時間を紐解く: TTD 命令エミュレーションのバグを深く掘り下げる
Mandiant
※この投稿は米国時間 2025 年 3 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
エグゼクティブ サマリー
このブログ投稿では、Microsoft の Time Travel Debugging(TTD)フレームワークについて詳しく見ていきます。TTD は、Windows ユーザーモード アプリケーション向けの強力な記録 / 再生型デバッグ フレームワークです。TTD は、プログラムの実行を忠実に再生するにあたり、正確な CPU 命令エミュレーションに大きく依存しています。ただし、このエミュレーション プロセス内に微細な不正確さが存在すると、重大なセキュリティや信頼性の問題が生じる可能性があります。脆弱性が隠されたり、重要な調査(特にインシデント対応やマルウェア分析)が誤った方向に導かれたりすれば、アナリストは脅威を見逃したり、誤った結論を導き出したりするでしょう。さらに、攻撃者がこのような不正確さを悪用して、意図的に検出を回避したり、フォレンジック分析を妨害したりすれば、調査結果が著しく損なわれることになりかねません。
このブログ投稿では、特定の課題を調査し、これまでの状況を説明し、実際のエミュレーションのバグを分析して、調査ツールの有効性と信頼性を確保するには正確性と継続的な改善が極めて重要であることを明らかにします。エミュレーションの問題に対処することで、セキュリティ分析を強化し、信頼性を向上させ、自信を持ってデバッグや調査プロセスを行えるようになるため、最終的にはユーザーに直接的なメリットがもたらされます。
概要
まず、TTD の概要を説明し、Nirvana ランタイム エンジンを活用した高度な CPU エミュレーション レイヤの使用について詳しく説明します。Nirvana は、ゲスト命令をホストレベルのマイクロオペレーションに変換するもので、プログラムの実行履歴を詳細にキャプチャして正確に再生できるようにします。
次に、CPU エミュレーション、特に、複雑な x86 アーキテクチャにおけるこれまでの課題を見ていきます。主な課題として、浮動小数点演算や SIMD 演算の問題、メモリモデルの複雑さ、周辺機器やデバイスのエミュレーション、自己変更コードの処理、パフォーマンスと精度の継続的なトレードオフなどがあります。これらの基本的な分析情報は、TTD 内で発見された特定の命令エミュレーションのバグをさらに詳しく調べるための地固めとなります。
バグには次のようなものが含まれます。
-
pop r16のエミュレーションに関連するバグ。結果として、ネイティブな実行と TTD の計測の間で重大な不一致が生じていました。 -
push segment命令に関する問題。これによって Intel CPU と AMD CPU の実装の相違が実証され、ハードウェアの動作に合わせた正確なエミュレーションの重要性が明らかになりました。 -
lodsb命令とlodsw命令の実装におけるエラー。変更すべきでない上位ビットが TTD で誤ってクリアされていました。 -
WinDbg TTDAnalyze デバッグ拡張機能内の問題。シンボルのクエリ中に固定出力バッファでデータが切り詰められ、結果としてデバッグの正確性が損なわれていました。
各ケースは、詳細な分析、アセンブリ コードの概念実証サンプル、デバッグ トレースで裏付けられており、TTD に関連して、最新の CPU エミュレーションの軽微ながら重大な落とし穴を表します。
発見されたバグのうち、ここに記載したもの以外は、Microsoft が対応するまで開示を保留しています。この投稿で取り上げるバグはすべて、TTD バージョン 1.11.410 の時点で解決されています。
TTD の概要
Time Travel Debugging(TTD)は、Microsoft が開発した強力なユーザーモードの記録 / 再生型フレームワークで、最初は 2006 年のホワイトペーパーで別の名前で紹介されました。これは Windows 環境に関連するワークフローでは定番となっています。
TTD を使用すると、プロセスの実行中にプロセス(および潜在的な子プロセス)の包括的な記録をキャプチャできます。これを行うには、ダイナミック リンク ライブラリ(DLL)を目的の対象プロセスに挿入し、実行の各状態をキャプチャします。このプログラムの実行時の動作の包括的な履歴ビューは、データベースのようなトレース ファイル(.trace)に保存されます。データベースと同じように、このファイルをさらにインデックス化して、対応する .idx ファイルを生成し、効率的なクエリや分析を行うことができます。
記録されたトレース ファイルは、実行履歴全体の再生をサポートしている、互換性のあるクライアントで使用できます。つまり、TTD は実質的に記録 / 再生型デバッガとして機能し、アナリストはこれを使用して、プログラムのライフサイクルの一時的なスナップショットを見て回るかのように、実行状態全体を前後に移動できます。
TTD は、CPU エミュレーション レイヤを利用してプログラムの実行を正確に記録し、再生します。このレイヤは、Nirvana ランタイム エンジンによって実装されていて、このエンジンがゲスト命令をより単純なホストレベルのマイクロオペレーションのシーケンスに変換してシミュレートします。このようにして、Nirvana で命令とサブ命令レベルでのきめ細かい制御が行われていて、命令処理の各ステージ(フェッチ、メモリの読み取り、書き込みなど)に計測手法を挿入できます。このアプローチにより、TTD は元のバイナリの動的動作を完全にキャプチャできるだけでなく、後で実行を正確に再シミュレートできます。
Nirvana の動的なバイナリ変換とコード キャッシュ保存の技術は、変換されたシーケンスを可能な限り再利用してパフォーマンスを向上させています。コードの自己変更シナリオなど、コードが予測不可能な挙動をする場合、Nirvana は必要に応じて純粋な解釈モードに切り替えたり、命令を再変換したりできます。このような適応戦略によって、TTD は忠実度と効率を確実に維持した記録 / 再生プロセスを実現し、実行トレースを保存して、分析対象となるコードの挙動を完全に再シミュレートして複雑な詳細を解明できます。
TTD フレームワークは、次のコア コンポーネントで構成されています。
-
TTD: メインの TTD クライアント実行可能ファイルで、トレースの実施方法を指定するさまざまな入力引数を入力として受け取ります。
-
TTDRecord: TTD クライアント実行可能ファイル内で実行される記録処理を担うメインの DLL。TTDLoader.dll を挿入して、ターゲット バイナリへの挿入シーケンスを開始します。
-
TTDLoader: ゲストプロセスに挿入され、TTDRecordCPU DLL を介してゲスト内でレコーダーを開始する DLL。また、ゲストプロセス内でプロセス計測コールバックを確立し、ゲストが行うシステム呼び出しの下り(外向き)を Nirvana がモニタリングできるようにします。
-
TTDRecordCPU: 実行状態を .trace ファイルにキャプチャするレコーダー。これは DLL としてゲストプロセスに挿入され、TTDRecord にトレースの状態を通知します。コアロジックは、それぞれの CPU をエミュレートすることで機能します。
-
TTDReplay と TTDReplayClient: キャプチャされた状態をトレース ファイルから読み取り、記録された実行をユーザーが 1 ステップずつ実行できるようにする再生コンポーネント。
-
Windbg は、これらのコンポーネントを使用して、トレース ファイルの置き換えに対応しています。
-
TTDAnalyze: 再生クライアントと統合された WinDbg 拡張機能で、TTD 専用機能を WinDbg に提供します。特に注目すべき機能は、Calls と Memory のデータモデル メソッドです。
CPU エミュレーション
これまで、CPU エミュレーションは、特に x86 のような複雑なアーキテクチャでは、エンジニアリングの長年の課題でした。初期の課題は命令の完全性と正確性です。文書化されていない動作やハードウェア エラッタにより、微妙に異なるコーナーケースをすべて再現することが困難な状況でした。徐々に、次のような繰り返し発生する問題領域やバグクラスが浮かび上がってきました。
-
浮動小数点演算と SIMD 演算: 浮動小数点演算命令は、精度モードやレジスタ状態がさまざまであるため、軽微なバグの原因となることがよくあります。浮動小数点の丸めを誤算したり、正規化されていない数値を誤って処理したり、FSIN や FCOS などの特殊な命令を誤って実装したりすると、サイレント データ破損や完全なクラッシュにつながる可能性があります。同様に、SSE や AVX などのベクトル化された命令により、正確な追跡が必要となる複雑な状態が生まれます。
-
メモリモデルとアドレス指定の問題: x86 アーキテクチャのメモリモデルには、セグメンテーション、ページング、アライメント制約があり、レガシーコードでアライメントの不整合が生じる可能性があるため、複雑なバグを生じさせる可能性があります。メモリアクセスを正しくエミュレートしなかったり、適切なページ境界を適用しなかったり、「遅延読み込み」ページフォルトやキャッシュ整合性を処理できなかったりすると、ごく限定的な条件下でのみ発生する軽微なエラーにつながる可能性があります。
-
周辺機器とデバイスのエミュレーション: シリアル I/O ポート、PCI デバイス、PS/2 キーボード、以前のコントローラなど、x86 固有の周辺機器の動作をエミュレートするのは特に厄介です。このようなコンポーネントは、ドキュメント化されていない動作やタイミングの癖に依存していることがよくあります。デバイス固有のレジスタを誤って解釈したり、タイミングによって異なる反応を再現しなかったりすると、間違ったエミュレータ動作やデバイスの誤作動につながる可能性があります。
-
古いプロセッサや特殊なプロセッサとの互換性: 古い世代の x86 プロセッサにはそれぞれ独自の特殊性があり、機能があまり標準化されていないため、エミュレートするのは困難です。デフォルト モードの設定、命令のバリアント、保護モードとリアルモードのセマンティクスの相違によって、予期しない破損が発生する可能性があります。一度は動作していたエミュレータでも、わずかに異なるマイクロアーキテクチャ用に記述されたコードや、非推奨の命令、古い CPU に異なる方法で実装されていた命令を受け取ると失敗することがあります。
-
自己変更コードと動的変換: 実行時に自己変更するコードには、キャッシュ保存された変換の無効化や、元のコードバイトの動的な再チェックといった適応戦略が必要です。このようなシナリオを誤って処理すると、最新でないコードの変換につながったり、最適化が誤って適用されたり、追跡が困難な論理エラーが発生したりする可能性があります。
-
パフォーマンスと精度のトレードオフ: これまで、CPU エミュレータの実装においては、多くの場合、精度とパフォーマンスをバランスを取りながら調整する必要がありました。命令を単純に 1 つずつ解釈すると正確性が得られますが、処理が遅くなりました。キャッシュ保存やジャストインタイム(JIT)ベースの最適化を導入すると、メモリ更新と適切に同期されなかったり、命令の境界が適切に維持されなかったりした場合に、同期に関する軽微な問題やバグが発生するリスクがありました。
これらの過去の課題を総合すると、CPU エミュレーションは単なる命令のデコードではないことがわかります。プロセッサの状態、メモリ階層、周辺機器の相互作用、タイミング特性といった複雑な詳細を忠実に再現する必要があります。ドキュメントとツールは改善が進んでいるものの、正確性と効率の両方を達成するには、引き続き細心の注意を払ってバランスを取る必要があります。エミュレーション プロジェクトは、このような永続的な複雑さに対処すべく進化を続けています。
最初の TTD バグ
高度に難読化された 32 ビット Windows Portable Executable(PE)ファイルを TTD 計測下で実行すると、クラッシュが発生しました。同じサンプル ファイルを実際のコンピュータや仮想マシンで実行したところ、クラッシュは発生しませんでした。そこで、サンプルが TTD の実行を検出しているか、TTD 自体に命令のエミュレーションに関するバグがあるかのどちらかではないかと考えました。TTD の問題のデバッグでは都合の良いことに、ほとんどの場合、TTD のトレース ファイル自体を使用して問題の原因を特定できます。図 1 は、TTD エミュレーション中に発生したクラッシュを示しています。

図 1: レジスタ ESI が指すアドレスにアクセスしたときに発生したクラッシュ
ESI のレジスタ値を 0xfb3e まで逆トレースすると、数百の命令をさかのぼって、図 2 に示すような命令のシーケンスになりました。
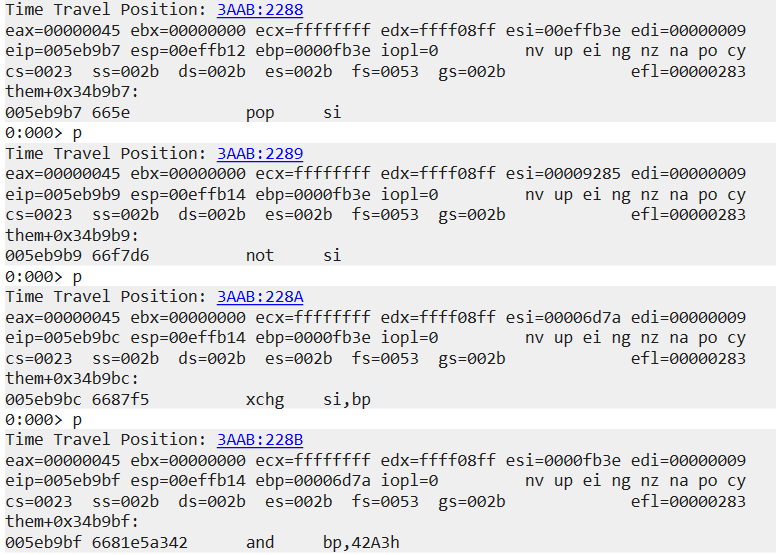
図 2: pop si と xchg si,bp によるレジスタ ESI へのデータ入力
ESI レジスタにデータを入力する 2 つの命令があります。どちらも 16 ビットのサブレジスタである SI を扱い、ESI レジスタの他の 16 ビット部分は完全に無視します。図 2 の pop si 命令の後の結果をよく見ると、ESI レジスタの上位 16 ビットが null に設定されているようです。これは pop r16 命令のエミュレーションのバグのように思われるため、検証のために概念実証コードを簡単に作成しました(図 3)。
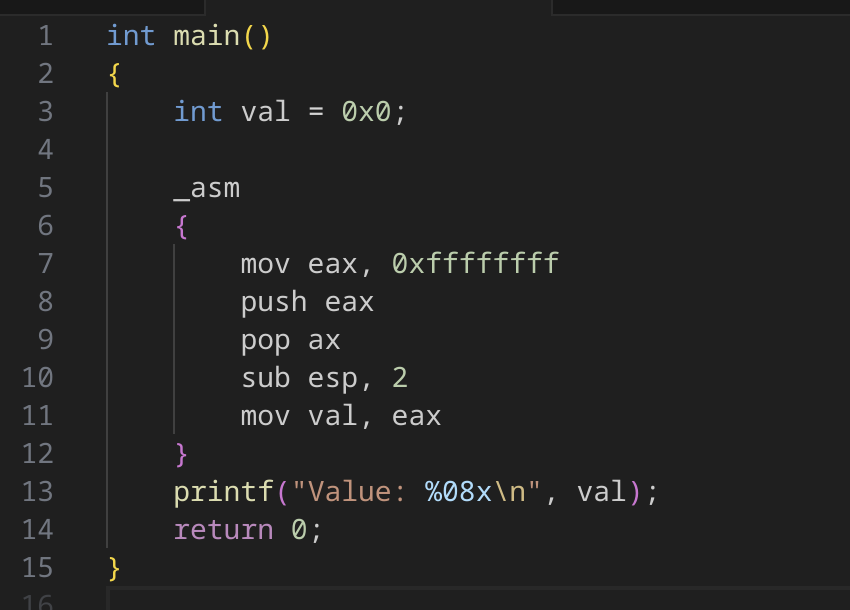
図 3: pop r16 の概念実証
図 4 に示すように、結果として得られたバイナリをネイティブに実行し、TTD 計測手法を使った実行と比較したところ、TTD での pop r16 命令のエミュレーションが、実際の CPU とは異なることが確認されました。
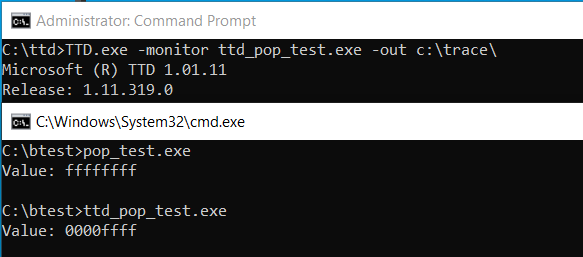
図 4: ネイティブと TTD 計測ありでコードを実行
この問題とファジングの結果を Microsoft の TTD チームに報告しました。
TTD のファジング
命令エミュレーションのバグ(実際の実行と TTD の実行で異なる結果を生成する命令シーケンス)が 1 つ見つかったことから、同様のバグを見つけるために TTD をファジングすることにしました。ランダムな一連の命令を実行して結果の値を記録するために、基本的なハーネスを作成しました。このハーネスを実際の CPU と TTD 計測下で実行し、2 つの結果セットを入手しました。結果が変わる場合や結果の一部が欠けている場合は、命令エミュレーションのバグである可能性があります。
結果
バグ 1: push segment 命令エミュレーションの不一致
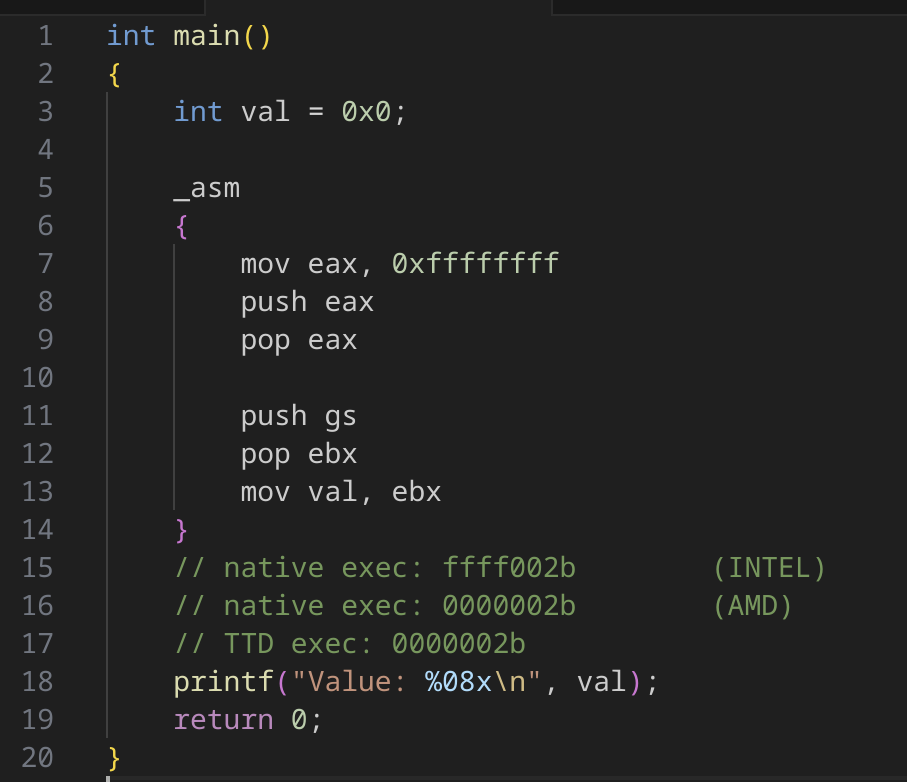
図 5: push segment の概念実証
この新しいバグは、元の pop r16 バグとよく似ていますが、push segment 命令にまつわるものです。また、このバグには少しひねりがあります。Intel CPU ベースのマシンでファザーを実行したところ、1 人はローカルでバグを確認しましたが、もう 1 人はバグを確認できませんでした。興味深いことに、この障害は AMD ベースの CPU で発生しました。これは、push segment 命令の実装が Intel CPU と AMD CPU で異なる可能性を示唆しています。
Intel CPU と AMD CPU の仕様を見ると、Intel の仕様では、最近のプロセッサに push segment register 命令がどのように実装されているかについて詳しく説明されています。
ソース オペランドがセグメント レジスタ(16 ビット)で、オペランドのサイズが 64 ビットの場合、ゼロ拡張された値がスタックに push されます。オペランドのサイズが 32 ビットの場合、ゼロ拡張された値がスタックに push されるか、16 ビットの移動を使用してセグメント セレクタがスタックに書き込まれます。最後のケースでは、最近の Intel Core および Intel Atom プロセッサはすべて 16 ビットの移動を実行し、スタック ロケーションの上部は変更されません。(Intel 仕様 Vol.2B 4-517)
Google がこの不一致を AMD PSIRT に報告したところ、AMD PSIRT は、これはセキュリティの脆弱性ではないと結論付けました。2007 年頃、Intel CPU と AMD CPU が push segment 命令を異なる方法で実装し始め、TTD エミュレーションは古い方法に従ったようです。
バグ 2: lodsb / lodsw 命令エミュレーションの不一致
lodsb と lodsw は、32 ビット命令と 64 ビット命令のどちらに対しても正しく実装されていません。どちらもレジスタ(rax / eax)の上位ビットをクリアしますが、元の命令はそれぞれの粒度を変更するだけです(つまり、lodsb は 1 バイトだけを上書きし、lodsw は 2 バイトだけを上書きします)。
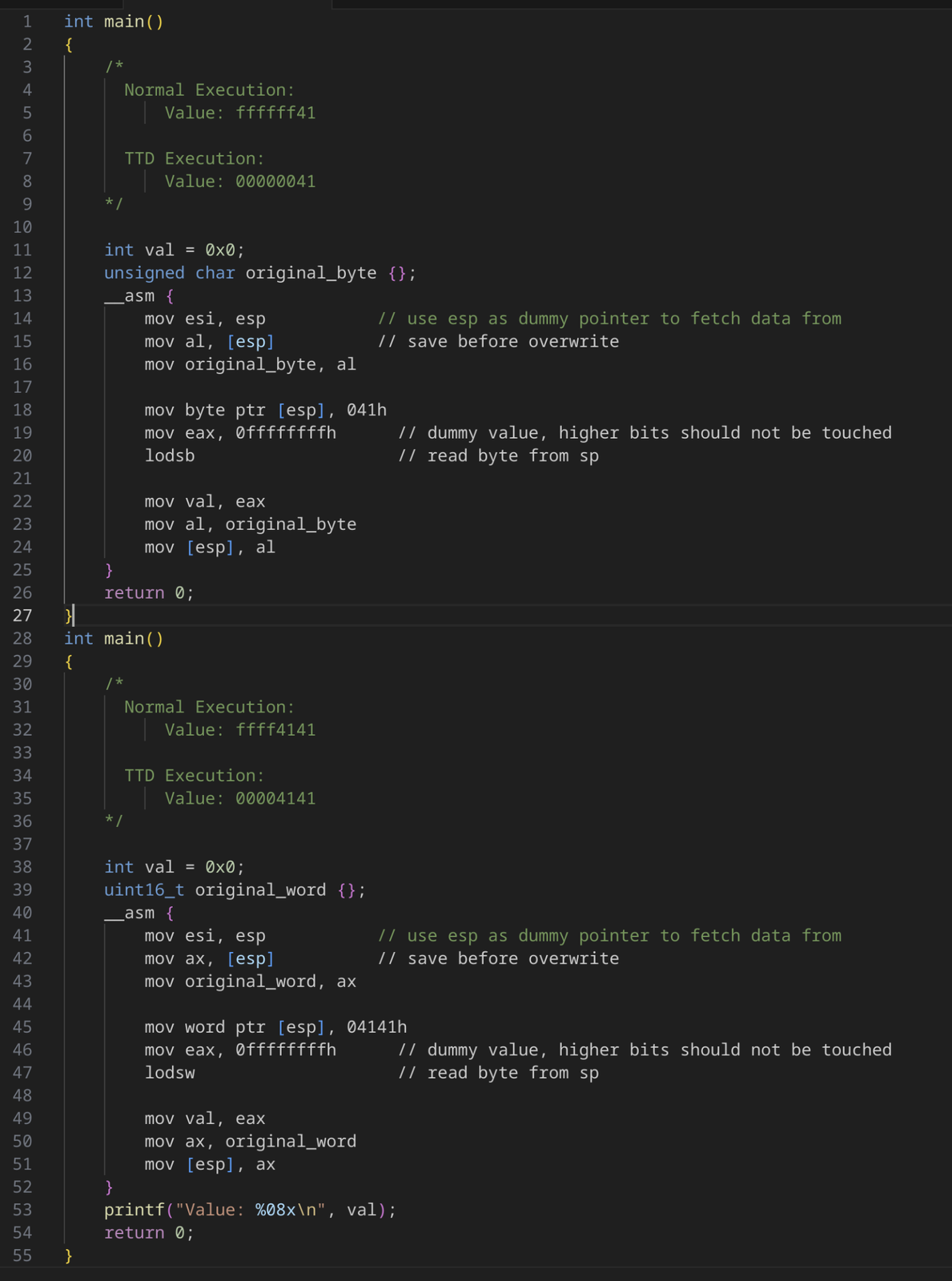
図 6: lodsb / lodsw の概念実証
その他にも Microsoft による修正が済んでいない命令エミュレーションのバグがあります。
バグ 3: Windbg TTDAnalyze の出力キャプチャの切り捨て
CPU エミュレータでの検証を進めていたところ、偶然別のバグに遭遇しました。今回はエミュレータではなく、TTD によって公開されている Windbg 拡張機能 TTDAnalyze.dll 内で発生したものです。
この拡張機能は、デバッガのデータモデルを活用して、ユーザーがインタラクティブにトレース ファイルを操作できるようにします。これは、現在のプロセス(@$curproces)、現在のスレッド(@$curthread)、現在のデバッグ セッション(@$cursession)など、データモデルの特定の部分で TTD データモデルの名前空間を公開することで実現します。
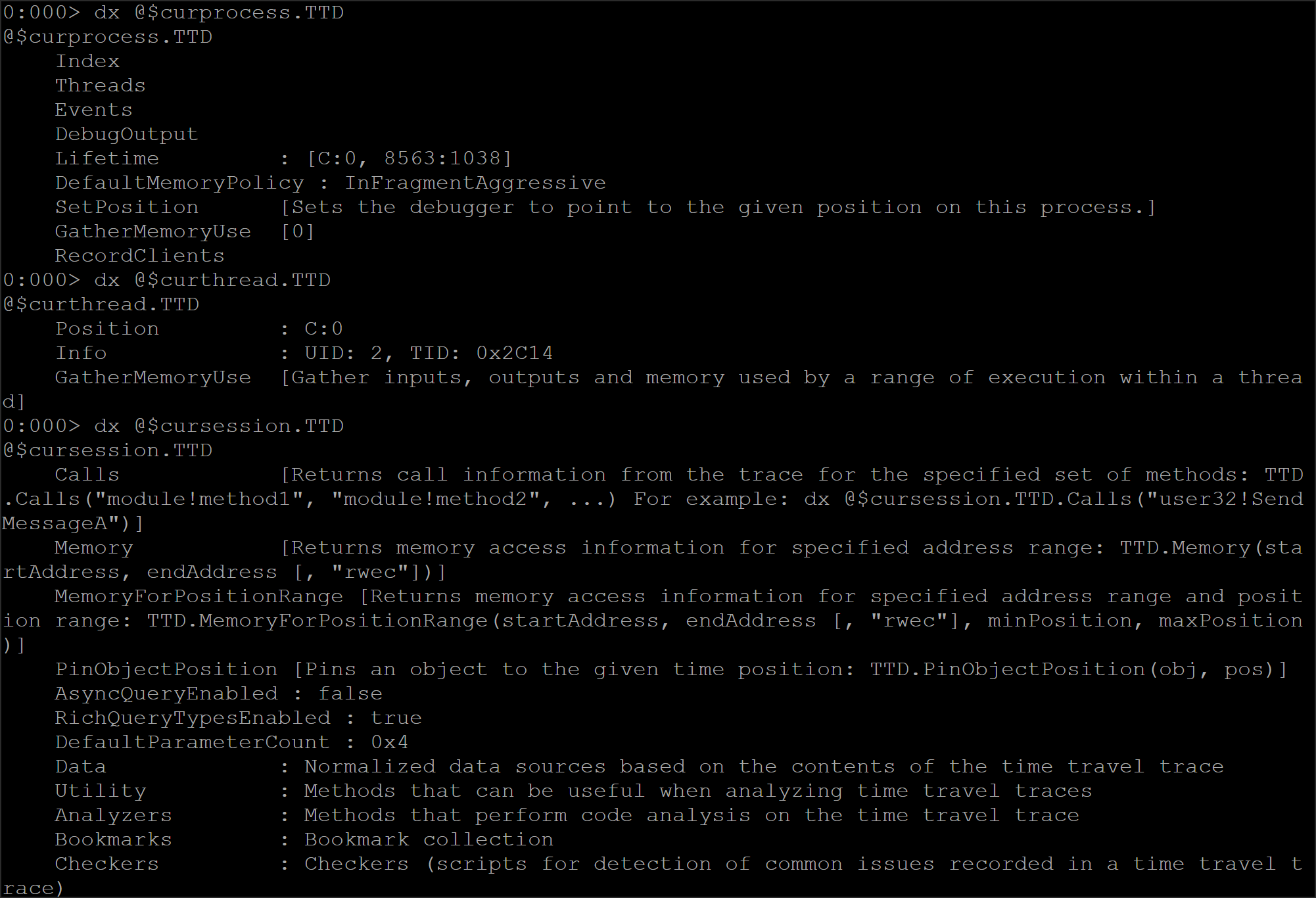
図 7: TTD のクエリタイプ
たとえば、@$cursession.TTD.Calls メソッドを使用すると、トレース内でキャプチャされたすべての呼び出しロケーションをクエリできます。入力として、アドレスまたは正規表現に対応した大文字と小文字を区別しないシンボル名を指定します。シンボル名は、文字列(引用符付き)または解析されたシンボル名(引用符なし)の形式にします。このデータモデルでは、プライベート シンボルを ObjectTargetObject オブジェクトに変換して、dx 評価式パーサーで使えるようにします。そのため、引用符付き文字列の形式はシンボルが完全に解決されている場合にのみ適用されます(例: プライベート シンボル)。
問題のバグは、@$cursession.TTD.Calls の下で公開されている Calls メソッドに直接影響します。というのは、このメソッドは固定の静的バッファを使用して、シンボルクエリの結果をキャプチャするためです。図 8 では、このことを示すために、結果が同じでない 2 つの似た正規表現文字列を渡しています。

Figure 8: TTD Calls query
C* と Create* をクエリした場合、C* のクエリ結果には、トレースで明らかにキャプチャされていた他の Create API は返されません。内部では、TTDAnalyze が調査デバッガ コマンド「x KERNELBASE!C*」を実行し、カスタム出力キャプチャを使用して結果を処理します。この出力キャプチャは、キャプチャされたデータのサイズが 64 KB を超えるとデータを切り捨てます。
修正前の TTDAnalyze(SHA256 CC5655E29AFA87598E0733A1A65D1318C4D7D87C94B7EBDE89A372779FF60BAD)のグローバル バッファと出力キャプチャ ルーチンの逆アセンブリを見ると、次のようになっています(図 9 と図 10)。
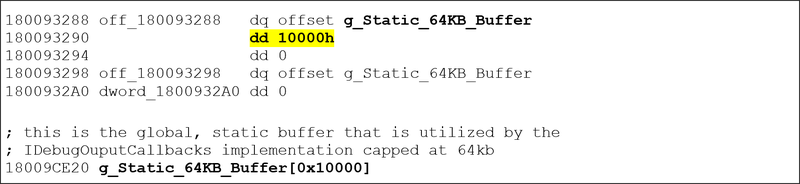
図 9: TTD 実装の逆アセンブリ
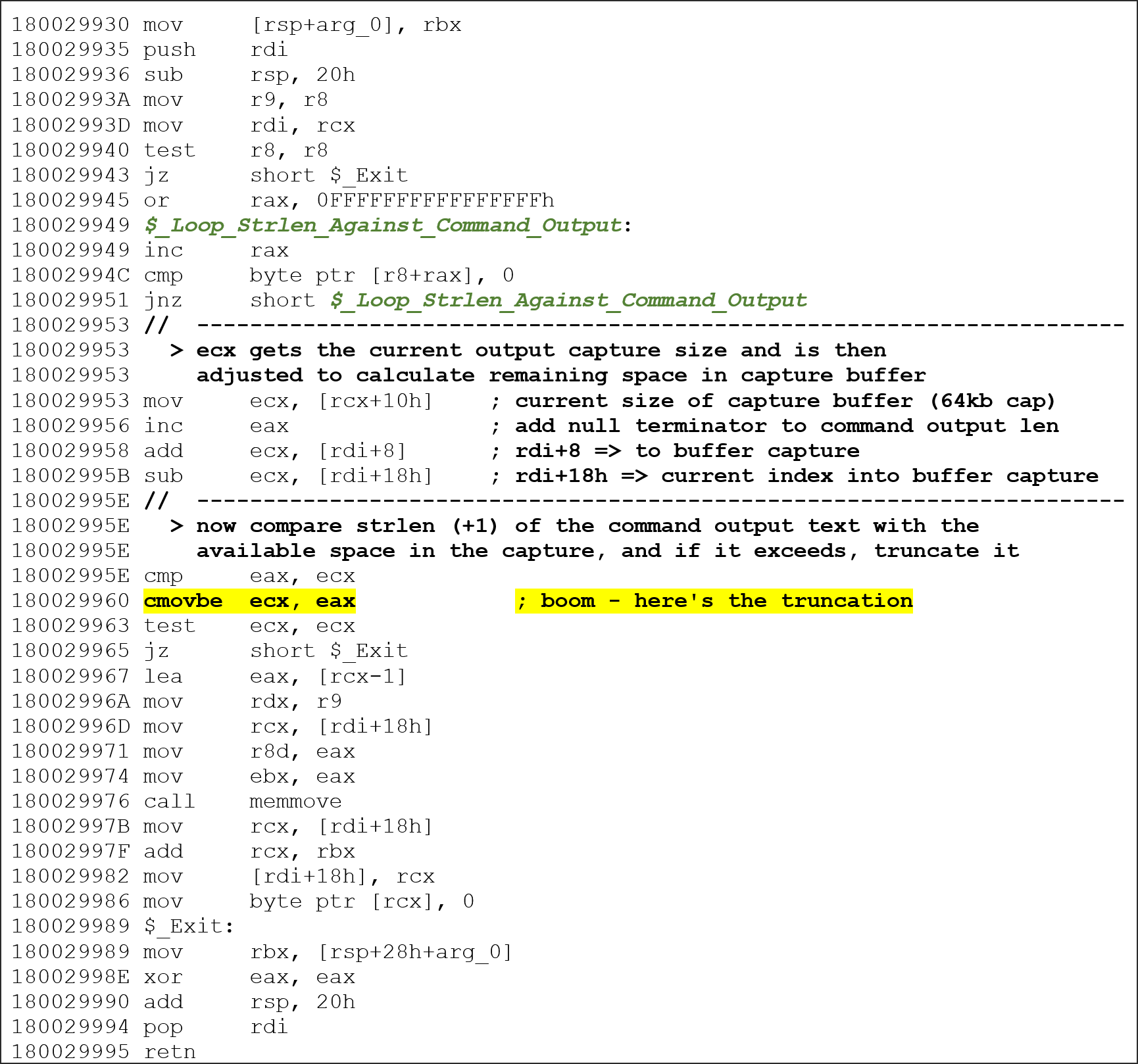
図 10: TTD 実装の逆アセンブリ
examine コマンドのキャプチャの上限は 64 KB です。返されるデータがこの上限を超えると、アドレス 0x180029960 で切り捨てが行われます。当然のことながら、C* で始まるシンボルをクエリすると、Create* で始まるシンボルだけでなく、通常は大量の結果が返されるため、結果としてデータの切り捨てが行われます。
最後に
このブログ投稿で紹介した分析は、命令エミュレーションにおける精度が、デバッグだけでなく、堅牢なセキュリティ分析のためにも不可欠であることを示しています。観察された不一致は軽微なものですが、より広範なセキュリティ上の懸念を浮き彫りにします。エミュレーション動作ではわずかな相違であっても、コードの実際の実行が誤って表現されることで、脆弱性が隠されたり、フォレンジック調査が誤った結果に導かれたりする可能性があります。
この調査は、次のようなセキュリティ上の課題を明らかにします。
-
デバッグツールの信頼性: TTD のようなフレームワークは、リバース エンジニアリングやインシデント対応に非常に有益です。ただし、pop r16、push セグメント、lods* 命令の誤った解釈によって露呈したように、エミュレーションの不正確さによって、分析の忠実度が損なわれる可能性があります。これは、Google のデバッグツールを使用して潜在的に悪意のあるコードや重大なコードを分析する場合に、そのツールに対する信頼性に関して重要な問題を引き起こします。
-
脅威分析への影響: マルウェアの隠れた挙動を明らかにしたり、複雑な脆弱性利用型不正プログラムを理解したりするには、プロセスの実行を忠実に再生する機能が不可欠です。命令エミュレーションのバグによって、実行パスや状態が意図せず変更され、結果として不完全な分析情報や偏った分析情報が生成されると、セキュリティ調査の結果に影響を及ぼす可能性があります。
-
コラボレーションと継続的な改善: これらのバグの発見と、その後の詳細なドキュメント化、Microsoft と AMD の関連チームへの報告は、セキュリティ調査における共同アプローチの重要性を浮き彫りにしています。継続的なテスト、ファジング、プラットフォーム間の比較は、分析ツールの完全性とセキュリティを維持するうえで不可欠です。
結論として、この調査は TTD 内の CPU エミュレーションの繊細な課題を明らかにしただけでなく、デバッグ フレームワークの精査の強化と厳格な検証を求める行動喚起の役割を果たすものでもあります。これらのツールでネイティブな実行を正確に映し出すことで、セキュリティ ポスチャーを強化し、進化し続けるデジタル環境において巧妙な脅威を検出、分析してこれに対応する能力を向上させることができます。
謝辞
報告した問題の解決に快く協力してくださった Microsoft の Time Travel Debugging チームの皆様に感謝の意を表します。チームの皆様との迅速かつ明確なコミュニケーションにより、バグが解決されただけでなく、TTD を堅牢で信頼性の高いものにするという Microsoft の真摯な姿勢が明らかになりました。また、トラブルシューティングと Windows セキュリティ研究の推進の両方にとって貴重なリソースである TTD を公開してくださったことについても深く感謝申し上げます。
-Mandiant、執筆者: Dhanesh Kizhakkinan、Nino Isakovic
