Cloud AI helps you train and serve TensorFlow TFX pipelines seamlessly and at scale
Anand Iyer
Group Product Manager, Google Cloud
Last week, at the TensorFlow Dev Summit, the TensorFlow team released new and updated components that integrate into the open source TFX Platform (TensorFlow eXtended). TFX components are a subset of the tools used inside Google to power hundreds of teams’ wide-ranging machine learning applications. They address critical challenges to successful deployment of machine learning (ML) applications in production, such as:
- The prevention of training-versus-serving skew
- Input data validation and quality checks
- Visualization of model performance on multiple slices of data
A TFX pipeline is a sequence of components that implements an ML pipeline that is specifically designed for scalable, high-performance machine learning tasks. TFX pipelines support modeling, training, serving/inference, and managing deployments to online, native mobile, and even JavaScript targets.
In this post, we‘ll explain how Google Cloud customers can use the TFX platform for their own ML applications, and deploy them at scale.
Cloud Dataflow as a serverless autoscaling execution engine for (Apache Beam-based) TFX components
The TensorFlow team authored TFX components using Apache Beam for distributed processing. You can run Beam natively on Google Cloud with Cloud Dataflow, a seamless autoscaling runtime that gives you access to large amounts of compute capability on-demand. Beam can also run in many other execution environments, including Apache Flink, both on-premises and in multi-cloud mode. When you run Beam pipelines on Cloud Dataflow—the execution environment they were designed for—you can access advanced optimization features such as Dataflow Shuffle that groups and joins datasets larger than 200 terabytes. The same team that designed and built MapReduce and Google Flume also created third-generation data runtime innovations like dynamic work rebalancing, batch and streaming unification, and runner-agnostic abstractions that exist today in Apache Beam.
Kubeflow Pipelines makes it easy to author, deploy, and manage TFX workflows
Kubeflow Pipelines, part of the popular Kubeflow open source project, helps you author, deploy and manage TFX workflows on Google Cloud. You can easily deploy Kubeflow on Google Kubernetes Engine (GKE), via the 1-click deploy process. It automatically configures and runs essential backend services, such as the orchestration service for workflows, and optionally the metadata backend that tracks information relevant to workflow runs and the corresponding artifacts that are consumed and produced. GKE provides essential enterprise capabilities for access control and security, as well as tooling for monitoring and metering.
Thus, Google Cloud makes it easy for you to execute TFX workflows at considerable scale using:
- Distributed model training and scalable model serving on Cloud ML Engine
- TFX component execution at scale on Cloud Dataflow
- Workflow and metadata orchestration and management with Kubeflow Pipelines on GKE
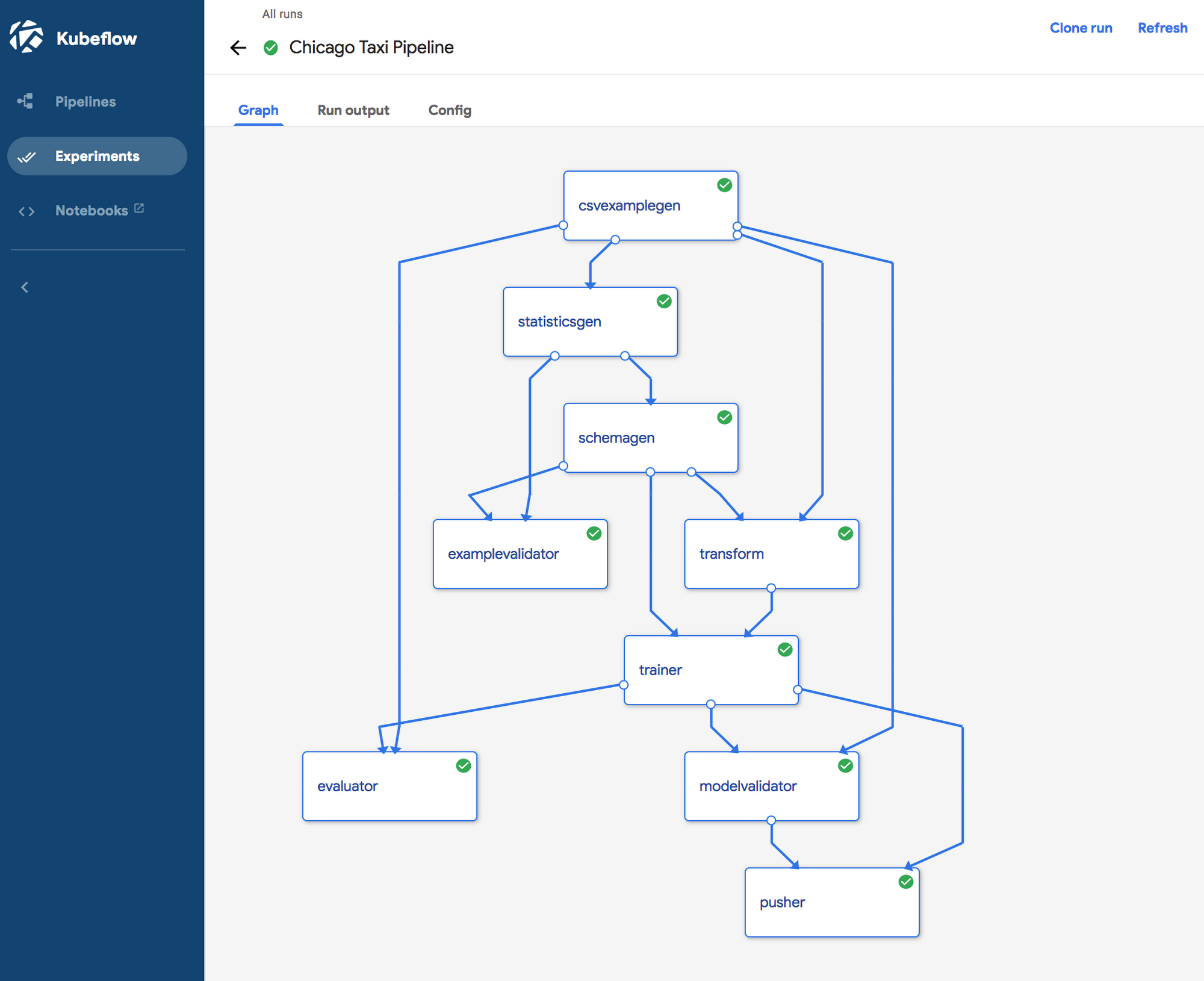
The Kubeflow Pipelines UI shown in the above diagram makes it easy to visualize and track all executions. For deeper analysis of the metadata about component runs and artifacts, you can host a Jupyter notebook in the Kubeflow cluster, and query the metadata backend directly. You can refer to this sample notebook for more details.
At Google Cloud, we work to empower our customers with the same set of tools and technologies that we use internally across many Google businesses to build sophisticated ML workflows. To learn more about using TFX, please check out the TFX user guide, or learn how to integrate TFX pipelines into your existing Apache Beam workflows in this video.
Acknowledgments:
Sam McVeety, Clemens Mewald, and Ajay Gopinathan also contributed to this post.


