클라우드 ML 애플리케이션의 NCCL 성능 향상
Manoj Jayadevan
Group Product Manager, Networking
Jiuxing Liu
Engineer, Network Infrastructure
* 본 아티클의 원문은 2021년 5월 20일 Google Cloud 블로그(영문)에 게재되었습니다.
클라우드는 특수 머신러닝(ML) 하드웨어에 맞게 규모를 조정할 수 있어 뛰어난 민첩성을 제공하므로 심층신경망 학습에 매우 적합한 옵션입니다. 아울러 클라우드를 사용하면 손쉽게 시작하고 사용한 만큼만 요금을 지불하는 사용 모델이 제공됩니다. 또한 초기 및 최신 GPU 기술을 계속해서 이용할 수 있게 됩니다.
대규모 데이터 세트에 심층신경망을 적용하는 데 있어 가장 큰 걸림돌은 심층신경망 학습에 드는 시간과 리소스입니다. 프로덕션 환경에서 딥 러닝 모델을 사용하려면 재학습이 수시로 필요하므로 학습 시간을 최대한 단축하는 것이 중요합니다. 또한 예측 정확도를 높이기 위해 모델의 규모와 복잡성이 증가하고 있으므로 높은 수준의 컴퓨팅 및 스토리지 리소스가 필요합니다. 가격 대비 성능은 고객에게 여전히 중요한 고려사항이기에 딥 러닝 워크로드에 맞게 클라우드를 효과적으로 사용하기 위해서 노드 간 지연 시간을 최적화하는 것이 중요합니다.
ML 프레임워크(예: TensorFlow 또는 PyTorch)에서는 분산된 노드 간 GPU 통신에 NCCL 라이브러리를 사용합니다. NCCL(NVIDIA Collective Communication Library)은 신경망을 빠르게 융합하는 데 필수적인 멀티 GPU 및 멀티 노드 통신을 제공하여 흔히 사용되는 통신 라이브러리입니다. 또한 NCCL은 all-gather, all-reduce, broadcast, reduce, reduce-scatter, point-to-point send 및 receive와 같은 루틴도 제공합니다. 루틴은 노드 내부와 노드 간 네트워크에서 고대역폭과 짧은 지연 시간을 달성하는 데 최적화되어 있습니다.
NCCL 메시지 지연 시간을 단축하는 것은 우수한 애플리케이션 성능과 확장성을 제공하는 데 매우 중요한 요소입니다. 최근 Google Cloud는 손쉽게 NCCL 워크로드를 실행하고 Google Cloud에서 최적의 성능을 얻을 수 있는 몇 가지 기능과 미세 조정을 도입했습니다. '권장사항'으로 통칭되는 이러한 업데이트를 적용하면 NCCL 지연 시간이 단축되고 소량 메시지와 집합 작업에 의존하는 애플리케이션에 이점을 제공합니다.
이 블로그 게시글에서는 딥 러닝 학습 시간을 최대한 단축하도록 GCP 인프라를 최적화하는 방법을 설명합니다. 이를 위해 NCCL를 사용한 분산/멀티 노드 동기 학습에 대해 알아보겠습니다.
Google Cloud에서 최적의 NCCL 성능 실현
1.NCCL Fast Socket과 최신 DLVM 사용
Google Cloud는 분산 ML 학습에 맞게 NCCL 집합 통신 성능을 극대화하기 위해 NCCL Fast Socket이라는 통신 라이브러리를 설계했습니다. NCCL 전송 플러그인으로 개발된 NCCL Fast Socket은 Google Cloud에서 NCCL 성능을 대폭 향상하는 최적화를 적용합니다. 이러한 최적화에는 다음이 포함됩니다.
- 여러 네트워크 흐름을 사용하여 처리량 극대화. NCCL Fast Socket은 중복되는 여러 통신 요청을 효율적으로 처리하는 등 NCCL의 기본 제공 멀티 스트림 지원을 통해 추가적인 최적화를 제공합니다.
- 여러 네트워크 흐름의 동적 부하 분산. 변화하는 네트워크 및 호스트 조건에 맞게 NCCL을 조정할 수 있습니다. 이러한 최적화 덕분에 straggler 네트워크 흐름이 있어도 전체 NCCL 집합 작업의 속도가 크게 저하되지 않습니다.
- Google Cloud의 Andromeda 가상 네트워크 스택과 통합. 이 통합으로 Andromeda와 게스트 가상 머신(VM) 간 경합이 방지되어 전반적인 네트워크 처리량이 증가합니다.
무엇보다 핵심 NCCL 라이브러리가 런타임에 NCCL Fast Socket을 동적으로 로드할 수 있습니다. 따라서 Google Cloud 사용자는 애플리케이션, ML 프레임워크(예: TensorFlow, PyTorch) 또는 NCCL 라이브러리를 변경하거나 다시 컴파일하지 않고도 NCCL Fast Socket을 이용할 수 있습니다.
현재 최신 딥 러닝 VM(DLVM) 이미지에 NCCL Fast Socket이 포함되어 있습니다. DLVM에 포함된 NCCL 라이브러리를 사용하면 자동으로 활성화됩니다. 여기에 설명된 안내를 따라 NCCL Fast Socket을 수동으로 설치할 수도 있습니다.
2. gVNIC 사용
NCCL에서 네트워크 처리량을 늘리려면 VM 인스턴스를 만들 때 Google Virtual NIC(gVNIC)를 사용 설정해야 합니다. GPU가 실행되고 분산 ML 학습에 사용되는 VM과 같이 성능 및 네트워크 처리량 요구사항이 엄격한 VM의 경우 gVNIC를 기본 네트워크 인터페이스로 사용하는 것이 좋습니다. 현재 gVNIC는 최대 100Gbps의 네트워크 처리량을 지원할 수 있으므로 NCCL의 성능을 대폭 향상시켜 줍니다. gVNIC를 사용하는 방법에 대한 자세한 안내는 gVNIC 가이드를 참고하세요. DLVM은 gVNIC를 즉시 지원하는 이미지도 제공합니다.
3. 사용 가능한 대역폭 최대화
VM에서 GPU 통신은 NVIDIA NVLink를 이용하여 VM 간 네트워킹보다 더 높은 처리량을 달성할 수 있습니다. 따라서 NVLink 대역폭을 최대한 사용하도록 하나의 VM에 가능한 한 많은 GPU를 패킹하는 것이 좋습니다. 여러 VM을 사용하는 경우 사용 가능한 네트워킹 대역폭을 최대화하기 위해 많은 수의 vCPU(96)를 사용하는 것이 좋습니다. 자세한 내용은 네트워크 대역폭 및 GPU 문서 페이지를 참고하세요.
4. 압축 배치 정책 사용
특정 GPU VM 유형(예: N1)에서 압축 배치 정책을 지원할 수 있습니다. VM을 서로 근접하게 할당하면 네트워크 성능이 향상되고 간섭이 줄어듭니다. 분산 학습은 지연 시간에 민감할 수 있으므로 압축 정책을 지원하는 VM 유형을 사용해야 합니다. 자세한 내용은 압축 정책 문서 페이지를 참고하세요.
향상된 성능 데이터의 예시:
NCCL Fast Socket은 NCCL 집합 작업과 ML 모델의 분산 학습에 맞게 성능을 향상합니다. NCCL Fast Socket과 스톡 NCCL을 비교한 몇 가지 예시가 아래에 나와 있습니다. (Google Cloud의 테스트에서 NCCL Fast Socket은 동일한 수의 네트워크 흐름과 도우미 스레드를 사용했습니다.) gVNIC 드라이버 버전 v1.0.0을 사용했습니다.
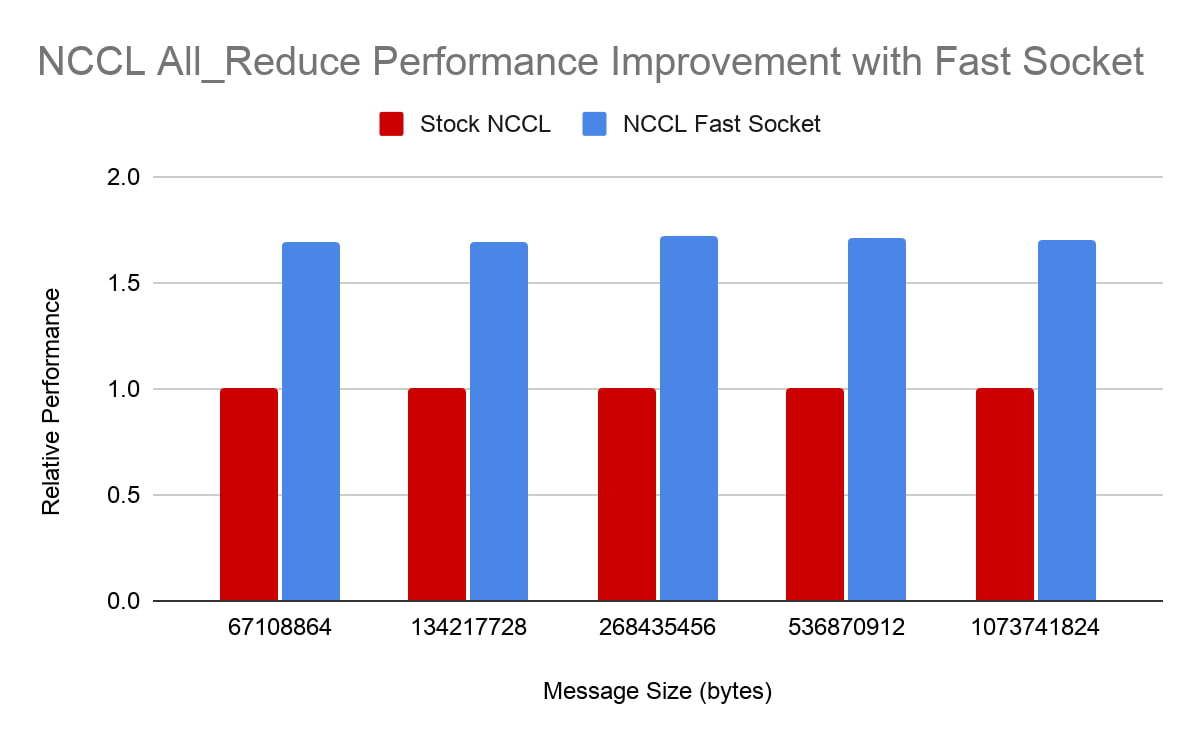
NCCL All_Reduce
All_Reduce는 NCCL에서 가장 중요한 집합 작업 중 하나입니다. ML 모델의 분산 학습에서 경사 집계에 자주 사용됩니다. 이 그림에는 2개의 VM에서 16개 NVIDIA V100 GPU를 사용하는 경우 NCCL All_Reduce 테스트의 성능이 나타나 있습니다. NCCL Fast Socket이 메시지 크기와 상관없이 All_Reduce 성능을 일관적으로 대폭 향상한다는 점을 이 그림을 통해 확인할 수 있습니다. (그림에서 막대가 높을수록 성능이 우수한 것입니다.)
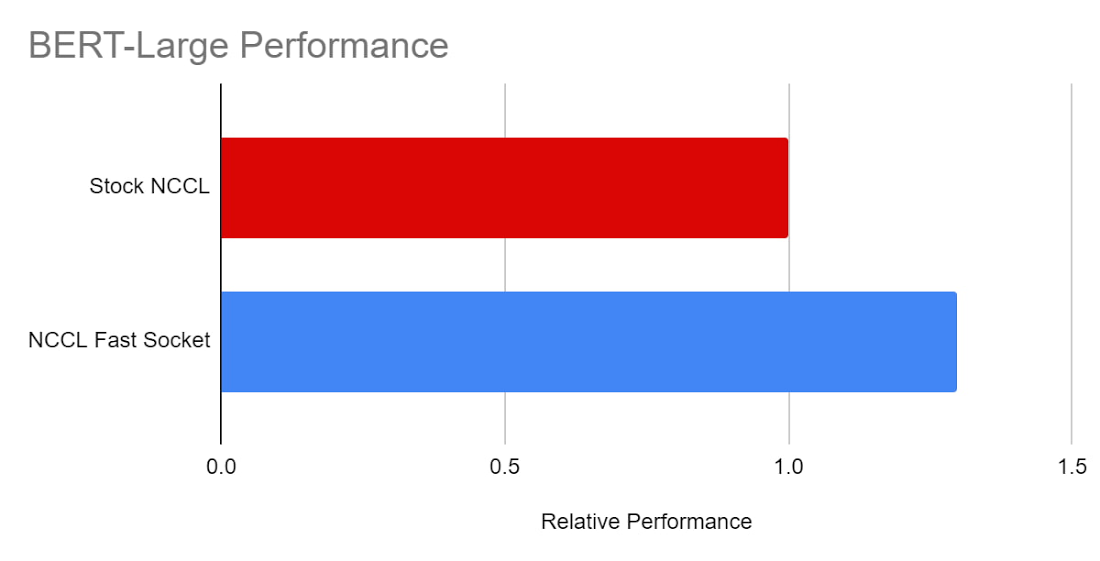
BERT-Large
또한 TensorFlow 모델인 BERT-Large에서 NCCL Fast Socket으로 인한 성능 향상을 알아보는 테스트를 진행했습니다. 본 테스트에서는 8개의 VM에서 64개 NVIDIA V100 GPU를 사용했습니다. NCCL Fast Socket을 사용하면 BERT-Large의 학습 속도가 크게(약 30%) 향상되는 것을 확인할 수 있습니다.
이제 Google Cloud에서 NCCL 애플리케이션을 더 쉽고 빠르게 실행할 수 있습니다.
이제 Google Cloud에서 NCCL 애플리케이션을 그 어느 때보다도 손쉽게 실행할 수 있습니다. NCCL Fast Socket 사용을 포함한 이 권장사항을 적용하면 애플리케이션 성능이 향상될 수 있습니다. NCCL Fast Socket의 배포 간소화를 위해 DLVM 이미지에 이 기능을 포함했으므로 Google Cloud에서 NCCL 워크로드를 처리할 때 즉시 최상의 성능을 얻을 수 있을 것입니다.
자세한 내용은 Fast Socket으로 네트워크 대역폭 속도 향상을 설명한 문서를 참고하세요.
도움을 주신 창 랜, 소루쉬 라드포에게 감사의 말을 전합니다.


