[개발자를 위한 Spanner 시리즈] Cloud Spanner 동작 원리 이해하기
Google Cloud Korea Team
이번 게시물은 Cloud Spanner의 데이터 모델과 애플리케이션에서 쿼리를 실행할 때 Spanner에서 처리되는 놀라운 방식에 대해 설명합니다. Spanner는 임의의 SQL 문으로 데이터를 어떻게 찾고 밀리초 단위로 응답을 반환할까요? Spanner의 기본적인 데이터 모델과 SIGMOD’17 백서에 설명된 몇 가지 개념을 통해, SQL 실행이 어떻게 처리 되는지 단계별로 설명합니다.
스키마 및 데이터 모델
Cloud Spanner 데이터베이스에는 하나 이상의 테이블이 포함될 수 있습니다. 테이블은 행, 열 및 값으로 구조화되고 기본 키를 포함한다는 점에서 관계형 데이터베이스 테이블 형태 입니다. Cloud Spanner의 데이터는 강력한 유형으로 각 데이터베이스에 대한 스키마를 정의해야 하며 해당 스키마는 각 테이블의 각 열에 대한 데이터 유형을 지정해야 합니다. 허용되는 데이터 유형에는 스칼라 및 배열 유형이 포함되며, 이는 데이터 유형에 자세히 설명되어 있습니다. 테이블에 하나 이상의 보조 인덱스도 정의할 수 있습니다.
Parent-child 테이블 관계
Cloud Spanner에는 상위-하위 관계를 정의하는 방법이 두 가지가 있습니다. 바로 테이블 인터리빙 과 외래 키 입니다. 테이블 인터리빙은 상위 테이블의 기본 키 열이 하위 테이블의 기본 키에 포함 되는 많은 상위-하위 관계에 적합하며, 부모 행과 자식 행을 같은 위치에 배치하여 성능이 크게 향상될 수 있습니다. 예를 들어, Singers 테이블과 Albums 테이블이 있고 애플리케이션이 지정된 가수의 모든 앨범을 자주 가져오는 경우 Albums를 Singers의 자식 테이블로 정의할 수 있습니다. 이렇게 하면 논리적으로 독립적인 두 테이블 간의 데이터 지역성 관계가 선언됩니다. 즉, 아래의 그림에서 처럼 하나의 Singers Row와 하나 이상의 Albums Row를 물리적으로 가까운 위치에 저장하게 됩니다.
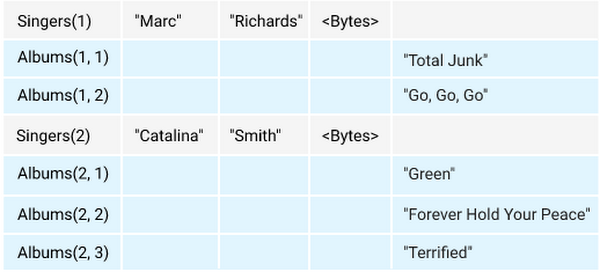
인터리빙에 대한 자세한 내용은 인터리브 테이블 만들기를 참조하세요.
외래 키는 보다 일반적인 부모-자식를 나타내며, 추가적인 사용 사례들이 있습니다. 기본 키 열에 국한되지 않으며 테이블에는 여러 외래 키 관계가 있을 수 있습니다. 그러나 외래 키 관계가 스토리지 계층에서 동일한 위치 의미하지는 않습니다.
외래 키 및 인터리브 테이블과의 비교에 대한 자세한 내용은 외래 키 개요를 참조하세요.
디자인 Best Practices
참고: Cloud Spanner’s Table Interleaving: A Query Optimization Feature
Spanner 데이터 위치 정보
앞서 설명한 바와 같이 데이터는 최상위 레벨의 테이블 또는 인터리브 테이블에 구성될 수 있습니다. 인터리빙은 부모자식 관계에서 자식 테이블의 Row 들을 키본 키를 공유하는 부모테이블의 Row 들과 근접한 곳에 저장 합니다. 예를 들어, Spanner 샘플 스키마에 있는 Singers와 Albums를 보면 다음과 같습니다.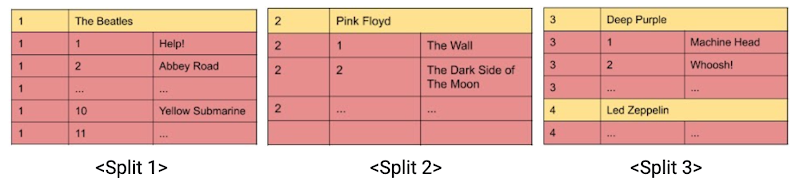
데이터는 최상위 테이블의 기본키에 의해서 분리가 결정되어 Split들에 저장 됩니다. 이러한 Split들의 분산을 결정하는 키의 범위를 보게 되면 다음과 같습니다.
Split 1: SingersId < 2,
Split 2: SingersId >=2, <3,
Split 3: SingersId >=3
각 Split은 독립적으로 배치되며 단일 서버에서 다른 Split과 함께 배치될수도 있고 아닐 수도 있습니다. Split은 분산 합의를 유지하고 트랜잭션의 쿼럼을 보장하기 위해 여러 복제본을 가집니다
Spanner 보조 프로세서(Coprocessor) 프레임워크
Spanner는 보조 프로세서 프레임워크를 사용합니다. 이 컴포넌트를 사용하면 Spanner가 RPC를 특정 서버가 아닌 데이터 위치로 지정하여 데이터 모델과 데이터 배치 간의 추상적 개념을 제공합니다
예를 들어, 보조 프로세서의 호출의 경우 목적지를 서버의 IP 주소가 아닌 Singers(2)와 같이 데이터 위치로 지정합니다. 그런 다음 보조 프로세서 프레임워크는 이 데이터를 가지고 있는 Split을 확인해서 클라이언트의 네트워크 대기 시간을 기준으로 가장 가까운 복제본에게 요청을 라우팅합니다. 이렇게 하면 데이터가 이동을 하더라도 클라이언트 애플리케이션은 이를 인식할 필요가 없으며 보조 프로세서 프레임워크를 통해 요청을 라우팅할 수 있습니다.
PrepareQuery
클라이언트가 Java에서 executeQuery() (Go의 ReadOnlyTransaction.Query)를 호출할 때 실행되는 첫 번째 보조 프로세서 호출이 PrepareQuery입니다. 이 호출은 쿼리를 파싱하고 분석하는 랜덤 서버로 라우팅 되며, 클라이언트에게 로케이션 힌트를 반환합니다. 로케이션 힌트는 쿼리를 보낼 최상위 테이블의 키를 포함합니다. 예를 들어 쿼리가 "SELECT SingerId, AlbumId, AlbumTitle from Albums WHERE SingerId=2"인 경우 로케이션 힌트는 "Singers(2)"가 됩니다.
로케이션 힌트 계산 절차
로케이션 힌트는 컴파일된 쿼리 구문을 분석하고 최상위 테이블의 키 컬럼에서 조건절을 찾아 계산됩니다. 로케이션 힌트는 바인드 변수를 포함할 수 있으므로 바인드 변수가 포함된 쿼리에 대해서도 캐시될 수 있습니다.
예를 들어, "SELECT * FROM Albums WHERE (SingerId = 1 AND AlbumId >= 10) OR (SingerId IN (2,3) AND AlbumId != 0)" 쿼리의 경우, 로케이션 힌트 추출 로직은 현재 쿼리가 최상위 테이블인 Singers의 자식 테이블에 접근하는 쿼리임을 알아내고, WHERE 절에서 SingerId 컬럼에 대한 첫 번째 조건 추출을 시도합니다. 여기서 SingerId = 1을 발견하고 로케이션 힌트 Singers(1)를 생성합니다. 만약 쿼리에 바인드 변수 형태로 SingerId = @id가 포함된 경우 로케이션 힌트는 Singers(@id)가 됩니다. 그런 다음 @id 변수의 실제 값을 분석하여 데이터 위치를 산출합니다(즉, id=1은 Singers(1)이 됩니다)
로케이션 힌트는 SQL 텍스트의 해시를 키로 사용하여 캐시됩니다. 즉, 애플리케이션이 다른 엔드유저에 대해 동일한 쿼리를 실행하는 경우, 바인드 변수 쿼리를 생성하여 캐시 적중률을 높이는 것이 좋습니다. 이 캐시가 적중되면 PrepareQuery에 대한 호출이 완전히 제거되므로 쿼리 대기 시간과 전체 성능이 개선됩니다. 이는 처리 시간이 네트워크 왕복 시간보다 짧은 "단순한" 쿼리의 경우 매우 중요할 수 있습니다. PrepareQuery 호출을 건너뛰게 되면 대기 시간이 절반으로 줄어들수 있습니다.
ExecuteQuery
로케이션 힌트를 사용할 수 있게 되면 다음 보조 프로세서 호출은 ExecuteQuery입니다. 이 호출은 로케이션 힌트를 기반으로 라우팅되며 수신 서버가 쿼리의 루트 서버가 됩니다. 그런 다음, 서버는 쿼리를 컴파일하고 실행 계획을 만들고 필요한 작업들을 수행하기 시작합니다. 컴파일된 쿼리 실행 계획은 기본적으로 캐시됩니다(즉, 반복되는 쿼리의 경우 바인드 변수화하는 것이 중요함).
실행 계획에는 하나 이상의 Split에서 데이터 액세스를 처리하기 위한 Distributed Union 연산자가 포함됩니다. 기본적으로 모든 실행 트리의 맨 위에는 Distributed Union이 있습니다. 또한 쿼리의 다른 스캔에 대해 추가로 Distributed Union 연산자가 삽입 될수 있습니다(예: 두 개의 최상위 테이블을 조인할 때).
Distributed Union은 데이터 범위 기반의 추출(아래에 설명됨)을 수행하고 서브쿼리를 다른 Split으로 내려 보내고 이들 원격 서버로 부터 실행된 결과를 다시 호출자에게 스트리밍 합니다.
Distributed Union 범위 추출
Spanner는 조건절을 컴파일하고 효율적인 키 조건과 범위 계산을 위해 필터 트리를 구축합니다. 예를 들어 위의 "SELECT * FROM Albums WHERE (SingerId = 1 AND AlbumId >= 10) OR (SingerId IN (2,3) AND AlbumId != 0)" 쿼리의 경우 FilterTree는 다음과 같을수 있습니다(빨간색 텍스트는 아래에 설명되어 있습니다.)
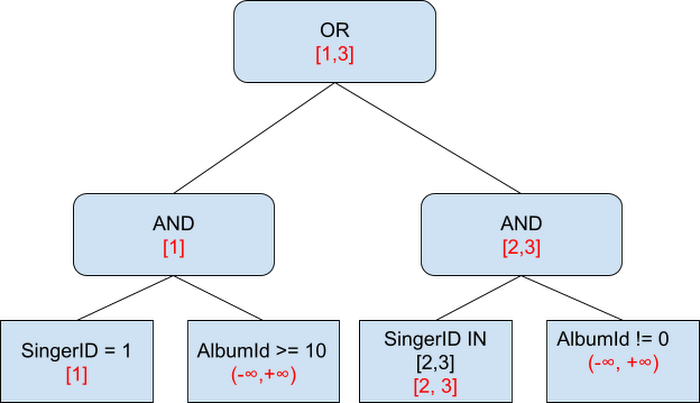
먼저, 분포 범위에 대한 계산을 위해 최상위 테이블의 키(SingerID) 추출을 시도하며, 이때 FilterTree는 빨간색으로 표시된 범위를 고려합니다. 예를 들어 그림에서 "SingerId = 1" 노드는 [1]의 범위를 생성합니다. "AlbumID>=10" 노드는 이 키와 관련이 없으므로 범위는 전체(-∞, ∞)입니다. 한단계 위의 AND 노드는 두 범위의 교집합으로 [1] 입니다. 유사한 방식으로 다른 트리도 진행후 최상위 SingerId 범위는 [1,3]으로 결정 됩니다. 궁극적으로 Distributed Union은 쿼리에서 요청한 데이터를 포함하고 있는 모든 Split를 찾게 됩니다.
쿼리에서 분산 키를 추출할 수 없는 경우(예: 키 조건자가 없는 "SELECT * FROM T") 쿼리는 테이블의 모든 Split에 전달됩니다.
ExecuteInternalQuery
앞서 ExecuteQuery 호출의 경우 단일 서버인 루트 서버로 라우팅이 되지만, 루트 서버가 모든 Split들을 가지고 있지 않은 경우, 다른 Split들을 처리하기 위한 호출이 추가적으로 발생합니다. 이를 ExecuteInternalQuery 라고 합니다. Split의 범위가 [1,3] 즉 1, 2, 3 이기 때문에, 루트 서버에서 Distribute Union은 값을 하나씩 읽어서 각 Split을 처리할 리모트 서버로 ExecuteInternalQuery 호출을 수행합니다. 이러한 호출은 병렬로 수행되기 때문에 빠른 처리가 가능합니다.
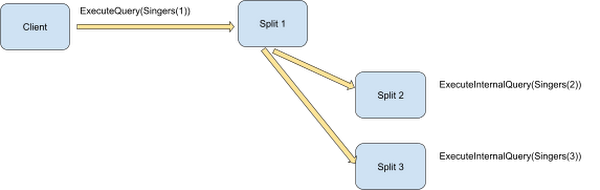
그림에서 처럼 내부 쿼리도 보조 프로세서 프레임워크를 사용하기 때문에 데이터의 일부를 유연하게 이동해서 각 서버의 로드를 고르게 분산할 수 있습니다.
Distributed Union 연산자는 다른 Split의 처리 결과를 가져와서 결합된 결과를 호출자에게 반환하는 일도 담당합니다. Split 수가 많은 경우 병렬 쿼리 힌트(USE_ADDITIONAL_PARALLELISM) 사용하여 더 많은 리소스를 할당하여 처리 시간을 줄일 수 있습니다.
요약
Spanner에서 쿼리를 실행하려면 동적으로 관리되는 데이터 배치 및 이동을 고려해야 합니다. 그렇지만 Spanner의 보조 프로세서 프레임워크는 Spanner의 나머지 구성 요소를 데이터의 물리적 위치에 대한 세부 정보로 부터 격리하고 논리적 데이터 정보를 기반으로 요청을 라우팅합니다.
PrepareQuery 호출에서 분배 키 추출을 통해 Spanner는 쿼리를 처리해야 하는 첫 번째 서버에서 실행을 시작할 수 있으며, 필요한 경우 추가적인 서브쿼리가 나머지 Split을 포함하는 다른 서버로 전송됩니다. 이러한 메커니즘을 통해 분산된 Split들로 부터 필요한 데이터를 수집하는 복잡한 쿼리를 가능하게 하며, 최종 사용자에게는 간단한 executeQuery API를 제공하게 됩니다.
본 게시물은 쿼리 실행의 복잡성에 대한 일부만을 다뤘습니다. 원본 백서의 경우 Spanner 팀이 제공하는 재시작 메커니즘, 스토리지 개선, 트랜잭션 등에 대한 설명이 추가되어 있으니 참고하시기 바랍니다
다음 게시물 예고
다음 게시물에서는 Cloud Spanner에서 애플리케이션을 개발 시작하는 방법에 대해 알아 보겠습니다. 기대해 주세요.



