How Waze predicts carpools with Google Cloud’s AI Platform
Philippe Adjiman
Senior Data Scientist, Waze
Waze’s mission is to eliminate traffic and we believe our carpool feature is a cornerstone that will help us achieve it. In our carpool apps, a rider (or a driver) is presented with a list of users that are relevant for their commute (see below). From there, the rider or the driver can initiate an offer to carpool, and if the other side accepts it, it’s a match and a carpool is born.

Let’s consider a rider who is commuting from somewhere in Tel-Aviv to Google’s offices, as an example that we’ll use throughout this post. Our goal will be to present to that rider a list of drivers that are geographically relevant to her commute, and to rank that list by the highest likelihood of the carpool between that rider and any driver on the list to actually happen.
Finding all the relevant candidates in a few seconds involves a lot of engineering and algorithmic challenges, and we’ve dedicated a full team of talented engineers to the task. In this post we’ll focus on the machine learning part of the system responsible for ranking those candidates.
In particular:
If hundreds (or more) drivers could be a good match for our rider (in our example), how can we build a ML model that would decide which ones to show her first?
How can we build the system in a way that allows us to iterate quickly on complex models in production while guaranteeing a low latency online in order to keep the overall user experience fast and delightful?
ML models to rank lists of drivers and riders
So, the rider in our example sees a list of potential drivers. For each such driver, we need to answer two questions:
What is the probability that our rider will send this driver a request to carpool?
What is the probability that the driver will actually accept the rider’s request?
We solve this using machine learning: we build models that estimate those two probabilities based on aggregated historical data of drivers and riders sending and accepting requests to carpool. We use the models to sort drivers from highest to lowest likelihood of the carpool to actually happen.
The models we’re using combine close to 90 signals to estimate those probabilities. Below are a few of the most important signals to our models:
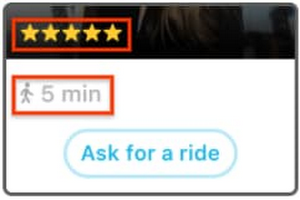
Star Ratings: higher rated drivers tend to get more requests
- Walking distance from pickup and dropoff: riders want to start and end their rides as close as possible to the driver’s route. But, the total walking distance (as seen in the screenshot above) isn’t everything: riders also care about how the walking distance compares to their overall commute length. Consider the two plans below of two different riders: both have 15 minutes walking, but the second one looks much more acceptable given that the commute length is larger to start with, while in the first one, the rider needs to walk as much as the actual carpool length, and is thus much less likely to be interested. The signal that is capturing this in the model and that came up as one of the most important signals, is the ratio between the walking and carpool distance.
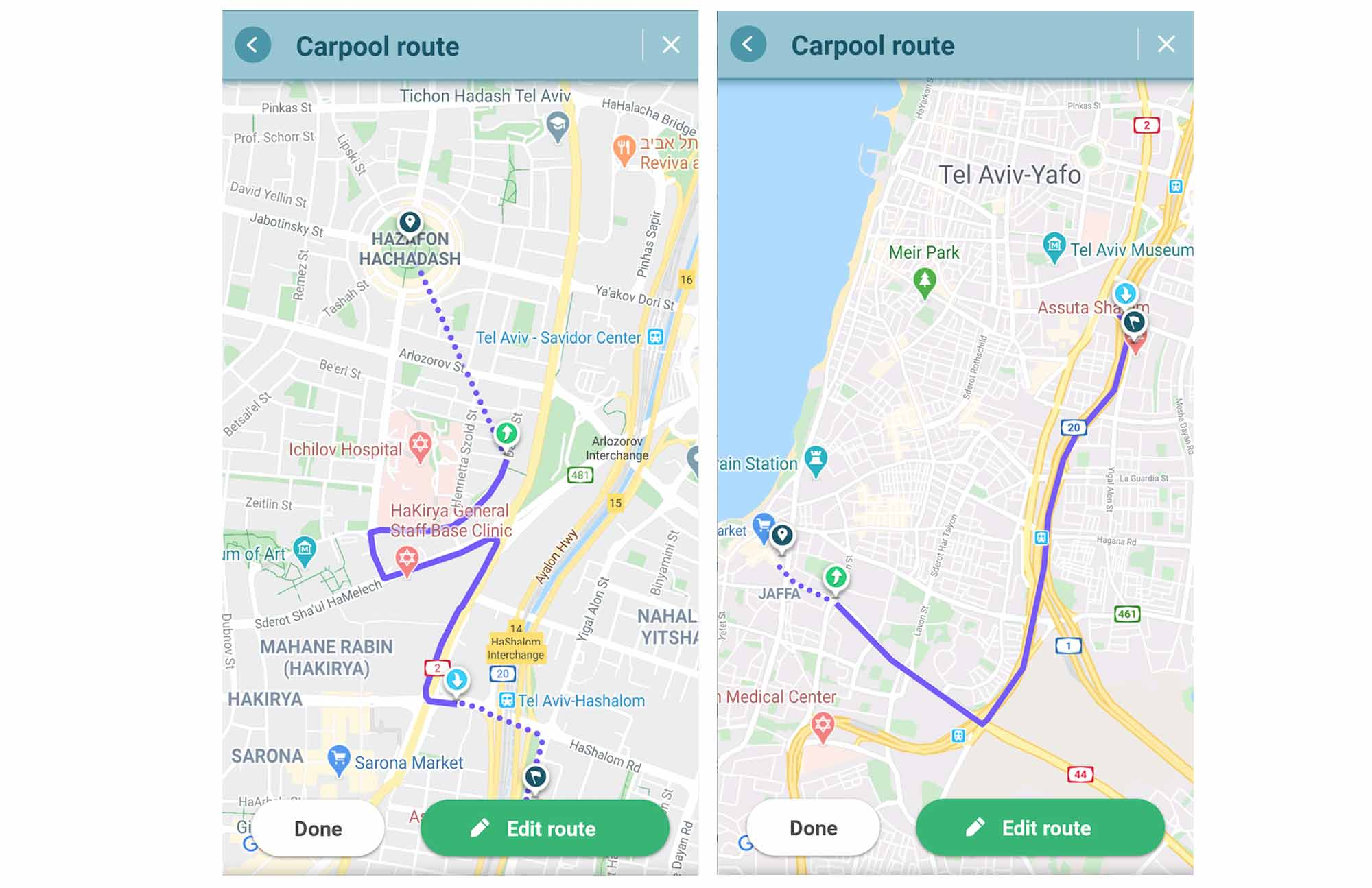
The same kind of consideration is valid on the driver side, when considering the length of the detour compared to the driver’s full drive from origin to destination.

- Driver’s intent: One of the most important factors impacting the probability of a driver to accept a request to carpool (sent by a rider) is her intent to actually carpool. We have several signals indicating a driver's intent, but the one that came up as the most important (as captured by the model) is the last time the driver was seen in the app. The more recent it is, the more likely the driver is to accept a request to carpool sent by a rider.
Model vs. Serving complexity
In the early stage of our product, we started with simple logistic regression models to estimate the likelihood of users sending/accepting offers. The models were trained offline using scikit learn. The training set was obtained using a “log and learn” approach (logging signals exactly as they were during serving time) over ~90 different signals, and the learned weights were injected into our serving layer.
Although those models were doing a pretty good job, we observed via offline experiments the great potential of more advanced non linear models such as gradient boosted regression classifiers for our ranking task.
Implementing an in-memory fast serving layer supporting such advanced models would require non-trivial effort, as well as an on-going maintenance cost. A much simpler option was to delegate the serving layer to an external managed service that can be called via a REST API. However, we needed to be sure that it wouldn’t add too much latency to the overall flow.
In order to make our decision, we decided to do a quick POC using the AI Platform Online Prediction service, which sounded like a potential great fit for our needs at the serving layer.
A quick (and successful) POC
We trained our gradient boosted models over our ~90 signals using scikit learn, serialized it as a pickle file, and simply deployed it as-is to the Google Cloud AI Platform. Done. We get a fully managed serving layer for our advanced model through a REST API. From there, we just had to connect it to our java serving layer (a lot of important details to make it work, but unrelated to the pure model serving layer).
Below is a very high level schema of what our offline/online training/serving architecture looks like. The carpool serving layer is responsible for a lot of logic around computing/fetching the relevant candidates to score, but we focus here on the pure ranking ML part. Google Cloud AI Platform plays a key role in that architecture. It greatly increases our velocity by providing us with an immediate, managed and robust serving layer for our models and allows us to focus on improving our features and modelling.
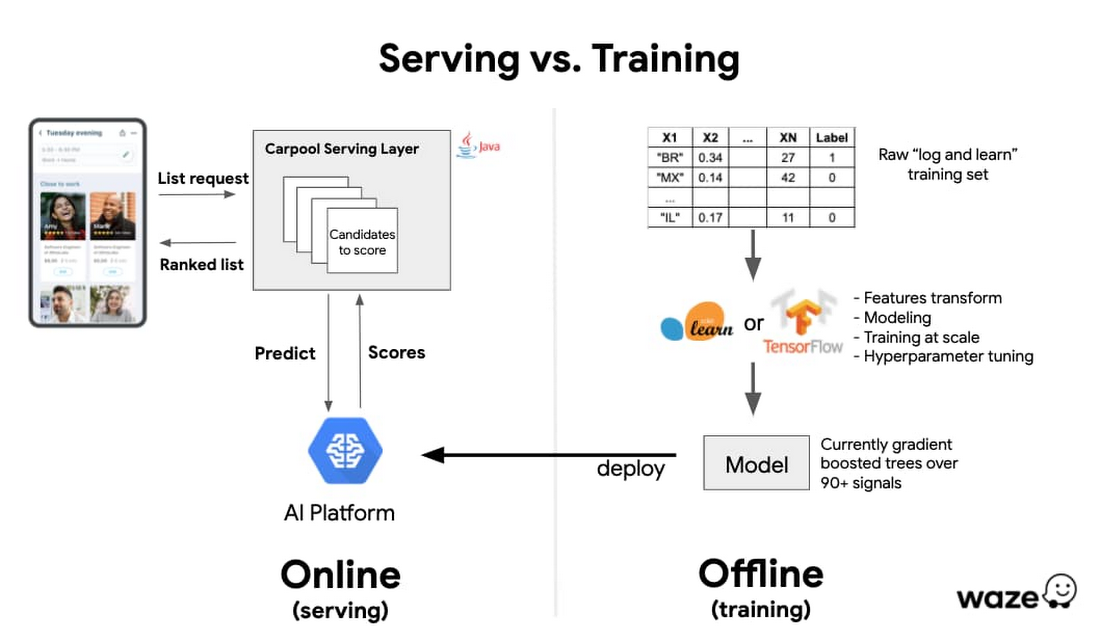
Increased velocity and the peace of mind to focus on our core model logic was great, but a core constraint was around the latency added by an external REST API call at the serving layer. We performed various latency checks/load tests against the online prediction API for different models and input sizes. AI Platform provided the low double digit millisecond latency that was necessary for our application.
In just a couple of weeks, we were able to implement and connect the components together and deploy the model in production for AB testing. Even though our previous models (a set of logistic regression classifiers) were performing well, we were thrilled to observe significant improvements on our core KPIs in the AB test. But what mattered even more for us, was having a platform to iterate quickly over even more complex models, without having to deal with the training/serving implementation and deployment headaches.
The tip of the (Google Cloud AI Platform) iceberg
In the future we plan to explore more sophisticated models using Tensorflow, along with Google Cloud’s Explainable AI component that will simplify the development of these sophisticated models by providing deeper insights into how they are performing. AI Platform Prediction’s recent GA release of support for GPUs and multiple high-memory and high-compute instance types will make it easy for us to deploy more sophisticated models in a cost effective way.
Based on our early success with the AI Platform Prediction service, we plan to aggressively leverage other compelling components offered by GCP’s AI Platform, such as the Training service w/ hyper parameter tuning, Pipelines, etc. In fact, multiple data science teams and projects (ads, future drive predictions, ETA modelling) at Waze are already using or started exploring other existing (or upcoming) components of the AI Platform. More on that in future posts.



