AI / LLM 서비스를 위한 클라우드 인프라 최적화 - GKE Inference Gateway -
Jinhyun Lee (이진현)
Customer Engineer, Network Specialist
대규모 언어 모델(LLM) 기반의 AI 워크로드는 기존 환경과는 다른 특성을 가집니다. 일반적인 웹 기반의 애플리케이션보다 더 긴 요청 처리 시간, 그리고 이러한 요청을 처리함에 있어서 GPU 자원에 대한 높은 의존성을 가지며 이는 전통적인 인프라 뿐만 아니라 클라우드 네이티브 환경에서 제공하는 기능과 지원 범위를 벗어나는 문제입니다. 특히 여러 도구와 모델을 순차적 또는 병렬적으로 호출하는 AI 에이전트(AI Agent) 아키텍처는 복잡성을 더욱 증대시키며 이를 고려하지 않거나 기존 배포 방식으로 구성 할 경우 결국 애플리케이션의 높은 지연 (Latency) 발생과 이로 인한 사용자 경험을 저해 시키는 결과로 이어집니다.
Google Cloud의 GKE Inference Gateway는 이러한 문제들을 해결할 수 있는 쿠버네티스 (Kubernetes) 네이티브 솔루션입니다. 본 블로그를 통해 GKE Inference Gateway의 핵심 기능과 동작 원리를 설명하고, 이를 LLM 추론 (Inference) 및 AI 에이전트 워크로드에 적용하는 구체적인 구성 방법을 소개합니다 .
LLM 환경 구성을 위한 기존 방식의 접근과 한계
가장 일반적인 LLM 워크로드의 구성 방식은 클라우드 업체가 제공하는 관리형 쿠버네티스 서비스 (예, Google Kubernetes Engine) 의 클러스터 환경에 GPU 혹은 TPU 전용 노드 풀을 구성하고, vLLM 과 같은 서빙 엔진 컨테이너와 LLM 모델을 포함하는 Pod 를 병렬로 배치하는 방법입니다. 그리고 사용자나 AI 에이전트의 요청을 연결하고 다수의 GPU 노드로 구성된 백엔드로 트래픽을 분산하기 위해 로드밸런서를 사용합니다. 하지만 이러한 일반적인 구성에서는 다음과 같은 한계에 직면하게 됩니다.
- 기존 로드밸런서의 한계 - 일반적인 로드밸런서가 제공하는 라운드 로빈 (Round Robin), 최소 연결 (Least Connection), 실시간 요청 수 (Rate) 를 기반으로 한 라우팅이나 트래픽 분배 방식은 LLM 요청 처리를 위한 효율적인 서비스 환경을 제공하기 어렵습니다. 특정 클라이언트가 요청한 상대적으로 큰 토큰 (Token) 을 처리중인 백엔드 Pod 와 GPU 노드는 세션이나 요청 수가 적은 상황에서도 추가적인 요청을 처리하기 어려운 상황일 수 있으며, 요청이 지속적으로 할당될 경우 AI 서비스의 품질 저하를 발생 시킵니다.
- 오토스케일 (Auto Scale) 의 한계 - 쿠버네티스 환경은 기본적으로 CPU 나 메모리 사용량을 기반으로하여 워크로드의 오토스케일링을 수행 합니다. 하지만 CPU 사용량만으로는 실제 GPU 의 부하 상태를 정확하게 파악할 수 없어 적절한 스케일링이 이루어지지 않아 불필요한 리소스 낭비 및 서비스 안정성을 떨어뜨리는 결과를 발생 시킵니다. LLM 서빙으로 인한 GPU 리소스의 부하 상태 확인과 이를 이용한 스케일 방식은 기존의 애플리케이션에서 제공되는 방법과는 다르게 측정하고 동작히여야 합니다.
- 비용 증가와 높은 지연 (Latency) 시간 - 위의 한계와 함께 LLM 서비스는 예측 불가능한 트래픽 패턴을 발생 시킵니다. 최대 트래픽 기준으로 GPU 노드 수를 고정적으로 할당 할 경우 비용 증가가 발생 할 뿐만 아니라 효율적인 요청 분배가 이루어지지 않아 지속적인 리소스 확대에도 불구하고 서비스 지연이 발생하는 악순환이 반복됩니다.
LLM 서비스 및 GPU 리소스 모니터링을 위한 접근
LLM은 'Self-Attention' 메커니즘을 통해 토큰을 미리 예측합니다. 이 과정에서 이전에 생성된 토큰의 연관성을 계산해야 하는데, 이때 각 토큰의 Key(K)와 Value(V) 벡터가 사용됩니다. 그리고 한번 계산된 Key와 Value 텐서를 GPU 메모리(VRAM)에 저장하는 기능을 KV Cache (Key-Value Cache) 라고 합니다. 이는 다음 토큰을 생성할 때 반복적인 계산을 피하게 해주는 핵심적인 최적화 기술입니다.
쉽게 말해 KV 캐시는 LLM이 이전에 생성된 토큰들의 중간 계산 결과를 저장하는 GPU 메모리 저장소입니다. LLM 모델은 이전에 계산해 둔 KV 캐시를 활용하여 다음 토큰 예측에 필요한 정보를 빠르게 불러올 수 있으며 추론 서비스 속도를 빠르게 올려줄 수 있는 방법 입니다.
이러한 KV 캐시의 사용률 (KV Cache Utilization)은 GPU 메모리의 점유 상태를 나타냅니다. 예를 들어 긴 대화나 긴 문서에 대한 요약, 분석 등의 요청을 처리 중인 모델 서버는 높은 KV 캐시 사용률을 보이며 이는 새로운 긴 요청을 받을 메모리 여유 공간이 부족함을 의미합니다. 만약 로드밸런서가 KV 캐시 사용률을 모니터링하여 GPU 메모리 점유 상태가 보다 적은 백엔드로 LLM 요청을 전달할 수 있다면 보다 빠른 요청 처리와 더불어 효율적인 GPU 자원 활용을 기대할 수 있습니다.
또한 Pending Request Queue Length 도 활용할 수 있습니다. 이는 각 개별 모델 서버가 요청을 이미 수신했지만 아직 처리를 시작하지 못한, 내부 큐에 대기 중인 LLM 요청의 수를 의미합니다. 이 지표는 모델 서버의 즉각적인 처리 부하 또는 백로그 상태를 나타냅니다.
이 두가지 지표는 서로 다른 차원의 부하 상태를 확인하여 상호 보완적으로 활용할 수 있습니다. 예를 들어, 한 모델 서버는 방금 긴 요청 처리를 마쳐 KV 캐시 여유 공간은 많지만, 그 사이에 여러 개의 짧은 요청들이 도착하여 Pending Queue가 길어질 수 있습니다. 반대로, 다른 서버는 단 하나의 매우 긴 요청을 처리하느라 Pending Queue는 비어있지만 KV 캐시 사용률은 매우 높은 상태일 수 있습니다.
빠르고 효율적인 AI 워크로드 환경을 제공하는 GKE Inference Gateway
Google Cloud 가 제공하는 관리형 쿠버네티스 서비스인 GKE (Google Kubernetes Engine) 는 Gateway 의 확장 서비스로 GKE Inference Gateway 라는 기능을 제공합니다. 이를 통해 생성형 AI 워크로드 및 LLM 추론 서비스를 위한 최적화된 라우팅 및 로드 밸런싱을 제공하며 LLM 워크로드의 배포, 관리를 간소화하고 모니터링 환경을 제공합니다. GKE Inference Gateway 은 다음과 같은 특징과 기능을 제공합니다.
- Optimized load balancing for inference: AI 모델 성능과 LLM 추론 서비스를 최적화 하기위해 클라이언트 요청에 대한 효율적인 부하분산을 제공 합니다. 앞서 설명한 KV 캐시 사용률과 Pending Queue 길이와 같은 모델 서버의 지표를 측정하여 최적의 백엔드로 요청을 분배함으로서 GPU/TPU 리소스를 효율적으로 사용할 수 있으며 보다 빠른 모델 서비스 환경을 사용자에게 제공할 수 있습니다.

<GKE Inference Gateway 의 모델서버 지표 기반 트래픽 전송>
-
Optimized autoscaling for inference: GKE 의 Horizontal Pod Autoscaler (HPA)는 기존의 지표가 아닌 앞서 설명한 모델 서버의 지표를 사용하여 자동으로 Pod를 확장하므로 효율적인 컴퓨팅 리소스 사용과 최적화된 LLM 추론 성능을 보장합니다.
-
Model aware routing: OpenAI API 사양에 정의된 모델 이름을 기반으로 추론 요청을 라우팅합니다. 이를 통해 단일 쿠버네티스 클러스터와 게이트웨이 하에 다양한 모델 버전을 배포하고 관리를 간소화할 수 있습니다. 예를 들어, 다양한 서빙 모델 (예, Gemma, Llama, Qwen 등)을 배포하고 사용자의 요청을 해당 모델로 라우팅 하는 환경을 구성하거나, 특정 메인 서빙 모델에 대한 요청을 서로 다른 버전 (예, Gemma 3 4B, 12B, 27B 등) 으로 제공하는 환경도 구성할 수 있습니다.
-
Dynamic LoRA fine-tuned model serving: AI 워크로드에 Dynamic LoRA (Low-Rank Adaptation) fine-tune 모델을 사용할 수 있도록 지원합니다. 메인으로 제공되는 서빙 모델에 복수개의 LoRA fine-tune을 적용할 수 있으며, GKE Inference Gateway 는 해당 모델을 인식하고 경로 조정을 통해 사용자의 요청을 해당 모델로 전송할 수 있습니다. 이를 통해 모델에 필요한 GPU/TPU 리소스를 절약할 수 있으며 최적의 모델 환경을 구현할 수 있습니다.
- Model-specific serving Criticality: AI 모델의 처리 우선순위를 지정할 수 있습니다. 여러 모델을 배포, 사용중인 환경에서 비즈니스에 보다 우선순위를 가지는 모델을 지정하여 우선적으로 처리할 수 있는 기능을 제공 합니다. 예를 들어, AI 에이전트가 필요로 하는 특정 모델을 우선시하여 혼잡 상황 발생 시 다른 일반 모델들의 처리가 지연 되더라도 해당 모델을 우선 처리하도록 조정할 수 있습니다.

<GKE Inference Gateway 의 모델 종류 및 중요도 판단 기반의 라우팅>
GKE Inference Gateway 의 상세 동작 방식
GKE Interference Gateway는 기존의 GKE 에서 제공하는 로드밸런서 서비스인 GatewayClass와 함께 동작하며 Gateway API 에서 새롭게 지원하는 CRD (Custom Resource Definition)를 사용하여 구성됩니다. GKE Inference Gateway의 동작 방식을 이해하기 위해서는 우선 아래 객체 (Object)에 대한 이해가 필요 합니다.
- InferencePool: 기본 AI 파운데이션 모델 및 버전을 기반으로 생성하며 GKE 클러스터 내에서 해당 모델을 위한 여러 GPU 리소스 및 Pod 그룹 객체입니다. 따라서 단일 InferencePool은 여러 노드에 걸쳐 작동할 수 있습니다. 예를 들어, Nvidia H100 GPU를 사용하는 여러 GPU 전용 노드에 Gemma 3 모델을 배포하는 경우 이를 하나의 InferencePool로 구성합니다. 이러한 InferencePool 단위로 GKE Inference Gateway는 각 GPU의 사용률을 모니터링하고 트래픽 밸런싱, 고가용성(HA) 및 스케일링을 수행합니다.
- InferenceModel: 실제 제공할 모델을 나타내는 InferenceModel이라는 객체도 필수로 구성해야 합니다. InferencePool에는 여러 InferenceModel을 구성할 수 있습니다. 예를 들어 Gemma 3를 여러 GPU 노드 리소스와 Pod 를 포함하는 InferencePool 로 생성하고 용도에 따른 여러 InferenceModel (예 - 쳇봇, 리뷰, 프로그래밍, 특정 언어 모델, 일반 추론 등)을 구성할 수 있습니다. 일부 모델은 효율적인 서비스 환경 구성을 위해 Lora Adaptor를 사용할 수도 있으며, 또한 혼잡 상황에서 어떤 모델이 요청 처리에 더 많은 기회를 가져야 하는지에 대한 중요도 (Criticality) 기능을 제공 합니다.
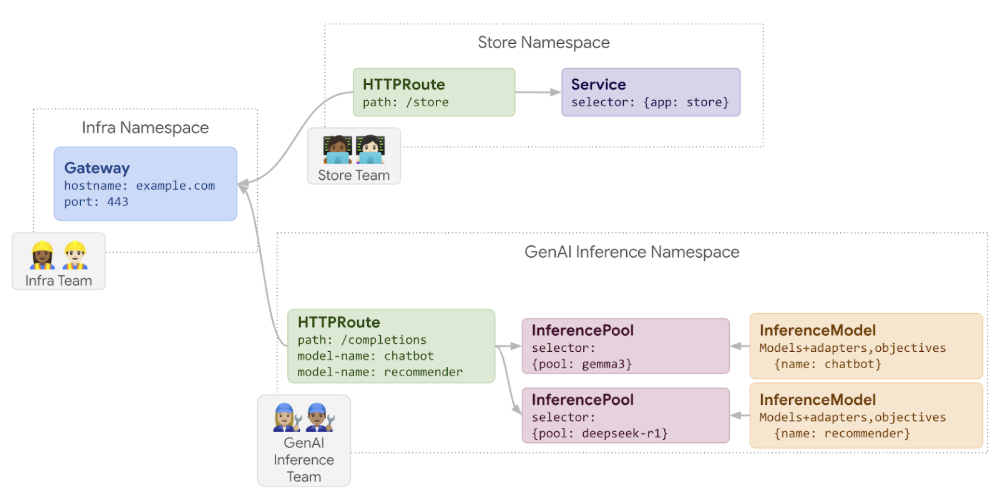
<InferencePool, InferenceModel 객체를 이용한 복수개의 모델 구성 방법>
이제 GKE Inference Gateway 가 어떻게 동작 하는지 살펴 보겠습니다.
- 클라이언트나 AI 에이전트가 LLM 추론 요청을 GKE 클러스터로 전송 합니다. GKE Inference Gateway가 해당 요청을 수신합니다.
- GKE Inference Gateway 는 다음과 같은 Extension 을 이용하여 요청을 처리합니다.
- Body-based Routing Extension: 클라이언트의 OpenAI API 규격을 준수하는 LLM 추론 요청을 확인하여 정확히 어떤 모델에 대한 요청인지 구분합니다. LLM 요청에서 실제 모델 정보는 request body 에 포함되어 있으므로 이를 확인하여 쿠버네티스의 HTTPRoute 객체가 처리할 수 있도록 모델 정보를 request header 에 정의합니다.
- Endpoint Picker Extension: 앞서 설명한 IneferencePool 객체 내의 리소스 사용량을 모니터링 합니다. KV 캐시 사용률, Pending Queue 길이, 그리고 모델 서버에 활성화 되어 있는 LoRA Adapter를 추적합니다. 그런 다음 이러한 지표를 기반으로 최적의 모델 복제본 (replica)으로 해당 요청에 대한 라우팅을 결정하여 AI 추론의 지연 시간을 최소화하고 처리량을 극대화합니다.
- Security Extension: AI 보안을 위한 검사를 수행할 수 있도록 보안 솔루션과의 연동을 구성할 수 있습니다. 이 부분은 하단에서 추가 설명을 제공 합니다.
3. GKE Inference Gateway는 Endpoint Picker Extension 에서 반환된 요청을 수신하여 모델 복제본으로 라우팅합니다.
아래 그림을 통해 GKE Inference Gateway 가 어떻게 동작하는지 좀 더 쉽게 이해할 수 있습니다.

<GKE Inference Gateway의 동작 방법>
GKE Inference Gateway 구성 방법
이제 GKE Inference Gateway 를 배포하고 실제 사용을 위한 주요 설정 내용을 살펴 보도록 하겠습니다. 본 블로그에서는 기본적인 GKE 클러스터 생성이나 환경 설정, LLM 모델 배포 등의 설정은 생략합니다. GKE Inference Gateway 설정을 위한 보다 상세한 설정은 ‘링크’ 의 공식 문서를 참고 하시기 바라며 GKE 클러스터에서 다양한 LLM 모델 배포를 위한 설정 방법은 ‘링크’ 를 참고 하시기 바랍니다 .
우선 GKE Inference Gateway를 GKE 클러스터에 사용하기 위해서는 앞서 설명한 InferencePool 및 InferenceModel 객체가 필요하며 다음 커맨드를 이용하여 CRD를 설치합니다.
InferencePool 은 다음과 같이 Helm 을 이용하여 설치합니다.
inferencePool.modelServers.matchLabels.app 의 값을 배포한 모델 서버의 Workload Pod 명으로 선언합니다. 아래는 vllm 기반의 llama3-8b 모델에 대한 예제 입니다.
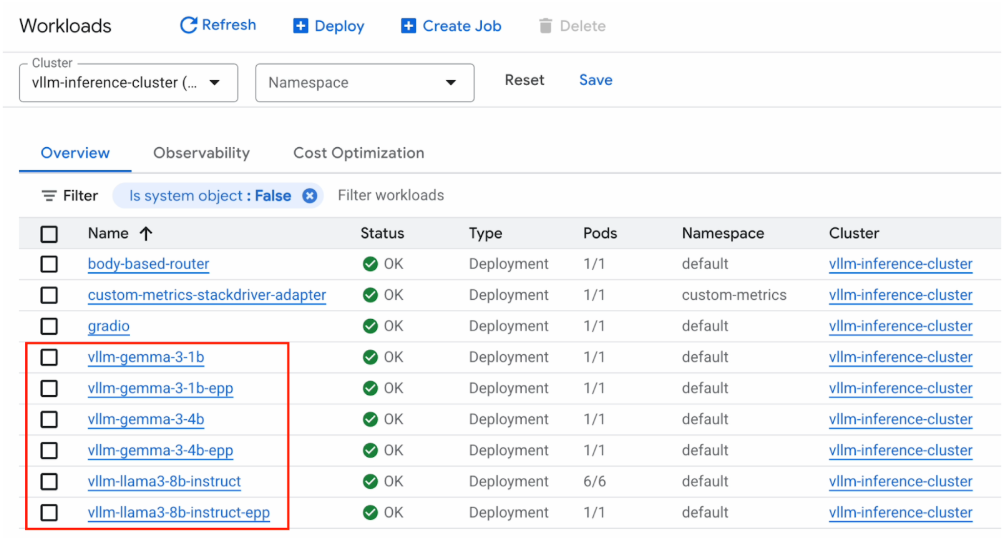
InferencePool을 구성하면 아래와 같이 ‘모델 워크로드명-epp’ 의 deployment가 추가로 생성되는 것을 확인할 수 있습니다. 이는 앞서 설명한 Endpoint Picker Extension으로 모델 리소스의 상태 정보를 모니터링하여 최적의 라우팅을 제공하기 위한 기능을 제공 합니다.
이제 InferenceModel 을 설정합니다. 아래 예제는 food-review 모델과 기본 베이스 모델을 앞서 설정한 InferencePool 에 생성하는 설정입니다.
참고로 모델의 중요도 (Criticality) 는 아래와 같이 3가지를 지원 합니다.
- Critical: 해당 모델을 가장 우선 처리하도록 하는 설정입니다. 시스템은 리소스 제약 조건에서도 해당 모델에 대한 요청이 처리되도록 보장합니다.
- Standard: 해당 모델은 리소스가 사용 가능할 때 처리됩니다. Critical 로 설정한 모델의 요청으로 인해 리소스가 제한되면 해당 모델에 대한 요청은 삭제될 수 있습니다.
- Sheddable: 이 모델은 기회적으로 처리됩니다. 리소스가 부족하면 주요 모델들을 보호하기 위해 이 모델에 대한 요청은 삭제됩니다.
다음으로 Gateway를 생성합니다. 앞서 설명드린대로 GKE Inference Gateway 는 기존 GKE 가 제공하는 Gateway 와 함께 동작합니다. 아래는 Regional External Application Load Balancer 의 GatewayClass 를 이용하여 로드밸런서를 생성하는 예제 입니다.
마지막으로 HTTPRoute 를 구성합니다. 일반적인 워크로드 환경에서의 백엔드는 clusterIP 서비스를 설정하지만 GKE Inference Gateway 에서는 앞서 설정한 InferencePool 을 백엔드 레퍼런스로 설정 합니다.
이제 GKE Inference Gateway 를 사용하기 위한 구성이 완료 되었습니다. 다음과 같이 모델에 대한 요청과 응답이 정상적으로 동작 하는지 확인합니다.
Request
Output 예
GKE Inference Gateway 의 효과
지금까지 GKE Inference Gateway 가 동작하는 방식과 실제 구성하는 방법에 대해서 살펴 보았습니다. GKE Inference Gateway 는 일반적인 워크로드와 리소스 환경의 지표가 아닌 KV 캐시 사용률과 Pending Queue 길이를 이용하여 부하분산과 최적의 라우팅을 제공합니다. 하지만 일반적인 구성 환경에서 사용하는 로드 밸런서를 적용하면 어떻게 될까요? 일정량의 LLM 추론 요청을 임의로 발생시켜 일반 로드밸런서와 GKE Inference Gateway를 아래와 같이 비교 해 볼 수 있습니다.

<일반 로드밸런서와 GKE Infererence Gateway 의 비교>
좌측의 그래프는 각 Pod와 이에 해당하는 GPU의 KV 캐시 사용률 입니다. 기존의 로드밸런서를 사용할 경우 KV 캐시의 사용률이 일률적이지 않고 특정 GPU는 사용률이 최대치에 도달하는 것을 확인할 수 있습니다. 하지만 동일한 조건으로 LLM 요청을 GKE Inference Gateway가 처리 시 모든 Pod와 GPU의 KV 캐시 사용률이 일정한 것을 확인할 수 있습니다.
우측의 그래프는 LLM 추론 처리시간 및 큐에서 대기 중인 요청 수 입니다. 기존 로드밸런서 사용 시 추론 요청 처리를 위해 많은 요청이 대기중이며 이로 인해 요청 처리 시간이 길어지는 지연 현상이 발생하는 것을 확인할 수 있습니다. 하지만 GKE Inference Gateway를 통해 처리되는 추론 요청은 대기나 지연 없이 효율적으로 리소스를 사용하여 빠르게 처리되는 것을 확인할 수 있습니다.
Google Cloud 는 GKE Inference Gateway를 이용한 최적의 추론 환경을 제공하며 기존 워크로드 환경과 비교하여 벤치마크 테스트 시 60% 이상 빠른 모델 요청 처리와 40% 이상의 요청 처리 성능을 제공합니다.

<기존 워크로드 환경과 GKE 환경의 추론 지연 비교>
AI 보안을 위한 확장과 연동 기능 제공
앞서 동작 방식에서 잠시 소개 해 드린대로 GKE Inference Gateway는 Security Extension 기능을 제공합니다. 이를 이용하여 Google Cloud의 AI 보안 서비스인 Model Armor와의 연동을 제공합니다.
Model Armor 는 AI 애플리케이션을 보호하기 위해 설계된 전문 보안 서비스입니다. AI 모델에 입력되는 프롬프트와 AI가 생성하는 응답을 실시간으로 검사하여 악의적인 입력을 방지하고, 콘텐츠 안전성을 검증하며, 민감한 데이터를 보호하고 규정을 준수하는 데 도움을 줄 수 있는 기능을 제공합니다.

보다 자세한 설명과 구성 방법은 ‘링크’ 를 통해 확인하실 수 있습니다.
OSS Gateway API Inference Extension
Google 은 내부적으로 15년 이상 사용해 온 컨테이너 관리 시스템인 Borg를 기반으로 하여 오픈소스로 개발한 OSS (Open Source Software) Kubernetes 를 2014년 공개하였으며 현재까지도 쿠버네티스 발전에 가장 큰 기여를 하고 있습니다. GKE Inference Gateway 또한 오픈소스 프로젝트인 Gateway API Inference Extension(Github)과 함께 릴리즈 되었습니다. 이번 릴리스는 GKE AI, GKE Networking 팀이 주도하여 최적화된 AI 추론을 위한 오픈소스 쿠버네티스 패러다임을 표준화하기 위해 2024년부터 수개월 동안 노력해 온 결과물입니다. 이 프로젝트는 Kubernetes Serving Working Group 주도의 프로젝트이자 노력의 결실이며 Google 뿐만 아니라 다양한 기업과 단체에 소속되어 있는 여러 구성원들의 노력으로 탄생할 수 있었습니다.

보다 자세한 내용은 아래 페이지를 통해 확인하실 수 있습니다.
https://gateway-api-inference-extension.sigs.k8s.io/
마치며
지금까지 AI와 LLM 추론 서비스를 위한 기존 방식의 한계, Google Cloud가 제공하는 GKE Inference Gateway 의 기능, 동작 방식을 이해하고 어떻게 문제를 해결할 수 있는지에 대한 데이터와 함께 실제 적용 방법까지 알아보았습니다. GKE Inference Gateway는 LLM 및 AI 에이전트 워크로드가 가지는 기술적 과제를 Kubernetes 네이티브 방식으로 해결하는 Google Cloud 의 기능입니다. 특히 KV Cache Utilization과 Pending Request Queue Leng 라는 지표를 종합적으로 모니터링하고 이를 라우팅 결정에 직접 활용함으로써 실제 AI 워크로드의 상태에 기반한 부하 분산을 수행합니다. 따라서 클라이언트 및 AI 에이전트의 추론 요청을 지연 없이 빠르게 처리할 수 있으며 GPU 리소스의 활용률을 극대화하고, 효율적이고 확장 가능한 AI 인프라와 워크로드 환경을 구현하며, 이제 AI 환경의 운영과 및 개발에 있어서는 애플리케이션 로직과 모델 성능 최적화에 더 집중할 수 있게 되었습니다.



