Accelerate Ray in production with new Ray Operator on GKE
Winston Chiang
Product Manager
Andrew Sy Kim
Staff Software Engineer, Google
The AI field is constantly evolving. With recent advancements in generative AI in particular, models are larger and more complex, pushing organizations to distribute tasks efficiently across more machines. One powerful approach is to run ray.io, an open-source framework for distributed AI/ML workloads, on Google Kubernetes Engine (GKE), our managed container orchestration service. To make that pattern super easy to implement, you can now enable declarative APIs to manage Ray clusters on GKE with a single configuration option!
Ray provides a simple API to seamlessly distribute and parallelize machine learning tasks, while GKE provides a scalable and flexible infrastructure platform that simplifies application management and improves resource utilization. Together, GKE and Ray offer scalability, fault tolerance, and ease of use for building, deploying, and managing Ray applications. Furthermore, the built-in Ray Operator on GKE simplifies the initial setup and guides users towards best practices for running Ray in a production environment. It is built with day-2 operations in mind, with integrated support for Cloud Logging and Cloud Monitoring to enhance the observability of your Ray applications on GKE.
"Ray Operator on GKE has transformed our workflow. We've slashed maintenance time and now spin up Ray clusters in 30 minutes – a task that used to take days. It's a game-changer." - Mengliao (Mike) Wang, Geotab
See our previous blog post Why GKE for your Ray AI workloads? to learn more about the benefits of running Ray on GKE.
Getting started
In the Google Cloud console, when creating a new GKE Cluster, select the feature checkbox to ‘Enable Ray Operator.’ With a GKE Autopilot Cluster, this can be found in ‘Advanced Settings’ under ‘AI and Machine Learning.’
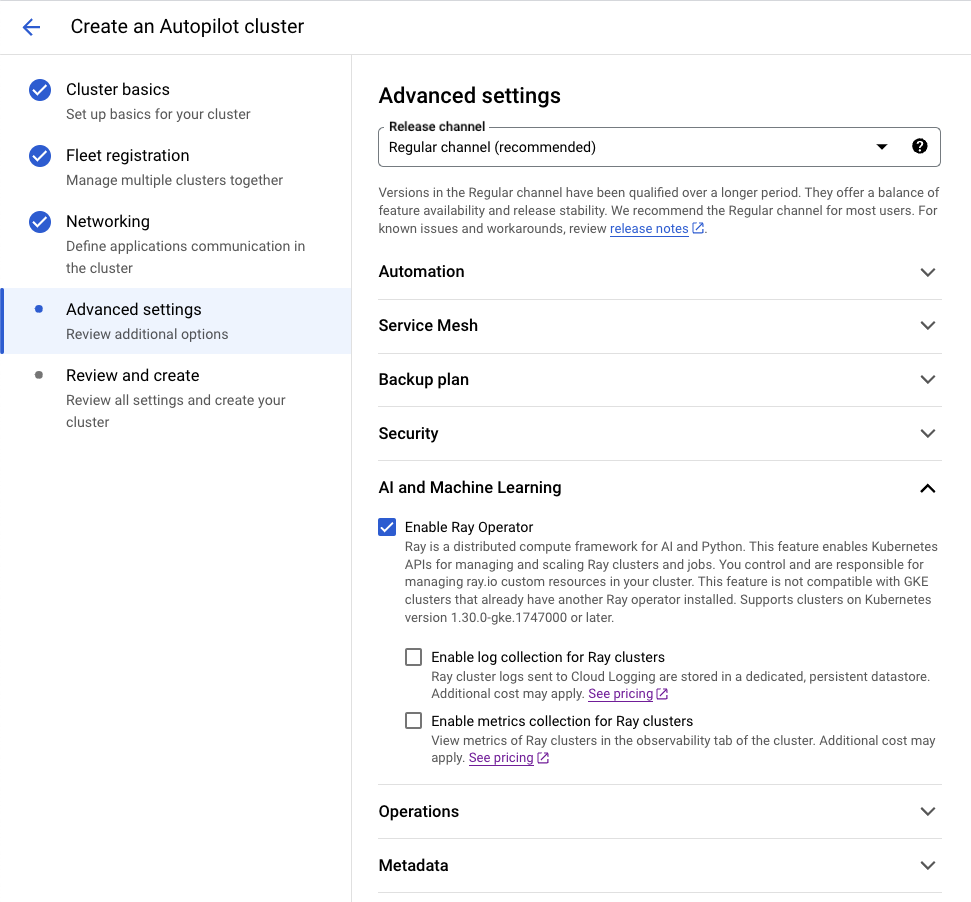
With a Standard Cluster, you can find the Enable Ray Operator feature checkbox in the ‘Features’ Menu under ‘AI and Machine Learning.’
To use the gcloud CLI, you can set an addons flag as following:
To use Terraform, you can enable the addon as follows:
Once enabled, GKE hosts and manages the Ray Operator on your behalf. Your cluster will be ready to create Ray Clusters and run Ray applications after cluster creation.
You can find examples for using Ray to serve large language models in our documentation. Or see how to train a model with Ray and Pytorch.
Logging and monitoring
Effective logging and metrics are essential when deploying Ray in production. The GKE Ray Operator offers optional features that automate the collection of logs and metrics, seamlessly storing them in Cloud Logging and Cloud Monitoring for easy access and analysis.
Enabling log collection ensures Ray logs are automatically captured and stored in Cloud Logging, encompassing all logs from both the Ray cluster Head node and Worker nodes. This feature centralizes log aggregation across all your Ray clusters, ensuring that even if the Ray cluster is shut down — intentionally or unexpectedly — the generated logs are preserved and readily searchable.
Enabling metrics collection allows GKE to gather all system metrics exported by Ray by leveraging Managed Service for Prometheus. System metrics are vital for monitoring the performance of your resources and quickly identifying errors. This comprehensive visibility is particularly crucial when dealing with expensive infrastructure such as GPUs. Cloud Monitoring makes it simple to create dashboards and set alerts, keeping you informed about the health of your Ray resources.
* Enabling logging and monitoring capabilities with the Ray Operator may incur additional costs. Refer to Google Cloud Observability pricing for more details.
TPU support
Tensor Processing Units (TPUs) are purpose-built hardware accelerators that dramatically speed up the training and inference of large machine learning models. With our AI Hypercomputer architecture, it’s easy to combine Ray with TPUs, to seamlessly scale your high-performance ML applications.
The GKE Ray Operator streamlines TPU integration by managing admission webhooks for TPU Pod scheduling and adding the necessary TPU environment variables for frameworks like JAX. It also supports autoscaling for both single-host and multi-host Ray clusters.
To see this in action, check out the example on deploying a Ray Serve application with a Stable Diffusion model and TPUs on GKE. For further information, consult the Ray documentation on TPUs.
Decrease startup latency
Minimizing start-up latency is crucial when running AI workloads in production, both for maintaining uptime and maximizing the use of costly hardware accelerators. The GKE Ray Operator, combined with other GKE features, can dramatically reduce this start-up time.
Hosting your Ray images on Artifact Registry and enabling image streaming can lead to substantial reductions in the time it takes to pull images for your Ray clusters. Large dependencies, often necessary for machine learning, can result in bulky container images that take several minutes to pull. Image streaming can cut this image pull time significantly, see Use Image streaming to pull container images for more details.
You can also enable GKE secondary boot disks to preload model weights or container images onto new nodes. This capability, in combination with image streaming, can lead to a 29X faster start-up time for your Ray applications, leading to better utilization of your hardware accelerators. See Use secondary boot disks to preload data or container images for more details.
Scale Ray in production today
Keeping up with the rapid advancements in AI requires a platform that scales alongside your workloads while offering a streamlined Pythonic experience that your AI developers are familiar with. Ray on GKE delivers this powerful combination of usability, scalability, and reliability. With the GKE Ray Operator, getting started and implementing best practices for scaling Ray in production is easier than ever.
To learn more and get started, check out the Ray on GKE user guides.



