[개발자를 위한 Spanner 시리즈] Node.js 기반의 애플리케이션 구축하기
Google Cloud Korea Team
이번 블로그 게시물에서는 OmegaTrade라는 샘플 주식 차트 시각화 도구를 사용하여 Cloud Spanner에서 Node.js 애플리케이션을 빌드하고 배포하는 방법을 설명합니다. 이 애플리케이션은 주가를 Cloud Spanner에 저장하고 Google 차트를 사용하여 시각화를 렌더링합니다. 몇 가지 중요한 Cloud Spanner 개념과 함께 Cloud Spanner 인스턴스를 설정하는 방법과 Node.js 애플리케이션을 Cloud Run에 배포하는 방법에 대해 알아 보겠습니다.
먼저, Cloud Run에서 애플리케이션을 배포하는 단계를 설명하는 것으로 시작해서 OmegaTrade에서도 채택된 일반적으로 Cloud Spanner를 사용하는 애플리케이션에 대한 세션 튜닝, 커넥션 풀링 및 타임아웃에 대한 모범 사례를 얘기하고 마무리 하겠습니다.
배포 단계
Cloud Spanner를 데이터 저장소로 사용하고, 프런트엔드 및 백엔드 서비스를 Cloud Run에 배포하여 완벽한 서버리스 애플리케이션을 배포 합니다. 여기서 Cloud Run을 선택한 이유는 인프라 관리를 추상화하고 트래픽에 따라 거의 즉시 자동으로 확장 또는 축소를 수행하기 때문 입니다.
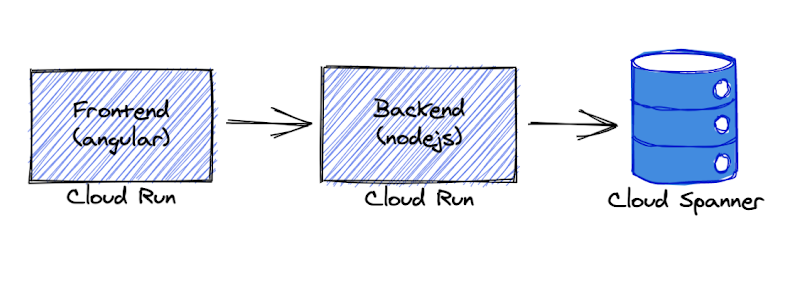
백엔드 서비스는 Node.js Express 프레임워크를 사용하고 기본 케넥션 풀링, 세션, 타임아웃 설정으로 Cloud Spanner에 연결합니다.
사전 준비 사항은 다음과 같습니다
다음의 권한 세트 중 하나로 신규 또는 기존 GCP 프로젝트에 연결:
Owner
Editor + Cloud Run Admin + Storage Admin
Cloud Run Admin + Service Usage Admin + Cloud Spanner Admin + Storage Admin
빌링이 설정된 GCP 프로젝트
다음의 툴들이 설치된 환경:
참고 - 권한이 조직 정책에 의해 제한되지 않았는지 확인하세요. 그렇지 않으면 나중에 배포 단계에서 문제가 발생할 수 있습니다.
그럼 이제 시작해 보겠습니다!!
먼저 gcloud 구성을 기본값으로 설정하고 GCP 프로젝트를 이 구성으로 설정하겠습니다. gcloud는 GCP 서비스를 위한 커맨드라인 인터페이스 입니다.
수행결과:
필요한 GCP 프로젝트에 대한 액세스 권한이 있는 Google 계정을 선택하고 메시지가 표시되면 프로젝트 ID를 입력합니다.
다음으로 기본 gcloud 구성이 올바르게 설정되었는지 확인해야 합니다. 다음에서 인증을 활성화하고 이전에 설정된 API 엔드포인트 URL 설정을 해제하고 기본 gcloud 구성에서 사용할 GCP 프로젝트를 설정합니다.
이제 Cloud Spanner, Container Registry, Cloud Run용 Google Cloud API를 설정해 보겠습니다.
Cloud Spanner 프로비전: 인스턴스, 데이터베이스 그리고 테이블
gcloud 명령어를 사용하여 Spanner 인스턴스와 데이터베이스를 생성해 보겠습니다.
OmegaTrade 애플리케이션에 필요한 4개의 테이블도 생성합니다.
Users
Companies
CompanyStocks (주식 가치 추적)
Simulations (각 시뮬레이션의 상태를 추적)
Cloud Spanner 인스턴스에서 INFORMATION_SCHEMA를 쿼리하여 이러한 테이블이 성공적으로 생성되었는지 확인합니다. SQL 스펙에 정의된 INFORMATION_SCHEMA는 데이터베이스 개체에 대한 메타데이터를 쿼리하는 표준 방법입니다.
위 단계에서 Cloud Spanner 인스턴스, 데이터베이스, 테이블이 생성되었으니 이제 OmegaTrade를 빌드하고 배포해 보겠습니다.
Cloud Run에 애플리케이션 백엔드 배포하기
이제 omegatrade/frontend 및 omegatrade/backtend 서비스를 Cloud Run에 배포하는 단계를 살펴보겠습니다. 먼저 백엔드를 배포한 다음 백엔드 서비스 URL을 사용하여 프런트엔드를 배포합니다.
먼저, 저장소를 복제 합니다.
그런 다음 앱이 작동하는 데 필요한 일부 환경 변수를 편집해 보겠습니다. [Your-Project-ID]에 프로젝트 ID를 추가합니다.
이제 dockerfile에서 이미지를 빌드하고 GCR에 푸시합니다. 위와 같이 GCP 프로젝트 ID를 반영하도록 명령어를 변경해야 합니다.
참고 - 인증에 문제가 있는 경우 GCP 문서(Authentication)에 언급된 절차를 따르고 아래 명령을 다시 시도하세요.
다음으로 Cloud Run에 백엔드를 배포해 보겠습니다. Cloud Run 서비스를 만들고 Cloud Spanner 구성을 위한 몇 가지 환경 변수로 빌드한 이미지를 배포합니다. 이 작업은 몇 분 정도 걸릴 수 있습니다.
이제 OmegaTrade 백엔드가 실행됩니다. 백엔드의 서비스 URL이 콘솔에 출력 됩니다. 프론트엔드를 구축하는데 사용하기 위해 이 URL을 기록해 둡니다.
샘플 주식 데이터를 데이터베이스로 가져오기
샘플 회사 및 주식 데이터를 가져오려면 백엔드 폴더에서 아래 명령을 실행하세요.
위의 명령은 샘플 데이터를 연결된 데이터베이스로 마이그레이션 합니다. 이 작업이 성공하면 `Data Loaded successfully' 메시지가 표시됩니다.
참고: 중복을 피하기 위해 빈 데이터베이스에서만 실행하시기 바랍니다
이제 프론트엔드를 배포해 보겠습니다.
Cloud Run에 애플리케이션 프론트엔드 배포하기
프론트엔드 서비스를 구축하기 전에 리포지토리에서 다음 파일을 백엔드 배포 단계에서 기록한 백엔드 URL, 즉 서비스 URL로 업데이트해야 합니다.
참고 - 애플리케이션에 대해 Google로 로그인을 활성화하려면 지금이 OAuth를 설정하는 것이 좋습니다. 설정 방법의 경우 readme의 6번째 스텝을 확인하세요.
Base URL을 서비스 URL로 변경합니다(/api/v1/ 추가). OAuth를 활성화한 경우 clientId가 OAuth 콘솔 플로우에서 얻은 값과 일치하는지 확인 하시기 바랍니다.
OAuth 자격 증명 생성을 건너뛴 경우 clientId를 빈 문자열로 설정합니다. 다른 모든 필드는 동일하게 유지 하시기 바랍니다
프론트엔드 폴더로 돌아갑니다. 프론트엔드 서비스를 빌드하고 이미지를 GCR에 푸시합니다. 이 프로세스는 몇 분 정도 걸릴 수 있습니다.
이제 Cloud Run에 프런트엔드를 배포해 보겠습니다.
만약 인증관련 이슈가 발생하는 경우 Authentication 과 Cloud Run Authentication 가이드를 참고하시기 바랍니다
이제 프런트 엔드가 배포되었습니다. 브라우저에서 이 서비스 URL로 이동하여 애플리케이션에 액세스할 수 있습니다.
선택적으로 OAuth 웹 애플리케이션에 프런트엔드 URL을 추가하여 Google 계정을 사용하여 로그인할 수 있습니다. OAuth 2.0 클라이언트 ID에서 생성한 애플리케이션을 엽니다. Authorized JavaScript origins 아래에 프런트엔드 URL을 추가하고 저장합니다.
참고 - 앱 실행이 차단되지 않도록 브라우저에서 쿠키가 활성화되어 있는지 확인하십시오.
완료 화면 스크린샷
축하합니다! 모든 절차를 완료하게 되면 이제 앱이 Cloud Run에서 실행 중일 것입니다. 프론트엔드 URL로 이동하여 애플리케이션을 자유롭게 사용해 보세요. 좋아하는 회사 티커를 추가하고 시뮬레이션을 생성해 보세요. 모든 데이터 쓰기 및 읽기는 Cloud Spanner에서 처리합니다.
다음은 앱의 몇 가지 스크린샷입니다.
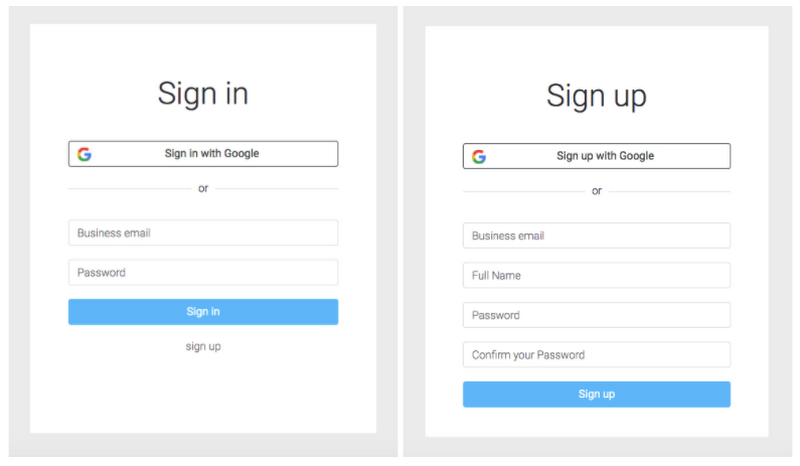
1. Login and Registration View: 사용자는 Google 계정(활성화된 경우 OAuth를 통해) 또는 이메일 주소를 사용하여 등록 및 인증할 수 있습니다. 로그인에 성공하면 화면이 대시보드로 전환 됩니다.
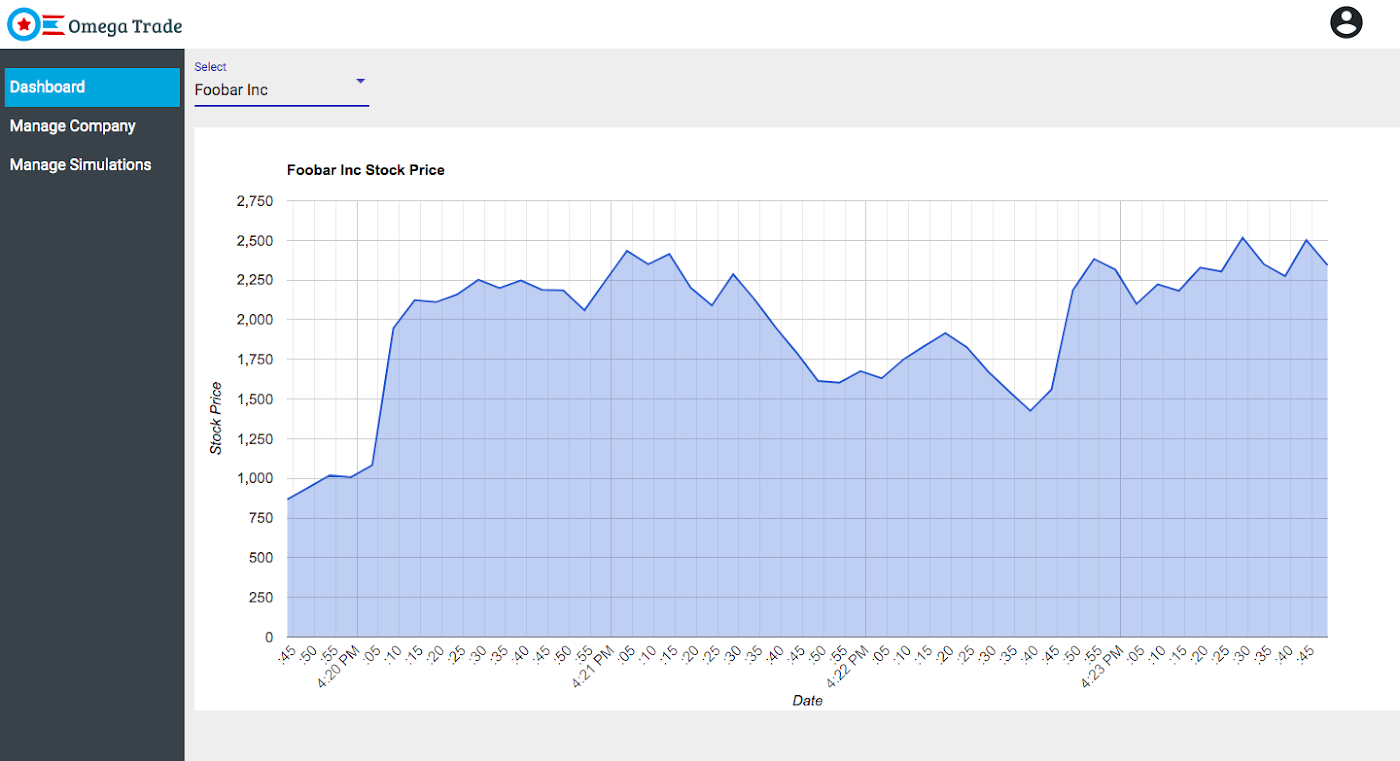
2. Dashboard View: 앱은 몇 개의 가상 샘플 회사에 대한 시뮬레이션된 주식 값으로 미리 구성되어 있습니다. 대시보드 화면은 시뮬레이션된 주가를 그래프로 렌더링합니다.
3. Manage Company View: 사용자는 이 화면을 사용하여 새 회사와 해당 종목 기호를 추가할 수 있습니다.
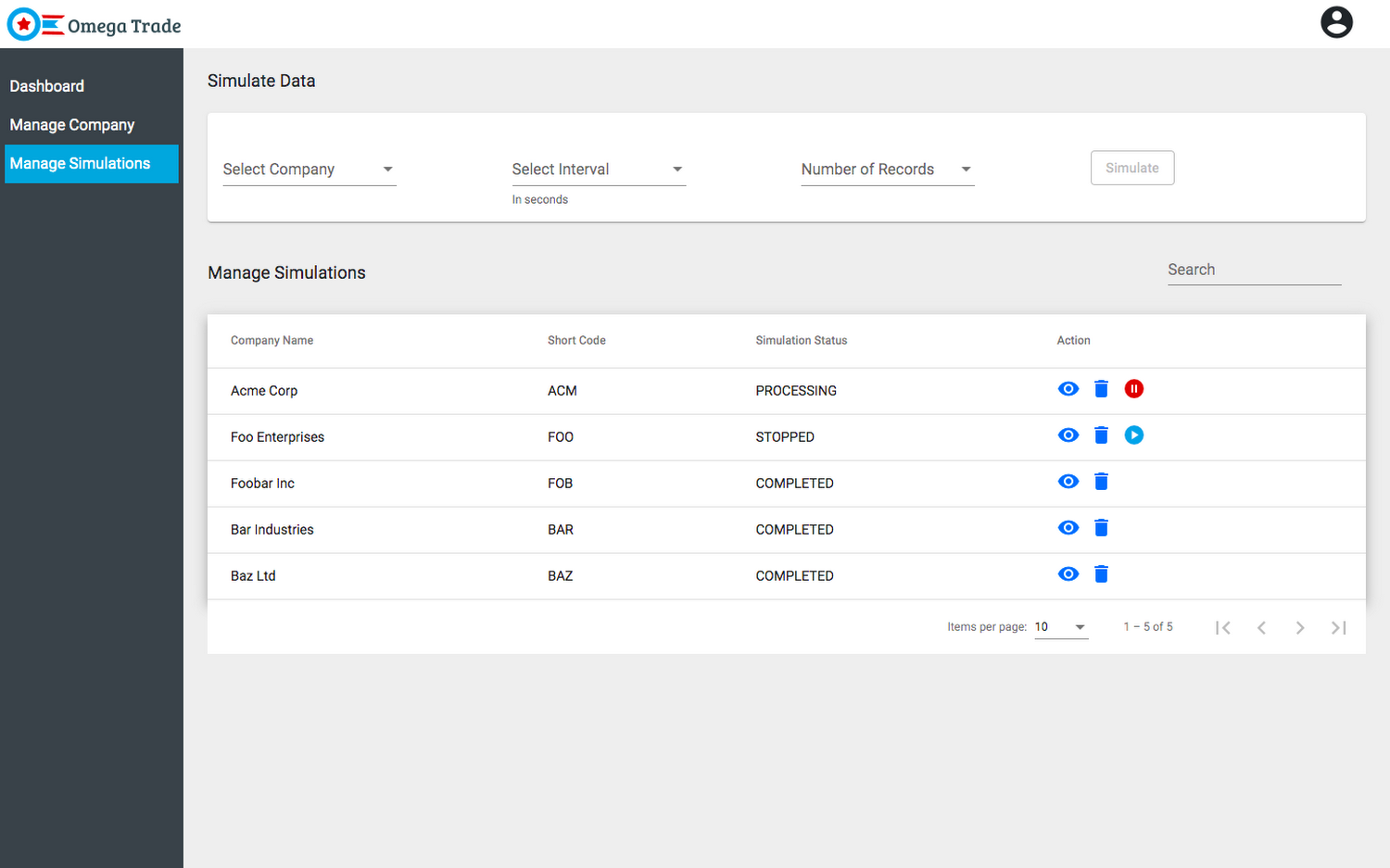
4. Simulate Data View: 이 화면을 통해 사용자는 기존 또는 새로 추가된 회사의 데이터를 시뮬레이션할 수 있습니다. 백엔드 서비스는 몇 가지 매개변수(선택한 간격 및 행 수)를 기반으로 데이터를 시뮬레이션합니다. 사용자는 실행 중인 시뮬레이션을 일시 중지, 재개 및 삭제할 수도 있습니다.
이제 애플리케이션을 배포했으므로 애플리케이션의 코드를 탐색할 때와 자체 애플리케이션에서 접하게 될 몇 가지 중요한 Spanner 개념을 살펴보겠습니다.
세션
세션은 Cloud Spanner 데이터베이스 서비스와의 통신 채널을 나타냅니다. Cloud Spanner 데이터베이스에서 데이터를 읽거나 쓰거나 수정하는 트랜잭션을 수행하는 데 사용됩니다. 세션은 단일 데이터베이스와 연결됩니다.
Best Practice - 사용자가 세션과 직접 상호 작용해야 하는 경우는 거의 없습니다. 세션은 내부적으로 클라이언트 라이브러리에 의해 생성 및 유지 관리되며 최상의 성능을 위해 이러한 라이브러리에 의해 최적화됩니다.
커넥션(세션) 풀링
Cloud Spanner에서 데이터베이스와의 수명이 긴 '케넥션'/'통신 채널'은 DatabaseClient 객체가 아닌 '세션'으로 모델링 됩니다. DatabaseClient 개체는 SessionPoolOptions를 통해 구성할 수 있는 SessionPool 개체에서 내부적으로 케넥션(세션) 풀링을 구현 합니다.
기본 세션 풀의 옵션은 다음과 같습니다
Best Practice - 최대 성능을 위해 미리 구성된 기본 세션 풀 옵션을 사용하는 것이 좋습니다.
타임아웃 및 재시도
Best Practice - 디폴트 타임아웃 및 재시도 구성을 사용하는 것이 좋습니다. [1] [2] [3] 타임아웃 및 재시도를 더 적극적으로 설정하면 백엔드가 요청을 조절하기 시작할 수 있기 때문입니다.
다음의 예에서는 지정된 작업에 대해 60초의 사용자 지정 타임아웃이 명시적으로 설정됩니다(totalTimeoutMillis 설정 참조). 작업이 이 타임아웃 보다 오래 걸리면 DEADLINE_EXCEEDED 오류가 반환됩니다.
마무리
축하합니다! 지금까지 Spanner를 기반으로 하는 Node.js 애플리케이션을 구축해 보았습니다. 또한 Cloud Spanner의 세션, 케넥션 풀링, 타임아웃 및 재시도와 관련된 다양한 매개변수를 더 잘 이해하게 되었을 것입니다. 자유롭게 응용 프로그램을 사용하고 코드베이스도 확인해 보시기 바랍니다.
Cloud Spanner에서 Node.js 애플리케이션을 구현하기 위한 구성 요소에 대해 자세히 알아보려면 추가적으로 다음을 확인해 보시기 바랍니다.
다음 게시물 예고
다음 게시물에서는 Cloud Spanner에서 성능 및 모니터링에 대해 알아 보겠습니다. 많은 관심 부탁 드립니다.



