G4 VMs under the hood: A custom, high-performance P2P fabric for multi-GPU workloads
Cyrill Hug
Sr. Product Manager Accelerator Software, Google
Prashanth Prakash
Software Engineer, Google
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try nowToday, we announced the general availability of the G4 VM family based on NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs. Thanks to unique platform optimizations only available in Google Cloud, G4 VMs deliver the best performance of any commercially available NVIDIA RTX PRO 6000 Blackwell GPU offering for inference and fine-tuning on a wide range of models, from less than 30B to over 100B parameters. In this blog, we discuss the need for these platform optimizations, how they work, and how to use them in your own environment.
Collective communications performance matters
Large language models (LLMs) vary significantly in size, as characterized by their number of parameters: small (~7B), medium (~70B), and large (~350B+). LLMs often exceed the memory capacity of a single GPU, including the NVIDIA RTX PRO 6000 Blackwell’s, with its 96GB of GDDR7 memory. A common solution is to use tensor parallelism, or TP, which works by distributing individual model layers across multiple GPUs. This involves partitioning a layer's weight matrices, allowing each GPU to perform a partial computation in parallel. However, a significant performance bottleneck arises from the subsequent need to combine these partial results using collective communication operations like All-Gather or All-Reduce.
The G4 family of GPU virtual machines utilizes a PCIe-only interconnect. We drew on our extensive infrastructure expertise to develop this high-performance, software-defined PCIe fabric that supports peer-to-peer (P2P) communication. Crucially, G4’s platform-level P2P optimization substantially accelerates collective communications for workloads that require multi-GPU scaling, resulting in a notable boost for both inference and fine-tuning of LLMs.
How G4 accelerates multi-GPU performance
Multi-GPU G4 VM shapes get their significantly enhanced PCIe P2P capabilities from a combination of both custom hardware and software. This advancement directly optimizes collective communications, including All-to-All, All-Reduce, and All-Gather collectives for managing GPU data exchange. The result is a low-latency data path that delivers a substantial performance increase for critical workloads like multi-GPU inference and fine-tuning.
In fact, across all major collectives, the enhanced G4 P2P capability provides an acceleration of up to 2.2x without requiring any changes to the code or workload.

Inference performance boost by P2P on G4
On G4 instances, enhanced peer-to-peer communication directly boosts multi-GPU workload performance, particularly for tensor parallel inference with vLLM, with up to 168% higher throughput, and up to 41% lower inter-token latency (ITL).
We observe these improvements when using tensor parallelism for model serving, especially when compared to standard non-P2P offerings.

At the same time, G4 coupled with software-defined PCIe and P2P innovation, significantly enhances inference throughput and reduces latency, giving you the control to optimize your inference deployment for your business needs.

Throughput or speed: G4 with P2P lets you choose
The platform-level optimizations on G4 VMs translate directly into a flexible and powerful competitive advantage. For interactive generative AI applications, where user experience is paramount, G4’s P2P technology delivers up to 41% less inter-token latency — the critical delay between generating each part of a response. This results in a noticeably snappier and more reactive end-user experience, increasing their satisfaction with your AI application.
Alternatively, for workloads where raw throughput is the priority, such as batch inference, G4 with P2P enables customers to serve up to 168% more requests than comparable offerings. This means you can either increase the number of users served by each model instance, or significantly improve the responsiveness of your AI applications. Whether your focus is on latency-sensitive interactions or high-volume throughput, G4 provides a superior return on investment compared to other NVIDIA RTX PRO 6000 offerings in the market.
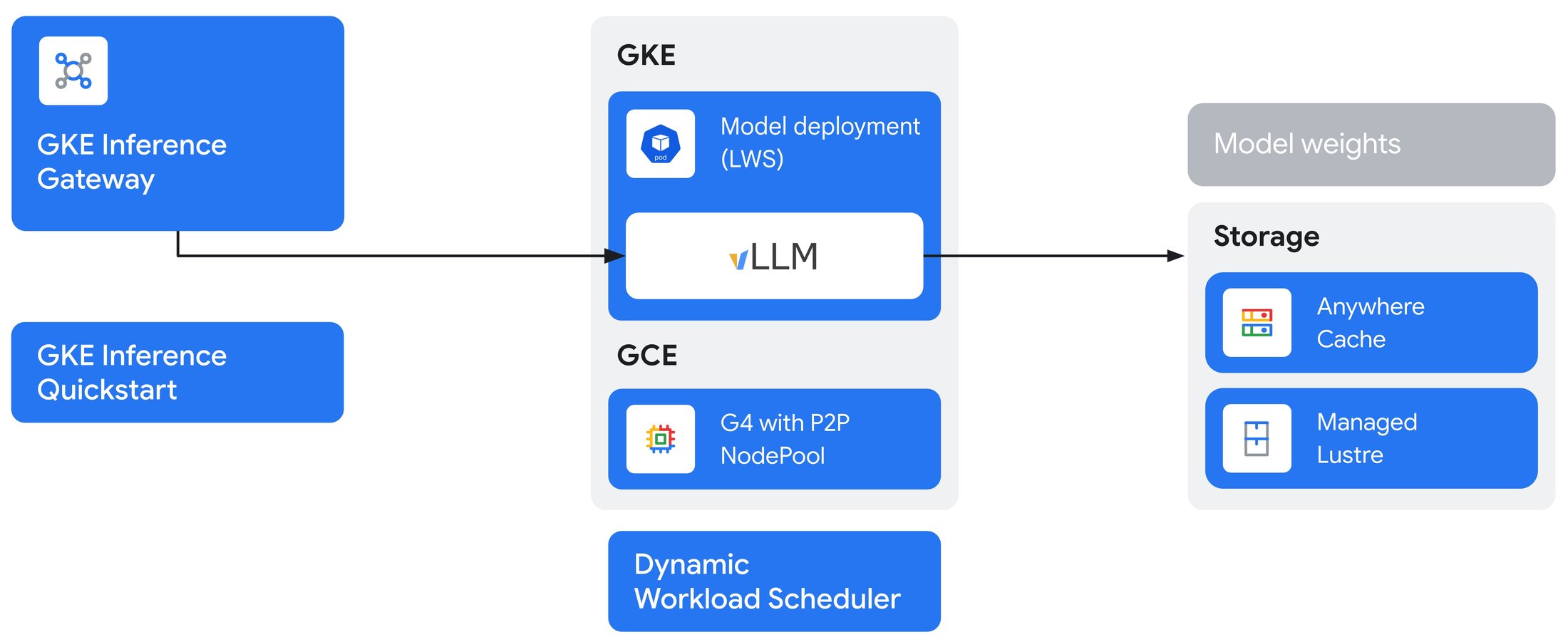
Scale further with G4 and GKE Inference Gateway
While P2P optimizes performance for a single model replica, scaling to meet production demand often requires multiple replicas. This is where the GKE Inference Gateway really shines. It acts as an intelligent traffic manager for your models, using advanced features like prefix-cache-aware routing and custom scheduling to maximize throughput and slash latency across your entire deployment.
By combining the vertical scaling of G4's P2P with the horizontal scaling of the Inference Gateway, you can build an end-to-end serving solution that is exceptionally performant and cost-effective for the most demanding generative AI applications. For instance, you can use G4's P2P to efficiently run a 2-GPU Llama-3.1-70B model replica with 66% higher throughput, and then use GKE Inference Gateway to intelligently manage and autoscale multiple of these replicas to meet global user demand.
G4 P2P supported VM Shapes
Peer-to-peer capabilities for NVIDIA RTX PRO 6000 Blackwell are available with the following multi-GPU G4 VM shapes:
For VM shapes smaller than 8 GPUs, our software defined PCIe fabric ensures path isolation between GPUs assigned to different VMs on the same physical machine. PCIe paths are created dynamically at VM creation and are dependent on the VM shape, ensuring isolation on multiple levels of the platform stack to prevent communication between GPUs that are not assigned to the same VM.
Get started with P2P on G4
The G4 peer-to-peer capability is transparent to the workload, and requires no changes to the application code or to libraries such as the NVIDIA Collective Communications Library (NCCL). All peer-to-peer paths are automatically set up during VM creation. You can find more information about enabling peer-to-peer for NCCL-based workloads in the G4 documentation.
Try Google Cloud G4 VMs with P2P from the Google Cloud console today, and start building your inference platform with GKE Inference Gateway. For more information, please contact your Google Cloud sales team or reseller.


