How to enrich product data with generative AI using Vertex AI
Karl Weinmeister
Director, Developer Relations
Product Information Management (PIM) is a critical process in the retail industry to manage product data, such as descriptions, images, and other attributes. In this blog post, we will show how to use Large Language Models (LLMs) with Vertex AI to enrich product data, which can improve the customer experience and the bottom line.
Product Information Management
PIM is the process of collecting, storing, and managing product information across an organization. It includes gathering data from a variety of sources, such as product catalogs, websites, and customer feedback. PIM systems then organize and normalize this data so that it can be used by other systems, such as e-commerce platforms, marketing automation tools, and product recommendations engines. The PIM market is growing rapidly, as businesses increasingly recognize the importance of having accurate and up-to-date product information.
LLMs can support the PIM process in a number of ways, including:
- Generating product descriptions: LLMs can be trained on a large corpus of product descriptions to generate new descriptions for products.
- Translating product descriptions: LLMs can be used to translate product descriptions into multiple languages.
- Extracting product attributes: LLMs can be used to extract product attributes from product descriptions, such as the product name, price, and features.
Getting started
For this demonstration, we'll use the Flipkart products dataset on Kaggle. It provides a sample of 20,000 products from the Indian e-commerce retailer Flipkart, with 15 fields including name, description, and price.
Our goal will be to improve the quality of product descriptions in the dataset. In particular, let's look for short or incomplete descriptions that can be augmented.
You can follow along with the Colab notebook. Here, we will highlight key steps but not include all of the details.
Data analysis
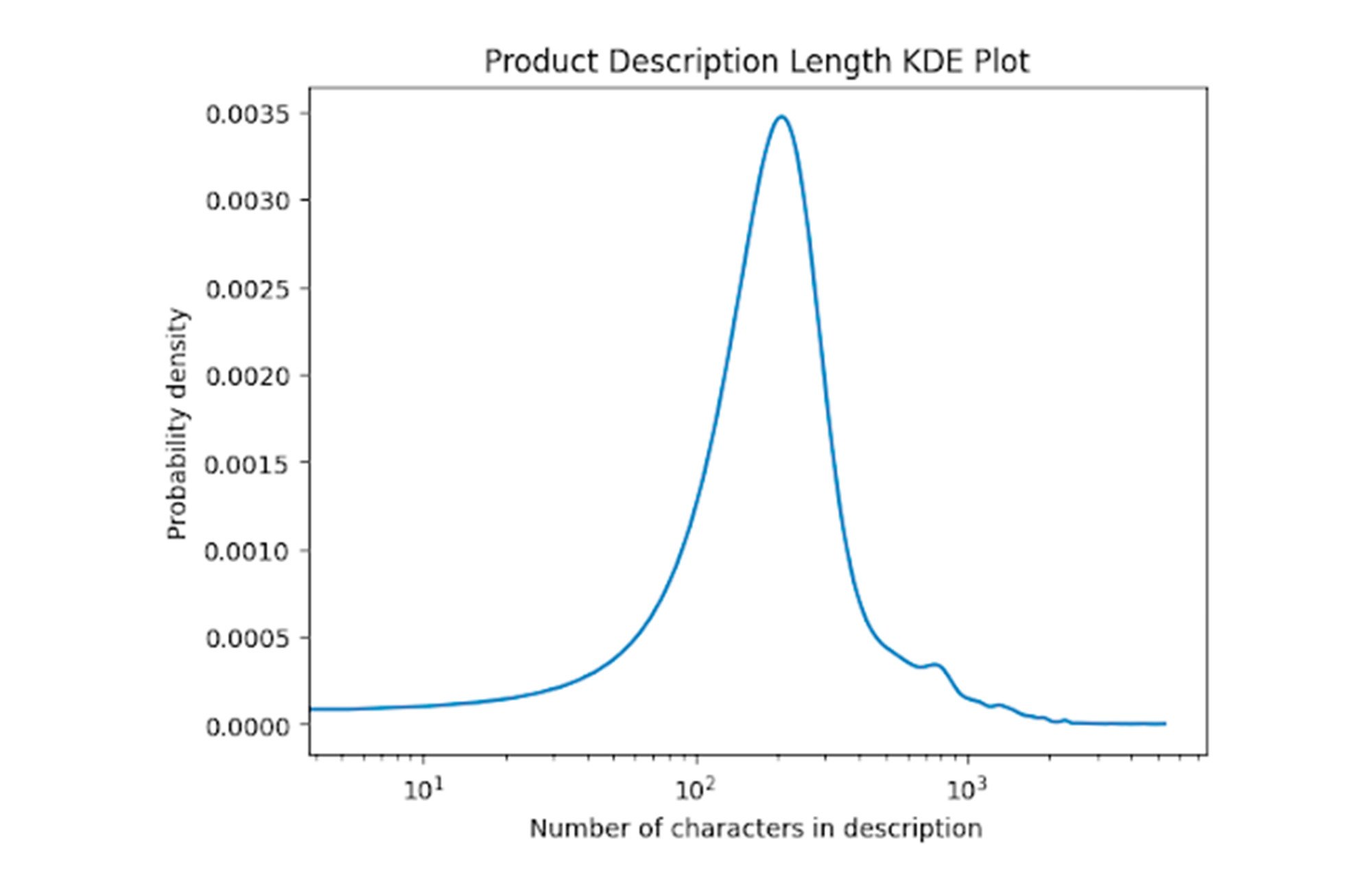
Our first step will be to understand the distribution of product descriptions. We can create a Kernel Density Estimation (KDE) plot, which can help us visualize a smoothed distribution of the data.
You may notice that we used a log scale on the X-axis, so we can more carefully inspect the left-tail of the distribution. We see that most descriptions are between 100 and 1000 characters. Let's augment the shortest 0.05% of our descriptions, setting our threshold to 93 characters.
Data preparation
We can compute that there are 13 product descriptions that can be augmented.
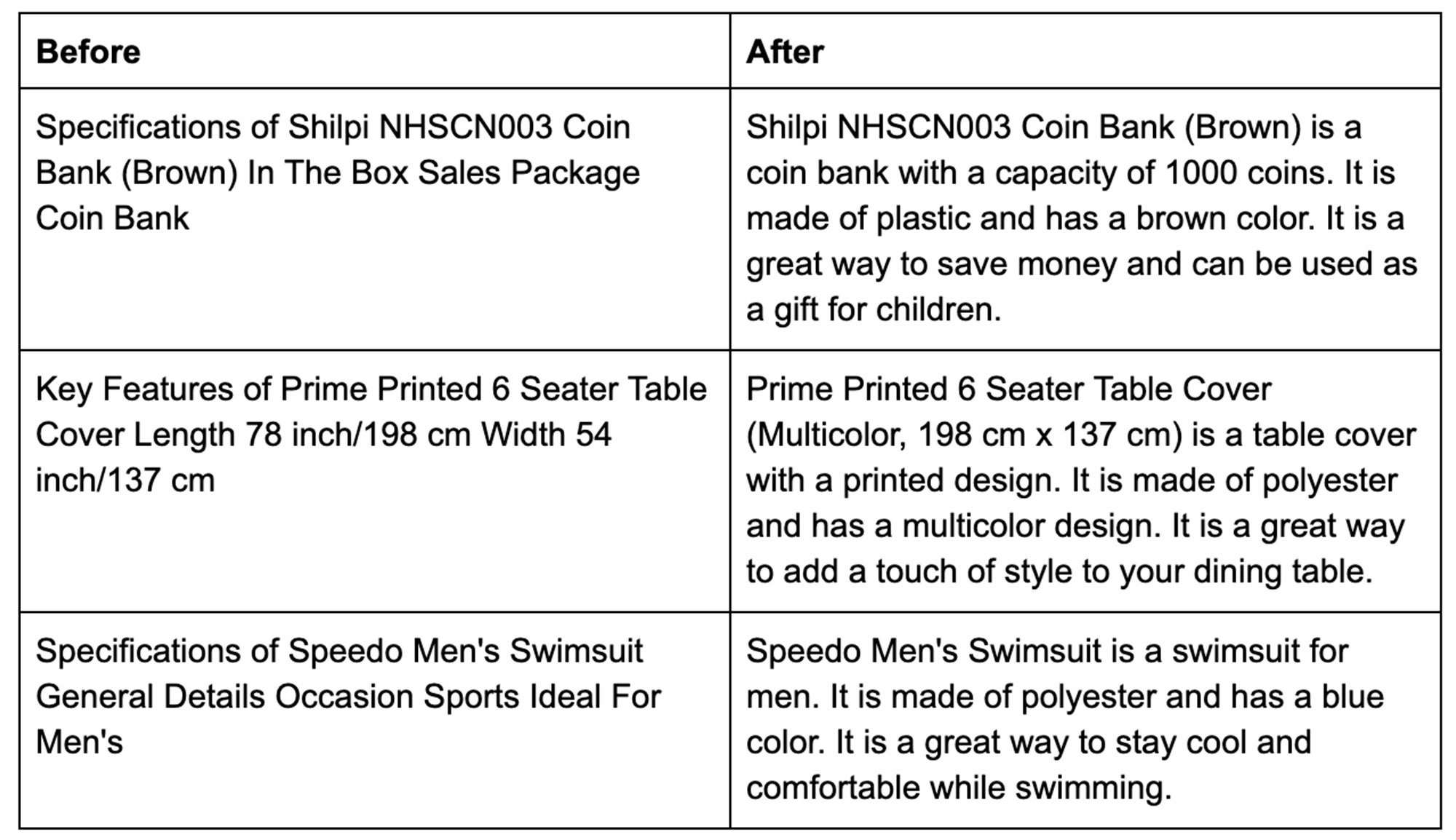
Let's take a sampling of 3 of these. Clearly, we can make improvements to the copy!
- Specifications of Shilpi NHSCN003 Coin Bank (Brown) In The Box Sales Package Coin Bank
- Key Features of Prime Printed 6 Seater Table Cover Length 78 inch/198 cm Width 54 inch/137 cm
- Specifications of Speedo Men's Swimsuit General Details Occasion Sports Ideal For Men's
It will be helpful to provide the LLM some extra context -- not just the original description, but other attributes such as name, brand, and category. We don't need to include everything, so let's filter out columns that don't help toward our goal. We can then put the results into a JSON string, so that it can be easily parsed by the model.
Prompt engineering
Our next step is to create a prompt that will instruct the model what to do. We won't go into too much depth on prompt design, but let's explore each part of the prompt we will use.
First, we'll want to be clear about our requirements — to provide compelling copy, while still being accurate. Also, we want the response to be in JSON format, so it can be easily parsed. Finally, we want to include the product unique identifier, so we can link the updated description to the original product. The product data we gathered up earlier will be embedded at the end of the prompt.
Querying the model
Now, we're ready to generate product descriptions. It will take four simple steps.
- First, import the Vertex AI SDK for Python and initialize the client with your project ID and region.
- Then, selected a pretrained text generation model from the Vertex AI Model Garden.
- Set the maximum output tokens to 1024, since we don't mind getting elaborate descriptions back.
- Query the model and see the result.
Here's our result:
[{"uniq_id": "CNBEJ9EDXWN8HQUU", "description": "Shilpi NHSCN003 Coin Bank (Brown) is a coin bank with a capacity of 1000 coins...
We see that it's a JSON structure that can be easily parsed. We can use JSON parsing functions to extract each ID and updated description, and then update the original product description.
Let's compare our results to what we had before. Quite an improvement!
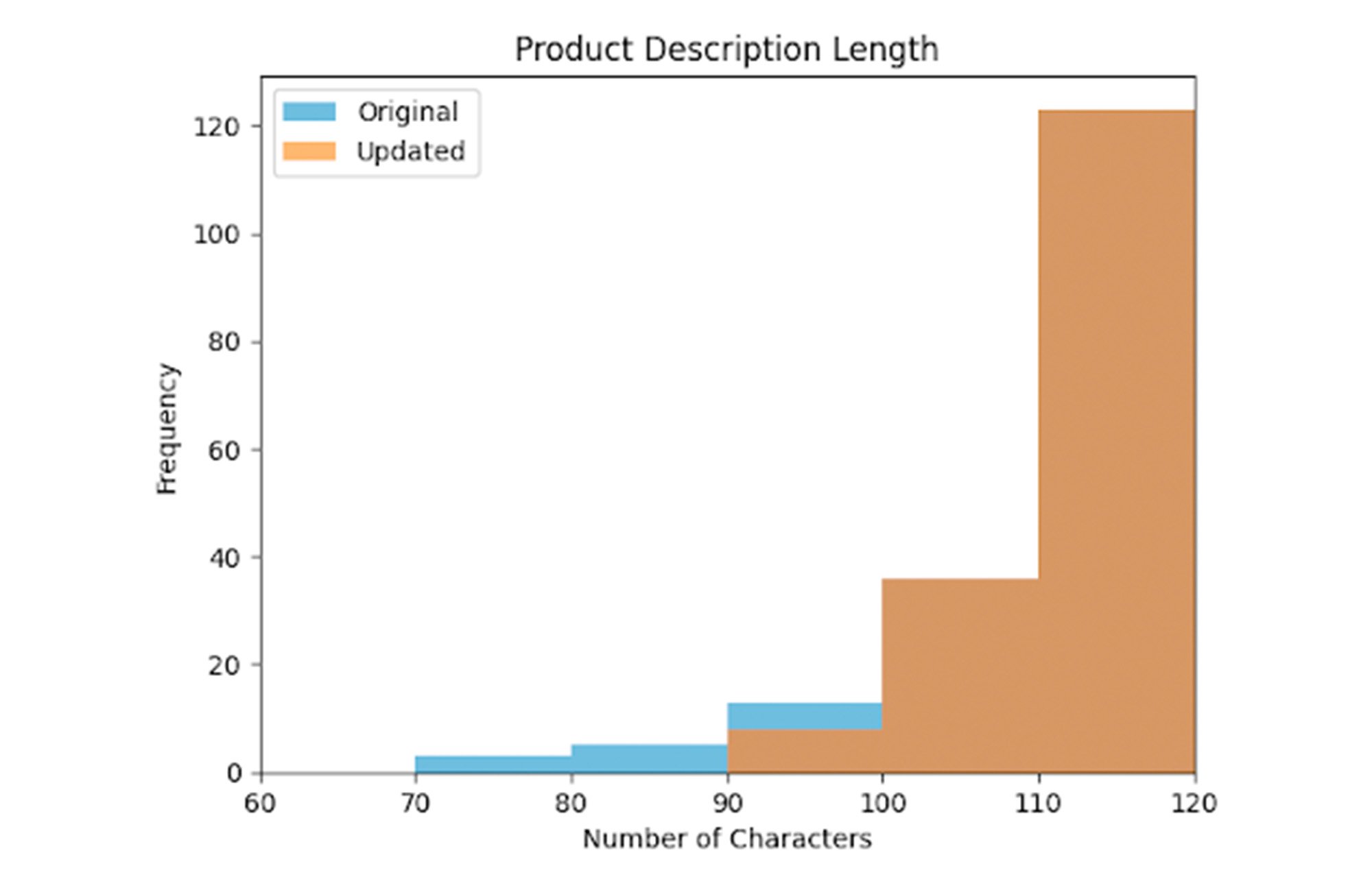
Here we see the distribution of the shorter product descriptions. We can see that we no longer have descriptions under the threshold.
Conclusion
Large Language Models can be an effective tool in improving product data quality. Consistent, accurate, and compelling product data is the cornerstone of the retail experience. We've seen in this blog post how we can easily integrate with Vertex AI services to make this happen. You can take the ideas further by capturing context from product images using Vertex AI Vision, or even create images based on the product metadata with Imagen on Vertex AI. You can find out more at our Vertex AI Generative AI and Google Cloud for Retail sites.



