Discover Card: How we designed an experiment to evaluate conversational experience platforms
John Coyne
Senior Software Engineer, Discover Financial Services
[Editor’s note: Today’s blog post comes from John Coyne, senior software engineer at Discover Financial Services. Discover is developing a conversational experience platform with the help of Dialogflow Enterprise Edition.]
Our mission is to help people spend smarter, manage debt better and save more, by providing banking and credit products that help people achieve their goals. But this mission isn’t possible without customer service that truly meets their needs. So we’re continuously looking for ways to improve customer satisfaction.
One way we’re doing this is by evolving our digital service channels—like our in-app mobile messaging—to serve our more digital-centric consumers. Through AI and conversational automation we hope to improve the speed and experience of these channels. We know time is valuable to our customers, and AI can be a tool that gives more of this valuable currency back to them.
To find the right AI solution to help us evolve our digital service experience, we compared a number of options and ultimately decided on Dialogflow Enterprise Edition as our development platform. In this post, I’ll give you an overview of our methodology for comparing natural language understanding accuracy based on our own use case. Anyone doing a similar comparison should be able to apply or be inspired by the same principles.
How we designed our experiment
Based on our own internal data, we knew the top 10-20 questions that customers ask via our mobile messaging feature, and that many of those interactions could be automated to help them get accurate answers in the fastest amount of time.
It was important to us to thoroughly test the best available platforms for this requirement, which included many of the public cloud providers. To do that, we wanted to build a model that would let us quickly test hundreds of iterations with a feedback loop that would help the testing process. In conjunction with performance testing, we also started designing the solution with security and customer satisfaction as key drivers in ensuring success.
In designing the experiment, we decided to test and record experiments around intent detection. In conversational tech lingo, an intent represents a mapping between the intention behind a user request (e.g. “update address”) and what action should be taken by your bot (e.g. directing the user to the appropriate form or documentation). By making intent detection our main metric for evaluating platforms, we were essentially asserting that if a bot can’t detect intents accurately, then the user experience is guaranteed to be poor.
In evaluating performance for intent detection, four core metrics were generated on a per-intent basis:
True positives: Expected Intent equals i and Detected Intent equals i
True negatives: Expected Intent does not equal i and Detected Intent does not equal i
False positives: Expected Intent does not equal i and Detected Intent equals i
False negatives: Expected Intent equals i and Detected Intent does not equal i
For our purposes, we wanted to minimize false positives. We would rather have the bot say, "I don't know what you mean" (or route to an agent), rather than supply an incorrect response.
We used two advanced metrics (both measured from 0.0 – 1.0) to gain more insight from the core metrics described above:
Precision: Precision can be summarized as: “Of the total number of tests where (i) was detected, what percentage were correct?” We used this metric to determine if we had problems with false positives--i.e., the bot detects an intent, but the wrong one.
Recall: Recall can be defined as: “Of the total number of tests where (i) was expected, what percentage were detected correctly as (i)?” We used this metric to determine if our intent was too narrowly defined, and was missing messages it was intended to pick up.
These metrics are complementary for the purpose of measuring performance. For example, Precision would be 1.0 with only one true positive as long as no false positives are present. But if Recall is low for the same intent, that means it is missing true positives as well as false positives. In this scenario, the bot does not add much value since it misses most messages entirely, even though it does a good job at avoiding incorrect guesses.
The training process
We started with a labeled dataset and ran hundreds of tests with variations of phrases. These phrases include requests like “I would like to pay my balance” and “What is my balance”. We understood that in being able to correctly identify roughly the top 10-20 intents, most customer requests could be fulfilled. Also, in identifying certain intents that would be more complex to resolve, we could identify when to route the request to a qualified live agent to ensure the best possible customer experience.
The following diagram illustrates an overview of the training process, which is also summarized below.
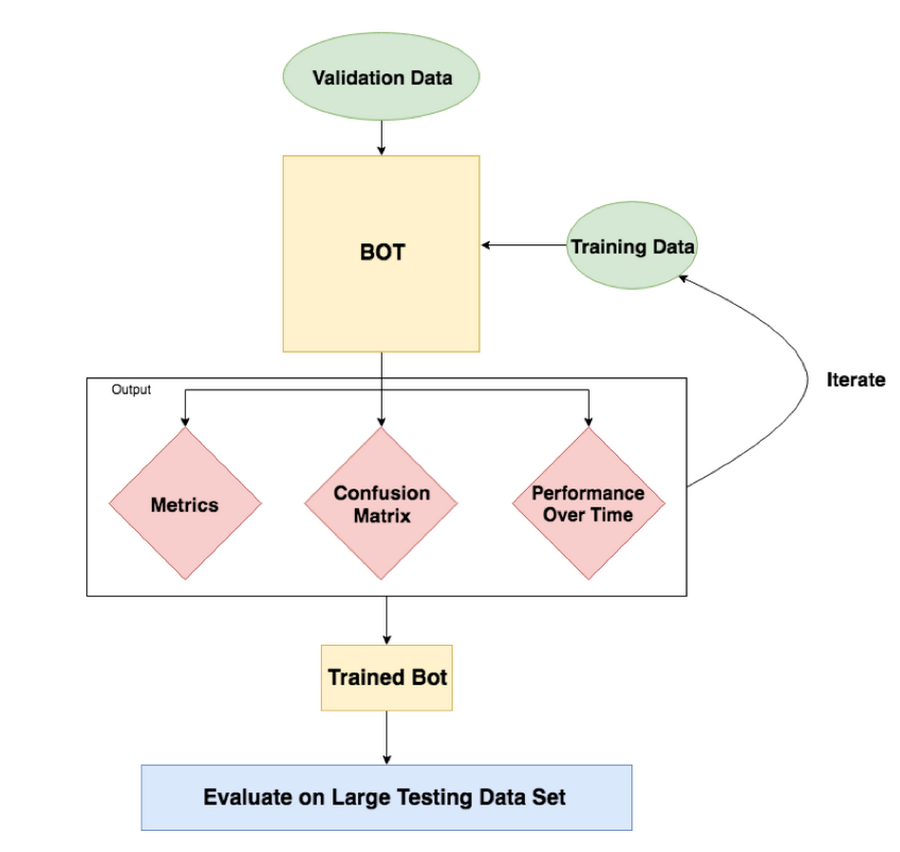
Our process for adding new intents and improving the performance was an iterative one. Using a subset of existing messages as a starting point, we created an initial set of utterances, known as the Training Data, to train the bot. We then used a different subset of messages, which had the expected intent labeled, as input to the bot for intent detection. The expected intent was compared to the detected intent and used in calculating the metrics as well as generating a confusion matrix. After performing some analysis, the Training Data would be updated and the process would be executed again until an optimal output is achieved.
The following diagram is a sample of one of our confusion matrices.
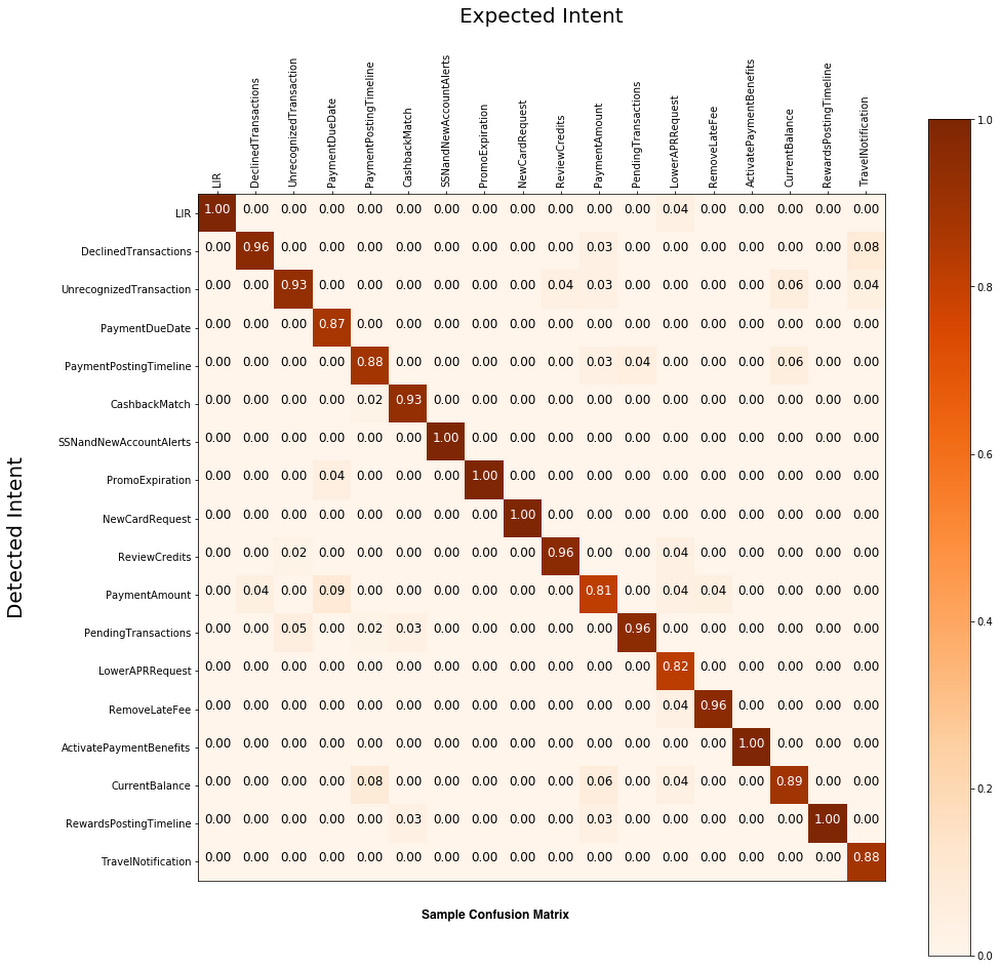
As mentioned above, using a confusion matrix was a big help during the training process. In our matrix, one axis showed the expected intent, and the other the detected intent. Having this visualization made it easy to determine which intents were too similarly defined, suggesting the need to remove overlap. In one instance, we had to combine two intents that proved to be too difficult to detect independently.
Our results
After producing the best-trained model we could for each AI solution we were evaluating, we used the metrics to help us make an informed decision.
The outcomes of all the iterations in this test were the most important part of the selection process. We found that Dialogflow had the best accuracy (precision + recall) and, at the time of testing, it could generate confidence scores and adjustable confidence thresholds to minimize false positives compared to other products on the market. In a production environment, having adjustable confidence thresholds influences whether the bot will provide an answer to a customer or transfer the conversation to a live agent. This capability was important for our objectives.
Based on the accuracy we found using Dialogflow and its support for adjustable confidence thresholds, we were confident selecting it as our conversational experience platform. With development underway, we’re now looking to increase our coverage of detectable intents, increase our channels of communication, and eventually roll out this functionality to users. Best of all, the results of implementing conversational experiences will be seamless and will make the customer experience better through faster and more accurate responses.



