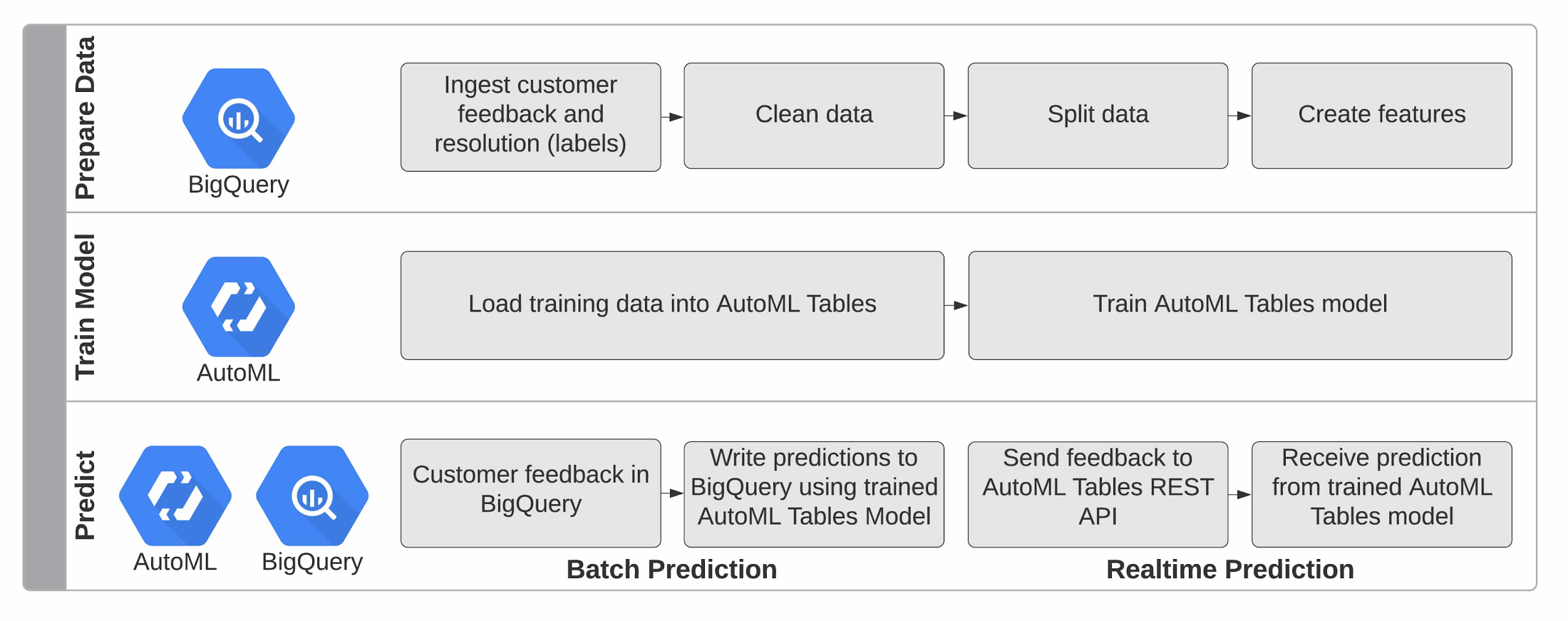
Whenever a customer takes the time to provide feedback—positive or negative—you have an opportunity to show them how much they’re valued. This example code and pipeline, powered by AutoML and BigQuery, provides the foundation for a more efficient and consumer-friendly customer service experience, which can help you improve not only your core customer support metrics, but also how your company is perceived in the eyes of consumers.
To learn more about how we are helping companies manage the surge in customer needs related to COVID-19, see How Cloud AI is helping during COVID-19.
Acknowledgement
This code linked from this post was built by Sahana Subramanian, Michael Sparkman, Karan Palsani, and Shane Kok, 2020 graduates of the Master of Science in Business Analytics program at the University of Texas at Austin. We’d also like to thank Dimos Christopoulos and Andrew Leach.


