How to implement document tagging with AutoML
Nitin Aggarwal
Head of AI Services, Google Cloud
Many businesses need to digitize photos, documents, memos, and other types of physical media to help with tasks like invoice processing, application review, and contract analysis. At Google Cloud, we provide a number of ways customers can do this, from using our pre-trained machine learning APIs, to build on our AutoML suite, to applying Document Understanding AI, our latest AI solution.
In this post, we’ll focus on one approach, using Cloud AutoML to perform document tagging for the purposes of document processing. Document tagging means identifying key value pairs from a document like responses (or values) to fields (or tags) such as customers, account numbers, totals, and more. Here, ‘tags’ are the fields that one wants to extract, and ‘values’ are the knowledge against that tag. In this solution, we’ll use AutoML to fetch important content from an image like signatures, stamps, and boxes, for processing.
Solutions of the past
A few years ago, digitizing a document meant simply scanning and storing it as an image in the cloud. Now, with better tools and techniques, and with the recent boom in ML-based solutions, it is possible to convert a physical document into structured data that can be automatically processed, and from which useful knowledge can be extracted.
Until recently, digitizing documents required the application of a rule-based methodology like using regular expressions for identifying fields, or extracting OCR from fixed field positions. But these solutions don’t always work on new documents and can be problematic with keyword-matching or text-based NLP models. Object detection and entity recognition, which gained a lot of traction in the last few years, have now led to significant improvements in this area. Cloud AutoML, our suite of AI services that let you create high-quality custom machine learning models with minimal ML expertise, is one example of that.
A GCP solution: AutoML at scale
There are a wide variety of AutoML services that can be used as a foundation to create models that solve unique business problems. In the case of document digitization, one possible architecture that can be used looks like this:
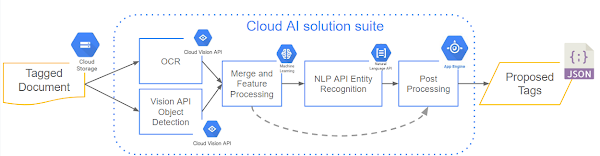
This type of architecture is not just simple to follow, but also easy to deploy in production. All components are based on existing GCP products that are highly scalable, serverless, and can be directly put in production.
Tagged document—You can use the AI Platform Data Labeling Service if you don’t already have annotated data.
OCR & object detection—This can be done by Vision API and AutoML Vision Object Detection, a recent addition to the AutoML suite of products.
Merge and feature processing—There are several different ways this can be done, like using a simple Jupyter notebook or a Python-based containerized solution.
Entity recognition—This can be done by using Entity extraction, a new feature in AutoML Natural Language, a recent addition to the AutoML suite of products
Post processing—This can be done in a similar fashion to feature processing.
The whole pipeline can be orchestrated using Cloud Composer, or can be deployed using Google Kubernetes Engine (GKE). However, some business problems, for e.g. building customized data ingestion pipeline to GCP, rules extraction from legal documents, redact sensitive information from the documents before parsing etc., require additional customizations that can be developed in addition to the above mentioned architecture. For such requirements you can contact our sales team for more details and help.
Value generation
Different ML solutions have their own business or technical benefits—and many of our customers have used solutions like this one to meet their objectives, whether it’s enhancing the user experience, decreasing operational costs, or reducing overall errors. Solutions like the one described in this post can be used across industries such as healthcare, financial services, media, and more. Here are just a few examples:
- Automatically extracting knowledge from Electronic Health Records (EHR).
- Key value pair generation from invoices.
- Field fetching from financial documents.
- Text understanding of customer complaints.
- Tagging of bank checks, tickets, and other data.
What’s next
In this age of deep learning, solutions that simplify the training process, like transfer learning, are increasingly needed. The architecture described in this post has been successfully tested and deployed to work at scale, and makes it possible to digitize documents without needing thousands of annotated images for model training.
Data variability, however, is still an important factor in any machine learning-based solution. AutoML automatically solves a lot of basic problems for variance in data, making it possible for you to use as little as a few thousand images to train a custom model.
Helping customers process their documents fits perfectly with Google’s mission to organize the world’s information and make it universally accessible and useful. We hope that by sharing this post, we can inspire more organizations to look to the cloud. Tools like Cloud AutoML Vision, Cloud AutoML Natural Language, and Cloud Storage can help you build a rich data set and improve the end-user experience.
This is a simple and targeted solution for a specific problem. For broader and more powerful document process automation and insight extraction technology, please refer to Google’s Document Understanding AI solution. AutoML is a core component of the end-to-end Document Understand AI solution, which is easy to deploy through our partners, and requires no machine learning expertise. You can learn more on our website.



