Perform hyperparameter tuning using R and caret on Vertex AI
Fabian Hirschmann
Machine Learning Specialist
Rajesh Thallam
Solutions Architect, Generative AI Solutions
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialTo produce any sufficiently accurate machine learning model, the process requires tuning parameters and hyperparameters. Your model’s parameters are variables that your chosen machine learning technique uses to adjust to your data, like weights in neural networks to minimize loss. Hyperparameters are variables that control the training process itself. For example, in a multilayer perceptron, altering the number and size of hidden layers can have a profound effect on your model’s performance, as does the maximum depth or minimum observations per node in a decision tree.
Hyperparameter tuning can be a costly endeavor, especially when done manually or when using exhaustive grid search to search over a larger hyperparameter space.
In 2017, Google introduced Vizier, a technique used internally at Google for performing black-box optimization. Vizier is used to optimize many of our own machine learning models, and is also available in Vertex AI, Google Cloud’s machine learning platform. Vertex AI Hyperparameter tuning for custom training is a built-in feature using Vertex AI Vizier for training jobs. It helps determine the best hyperparameter settings for an ML model.
Overview
In this blog post, you will learn how to perform hyperparameter tuning of your custom R models through Vertex AI.
Since many R users prefer to use Vertex AI from RStudio programmatically, you will interact with Vertex AI through the Vertex AI SDK via the reticulate package.
The process of tuning your custom R models on Vertex AI comprises the following steps:
Enable Google Cloud Platform (GCP) APIs and set up the local environment
Create custom R script for training a model using specific set of hyperparameters
Create a Docker container that supports training R models with Cloud Build and Container Registry
Train and tune a model using HyperParameter Tuning jobs on Vertex AI Training
Dataset
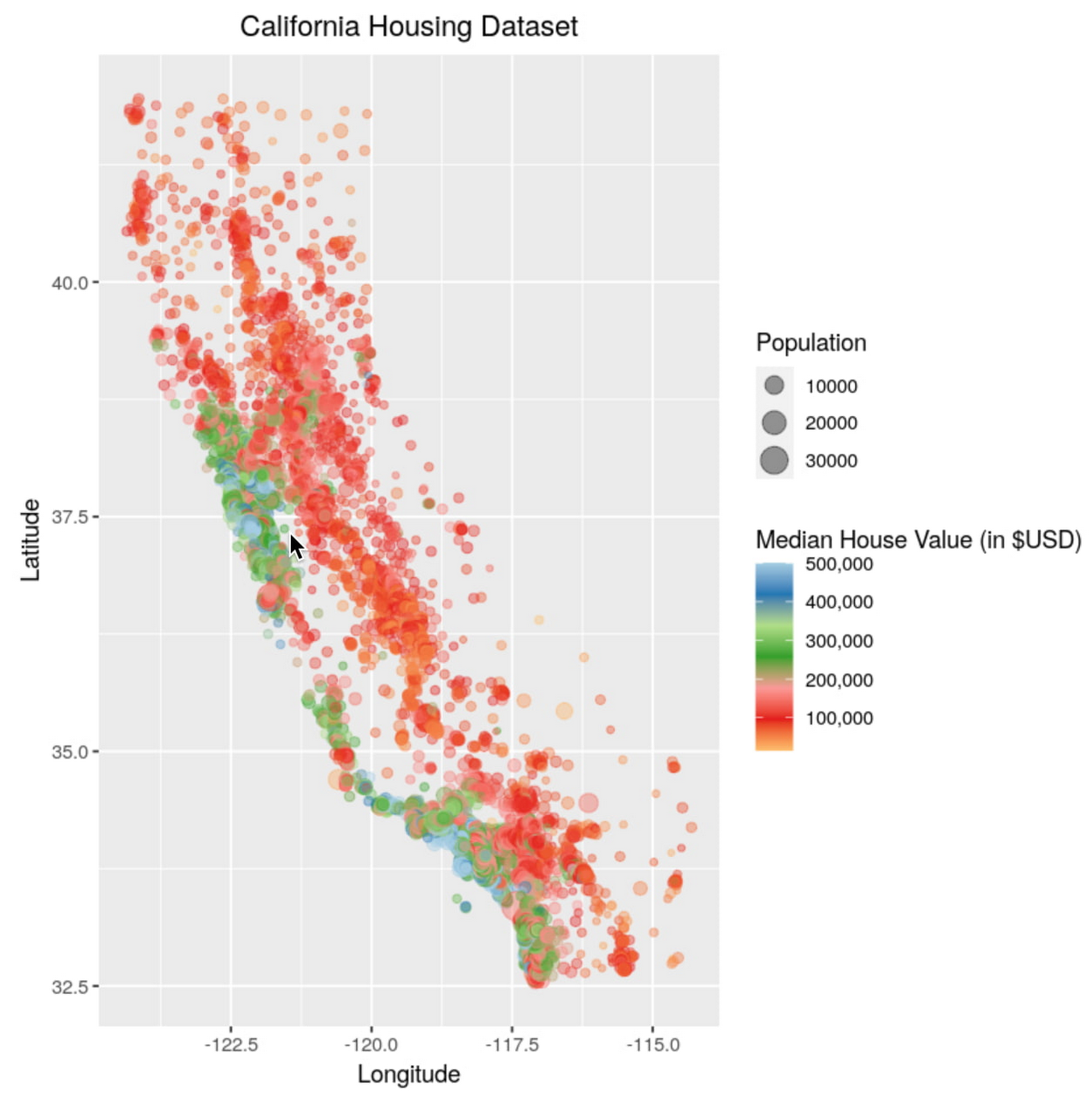
To showcase this process, you train a simple boosted tree model to predict housing prices on the California housing data set. The data contains information from the 1990 California census. The data set is publicly available from Google Cloud Storage at gs://cloud-samples-data/ai-platform-unified/datasets/tabular/california-housing-tabular-regression.csv
The tree model model will predict a median housing price, given a longitude and latitude along with data from the corresponding census block group. A block group is the smallest geographical unit for which the U.S. Census Bureau publishes sample data (a block group typically has a population of 600 to 3,000 people).
Environment setup
This blog post assumes that you are either using Vertex AI Workbench with an R kernel or RStudio. Your environment should include the following requirements:
The Google Cloud SDK
Git
R
Python 3
Virtualenv
To execute shell commands, define a helper function:
You should also install a few R packages and update the SDK for Vertex AI:
Next, you define variables to support the training and deployment process, namely:
PROJECT_ID: Your Google Cloud Platform Project IDREGION: Currently, the regions us-central1, europe-west4, and asia-east1 are supported for Vertex AI; it is recommended that you choose the region closest to youBUCKET_URI: The staging bucket where all the data associated with your dataset and model resources are storedDOCKER_REPO: The Docker repository name to store container artifactsIMAGE_NAME: The name of the container imageIMAGE_TAG: The image tag that Vertex AI will useIMAGE_URI: The complete URI of the container image
When you initialize the Vertex AI SDK for Python, you specify a Cloud Storage staging bucket. The staging bucket is where all the data associated with your dataset and model resources are retained across sessions.
Finally, you import and initialize the reticulate R package to interface with the Vertex AI SDK, which is written in Python.
Create container images for training and tuning models
The Dockerfile for your custom container is built on top of the Deep Learning container — the same container that is also used for Vertex AI Workbench. You just add an R script for model training and tuning.
Before creating such a container, you enable Artifact Registry and configure Docker to authenticate requests to it in your region.
Next, create a Dockerfile.
Next, create the file train.R, which is used to train your R model. The script trains a gbm model (generalized boosted regression model) on the California Housing dataset. Vertex AI sets environment variables that you can utilize, and the hyperparameters for each trial are passed as command line arguments. The trained model artifacts are then stored in your Cloud Storage bucket. The results of your training script are communicated back to Vertex AI using the hypertune package, which stores a JSON file to /tmp/hypertune/output.metrics. Vertex AI uses this information to come up with a hyperparameter configuration for the next trial, and to assess which trial was responsible for the best overall result.
Finally, you build the Docker container image on Cloud Build - the serverless CI/CD platform. Building the Docker container image may take 10 to 15 minutes.
Tune custom R model
Once your training application is containerized, you define the machine specifications for the tuning job. In this example, you use n1-standard-4 instances.
This specification is then used in a CustomJob.
Hyperparameter tuning jobs search for the best combination of hyperparameters to optimize your metrics. Hyperparameter tuning jobs do this by running multiple trials of your training application with different sets of hyperparameters.
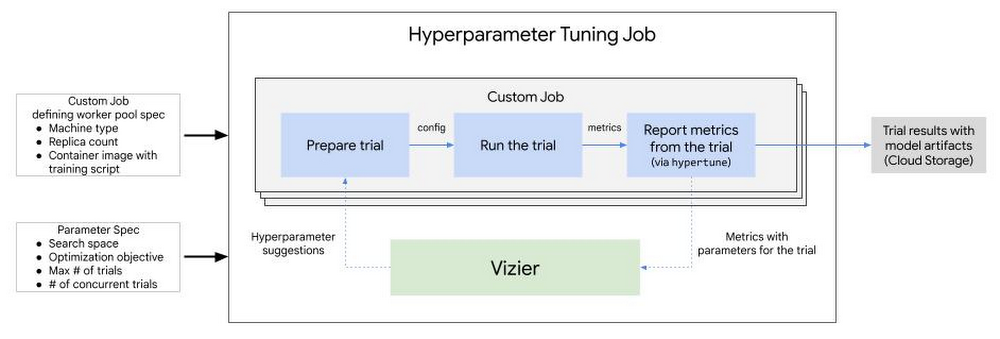
You can control the job in the following ways:
max_trial_count: Decide how many trials you want to allow the service to run. Increasing the number of trials generally yields better results, but it is not always so. Usually, there is a point of diminishing returns after which additional trials have little or no effect on the accuracy. Before starting a job with a large number of trials, you may want to start with a small number of trials to gauge the effect your chosen hyperparameters have on your model's accuracy. To get the most out of hyperparameter tuning, you shouldn't set your maximum value lower than ten times the number of hyperparameters you use.parallel_trial_count: You can specify how many trials can run in parallel. Running parallel trials has the benefit of reducing the time the training job takes (real time — the total processing time required is not typically changed). However, running in parallel can reduce the effectiveness of the tuning job overall. That is because hyperparameter tuning uses the results of previous trials to inform the values to assign to the hyperparameters of subsequent trials. When running in parallel, some trials start without having the benefit of the results of any trials still running.
In addition, you also need to specify which hyperparameters to tune. There is little universal advice to give about how to choose which hyperparameters you should tune. If you have experience with the machine learning technique that you're using, you may have insight into how its hyperparameters behave. You may also be able to find advice from machine learning communities.
However you choose them, it's important to understand the implications. Every hyperparameter that you choose to tune has the potential to increase the number of trials required for a successful tuning job. When you run a hyperparameter tuning job on Vertex AI, the amount you are charged is based on the duration of the trials initiated by your hyperparameter tuning job. A careful choice of hyperparameters to tune can reduce the time and cost of your hyperparameter tuning job.
Vertex AI supports several data types for hyperparameter tuning jobs.
To tune the model, you call the method run().
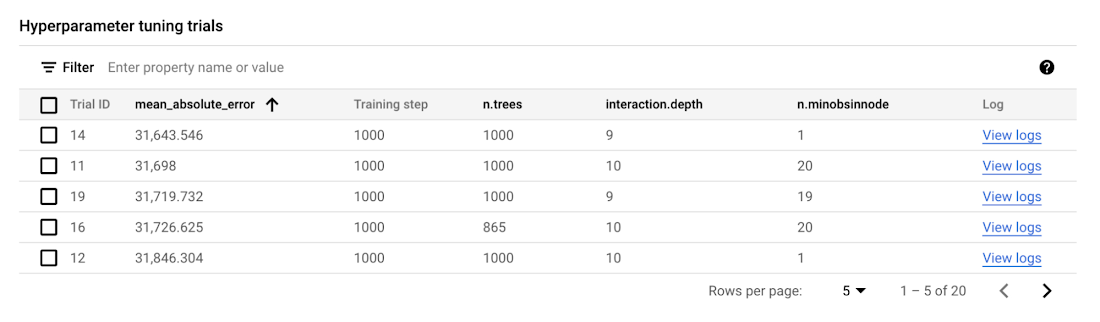
Finally, to list all trials and their respective results, we can inspect hpt_job$trials.
And find the trial with the lowest error.
The results of this tuning job can also be inspected from the Vertex AI Console.
Summary
In this blog post, you have gone through tuning a custom R model using Vertex AI. For easier reproducibility, you can refer to this notebook on GitHub. You can deploy the resultant model from the best trial on Vertex AI Prediction following the article here.

