Vertex AI Embeddings for Text: Grounding LLMs made easy
Kaz Sato
Developer Advocate, Cloud AI
Ivan Cheung
Developer Programs Engineer, Google Cloud
Many people are now starting to think about how to bring Gen AI and large language models (LLMs) to production services. You may be wondering "How to integrate LLMs or AI chatbots with existing IT systems, databases and business data?", "We have thousands of products. How can I let LLM memorize them all precisely?", or "How to handle the hallucination issues in AI chatbots to build a reliable service?". Here is a quick solution: grounding with embeddings and vector search.
What is grounding? What are embedding and vector search? In this post, we will learn these crucial concepts to build reliable Gen AI services for enterprise use. But before we dive deeper, here is an example:

Semantic search on 8 million Stack Overflow questions in milliseconds. (Try the demo here)
This demo is available as a public live demo here. Select "STACKOVERFLOW" and enter any coding question as a query, so it runs a text search on 8 million questions posted on Stack Overflow.
The following points make this demo unique:
LLM-enabled semantic search: The 8 million Stack Overflow questions and query text are both interpreted by Vertex AI Generative AI models. The model understands the meaning and intent (semantics) of the text and code snippets in the question body at librarian-level precision. The demo leverages this ability for finding highly relevant questions and goes far beyond simple keyword search in terms of user experience. For example, if you enter "How do I write a class that instantiates only once", then the demo shows "How to create a singleton class" at the top, as the model knows their meanings are the same in the context of computer programming.
Grounded to business facts: In this demo, we didn't try having the LLM to memorize the 8 million items with complex and lengthy prompt engineering. Instead, we attached the Stack Overflow dataset to the model as an external memory using vector search, and used no prompt engineering. This means, the outputs are all directly "grounded" (connected) to the business facts, not the artificial output from the LLM. So the demo is ready to be served today as a production service with mission critical business responsibility. It does not suffer from the limitation of LLM memory or unexpected behaviors of LLMs such as the hallucinations.
Scalable and fast: The demo gives you the search results in tens of milliseconds while retaining the deep semantic understanding capability. Also, the demo is capable of scaling out to handle thousands of search queries every second. This is enabled with the combination of LLM embeddings and Google AI's vector search technology.
The key enablers of this solution are 1) the embeddings generated with Vertex AI Embeddings for Text and 2) fast and scalable vector search by Vertex AI Vector Search. Let's start by taking a look at these technologies.
First key enabler: Vertex AI Embeddings for Text
On May 10, 2023, Google Cloud announced the following Embedding APIs for Text and Image. They are available on Vertex AI Model Garden.
Embeddings for Text : The API takes text input up to 3,072 input tokens and outputs 768 dimensional text embeddings, and is available as a public preview. As of May 10, 2023, the pricing is $0.0001 per 1000 characters (the latest pricing is available on the Pricing for Generative AI models page).
Embeddings for Image: Based on Google AI's Contrastive Captioners (CoCa) model, the API takes either image or text input and outputs 1024 dimensional image/text multimodal embeddings, available to trusted testers. This API outputs so-called "multimodal" embeddings, enabling multimodal queries where you can execute semantic search on images by text queries, or vise-versa. We will feature this API in another blog post soon.
In this blog, we will explain more about why embeddings are useful and show you how to build and an application leveraging Embeddings API for Text. In a future blog post, we will provide a deep dive on Embeddings API for Image.
Embeddings API for Text on Vertex AI Model Garden
What is embeddings?
So, what are semantic search and embeddings? With the rise of LLMs, why is it becoming important for IT engineers and ITDMs to understand how they work? To learn it, please take a look at this video from a Google I/O 2023 session for 5 minutes:

Also, Foundational courses: Embeddings on Google Machine Learning DYM crash course and Meet AI’s multitool: Vector embeddings by Dale Markowitz are great materials to learn more about embeddings.
LLM text embedding business use cases
With the embedding API, you can apply the innovation of embeddings, combined with the LLM capability, to various text processing tasks, such as:
- LLM-enabled Semantic Search: text embeddings can be used to represent both the meaning and intent of a user's query and documents in the embedding space. Documents that have similar meaning to the user's query intent will be found fast with vector search technology. The model is capable of generating text embeddings that capture the subtle nuances of each sentence and paragraphs in the document.
- LLM-enabled Text Classification: LLM text embeddings can be used for text classification with a deep understanding of different contexts without any training or fine-tuning (so-called zero-shot learning). This wasn't possible with the past language models without task-specific training.
- LLM-enabled Recommendation: The text embedding can be used for recommendation systems as a strong feature for training recommendation models such as Two-Tower model. The model learns the relationship between the query and candidate embeddings, resulting in next-gen user experience with semantic product recommendation.
- LLM-enabled Clustering, Anomaly Detection, Sentiment Analysis, and more, can be also handled with the LLM-level deep semantics understanding.
Sorting 8 million texts at "librarian-level" precision
Vertex AI Embeddings for Text has an embedding space with 768 dimensions. As explained in the video above, the space represents a huge map of a wide variety of texts in the world, organized by their meanings. With each input text, the model can find a location (embedding) in the map.
The API can take 3,072 input tokens, so it can digest the overall meaning of a long text and even programming code, and represent it as single embedding. It is like having a librarian knowledgeable about a wide variety of industries, reading through millions of texts carefully, and sorting them with millions of nano-categories that can classify even slight differences of subtle nuances.
By visualizing the embedding space, you can actually observe how the model sorts the texts at the "librarian-level" precision. Nomic AI provides a platform called Atlas for storing, visualizing and interacting with embedding spaces with high scalability and in a smooth UI, and they worked with Google for visualizing the embedding space of the 8 million Stack Overflow questions. You can try exploring around the space, zooming in and out to each data point on your browser on this page, courtesy of Nomic AI.

8 million Stack Overflow questions embedding spaceVisualized by Nomic AI Atlas (Try exploring it here)

Examples of the "librarian-level" semantic understanding by Embeddings API with Stack Overflow questions
Note that this demo didn't require any training or fine-tuning with computer programming specific datasets. This is the innovative part of the zero-shot learning capability of the LLM; it can be applied to a wide variety of industries, including finance, healthcare, retail, manufacturing, construction, media, and more, for deep semantic search on the industry-focused business documents without spending time and cost for collecting industry specific datasets and training models.
The second key enabler: fast and scalable Vector Search
The second key enabler of the Stack Overflow demo shown earlier is the vector search technology. This is another innovation we are having in the data science field.
The problem is "how to find similar embeddings in the embedding space". Since embeddings are vectors, this can be done by calculating the distance or similarity between vectors, as shown below.
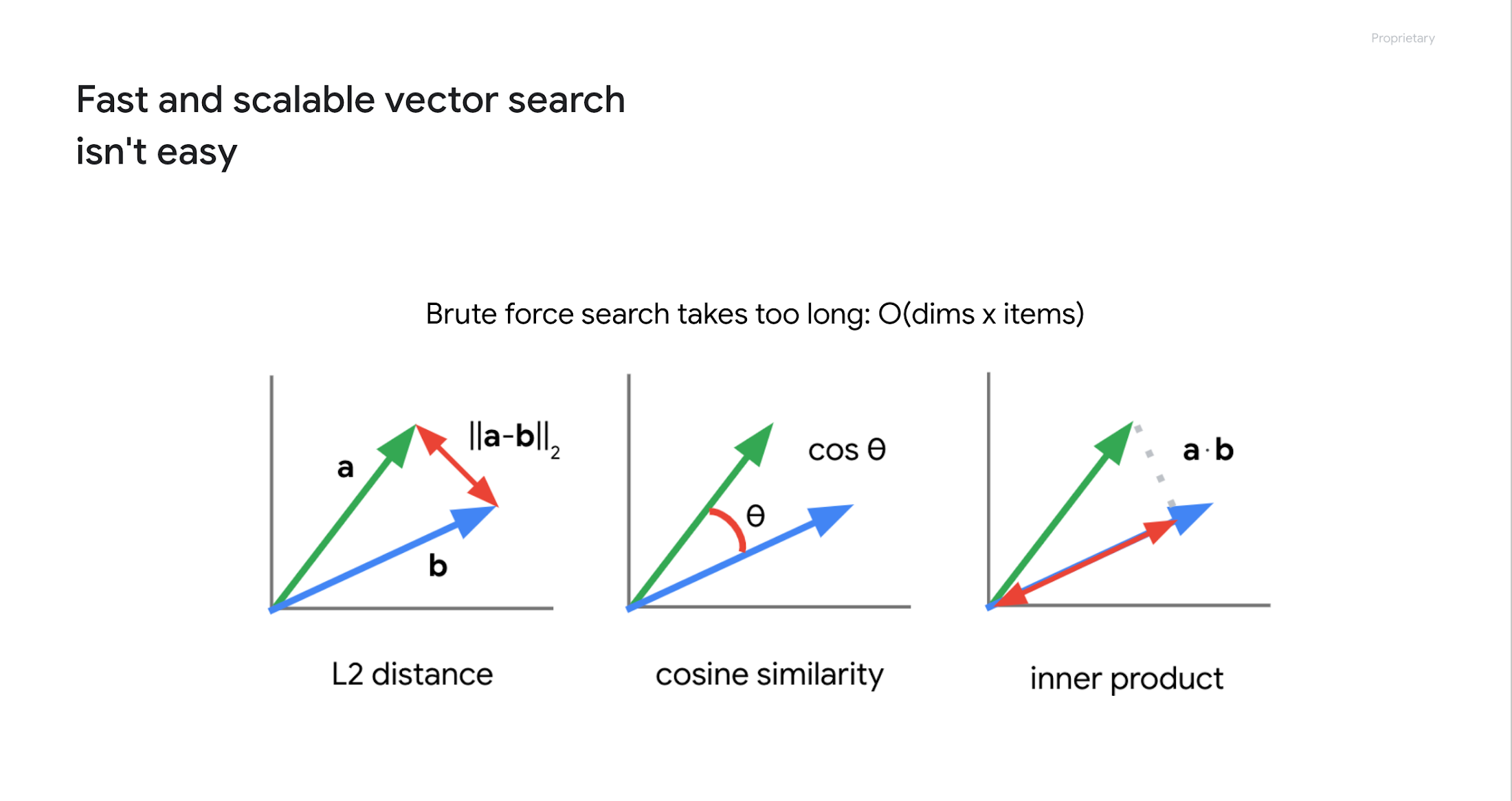
But this isn't easy when you have millions or billions of embeddings. For example, if you have 8 million embeddings with 768 dimensions, you would need to repeat the calculation in the order of 8 million x 768. This would take a very long time to finish. Actually, when we tried this on BigQuery with one million embeddings five years ago, it took 20 seconds.
So the researchers have been studying a technique called Approximate Nearest Neighbor (ANN) for faster search. ANN uses "vector quantization" for separating the space into multiple spaces with a tree structure. This is similar to the index in relational databases for improving the query performance, enabling very fast and scalable search with billions of embeddings.
With the rise of LLMs, the ANN is getting popular quite rapidly, known as the Vector Search technology.

In 2020, Google Research published a new ANN algorithm called ScaNN. It is considered one of the best ANN algorithms in the industry, also the most important foundation for search and recommendation in major Google services such as Google Search, YouTube and many others.
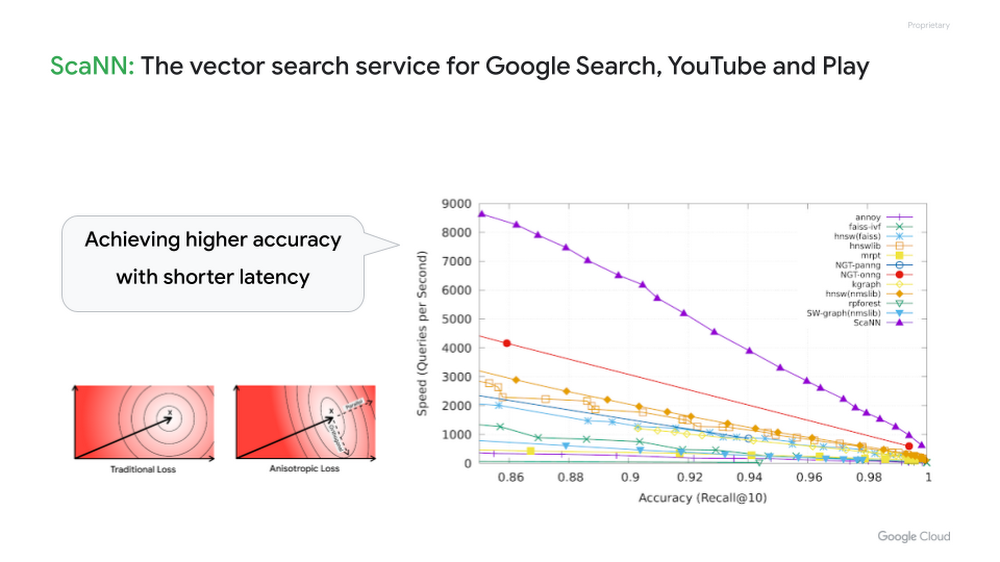
Google Cloud developers can take the full advantage of Google's vector search technology with Vertex AI Vector Search. With this fully managed service, developers can just add the embeddings to its index and issue a search query with a key embedding for the blazingly fast vector search. In the case of the Stack Overflow demo, Vector Search can find relevant questions from 8 million embeddings in tens of milliseconds.
With Vector Search, you don't need to spend much time and money building your own vector search service from scratch or using open source tools if your goal is high scalability, availability and maintainability for production systems.
Grounding LLM outputs with Vector Search
By combining the Embeddings API and Vector Search, you can use the embeddings to "ground" LLM outputs to real business data with low latency:
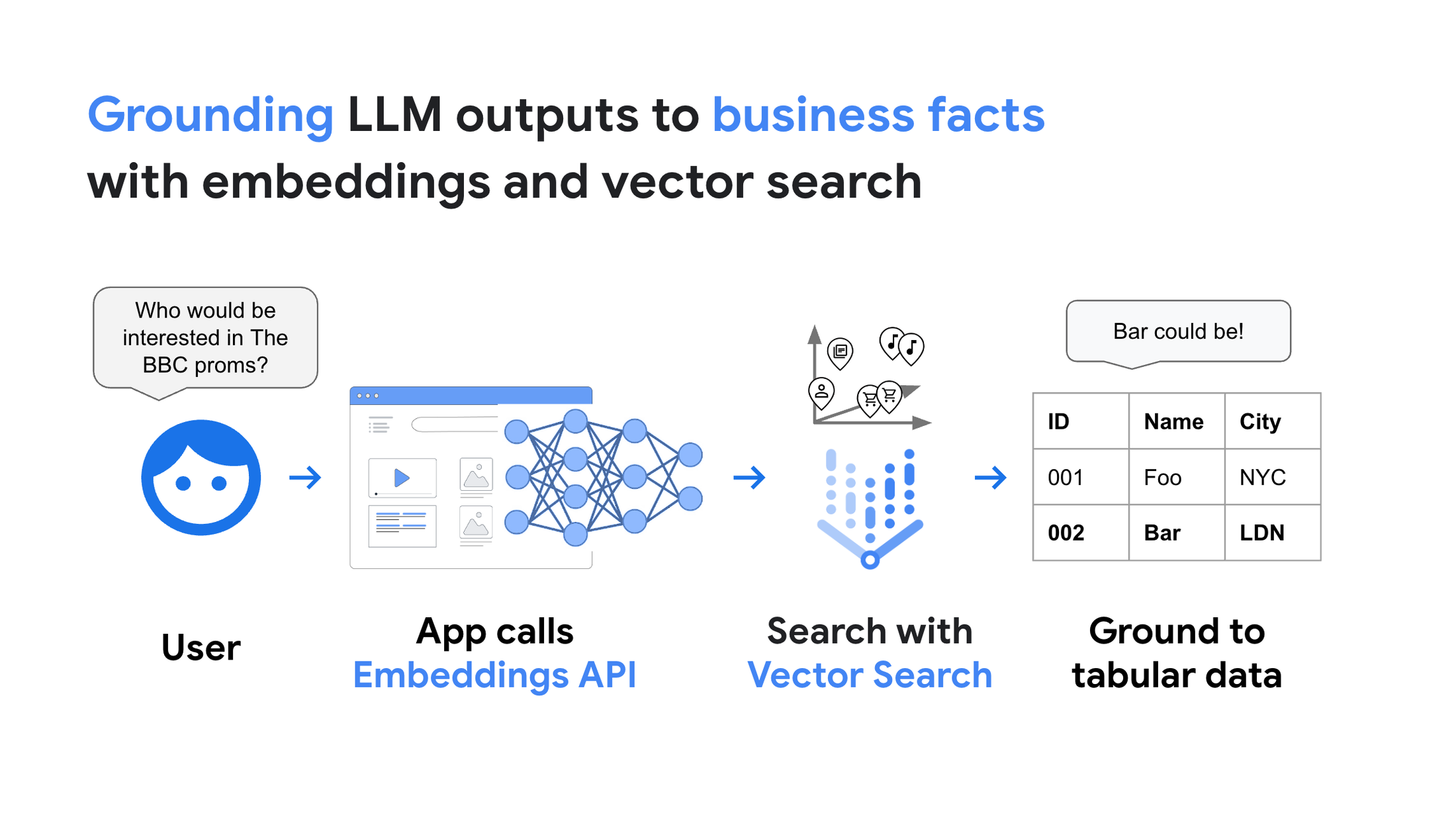
In the case of the Stack Overflow demo shown earlier, we've built a system with the following architecture.
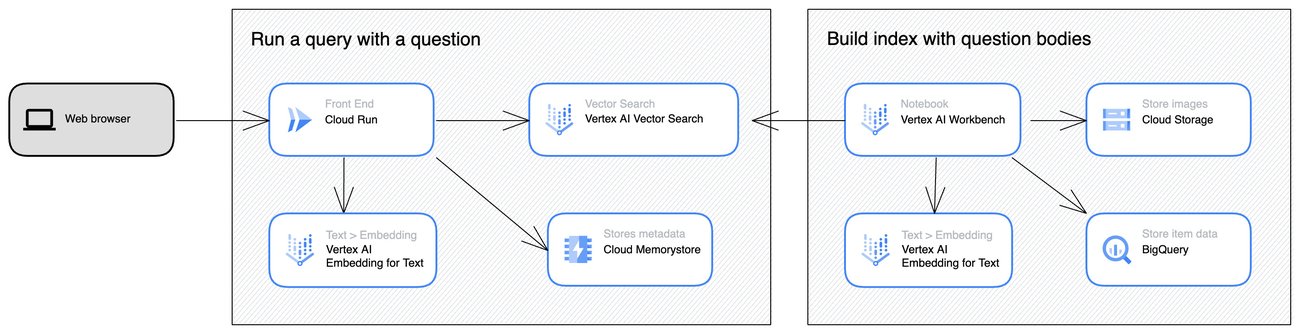
Stack Overflow semantic search demo architecture
The demo architecture has two parts: 1) building a Vector Search index with Vertex AI Workbench and the Stack Overflow dataset on BigQuery (on the right) and 2) processing vector search requests with Cloud Run (on the left) and Vector Search. For the details, please see the sample Notebook on GitHub.
Grounding LLMs with LangChain and Vertex AI
In addition to the architecture used for the Stack Overflow demo, another popular way for grounding is to enter the vector search result into the LLM and let the LLM generate the final answer text for the user. LangChain is a popular tool for implementing this pipeline, and Vertex AI Gen AI embedding APIs and Vector Search are definitely best suited for LangChain integration. In a future blog post, we will explore this topic further. So stay tuned!
How to get started
In this post, we have seen how the combination of Embeddings for Text API and Vector Search allows enterprises to use Gen AI and LLMs in a grounded and reliable way. The fine-grained semantic understanding capability of the API can bring the intelligence to information search and recommendation in a wide variety of businesses, setting a new standard of user experience in enterprise IT systems.
To get started, please check out the following resources:
- Stack Overflow semantic search demo: sample Notebook on GitHub
- Vertex AI Embeddings for Text API documentation
- Vector Search documentation


