최소한의 다운타임으로 테라바이트 규모의 데이터베이스를 Cloud SQL로 연속적 마이그레이션
Shreyasi Kalgutkar
Big Data & Analytics Consultant, Google Cloud Professional Services
Rudresha Murthy
Technical Director, Symantec Endpoint Security Division, Broadcom
* 본 아티클의 원문은 2021년 4월 13일 Google Cloud 블로그(영문)에 게재되었습니다.
2019년 후반 Broadcom이 Symantec Enterprise 보안 사업부를 인수했을 때 Symantec Endpoint Security Complete 제품을 포함하여 Symantec 워크로드를 Google Cloud로 이동하는 전략적 결정을 내렸습니다. 이것은 Symantec의 엔드포인트 보호를 위해 클라우드에서 관리되는 SaaS 버전에 해당하며, 기존 및 모바일 엔드포인트 간의 고급 위협에 대해 규모에 맞는 보호, 감지, 응답 기능을 제공합니다.
사용자를 방해하지 않고 워크로드를 이동하기 위해 Broadcom은 여러 데이터베이스에 있는 테라바이트 규모의 데이터를 Google Cloud로 마이그레이션해야 했습니다. 이 블로그에서는 테라바이트 규모의 데이터를 Cloud SQL로 연속적으로 마이그레이션하기 위한 몇 가지 접근방법과 다운타임을 최소화하면서 이러한 대규모 마이그레이션을 계획하고 실행할 수 있었던 Broadcom 사례를 살펴보고자 합니다.
Broadcom의 데이터 마이그레이션 요구사항
- 테라바이트 규모: 기본 요구사항은 총 크기가 10TB를 넘는 40개 이상의 MySQL 데이터베이스를 마이그레이션하는 것이었습니다.
- 최소한의 다운타임: SLA 요구사항에 따라 데이터베이스 컷오버로 인한 다운타임을 10분 이내로 제한해야 했습니다.
- 상세 스키마 선택: 또한 복제 파이프라인 필터로 테이블 또는 데이터베이스를 선택적으로 포함하고 제외해야 했습니다.
- 다중 소스 및 다중 대상: 기존의 단일 소스 및 단일 대상 복제 시나리오는 여기에 충분하지 않았습니다. 아래 표시된 Broadcom의 복잡한 시나리오를 확인해 보세요.
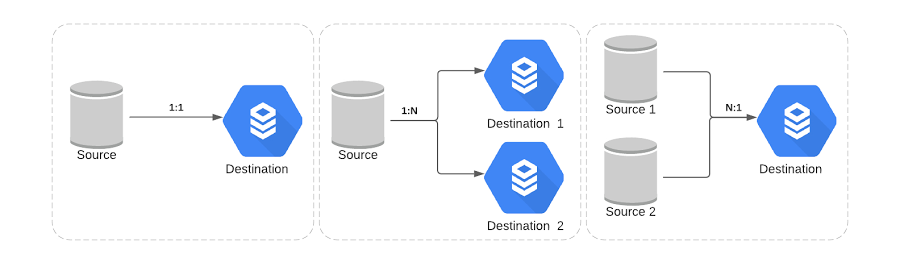
연속적인 데이터 마이그레이션 설정 방법
Broadcom은 데이터베이스를 Google Cloud로 마이그레이션하기 위해 다음 단계를 수행했습니다.
1단계: 일회용 덤프 및 복원
Broadcom은 고유 mysqldump에 대한 초기 스냅샷을 위해 멀티스레드 기반의 병렬 덤프 및 복원을 지원하는 mydumper/myloader 도구를 사용했습니다.
2단계: 연속적인 복제 파이프라인
Google은 데이터 마이그레이션을 위한 연속 복제를 달성하기 위해 두 가지 접근방법을 제공합니다.
- 접근방법 A: Database Migration Service
Google은 온프레미스 또는 다른 클라우드 제공업체와 같은 외부 소스로부터 Cloud SQL로 데이터를 마이그레이션할 수 있도록 최근에 이 관리형 서비스를 출시했습니다. 이 서비스는 네트워킹 워크플로를 효율화하고, 초기 스냅샷 및 지속적인 복제를 관리하고, 마이그레이션 작업의 상태를 알려줍니다. - 접근방법 B: 외부 서버 복제
이 프로세스를 사용하면 소스 데이터베이스 서버(기본 서버)의 데이터를 다른 데이터베이스(보조 서버)로 연속적으로 복사할 수 있게 됩니다. 자세한 내용은 MySQL용 Cloud SQL로 마이그레이션을 위한 권장사항 동영상을 확인하세요.
Broadcom의 데이터베이스 마이그레이션 사례
Broadcom의 고유 요구사항을 처리하고 데이터 마이그레이션 중 더 세밀한 제어 수준을 제공하기 위해 Broadcom과 Google Cloud 전문 서비스팀은 저장 프로시저가 래핑된 커스텀 집합으로 증강된 접근방법 B를 선택하기로 함께 결정했습니다.
다음 솔루션 다이어그램에서 이러한 데이터 마이그레이션 프로세스를 확인해 보세요.
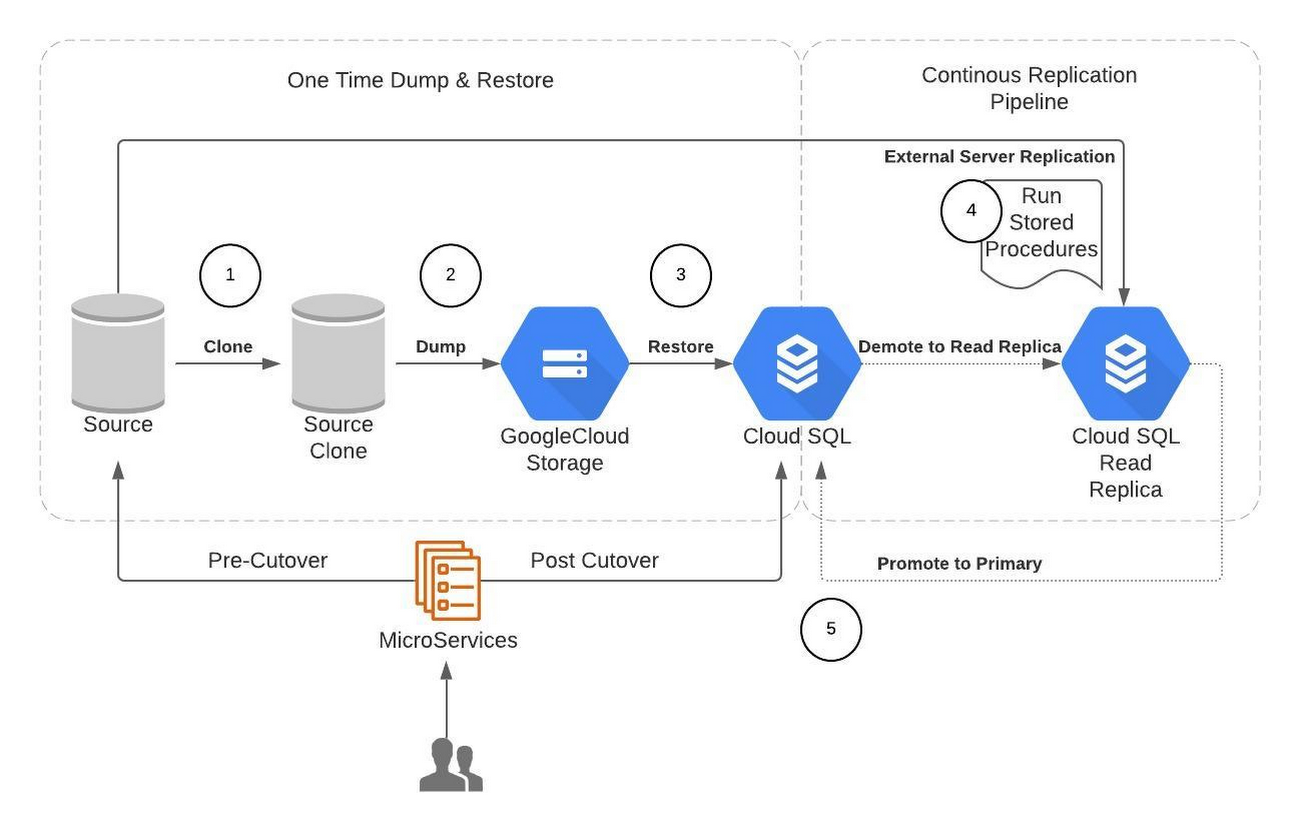
Broadcom에서 데이터 마이그레이션을 위해 선택한 단계는 다음과 같습니다.
소스 데이터베이스를 클론합니다.
소스 데이터베이스의 덤프를 작성하고 이를 Google Cloud Storage에 업로드합니다.
컴퓨팅 인스턴스를 프로비저닝하고 mydumper, Cloud Storage 클라이언트와 같은 도구를 설치합니다.
mydumper를 사용하여 병렬 덤프 작업을 시작합니다.
덤프를 암호화하고 Cloud Storage 버킷에 업로드합니다.
Cloud SQL을 프로비저닝하고 덤프를 복원합니다.
컴퓨팅 인스턴스를 프로비저닝하고 myloader와 같은 도구를 설치합니다.
Google Cloud Storage 버킷에서 덤프를 다운로드하고 이를 복호화합니다.
myloader를 사용하여 병렬 복원 작업을 시작합니다.
저장 프로시저를 사용하여 외부 서버 복제를 구성합니다.
Cloud SQL 구성을 읽기 복제본으로 업데이트합니다.
테이블 또는 데이터베이스 수준 필터와 함께 외부 기본 복제 파이프라인을 설정합니다.
복제를 위해 최적화된 매개변수를 구성합니다.
데이터베이스 컷오버
읽기 복제본 지연을 따라 잡을 수 있도록 데이터베이스에 대한 업스트림 서비스 트래픽을 부동태화합니다.
복제 지연이 0이면 Cloud SQL 읽기 복제본을 마스터로 승격시키고 원본 소스에서 Cloud SQL 인스턴스로 업스트림 트래픽을 컷오버합니다.
데이터 마이그레이션에 대한 추가 데이터 보안 및 무결성 고려사항:
- 트래픽이 비공개 VPC 경계를 벗어나지 않도록, 소스와 대상 간의 통신은 지속적인 복제 트래픽에 대한 VPC 피어링을 통해 비공개 네트워크에서 이루어져야 합니다.
- 저장 데이터 및 전송 중 데이터는 TLS/SSL을 지원하고 암호화되어야 합니다.
- 대규모 마이그레이션은 반복되는 안정성을 위해 완전 자동화가 필요하며, Ansible 자동화 프레임워크를 통해 달성될 수 있습니다. 또한 소스 및 대상 데이터베이스 사이의 데이터 무결성 검사를 자동화합니다.
- 복원 및 복제 시 오류 지점을 감지하고 복구할 수 있어야 합니다.



