Moving from experimentation into production with Gemini models and Vertex AI

Saurabh Tiwary
VP & GM, Cloud AI
You might have seen the recent stat on how 61% of enterprises are running generative AI use cases in production — and with industry leaders including PUMA, Snap, and Warner Brothers Discovery speaking at today’s Gemini at Work event, our customers are bringing this momentum to life.
We’re inspired by what you – our customers — have been building. In fact, we've witnessed a staggering 36x increase in Gemini API usage and nearly 5x increase of Imagen API usage on Vertex AI this year alone — clear reinforcement that enterprises are moving from gen AI experimentation to real-world production.
In this post, we’ll answer questions about how our customers have moved from AI experimentation to production and share critical learnings, while also announcing a few exciting updates to our models and platform.
1. What are the latest Gemini and Imagen model announcements and how do they help me maximize performance without compromising on latency and costs?
At Google Cloud, our objective is to bring you the best models suited for enterprise use cases, by pushing the boundaries across performance, latency, and costs. Today’s announcements accelerate this mission with several exciting capabilities:
Updates to Gemini models: Generally available today, the newly updated versions of Gemini 1.5 Pro and Flash models deliver quality improvements in math, long context understanding, and vision. From a latency standpoint, the new version of Gemini 1.5 Flash model is nearly 2.5x faster than GPT-4o mini.
We are also making the 2M context window for Gemini 1.5 Pro model generally available, helping with complex tasks such as analyzing two-hour videos, or answering questions about very large codebases, lengthy contracts, and financial documents.
With these improvements to Gemini 1.5 Pro and Flash models, enterprises can now address more sophisticated use cases. For example, healthcare companies can leverage Gemini to potentially predict disease progression and personalize treatment plans. Finance companies can optimize investment portfolios and detect needle-in-a-haystack fraud patterns. And retailers can analyze customer data to deliver hyper-personalized recommendations.
Gemini 1.5 Pro Model Pricing Update: In August, we improved Gemini 1.5 Flash to reduce costs by up to 80%, as part of our ongoing commitment to make AI accessible for every enterprise. Now we are thrilled to bring the same improvements to Gemini 1.5 Pro, reducing costs by 50% across both input and output tokens, effective on Vertex AI on October 7, 2024.
Updates to Imagen 3: Now generally available for Vertex AI customers on the allowlist, Imagen 3 model has improved prompt understanding, instruction-following, photorealistic quality, and even greater control over text within images. We've seen nearly 5x growth in Imagen API usage on Vertex AI this year, with compelling use cases across many industries.
For example, retailers and branding agencies are using Imagen 3 to craft compelling visuals for everything from product showcases to captivating storyboards. In advertising and media, Imagen 3 is helping brands drive new levels of engagement through tailored recommendations or visuals, and we have seen creative platforms use Imagen 3 for stock photography and design inspiration.
“As a customer-centric company, Cimpress is continually focused on innovating within the creative design process to empower businesses, entrepreneurs, and all users to make an impression. One way we have been doing this is to experiment with Imagen as a means to deliver even greater options and levels of customization to our customers, whether it's generating high-quality photos, creating unique clipart for direct customer use, designing eye-catching logos, or rapidly producing professional templates. Benchmarked against our previous generative AI solution, Imagen 3 showed a 130% improvement in clearing our quality threshold.” - Maarten Wensveen, EVP & Chief Technology Officer at Cimpress.
“As the Beauty Tech champion, L’Oréal leverages science, technology and creativity to shape the future of beauty. We are pioneers in our industry and were the first beauty company to embrace Imagen for internal storyboarding and creative brainstorming. This AI tool is helping us bring our product vision in a visually stunning and efficient manner. With Imagen3, we give our digital marketing teams the possibility to generate diverse product visualizations, significantly reducing development time and expanding our creative possibilities. Imagen 3’s enhanced safety features and cost-effective managed service give us the confidence to scale image generation effectively. It has become an invaluable creative partner, empowering our teams to craft more engaging and innovative product concepts during the crucial ideation phase.” - Etienne Bertin – Chief Information Officer L’Oréal Group
Imagen 3 generates images 40% quicker than its predecessor and also comes with built-in safety features like Google DeepMind's SynthID watermarking. In the coming weeks, you will also be able to quickly insert or remove objects and make background changes. In addition, powerful new customization features will allow you to specialize Imagen 3 for specific types of images, subjects, products, and styles.
We are committed to giving customers choice with an open AI ecosystem that includes our first party models, third party, and open models. We recently announced support on Vertex AI for new models from Meta, Mistral AI, and AI21 Labs, helping ensure Vertex AI is the best place to build gen AI apps and agents across use cases and model choices.
2. How can I make sure my AI outputs are reliable and meaningful?
Driving measurable value in AI goes beyond just providing great models. It's about controlling those models to produce the results you need. That’s why our investments in Vertex AI are centered around giving you a platform that makes it easy to access, evaluate, customize, and deploy these models at scale. Today, we're introducing several new capabilities to Vertex AI that make it easier than ever to shape and refine your AI outputs:
Precisely control your outputs and costs
-
We're making Controlled Generation generally available, giving you fine-grained control over your AI outputs so they can be specifically tailored to fit downstream applications. Most models cannot guarantee the format and syntax of their outputs, even with specified instructions. Vertex AI Controlled Generation lets you choose the desired output format via pre-built options like JSON and ENUM, or by defining custom formats.
-
With Batch API (currently in preview), you can send a large number of multimodal prompts in a single batch request for speeding up developer workflows at 50% of the costs of a standard prompt. This is especially useful for non-latency sensitive text prompt requests, supporting use cases such as classification and sentiment analysis, data extraction, and description generation.
Tailor models for your use cases
-
In the coming weeks, we will make supervised fine tuning (SFT) for Gemini 1.5 Flash and Pro generally available. SFT allows you to tune the model to be more precise for your enterprise task.
-
Deploying large language models can be a resource-intensive challenge. With distillation techniques in Vertex AI, now available in preview, you can leverage the power of those large models while keeping your deployments lean and efficient. Train smaller, specialized models that inherit the knowledge of their larger Gemini model, achieving comparable performance with the flexibility of self-hosting your custom model on Vertex AI.
Master and manage your prompts
-
Now in preview, Vertex AI’s Prompt Optimizer helps you avoid the tedious trial-and-error of prompt engineering. Based on Google Research’s publication on automatic prompt optimization (APO) methods, Prompt Optimizer adapts your prompts using the optimal instructions and examples to elicit the best performance from your chosen model. Our prompt strategies guide helps you make the models more verbose and conversational.
-
Vertex AI’s Prompt Management SDK allows users to retrieve and organize prompts and will be generally available in coming weeks. It lets you version prompts, restore old prompts, and generate suggestions to improve performance.
Ground your AI with the right information
-
We are the only provider to offer Grounding with Google Search, letting you ensure fresh outputs by augmenting model responses with real-time information and the vastness of the world’s knowledge. We also launched dynamic retrieval for Grounding with Google Search, which further optimizes cost and performance by detecting when to rely on training data and when to rely on search grounding. What’s more, we're partnering with industry leaders like Moody's, MSCI, Thomson Reuters, and ZoomInfo to soon provide access to specialized third-party datasets.
-
Function calling is a built-in feature of the Gemini API that translates natural language into structured data and back. Now, with multimodal function calling, your agents can also execute functions where your user can provide images, along with text, to help the model pick the right function and function parameters to call.
3. How can I deploy and scale my AI investments with confidence?
Reliability and safety are paramount for enterprises. To meet these needs, we're making not only cutting-edge innovations in models, but also large strides in helping customers execute a “your AI, your way” strategy:
Evaluate with confidence
While leaderboards and reports offer insights into overall model performance, they don't reveal how a model handles your specific needs. Now generally available, the Gen AI Evaluation Service helps you define your own evaluation criteria, for a clear understanding of how well generative AI models and applications align with your unique use case.
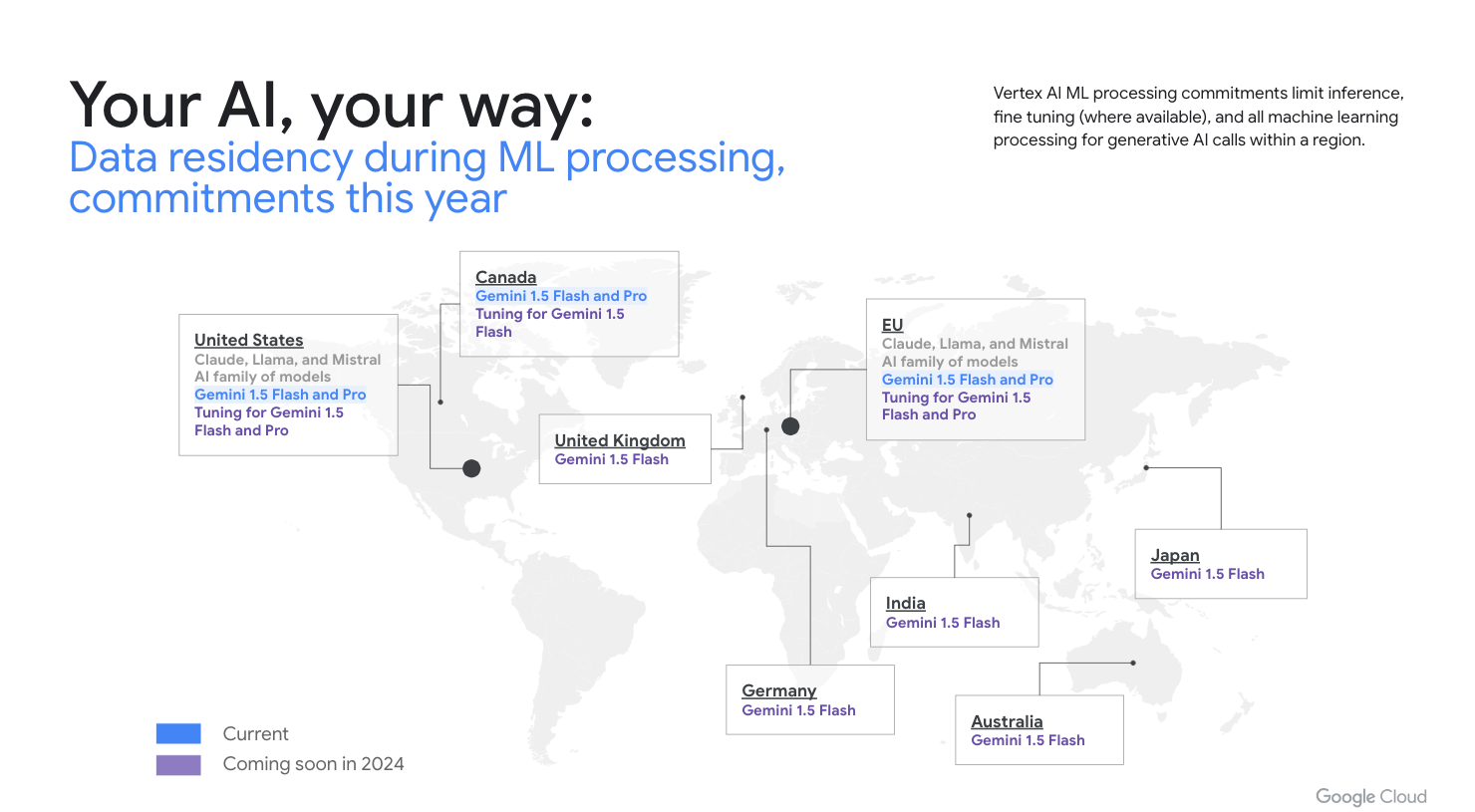
Your AI, your way, with data residency
We offer two types of data residency commitments: at-rest (storing your data only in the specific geographic locations you select), and during ML processing (performing machine learning processing of your data — like prompt ingestion, inference, and output generation — within the same specific region or multi-region where it's stored). We recently expanded ML processing commitments to Canadian organizations, and we are continuously expanding our data residency commitments across the globe, including ongoing work to grow our in region ML processing commitments to Japan and Australia in the coming weeks.
The bottom line
These enhancements are a direct response to what you, our customers, have been asking for. Google Cloud is your partner in transforming AI aspirations into tangible results. We're committed to providing the best models, an open and flexible platform, and the tools you need to innovate, deploy, and scale with confidence. Whether you're taking your first steps into the world of AI or ready to launch and expand AI solutions, check out our sessions at Gemini at Work for the insights and resources you need.



