ScatterBrain: PoisonPlug の難読化コンパイラの隠された正体を暴く
Mandiant
※この投稿は米国時間 2025 年 1 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
2022 年以降、Google Threat Intelligence グループ(GTIG)は中国との関連が疑われるエスピオナージ アクターが POISONPLUG.SHADOW を使って行っている複数のサイバー エスピオナージ活動を追跡しています。これらのスパイ活動では、Google が「ScatterBrain」と呼んでいるカスタムの難読化コンパイラを利用し、ヨーロッパとアジア太平洋(APAC)地域のさまざまなエンティティに対する攻撃を行っています。ScatterBrain は、以前 PWC が分析した ScatterBee という難読化コンパイラを大幅に進化させたものと考えられます。
GTIG の評価では、POISONPLUG は、中華人民共和国(PRC)を拠点とする複数の脅威グループが利用している高度なモジュール型バックドアです。これらの脅威グループはそれぞれ異なりますが、互いに関連性があると考えられます。一方で、POISONPLUG.SHADOW の利用はさらに APT41 に関連する集団に限られているようです。
GTIG は現在、POISONPLUG の既知の亜種として次の 3 つを追跡しています。
- POISONPLUG
- POISONPLUG.DEED
- POISONPLUG.SHADOW

「Shadowpad」とも呼ばれる POISONPLUG.SHADOW というマルウェア ファミリーは、当初 Kaspersky によって発見されました。その目立った特徴は、検出と分析を回避するように設計されたカスタムの難読化コンパイラを使用するという点です。この難読化コンパイラは、使用されている難読化メカニズムの幅広さだけでなく、攻撃者の高度な脅威戦術によっても、輪を掛けて複雑なものとなっています。こうした要因が重なっていることから、その分析は極めて困難であり、POISONPLUG.SHADOW に伴う脅威を特定、把握、軽減する取り組みは複雑になります。
これらの課題に対処するため、GTIG は FLARE チームと緊密に連携して POISONPLUG.SHADOW の調査、分析を進めています。このパートナーシップでは、この脅威アクターによる高度な脅威を軽減するうえで必要な最先端のリバース エンジニアリング手法と包括的な脅威インテリジェンス機能を活用しています。Google は今後も、脅威アクターの進化し続ける戦術に対応、対抗すべく、さまざまな手法を進化させ、イノベーションを推進することで、高度なサイバー エスピオナージ活動に対して、Google と Google のお客様のセキュリティを確保していきます。
概要
このブログ投稿では、ScatterBrain 難読化コンパイラについて Google が行った詳細分析の内容をご紹介します。Google はこの分析に基づき、どのバイナリ分析フレームワークにも依存しない、完全にスタンドアロンの静的難読化解除ライブラリを開発しました。Google はこの難読化コンパイラ自体を所有していないため、この分析は、復元に成功した難読化サンプルのみに基づいています。こうした制約はありますが、Google はこの難読化コンパイラのあらゆる側面と、難読化の解除に必要な要件を包括的に推測することができました。この分析により、ScatterBrain が継続的に進化していることも明らかになりました。段階的な変更が徐々に特定され、この難読化コンパイラの開発が現在も進行中であることが判明したのです。
この投稿ではまず、ScatterBrain の基本構造について詳しく探り、そのすべてのコンポーネントと、それらのコンポーネントが分析にもたらす課題について説明します。その後、それぞれの保護メカニズムを無力化し除去するための手順を詳しく説明します。これらの手順の集大成が、Google の難読化解除ライブラリです。このライブラリは、ScatterBrain によって生成された保護済みバイナリを入力として受け取り、難読化が解除された完全に機能するバイナリを出力として生成します。
ScatterBrain の内部構造について詳しく説明し、Google の難読化解除ライブラリをご紹介することで、効果的な対策を策定するための有益な分析情報を提供できることを願っています。このブログ投稿は、意図的に包括的な内容となっています。Google はクライアントの難読化に対処してきた経験の中で、最新の難読化手法を把握するための明確な情報が大幅に欠けているという状況を目にしてきたからです。同様に、比較的シンプルな難読化手法であっても、標準的なバイナリ分析ツールがそれを想定して設計されていないことが主な原因で、アナリストが容易に理解できないことも多くあります。そのため Google は、分析の負担を軽減し、一般的に見られる保護メカニズムに対する共通認識を促進することを目指しています。
難読化コンパイラに関する一般的な質問については、このトピックに関する以前の記事をご覧ください。コンパイラの紹介と概要を説明しています。
ScatterBrain 難読化コンパイラ
はじめに
ScatterBrain は、生成するバイナリの分析を大幅に複雑にすることを目的に、複数の動作モードと保護コンポーネントを統合した高度な難読化コンパイラです。ScatterBrain は最新のバイナリ分析フレームワークと防御ツールを無効にするように設計されており、静的分析と動的分析のどちらも妨害します。
-
保護モード: ScatterBrain は 3 つの異なるモードで動作します。モードによって、全体的な構造と適用される保護の強度は異なります。これらのモードにより、難読化コンパイラは攻撃の特定の要件に応じて、その難読化戦略を適応させることができます。
-
保護コンポーネント: このコンパイラで利用されている主な保護コンポーネントは次のとおりです。
-
選択的または完全な制御フローグラフ(CFG)難読化: この手法では、プログラムの制御フローを再構築して、難読化の分析とその検出ルールの作成を非常に困難にします。
-
命令ミューテーション: ScatterBrain はプログラムの動作を変更せずに、命令を改ざんしてその本来の機能をわかりにくくします。
-
完全なインポート保護: ScatterBrain はバイナリのインポート テーブルを完全に保護するため、基礎となるオペレーティング システムとバイナリがどのようにやり取りしているかを理解することは極めて困難です。
ScatterBrain は以上の保護メカニズムを総動員することで、難読化されたバイナリの機能をアナリストが分解して理解できないようにしています。そのため、サイバーセキュリティの専門家が ScatterBrain によってもたらされる脅威を詳細に調査して軽減しようとしても、大きな障壁に突き当たります。
動作モード
モードとは、ScatterBrain が所定のバイナリを難読化した表現に変換する方法のことです。モードは、実際の中核的な難読化メカニズム自体とは別の、保護を適用する全体的な戦略に関連するものです。Google の分析により、攻撃チェーンの特定の段階でそれぞれの保護モードが適用される際に、一貫したパターンがあることが明らかになっています。
-
選択的保護: 個別に選択された関数のグループが保護され、バイナリの残りの部分は元の状態のまま維持されます。選択された関数内では、インポートの参照も難読化されます。攻撃チェーンのドロッパー サンプルに対してのみ、このモードが使用されることが観測されています。
-
完全保護: コード セクション全体とすべてのインポートが保護されます。このモードは、メインのバックドア ペイロード内に埋め込まれたプラグインにのみ適用されていました。
-
「ヘッダーレス」完全保護: これは完全保護モードを拡張したものです。データ保護が強化され、PE ヘッダーが削除されます。このモードは、最終的なバックドア ペイロード専用に使われていました。
選択的保護
選択的保護モードでは、難読化コンパイラのユーザーがバイナリ内の個々の関数を選択して、保護対象にすることができます。個々の関数を保護するために、関数が(元のコンパイラおよびリンカーによって生成された)元の開始アドレスに保持され、最初の命令が難読化されたコードへのジャンプに置き換えられます。生成された難読化は、この開始アドレスから指定の「エンドマーカー」(保護の適用範囲の終わりを示すマーカー)まで線形に保存されます。この範囲全体が、保護された関数となります。
呼び出しサイトから保護された関数への逆アセンブリは、次の形式を取ることができます。
.text:180001000 sub rsp, 28h
.text:180001004 mov rcx, cs:g_Imagebase
.text:18000100B call PROTECTED_FUNCTION ; 保護された関数の呼び出し
.text:180001010 mov ecx, eax
.text:180001012 call cs:ExitProcess図 1: 保護された関数に対する呼び出しの逆アセンブリ
保護された関数の開始部分は、次のようになっています。
.text:180001039 PROTECTED_FUNCTION
.text:180001039 jmp loc_18000DF97 ; 難読化されたコードへのジャンプ
.text:180001039 sub_180001039 endp
.text:000000018000103E db 48h ; H. ; ガベージデータ
.text:000000018000103F db 0FFh
.text:0000000180001040 db 0C1h図 2: 保護された関数内での逆アセンブリ
「エンドマーカー」は、2 つのパディング命令からなります。具体的には、int3 命令と単一の multi-nop 命令です。
END_MARKER:
.text:18001A95C CC CC CC CC CC CC CC CC CC CC 66
66 0F 1F 84 00 00 00 00 00
.text:18001A95C int 3
.text:18001A95D int 3
.text:18001A95E int 3
.text:18001A95F int 3
.text:18001A960 int 3
.text:18001A961 int 3
.text:18001A962 int 3
.text:18001A963 int 3
.text:18001A964 int 3
.text:18001A965 int 3
.text:18001A966 db 66h, 66h ; @注: IDA は適切に逆アセンブルしない
.text:18001A966 nop word ptr [rax+rax+00000000h]
; -------------------------------------------------------------------------
; 以下は元の関数
.text:18001A970 ; [0000001F BYTES: COLLAPSED FUNCTION
__security_check_cookie. PRESS CTRL-NUMPAD+ TO EXPAND]図 3: エンドマーカーの逆アセンブリ リスティング
完全保護
完全保護モードでは、バイナリの .text セクション内にあるすべての関数が保護され、これらすべての保護が単一のコード セクションに直接統合されます。保護された領域を示すエンドマーカーは使用されません。代わりに、すべての関数が同じように保護されて、セクションを区切ることなく包括的に保護対象となるようにします。
このモードに対抗するには、なんらかの難読化解除ツールが必要となります。選択的保護モードでは選択された関数のみが保護されて、他の関数はすべて元の状態のままになりますが、このモードの場合、難読化を考慮しなければ、出力されたバイナリの分析が極めて困難になります。
ヘッダーレス完全保護
このモードは、完全保護のアプローチを拡張し、コードの保護に加え、データの難読化をさらに強化したものです。これは最も包括的な保護モードであり、攻撃チェーンの最終ペイロードでのみ観測されています。このモードには次の特性があります。
-
保護されたバイナリの PE ヘッダーが完全に削除されます。
-
カスタムの読み込みロジック(ローダ)が導入されます。
-
保護されたバイナリのエントリー ポイントになります。
-
保護されたバイナリが機能することを確認する役割を果たします。
-
オプションで、読み込まれた最初のメモリ領域とは異なるメモリ領域内の最終ペイロードをマッピングします。
-
メタデータは、ハッシュと似た完全性チェックによって保護されます。
-
ローダはその初期化シーケンスの一貫として、このメタデータを使用します。
-
インポート保護には再配置の調整が必要です。
-
この調整は「インポート フィックスアップ テーブル」によって行われます。
ローダのエントリー ルーチンはバイナリの元のエントリーと疎結合するために、この 2 つを結び付ける複数の jmp 命令を挿入します。ヘッダーレス モードで保護されたバイナリに対して Google の難読化解除ツールを実行すると、エントリー ポイントは以下のようになります。

図 4: 難読化解除されたローダ エントリー
ローダのメタデータは保護されたバイナリの .data セクションに保存されます。これは、事前定義された定数に対してビット単位 XOR 演算を適用するメモリスキャンによって検出されます。これらの演算の使用は、メタデータの位置を特定するだけでなく、その完全性も検証するという二重の役割を果たします。事前定義された定数に XOR 演算を適用し、データが想定パターンに一致することをチェックすることで、ローダはメタデータが改変または改ざんされていないことを確認します。

図 5: .data セクション内にあるローダのメタデータを特定するためのメモリスキャン
メタデータには以下のものが(記載順に)含まれます。
-
インポート フィックスアップ テーブル(「インポート保護」のセクションで詳しく説明)
-
完全性ハッシュ定数
-
.dataセクションの相対仮想アドレス(RVA) -
.dataセクションの開始位置からインポート フィックスアップ テーブルまでのオフセット -
フィックスアップ テーブルのサイズ(バイト数)
-
バッグドアがあるメモリアドレスを指すグローバル ポインタ
-
暗号化されて圧縮された、バックドアに固有のデータ
-
バッグドアの構成とプラグイン

図 6: ローダのメタデータ
主要な保護コンポーネント
命令ディスパッチャー
命令ディスパッチャーは、バイナリ(または個々の関数)の自然な制御フローを分散した基本ブロックに変換する、中心的な保護コンポーネントです。これらの基本ブロックは、保護されたバイナリの実行を動的に誘導する固有のディスパッチャー ルーチンで終わります。

図 7: 命令ディスパッチャーが誘導する制御フロー命令のイラスト
ディスパッチャーに対する各呼び出しの直後に、エンコードされた 32 ビット ディスプレースメントが続きます。これは、本来は呼び出しの戻りアドレスである場所に配置されています。ディスパッチャーはこのディスプレースメントをデコードして、次に実行する命令グループの宛先とするターゲットを計算します。保護されたバイナリには、数千あるいは数万ものディスパッチャーが含まれることがあるため、これらのディスパッチャーを手動で分析するのは事実上不可能です。さらに、動的にディスパッチしてデコードするロジックを各ディスパッチャーが使用するため、すべてのバイナリ分析フレームワークで使用される CFG 再構築手法は実質的に機能しません。
デコード ロジックはディスパッチャーごとに固有であり、add 命令、sub 命令、xor 命令、and 命令、or 命令、lea 命令を組み合わせて実行されます。デコードされたオフセット値が、ディスパッチャー呼び出しの想定される戻りアドレスに対して減算または加算されて、最終的な宛先アドレスが決定されます。このように計算されたアドレスは次の命令ブロックに実行を割り当て、次の命令ブロックは同じようにディスパッチャーで終了します。ディスパッチャーは、固有のデコードを行って後続の命令ブロックにジャンプします。このプロセスが繰り返されることでプログラムのフローが制御されます。
以下のスクリーンショットは、IDA Pro で作成されたディスパッチャー インスタンスを示しています。分散されたアドレスが命令ディスパッチャー内にも存在していることに注目してください。なぜこのようになっているかというと、難読化コンパイラがフォールスルー命令(先行する命令に自然に続く命令)を、それぞれ反対の条件を使用する条件付き分岐のペアに変換するからです。これにより、常に 1 つの分岐が選択されて、実質的に無条件のジャンプが作成されます。さらに、NoOps として機能する mov 命令が挿入されて、これらの分岐が分割されるため、制御フローがさらにわかりにくくなります。

図 8: 命令ディスパッチャーとそのすべてのコンポーネントの例
どのディスパッチャーのコアロジックも、次の 4 つのフェーズに分類できます。
1. 実行コンテキストの維持
-
各ディスパッチャーが、難読化プロセス中に単一のワーキング レジスタを選択します(スクリーンショットに示されている
RSIなど)。このレジスタがスタックとともに使用されて、意図されているデコード演算とディスパッチを実行します。 -
次に、デコード シーケンスを実行する前に
pushfq命令とpopfq命令を使用して、RFLAGSレジスタが保護されます。
2. エンコードされたディスプレースメントの取得
-
各ディスパッチャーが、それぞれに対応する呼び出し命令の戻りアドレスにある、エンコードされた 32 ビット ディスプレースメントを取得します。このエンコードされたディスプレースメントに基づいて、次の宛先アドレスが決定されます。
3. デコード シーケンス
-
各ディスパッチャーが、
xor、sub、add、mul、imul、div、idiv、and、or、notの算術命令と論理命令からなる固有のデコード シーケンスを使用します。この可変性により、まったく同じ動作をする 2 つのディスパッチャーは存在せず、制御フローが大幅に複雑化します。
4. 終了とディスパッチ
-
ディスパッチャー関数終了の合図と、プログラムの制御フローの計算済みの宛先アドレスへのリダイレクトを同時に行うために、
ret命令が戦略的に使用されます。
難読化コンパイラがその変換処理を元のバイナリに適用するときには、図 9 に示すようなテンプレートを使用すると考えるのが論理的です。

図 9: 命令ディスパッチャー テンプレート
opaque 述語
ScatterBrain が使用する一見して単純な一連の opaque 述語(OP)は、アナリストにとっては簡単に見えても、集合的に使用される場合は特に、現代のバイナリ分析フレームワークにとっては大きな難題になります。これらの opaque 述語は、そのロジックを無効にするように設計されていない静的な CFG 復元手法を妨害します。さらに、パスを急増させてパスの優先順位付けを困難にすることから、記号的実行アプローチも複雑になります。以降のセクションで、ScatterBrain によって生成された opaque 述語の例をいくつか紹介します。
test OP
この opaque 述語は、test 命令を即値のゼロと組み合わせた場合の動作を中心に構築されています。この難読化コンパイラは、test 命令がビット単位 AND 演算を行うこと、そしてゼロによるビット単位 AND 演算で処理されたすべての値は必ずゼロになるという事実を悪用しています。
たとえば、保護されたバイナリでは以下のような抽象化された例が見られます。この場合の抽象化とは、すべての命令が連続的に続くことが保証されず、命令間に別の形のミューテーションや命令ディスパッチャーが含まれる可能性があるという意味です。
test bl, 0
jnp loc_56C96 ; これらの条件が満たされることはない
------------------------------
test r8, 0
jo near ptr loc_3CBC8
------------------------------
test r13, 0
jnp near ptr loc_1A834
------------------------------
test eax, 0
jnz near ptr loc_46806図 10: test の opaque 述語の例
この opaque 述語の実装ロジックを把握するには、test 命令とプロセッサのフラグレジスタへのその影響のセマンティクスが必要です。この命令は、6 種類のフラグに次のように影響する可能性があります。
-
オーバーフロー フラグ(OF): 常にクリアされる
-
キャリーフラグ(CF): 常にクリアされる
-
符号フラグ(SF): 結果の最上位ビット(MSB)が設定されている場合は設定され、そうでなければクリアされる
-
ゼロフラグ(ZF): 結果がゼロの場合は設定され、そうでなければクリアされる
-
パリティフラグ(PF): 結果の最下位ビット(LSB)に設定されたビット数が偶数の場合は設定され、そうでなければクリアされる
-
補助キャリーフラグ(AF): 定義されない
この理解を ScatterBrain によって生成されるシーケンスに当てはめると、生成される条件が論理的に満たされることがないことは明白です。
表 1: test の opaque 述語の理解
jcc OP
opaque 述語は、条件付き分岐(jcc)命令の元の即値の分岐ターゲットを静的に曖昧にするように設計されています。以下の例を考えてみましょう。
test eax, eax
ja loc_3BF9C
ja loc_2D154
test r13, r13
jns loc_3EA84
jns loc_53AD9
test eax, eax
jnz loc_99C5
jnz loc_121EC
cmp eax, FFFFFFFF
jz loc_273EE
jz loc_4C227図 11: jcc の opaque 述語の例
この実装は単純なものであり、それぞれの元の jcc 命令が複製されて不正な分岐ターゲットが設定されます。どちらの jcc 命令も機能的には同じですが、分岐の宛先が異なるので、各ペアの最初の jcc が元の命令であると確実に判断できます。この元の jcc は、該当する条件が満たされた場合に従うべき正しい分岐ターゲットを指示しています。一方、複製された jcc は誤った分岐に誘導して分析ツールを混乱させます。
スタックベースの OP
スタックベースの opaque 述語は、現在のスタック ポインタ(rsp)が即値の事前定義済みしきい値を下回っているかどうか(true になることはない条件)をチェックするように設計されています。これは常に、cmp rsp 命令の直後に jb(下回っている場合はジャンプ)条件を組み合わせて実装されます。
cmp rsp, 0x8d6e
jb near ptr unk_180009FDA図 12: スタックベースの opaque 述語の例
この手法では、常に false となる条件を挿入することで、CFG アルゴリズムが両方の分岐を辿るようにします。これによって、CFG アルゴリズムによる制御フローの正確な再構築を阻害します。
インポート保護
この難読化コンパイラは高度なインポート保護層を実装しています。このメカニズムでは、バイナリの依存関係を隠すために、インポートをターゲットとする元の call 命令または jmp 命令のそれぞれが、当該インポートを動的に解決して取り消す方法を把握している固有のスタブ ディスパッチャー ルーチンで変換されます。

図 13: インポート保護に関与するすべてのコンポーネントのイラスト
これは次のコンポーネントで構成されています。
-
インポート固有の暗号化データ: 保護された各インポートが、固有のディスパッチャー スタブと分散されたデータ構造体で表されます。この分散されたデータ構造体では、暗号化されたダイナミック リンク ライブラリ(DLL)名とアプリケーション プログラミング インターフェース(API)名の両方への RVA が保存されます。Google ではこの構造体を
obf_imp_tと呼んでいます。各ディスパッチャー スタブには、そのobf_imp_tへの参照がハードコードされます。 -
ディスパッチャー スタブ: この難読化されたスタブが、意図されているインポートを動的に解決して呼び出します。すべてのスタブで同一のテンプレートを共有しますが、各スタブにはハードコードされた固有の RVA が含まれます。この RVA は対応する
obf_imp_tを識別し、その場所を特定します。 -
リゾルバ ルーチン: この難読化されたルーチンはディスパッチャー スタブから呼び出され、インポートを解決して、その結果をディスパッチャーに返します。これにより、意図されたインポートの最終呼び出しが可能になります。このルーチンではまず、
obf_imp_t内の情報に基づいて、暗号化された DLL 名と API 名の場所を特定します。次に、これらの名前を復号し、復号した名前を使用して API のメモリアドレスを解決します。 -
インポート復号ルーチン: この難読化されたルーチンはリゾルバ ルーチンから呼び出され、カスタムのストリーム暗号の実装によって DLL 名と API 名の blob を復号します。復号に使用するのはハードコードされた 32 ビットのソルトです。これは、保護されたサンプルごとに異なります。
-
フィックスアップ テーブル: ヘッダーレス モードでのみ存在します。ローダはヘッダーレス モードでこの再配置フィックスアップ テーブルを使用し、以下のインポート保護コンポーネントを指すすべてのメモリ ディスプレースメントを修正します。
-
暗号化された DLL 名
-
暗号化された API 名
-
インポート ディスパッチャー参照
ディスパッチャー スタブ
インポート保護メカニズムの中核となるのは、ディスパッチャー スタブです。各スタブは個々のインポートに応じて調整されます。また、一貫して lea 命令を使用してそれぞれの obf_imp_t にアクセスし、これを唯一の入力としてリゾルバ ルーチンに渡します。
push rcx ; RCX を保存
lea rcx, [rip+obf_imp_t] ; インポート固有の obf_imp_t をフェッチ
push rdx ; スタブが使用する他のすべてのレジスタを保存
push r8
push r9
sub rsp, 28h
call ObfImportResolver ; インポートを解決して RAX で返す
add rsp, 28h
pop r9 ; 保存されたすべてのレジスタを復元
pop r8
pop rdx
pop rcx
jmp rax ; 解決されたインポートを呼び出す 図 14: 難読化解除されたインポート ディスパッチャー スタブ
各スタブは、前述のミューテーション メカニズムによって難読化されます。これは、リゾルバ ルーチンとインポート復号ルーチンにも該当します。以下に、スタブの実行フローの例を示します。アドレスは順に記載されていますが、実際には命令ディスパッチャーによってコード セグメント全体にジャンプする分散アドレスなので注意してください。
0x01123a call InstructionDispatcher_TargetTo_11552
0x011552 push rcx
0x011553 call InstructionDispatcher_TargetTo_5618
0x005618 lea rcx, [rip+0x33b5b] ; obf_imp_t をフェッチ
0x00561f call InstructionDispatcher_TargetTo_f00c
0x00f00c call InstructionDispatcher_TargetTo_191b5
0x0191b5 call InstructionDispatcher_TargetTo_1705a
0x01705a push rdx
0x01705b call InstructionDispatcher_TargetTo_05b4
0x0105b4 push r8
0x0105b6 call InstructionDispatcher_TargetTo_f027
0x00f027 push r9
0x00f029 call InstructionDispatcher_TargetTo_18294
0x018294 test eax, 0
0x01829a jo 0xf33c
0x00f77b call InstructionDispatcher_TargetTo_e817
0x00e817 sub rsp, 0x28
0x00e81b call InstructionDispatcher_TargetTo_a556
0x00a556 call 0x6afa (ObfImportResolver)
0x00a55b call InstructionDispatcher_TargetTo_19592
0x019592 test ah, 0
0x019595 call InstructionDispatcher_TargetTo_a739
0x00a739 js 0x1935
0x00a73b call InstructionDispatcher_TargetTo_6eaa
0x006eaa add rsp, 0x28
0x006eae call InstructionDispatcher_TargetTo_6257
0x006257 pop r9
0x006259 call InstructionDispatcher_TargetTo_66d6
0x0066d6 pop r8
0x0066d8 call InstructionDispatcher_TargetTo_1a3cb
0x01a3cb pop rdx
0x01a3cc call InstructionDispatcher_TargetTo_67ab
0x0067ab pop rcx
0x0067ac call InstructionDispatcher_TargetTo_6911
0x006911 jmp rax図 15: 難読化されたインポート ディスパッチャー スタブ
リゾルバ ロジック
obf_imp_t は中心的なデータ構造体であり、各インポートを解決するための関連情報を格納しており、次の形式になっています。
struct obf_imp_t { // sizeof=0x18
uint32_t CryptDllNameRVA; // 注: パディングにより、64 ビットになります
uint32_t CryptAPINameRVA; // 注: パディングにより、64 ビットになります
uint64_t ResolvedImportAPI; // ここに、解決されたアドレスが格納されます
};
図 16: obf_imp_t の元の C 構造体ソース形式
これを処理するリゾルバ ルーチンでは、組み込まれた RVA を使用して暗号化された DLL 名と API 名の場所を特定してから、それぞれの名前を復号します。それぞれの名前 blob を復号した後、LoadLibraryA を使用して DLL 依存関係がメモリに読み込まれたことを確認し、GetProcAddress を使用してインポートのアドレスを取得します。
完全に逆コンパイルされた ObfImportResolver は次のようになります。

図 17: 完全に逆コンパイルされたインポート リゾルバ ルーチン
インポート暗号化ロジック
インポート復号ロジックは、線形合同法(LCG)アルゴリズムを使用して実装されています。LCG アルゴリズムで疑似ランダム キーストリームを生成し、そのキーストリームを XOR ベースのストリーム暗号で復号に使用するという仕組みです。このロジックは、次の数式で動作します。
Xn + 1 = (a • Xn + c) mod 232
ここで
-
aは常に 17 にハードコードされ、乗数として機能します。 -
cは、保護されたサンプルごとに固有の 32 ビットの定数で、暗号化のコンテキストで決定されます。 -
この定数は
imp_decrypt_constと呼びます。 -
mod232 はシーケンス値を 32 ビットの範囲に制限します。
復号ロジックは暗号化データからの値を使って初期化し、上記の LCG 数式を使用して繰り返し新しい値を生成します。反復処理のたびに、計算された値からバイトを生成し、そのバイトとそれに対応する暗号化されたバイトを XOR 演算で処理します。このプロセスが、終了条件に達するまでバイトごとに繰り返されます。
図 18 は、復号ロジックの完全に復元された Python 実装を示しています。
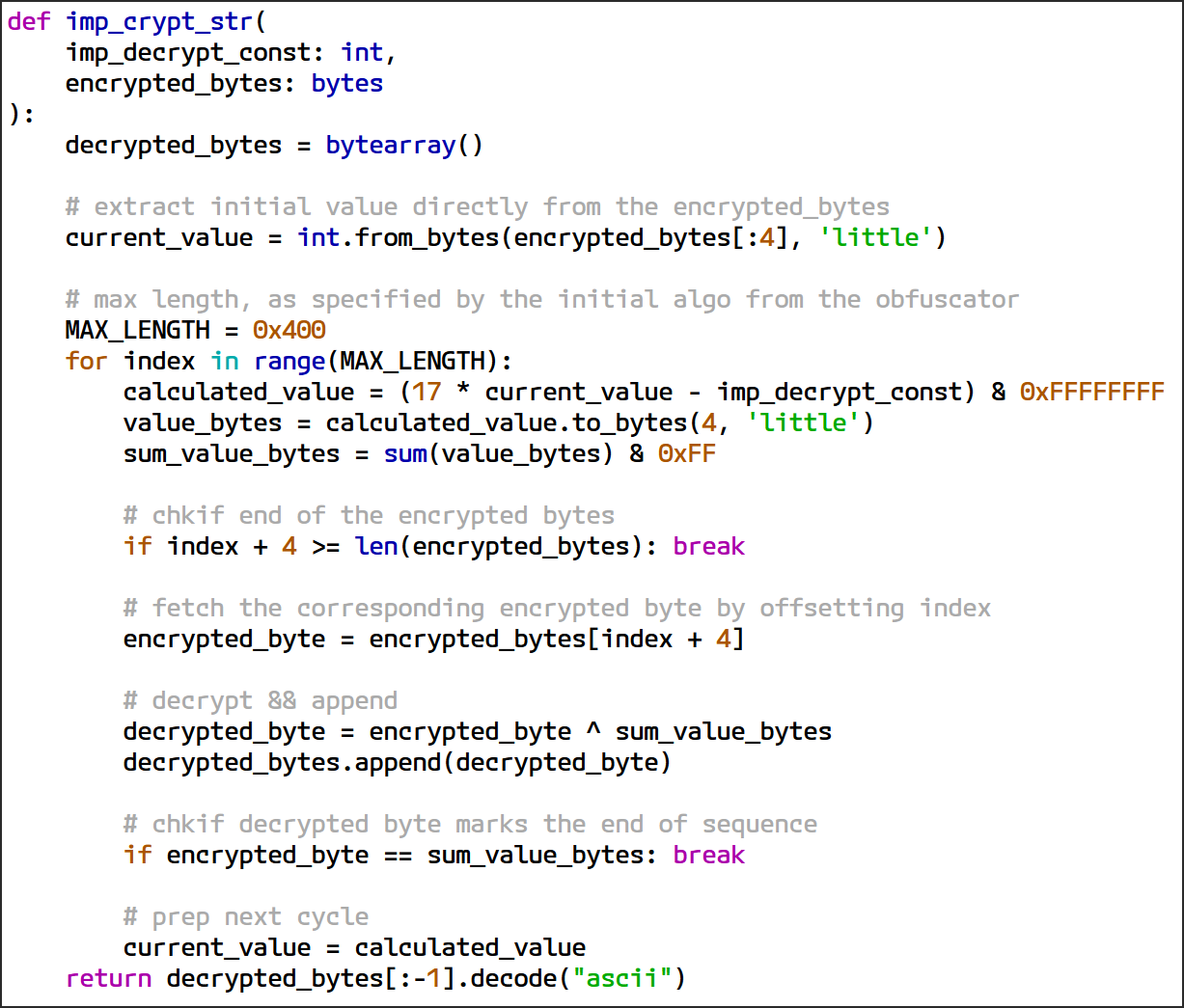
図 18: インポート文字列復号ルーチンの完全な Python 実装
インポート フィックスアップ テーブル
インポート再配置フィックスアップ テーブルは、32 ビットの 2 つの RVA エントリからなる固定サイズの配列です。1 つ目の RVA は、データの参照元のメモリ ディスプレースメントを表します。2 つ目の RVA は、該当する実際のデータを指しています。フィックスアップ テーブル内のエントリは、それぞれ特定のインポート コンポーネントに対応する、次の 3 つのタイプに分類できます。
-
暗号化された DLL 名
-
暗号化された API 名
インポート ディスパッチャー参照

図 19: インポート フィックスアップ テーブルのイラスト
フィックスアップ テーブルの場所は、ローダのメタデータによって決定されます。具体的には、.data セクションの先頭からフィックスアップ テーブルの先頭までのオフセットを指定するメタデータです。初期化の際に、ローダがテーブル内の各エントリに再配置フィックスアップを適用します。

図 20: インポート フィックスアップ テーブルのエントリと、その検出に使用されるメタデータを示すローダ メタデータ
復元
難読化されたバイナリを効果的に復元するには、使用されている保護メカニズムを完全に理解する必要があります。難読化解除では通常、未処理の逆アセンブリではなく中間表現(IR)を操作すると効果を得られますが(IR を使用すると、変換を元に戻す際により細かく制御できます)、この難読化コンパイラはコンパイルされた元のコードを維持し、そのコードを単に追加の保護層で覆うだけです。このような背景から、Google の難読化解除戦略では、逆アセンブリからこの難読化コンパイラの変換を取り除き、元の命令とデータを明らかにすることに重点を置いています。前のフェーズを基盤に次のフェーズを構築する、一連の階層的なフェーズによって包括的な難読化解除を行っています。
このアプローチは、最終的に統合される 3 つの異なるカテゴリからなります。
1. CFG の復元
-
命令と基本ブロックのレベルで難読化によるアーティファクトを取り除いて、自然な制御フローを復元します。この復元は、次の 2 つのフェーズで行います。
-
命令ディスパッチャーの考慮: 実行フローを曖昧にする制御フロー保護の中核に対処します。
-
関数識別と復元: 分散された命令をカタログ化して、元の対応する関数に再構成します。
2. インポートの復元
-
元のインポート テーブル: ここでの目標は、元のインポート テーブルを再構築して、必要なすべてのライブラリと関数参照が正確に復元されるようにすることです。
3. バイナリの書き換え
-
難読化解除された実行可能ファイルの生成: このプロセスでは、難読化解除された新しい実行可能ファイルを作成します。このファイルでは ScatterBrain による変更が取り除かれ、元の機能が維持されています。
各カテゴリの複雑さを考慮すると、難読化コンパイラを打倒するための核となる側面に集中する必要があります。そこで Google は、難読化解除ツールのソースコードのガイド付きチュートリアルを提供して、難読化コンパイラによる変換を元に戻すうえで不可欠のロジックを示しています。この検証チュートリアルでは、それぞれの難読化手法を一つずつ無効にし、最終的にバイナリの元の構造を復元する方法を示し、その手順を紹介しています。
以下のディレクトリ構造に、この体系的なアプローチが反映されています。
+---helpers
| | emu64.py
| | pefile_utils.py
| |--- x86disasm.py
|
\---recover
| recover_cfg.py
| recover_core.py
| recover_dispatchers.py
| recover_functions.py
| recover_imports.py
|--- recover_output64.py図 21: Google の難読化解除ライブラリのディレクトリ構造
この包括的な復元プロセスは、バイナリを元の状態に復元するだけでなく、将来的に同様の難読化手法に対抗するうえで必要となるツールと知識をアナリストに提供します。
CFG の復元
自然な制御フローグラフを妨げる主な障害は、命令ディスパッチャーが使用されていることです。これらのディスパッチャーを排除することが、CFG を取得するうえでの最優先事項となります。その後、分散された命令を元の関数表現に再編成する必要がありますが、これは一般化するのが非常に困難な「関数識別」と呼ばれる問題です。そこで、この難読化コンパイラについて知っている具体的な情報を基に、この問題に取り組むことにしました。
分散された CFG の線形化
元の CFG を復元するための最初のステップは、命令ディスパッチャーがもたらす分散効果を排除することです。そのために、すべてのディスパッチャー呼び出し命令を変換して、解決済みターゲットへの直接分岐にします。この変換によって実行フローを線形化し、CFG 復元に向けた 2 番目のフェーズを静的かつ簡単に遂行できるようにします。この変換は、ブルート フォース スキャン、静的解析、エミュレーション、命令のパッチ適用によって実装します。
関数識別と復元
コードの既知のエントリー ポイントに深さ優先探索(DFS)戦略を採用した再帰下降アルゴリズムを使用し、一度に 1 つの命令を処理する「シングル ステップ」ですべてのコードパスを網羅することを試みます。各命令の処理に「ミューテーション ルール」という形のロジックを追加して、個々の命令をどのように処理する必要があるかを規定します。これらのルールで、元のコードから難読化コンパイラのコードを取り除けるようにします。
命令ディスパッチャーの除去
命令ディスパッチャーを排除するには、各ディスパッチャーの位置とその対応するディスパッチ ターゲットを特定する必要があります。前述したとおり、ターゲットは一意にエンコードされた 32 ビットのディスプレースメントであり、これはディスパッチャー呼び出しの戻りアドレスに配置されています。命令ディスパッチャーを除去するには、まずこれらを正確に特定する方法を理解することが不可欠です。そこで、まずは個々の命令ディスパッチャーを定義するプロパティを分類します。
-
near call のターゲット
-
ディスパッチャーは常に、near
call命令の宛先になります。これは、E8オペコードとそれに続く 32 ビットのディスプレースメントで表されます。 -
戻りアドレスにあるエンコードされた 32 ビットのディスプレースメントの参照
-
ディスパッチャーはスタック ポインタから 32 ビットを読み取って、スタック上の戻りアドレスにあるエンコードされた 32 ビットのディスプレースメントを参照します。このディスプレースメントは、次の実行ターゲットを決定するのに不可欠です。
-
デコードを保護する
pushfq命令とpopfq命令の組み合わせ -
ディスパッチャーはデコード プロセス中に
pushfq命令とpopfq命令を組み合わせて使用して、RFLAGSレジスタの状態を維持します。これにより、ディスパッチャーは元の実行コンテキストを変えずに、レジスタのコンテンツの完全性を維持します。 -
ret命令による終了 -
各ディスパッチャーは
ret命令で終了します。この命令はディスパッチャー関数を終了させるだけでなく、制御を次の命令セットにリダイレクトして、実行フローを継続させます。
命令ディスパッチャーを特定して除去するために、上記の分類を使用して次のアプローチを実装します。
1.near call 位置のブルート フォース スキャナ
-
保護されたバイナリのコード セクション内にあるすべての near
call命令を検索するスキャナを作成します。このスキャナによって、ディスパッチャーとして機能する可能性がある call 位置の大規模な配列を生成します。
2.フィンガープリンティング ルーチンの実装
-
ブルート フォース スキャンでは多数の偽陽性が発生するため、これらの偽陽性を効率的な方法でフィルタする必要があります。エミュレーションで偽陽性を除外することもできますが、このブルート フォースの結果を処理すると計算費用が高額になります。
-
各候補の逆アセンブリを走査して、ディスパッチャーの主な特性(
pushfqとpopfqのシーケンスの有無など)を特定するシャロー フィンガープリンティング ルーチンを導入します。エミュレーションで確実に検証する前に、このルーチンでほとんどの偽陽性を排除することで、パフォーマンスが大幅に向上します。
3.ターゲットのエミュレーションによる宛先の復元
-
検証された各 call サイトからの実行をエミュレートして、実際のディスパッチャー ターゲットを正確に復元します。call サイトからエミュレートすることで、エミュレータが戻りアドレスにあるエンコードされたオフセット データを確実に処理して、各ディスパッチャーによって採用されている具体的なデコード ロジックを抽象化できます。
-
効果的なエミュレーションは、ディスパッチャーを特定したことを確認する最終的な検証ステップとしても役立ちます。
4. ret 命令によるディスパッチ ターゲットの特定
-
ディスパッチャー関数を終了させる ret 命令を使用して、バイナリ内のディスパッチ ターゲットを正確に特定します。
-
ret 命令は、ディスパッチャー関数の終了位置と制御フローのリダイレクトのタイミングを示す決定的なマーカーであるため、ターゲットを識別するための確実なインジケーターとなります。
ブルート フォース スキャナ
以下の Python コードは、保護されたバイナリのコード セグメント内で包括的なバイト シグネチャ スキャンを行うブルート フォース スキャナを実装します。このスキャナは、推定されるすべての call 命令の位置を体系的に識別するために、near call 命令に関連付けらている 0xE8 オペコードを探します。識別されたアドレスは、以降の分析と検証のために保存されます。

図 22: ブルート フォース スキャナの Python 実装
ディスパッチャーのフィンガープリンティング
フィンガープリンティング ルーチンでは、「命令ディスパッチャー」のセクションで説明した命令ディスパッチャー固有の特性を利用して、保護されたバイナリ内の推定されるディスパッチャー位置を静的に識別します。この識別プロセスでは、先行するブルート フォース スキャンによる結果が使用されます。この配列に含まれるアドレスごとにルーチンでコードを逆アセンブルし、その結果として生成された逆アセンブリ リスティングを調べて、それが既知のディスパッチャー シグネチャと一致するかどうかを判別します。
この方法は、100% の精度を保証するものではありません。命令ディスパッチャーである可能性が高い call 位置を識別するための費用対効果の高いアプローチであると考えてください。後続のエミュレーションによって、これらの識別結果が確認されます。
1. call 命令のデコードが成功すること
-
識別された位置は、
call命令に正常にデコードされなければなりません。ディスパッチャーは常に、call 命令によって呼び出されます。また、ディスパッチャーは call サイトからの戻りアドレスを使用して、エンコードされた 32 ビットのディスプレースメントの位置を特定します。
2. 後続の call 命令がないこと
-
ディスパッチャーの逆アセンブリ リスティングには、
call命令が含まれていてはなりません。推定されるディスパッチャー範囲内にcall命令が 1 つでもある場合、その call 位置はディスパッチャー候補から外されます。
3. 特権命令と間接的な制御転送がないこと
-
call命令と同様に、ディスパッチャーには特権命令や間接的な無条件jmpが含まれていてはなりません。このような命令が 1 つでも存在する場合、その call 位置は候補から外されます。
4.pushfq と popfq のガード シーケンスが検出されること
-
ディスパッチャーには、デコードの際に
RFLAGSレジスタを保護するためのpushfq命令とpopfq命令が含まれていなければなりません。これらのシーケンスはディスパッチャーに固有のものであり、一般的な識別には十分です。デコードの手法によって生じる違いを懸念する必要はありません。
図 23 のフィンガープリンティング検証ルーチンには、推定される call 位置での前述の特性と検証のチェックがすべて統合されています。

図 23: ディスパッチャーのフィンガープリンティング ルーチン
ディスパッチャーのエミュレーションによる宛先ターゲットの解決
フィンガープリンティング ルーチンで推定されるディスパッチャーを絞り込んだ後は、宛先ターゲットを復元するためにこれらのディスパッチャーをエミュレートします。

図 24: ディスパッチャーの宛先ターゲットを復元するために使用するエミュレーション シーケンス
図 24 の Python コードは、このロジックを適用して次のように動作します。
-
エミュレータの初期化
-
コードの実行をシミュレートするためのコアエンジン(
EmulateIntel64)を作成し、保護されたバイナリ イメージ(imgbuffer)をエミュレータのメモリスペースにマッピングします。さらに、実際の Windows 実行環境をシミュレートするためにスレッド環境ブロック(TEB)をマッピングし、初期スナップショットを作成します。これにより、各エミュレーションを実行する前に迅速にリセットできるようになり、その都度エミュレータ全体を再初期化する必要がなくなります。 -
MAX_DISPATCHER_RANGEで、ディスパッチャーごとにエミュレートする命令の最大数を指定します。上記のコードでは任意の値として 45 を選択していますが、ミューテーションが追加されていても、ディスパッチャー内の命令数は限られているため、この値は最大数として十分です。 -
try/exceptブロックを使用して、エミュレーション中に発生した例外を処理します。ここでは、前に識別された推定されるディスパッチャーが偽陽性である場合に例外が発生するため、例外を無視しても問題ないとみなされます。 -
推定される各ディスパッチャーのエミュレーション
-
推定されるディスパッチャーのアドレス(
call_dispatch_ea)ごとに、エミュレータのコンテキストが初期スナップショットに復元されます。プログラム カウンタ(emu.pc)は各ディスパッチャーのアドレスに設定されます。emu.stepi()が現行のプログラム カウンタで 1 つの命令を実行した後、命令が分析されて、エミュレーションが完了したかどうかが判別されます。 -
命令が
retの場合、エミュレーションはディスパッチ ポイントに到達したことになります。 -
emu.parse_u64(emu.rsp)を使用して、ディスパッチ ターゲット アドレスがスタックから読み込まれます。 -
d.dispatchers_to_targetが結果をキャプチャし、ディスパッチャーのアドレスをディスパッチ ターゲットにマッピングします。ディスパッチャーのアドレスは、d.dispatcher_locsルックアップ キャッシュにも保存されます。 -
breakステートメントで内部ループが終了し、次のディスパッチャーに移ります。
パッチ適用と線形化
キャプチャされたすべての命令ディスパッチャーを収集して検証したら、最後のステップとして、各 call 位置をその宛先ターゲットへの直接分岐で置き換えます。near call 命令と jmp 命令のサイズはどちらも 5 バイトなので、call 命令に jmp 命令のパッチを適用するだけで、この置き換えをシームレスに行うことができます。
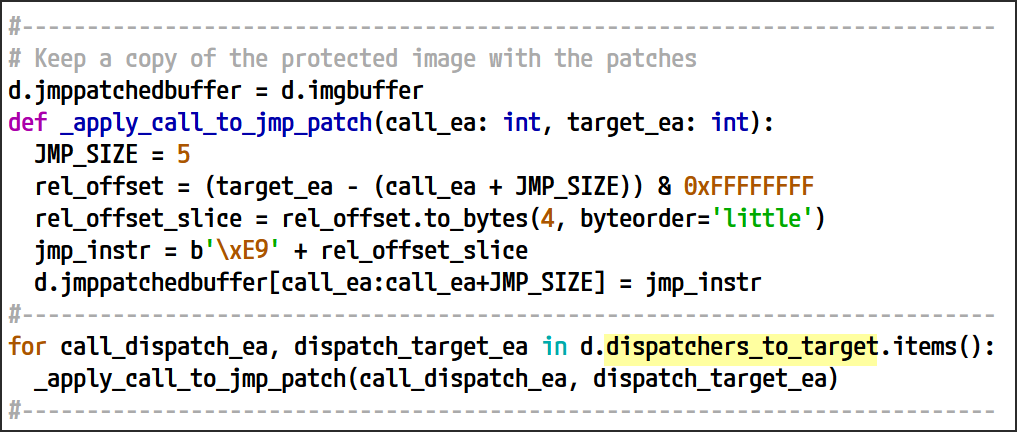
図 25: 命令ディスパッチャー呼び出しを宛先ターゲットへの無条件ジャンプに変換するパッチ適用シーケンス
前のセクションで設定した dispatchers_to_target マップを使用して、各ディスパッチャーの call 位置をその対応する宛先ターゲットに関連付けます。このマップを反復処理することで、各ディスパッチャーの call 位置を特定し、元の call 命令を jmp で置き換えます。この置換により、実行フローが意図されたターゲット アドレスに直接リダイレクトされます。
こうした命令の除去は、Google の難読化解除戦略にとって極めて重要です。これによって、命令ディスパッチャーが提供するように意図された動的ディスパッチ要素が削除されるためです。コードはまだコード セグメント全体に分散されていますが、実行フローは静的かつ決定的なフローに変わり、どの命令が次の命令につながるかがすぐにわかるようになります。
以下の結果を「命令ディスパッチャー」セクションに記載されている最初のスクリーンショットと比べると、ブロックはまだ分散されているように見えます。ただし、実行フローは線形化されています。この進歩により、CFG 復元の 2 番目のフェーズに進むことができます。

図 26: 線形化された命令ディスパッチャーの制御フロー
関数識別と復元
ここまでのところで、命令ディスパッチャーの影響を排除して実行フローを線形化しました。次のステップでは、分散されたコードを結合し、線形化された制御フローを使用して、保護されていないバイナリからなる元の関数を再構成します。この復元フェーズは、未処理の命令の復元、正規化、最終的な CFG の再構築といった複数の段階からなります。
関数識別と復元は、次の 2 つの抽象化にカプセル化されます。
-
復元された命令(
RecoveredInstr): 難読化されたバイナリから復元された個々の命令を表す基本単位。インスタンスごとに、未処理の命令データだけでなく、CFG 復元プロセスに含まれる再配置、正規化、分析に不可欠なメタデータもカプセル化されます。 -
復元された関数(
RecoveredFunc): 難読化されたバイナリから正常に復元された個々の関数の最終結果。複数のRecoveredInstrインスタンスを集約して、保護されていない関数を構成する命令のシーケンスを表します。完全な CFG 復元プロセスでは、RecoveredFuncインスタンスが数多く生成され、各インスタンスはバイナリ内の個別の関数に対応しています。最後の「難読化解除されたバイナリでの再配置の構築」セクションでは、これらの結果を使用して、完全に難読化解除されたバイナリを生成します。
この復元アプローチでは、基本ブロックの抽象化は使用しません。なぜなら、基本ブロックを適切に抽象化するには、完全な CFG 復元が前提条件となるからです。完全な CFG 復元を行うと、ここでの目的には必要のない複雑さとオーバーヘッドが生じてしまいます。この特定の難読化解除のコンテキストでは、関数を基本ブロックの集合ではなく個々の命令の集約として概念化したほうが、シンプルで効率的です。
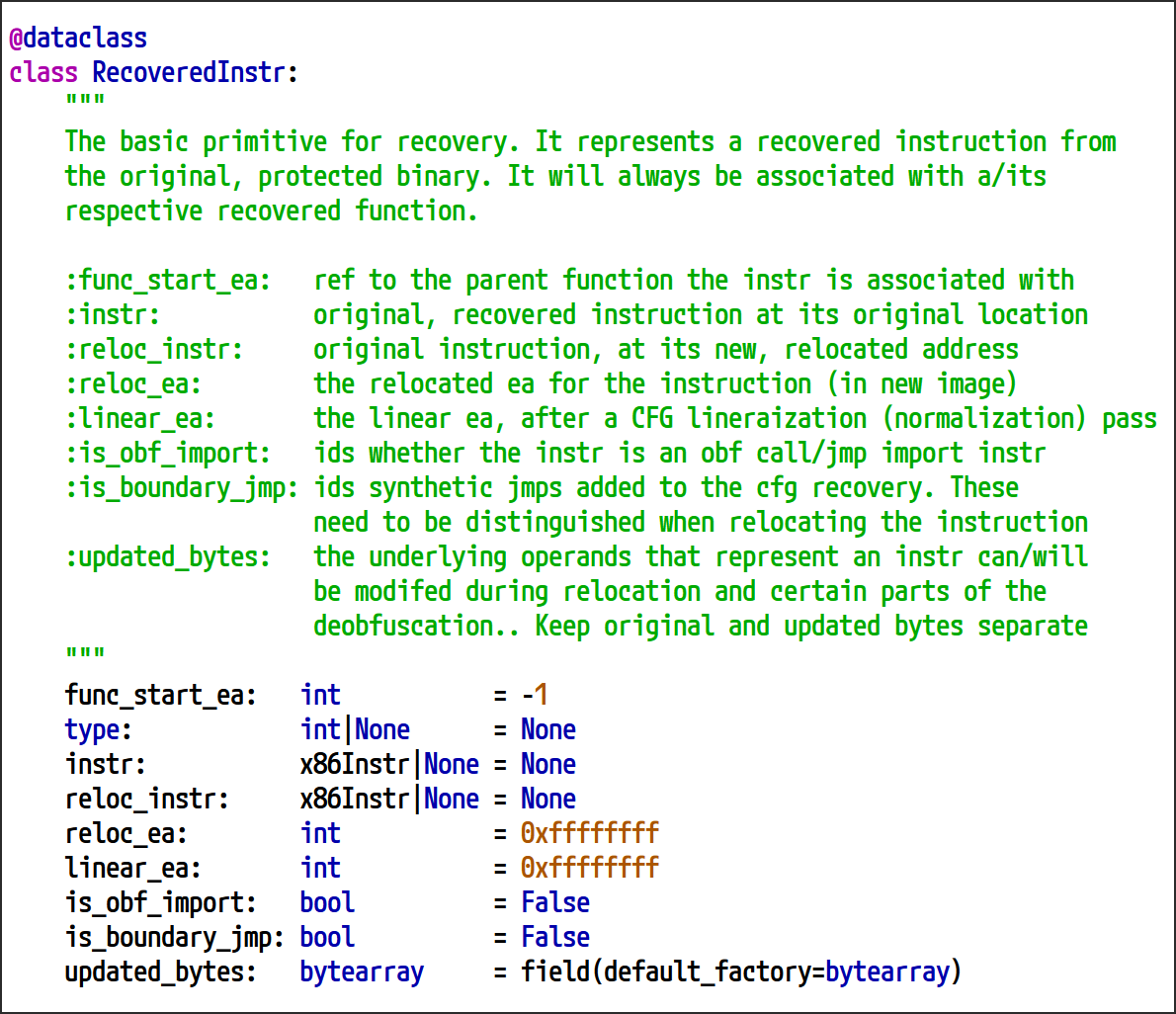
図 27: RecoveredInstr 型の定義

図 28: RecoveredFunc 型の定義
DFS ルール誘導型ステッピングの紹介
Google が再帰的深さ優先探索アルゴリズムを選択した理由は次のとおりです。
-
コードのトラバーサルに適している: DFS を使用すれば、実行フローのみに基づいて関数の境界を推測できます。DFS は、関数が他の関数を呼び出す方法をミラーリングするため、直観的に関数の境界を実装でき、そうすべき状況も直感的に推論できます。また、ループと条件付き分岐を辿るのも簡単になります。
-
実行パスが保証される: このプロセスでは、確実に実行されるコードに集中します。難読化されたコードへの既知のエントリー ポイントが少なくとも 1 つあることを踏まえると、コードの他の部分に到達するために、難読化されたコードが必ずそのエントリー ポイントを通って実行されることがわかります。コードの他の部分がより間接的に呼び出されるなか、このエントリー ポイントが基本的な出発点として機能します。
-
既知のエントリーから再帰的に探索することで、トラバーサルでほぼ確実に、事実上すべてのコードパスと関数を検出して特定できます。
-
命令のミューテーションに適応する: トラバーサルのロジックを、個々の命令の処理方法を規定するコールバック、つまり「ルール」を使用してカスタマイズします。これにより、既知の命令ミューテーションを考慮できるようになるため、難読化コンパイラのコードを除去するのに役立ちます。
このプロセスに関与する主要なデータ構造体は、CFGResult、CFGStepState、RuleHandler です。
-
CFGResult: CFG 復元プロセスの結果を格納するコンテナ。バイナリ内の関数の CFG を表現するために必要なすべての関連情報を集約します。これらの情報は、主にCFGStepStateから取り込みます。 -
CFGStepState: CFG 復元プロセス全体で、特に、ステップを制御したトラバーサル中に状態を維持します。トラバーサルの状態管理に必要なすべての情報をカプセル化して、進捗状況を追跡し、中間結果を保存します。 -
復元されたキャッシュ: 保護された関数用に復元された命令を、追加のクリーンアップや検証は行わずに保存します。この初期のコレクションは、正規化や検証のプロセスが適用される前の、難読化されたバイナリ内にあったときの未処理の状態のまま命令を維持するには必要不可欠となります。これが常に、復元の最初の段階になります。
-
正規化されたキャッシュ: CFG 復元プロセスの最終段階。難読化コンパイラが導入したすべての命令を削除し、関数が有効で首尾一貫していることを確認することで、復元されたキャッシュ内に保存されている未処理の命令を完全に正規化された CFG に変換します。
-
探索スタック: 保護された関数の DFS トラバーサルで、これから探索される一連の命令アドレスを管理します。命令を処理する順序を決定するとともに、
visitedセットを使用して、各命令が一度だけ処理されるようにします。 -
難読化コンパイラのバックボーン: 難読化コンパイラによって導入された必須の制御フローリンクを維持するためのマッピング。
RuleHandler: ミューテーション ルールとは、特定の関数のシグネチャに従った、CFG 復元プロセスの命令ステップごとに呼び出されるコールバックにすぎません。入力として、保護された現在のバイナリ(CFGStepState)と現在探索対象となっている命令を受け取ります。ルールごとに、難読化コンパイラが導入した命令特性の特定のタイプを検出するように設計された固有のロジックが含まれます。ルールでは、これらの特性の検出に基づいてトラバーサルを進める方法を決定します。たとえば、ルールがミューテーションの特性に基づいて、トラバーサルの続行、特定の命令のスキップ、あるいはプロセスの停止を決定する場合があります。

図 29: CFGResult 型の定義

図 30: CFGStepState 型の定義

図 31: RuleHandler 型の定義
以下の図は、ルールの一例を示しています。このルールは、前のセクションで導入したパッチ適用後の命令ディスパッチャーを検出して、標準の jmp 命令から区別するために使用されます。

図 32: パッチ適用後の命令ディスパッチャーを特定し、標準の jmp 命令から区別する RuleHandler の例
DFS ルール誘導型ステッピングの実装
残りのコンポーネントは、保護されたバイナリ内の所定の関数アドレスの CFG 復元プロセスをオーケストレートするルーチンです。このルーチンは CFGStepState を使用して DFS トラバーサルを管理し、ミューテーション ルールを適用して体系的に命令をデコードし、復元します。その結果は、RecoveredInstr インスタンスの集約になります。これらのインスタンスが、未処理の命令を復元する出発点となります。

図 33: DFS ルール誘導型ステッピング アルゴリズムのフローチャート
以下の Python コードは、図 33 に示されているアルゴリズムを直接実装します。このコードは CFG ステッピング状態を初期化して、関数のエントリー アドレスから DFS トラバーサルを開始します。トラバーサルの各ステップで、現在の命令アドレスが to_explore 探索スタックから取得されて、冗長な処理を防ぐために visited セットに照らしてチェックされます。次に、現在のアドレスにある命令がデコードされ、一連のミューテーション ルールが適用されて、難読化コンパイラによる命令の変更が処理されます。これらのルールによる処理結果に基づいて、トラバーサルが続行されるか、特定の命令がスキップされるか、プロセス全体が停止します。
復元された命令は recovered キャッシュに追加され、その命令に対応するマッピングが CFGStepState 内で更新されます。続いて、体系的なトラバーサルが行われるように、次に続く命令のアドレスで to_explore スタックが更新されます。この反復プロセスは、関連するすべての命令が探索されて、完全に復元された CFG が CFGResult にカプセル化されるまで続きます。

図 34: DFS ルール誘導型ステッピング アルゴリズムの Python 実装
フローの正規化
未処理の命令が正常に復元されたら、次のステップとして、制御フローを正規化します。未処理の命令の復元プロセスにより、元のすべての命令がキャプチャされますが、これらの命令だけでは、完全な秩序だった関数の形にはなりません。合理化された制御フローを実現するには、復元された命令をフィルタして絞り込む必要があります。これが、正規化と呼ばれるプロセスです。この段階で行う主なタスクは以下のとおりです。
-
分岐ターゲットの更新: 難読化コンパイラによって導入されたすべてのコード(命令ディスパッチャーとミューテーション)が完全に削除されたら、すべての分岐命令を正しい宛先にリダイレクトする必要があります。難読化の分散効果によって、分岐の宛先が無関係のコード セグメントのままになることはよくあります。
-
重複する基本ブロックの結合: 基本ブロックには厳密に 1 つの開始位置と 1 つの終了位置しかないという考え方に反して、基本ブロックが別の基本ブロックの中で始まっているコードがコンパイラで生成される場合があります。この基本ブロックの重複は、一般的にループ構造体で見られるものです。したがって、首尾一貫している CFG を実現するには、これらの重複を解決しなければなりません。
-
関数の適切な境界命令: 各関数は、バイナリのメモリスペース内で明確に定義された境界で開始し、終了しなければなりません。これらの境界を正しく特定して適用することが、正確な CFG 表現と以降の分析には不可欠です。
合成境界ジャンプによる簡素化
従来の基本ブロックの抽象化には不要なオーバーヘッドが伴うため、この抽象化ではなく合成境界ジャンプを使って CFG 正規化を簡素化します。分離されている命令をこれらの人工的な jmp 命令でリンクすることで、重複するブロックの分割を回避して、各関数が適切な境界命令で終了するようにします。また、このアプローチにより、復元された関数を難読化解除された最終的な出力バイナリに再構成する際のバイナリの書き換えプロセスも合理化されます。
重複する基本ブロックを結合する際も、関数に適切な境界命令が適用されるようにする際も、同じ問題に突き当たります。つまり、分散されたどの命令同士をリンクさせるかを判断しなければならないという問題です。例として、合成ジャンプによって関数が正しい境界命令で終わるようにして、この問題を効果的に解決する方法を確認しましょう。これとまったく同じアプローチを、基本ブロックの結合にも適用できます。
関数の境界を定める合成境界ジャンプ
たとえば、DFS ベースのルール誘導型アプローチを使用して関数を正常に復元したとします。CFGState 内の復元された命令を調べると、最後の演算が mov 命令であることがわかります。この関数を現状のままメモリ内で再構成すると、後続のフォールスルー命令がないことが原因で、関数のロジックが損なわれてしまいます。

図 35: 関数の自然な境界命令で終了していない、未処理の命令の復元例
この問題に対処するために、復元された最後の命令が関数の自然な境界命令(ret、jmp、int3 など)でない場合は常に、合成ジャンプを導入します。

図 36: 関数の境界命令を識別する単純な Python ルーチン
フォールスルー アドレスを判断した結果、そのアドレスが難読化コンパイラによって導入された命令を指している場合は、最初の正規の命令に到達するまで進み続けます。このトラバーサルを「難読化コンパイラのバックボーン追跡」と呼んでいます。

図 37: 難読化コンパイラのバックボーン追跡ロジックを実装する Python ルーチン
次に、これらのポイントを合成ジャンプでリンクします。合成ジャンプは元のアドレスをメタデータとして継承することで、論理的なつながりのある命令を示します。
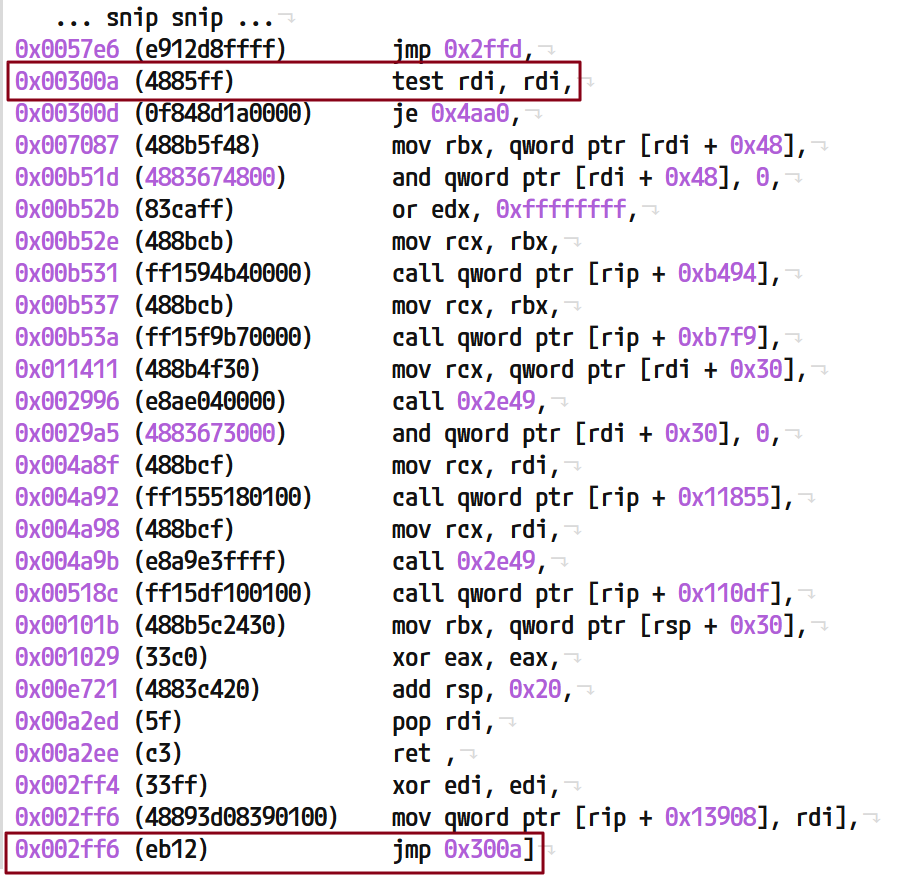
図 38: 合成境界ジャンプを追加して関数の自然な境界を作成する例
分岐ターゲットの更新
制御フローを正規化した後は、分岐ターゲットを調整する作業は単純なプロセスとなります。場合によっては、復元されたコード内の各分岐命令は、意図された宛先ではなく、難読化コンパイラによって導入された命令をまだ指しています。normalized_flow キャッシュ(次のセクションで生成されるキャッシュ)を反復処理することで、分岐命令を特定して、そのターゲットを walk_backbone ルーチンによって検証します。
これにより、すべての分岐ターゲットが難読化コンパイラのアーティファクトからリダイレクトされ、意図された実行パスと正しく整合するようになります。call 命令は無視することができます。なぜなら、ディスパッチャー以外の call 命令は常に正当なものであり、難読化コンパイラの保護対象になることはないからです。ただし、これらの命令は、「難読化解除されたバイナリでの再配置の構築」セクションで説明する最後の再配置フェーズで更新する必要があります。
再計算した後、更新されたディスプレースメントで命令を再アセンブルしてデコードし、正確さと整合性の両方を維持します。

図 39: すべての分岐ターゲットを更新する Python ルーチン
すべてをまとめる
Google は、すべてをまとめるために次のアルゴリズムを開発しました。このアルゴリズムは前に復元された命令を基盤とし、それぞれの命令、分岐、ブロックが適切に接続されるようにします。これにより、保護されたバイナリ全体の CFG が完全に復元され、難読化解除されます。復元されたキャッシュを使用して、正規化されたキャッシュを新たに作成します。このアルゴリズムのステップは以下のとおりです。
1. 復元されたすべての命令を反復処理する
-
DFS ベースのステッピング アプローチによって復元されたすべての命令を走査します。
2. 正規化されたキャッシュに命令を追加する
-
正規化されたキャッシュに各命令を追加します。これによって正規化段階の結果がキャプチャされます。
3. 境界命令を特定する
-
現在の命令が境界命令であるかどうかをチェックします。
-
境界命令である場合は、その命令の以降の処理をスキップし、次の命令に進みます(ステップ 1 に戻ります)。
4. 想定されるフォールスルー命令を計算する
-
メモリ内で現在の命令の後に続く命令を特定して、想定されるフォールスルー命令を判断します。
5. フォールスルー命令を検証する
-
計算されたフォールスルー命令を、復元されたキャッシュ内の次の命令と比較します。
-
フォールスルー命令が、メモリ内で次に続く命令でない場合は、それが正規化した復元済みの命令であるかどうかをチェックします。
-
正規化した復元済みの命令である場合は、合成ジャンプを追加して 2 つの命令を正規化されたキャッシュ内でリンクします
-
正規化した復元済みの命令でない場合は、それを接続するフォールスルー命令を復元済みキャッシュから取得し、正規化されたキャッシュに追加します。
-
フォールスルー命令が、復元済みキャッシュで次に続く命令と一致する場合:
-
復元された命令はすでに正しいフォールスルーを指しているため、何もしません。ステップ 6 に進みます。
6. 最終命令を処理する
-
現在の命令が復元されたキャッシュ内の最終命令であるかどうかをチェックします。
-
最終命令である場合:
-
この段階まで達している場合は、ステップ 3 でのチェックに失敗しているため、最終的な合成境界ジャンプを追加します。
-
反復処理を続行します。これによってループが終了します。
-
-
最終命令でない場合:
- 通常どおりに反復処理を続行します(ステップ 1 に戻ります)。
-

図 40: 正規化アルゴリズムのフローチャート
図 41 の Python コードは、これらの正規化ステップを直接実装します。復元された命令を反復処理し、それらの命令を正規化されたキャッシュ(normalized_flow)に追加し、線形マッピングを作成して、合成ジャンプが必要な場所を特定します。分岐ターゲットが難読化コンパイラによって注入されたコードを指している場合は、バックボーンを追跡して(walk_backbone)次の正当な命令を見つけます。関数の終わりに達した場所に自然な境界がない場合、合成ジャンプを作成して適切な継続性を確保します。反復処理が完了したら、前のセクションで説明したように、すべての分岐ターゲットを更新します(update_branch_targets)。これにより、各命令が適切にリンクされて、完全に正規化された CFG になります。

図 41: 正規化アルゴリズムの Python 実装
結果の確認
2 つの主な段階が完了し、ほぼすべての保護メカニズムが排除されました。まだインポート保護に対処する必要がありますが、このアプローチによって、理解不能な制御フローが完全に復元された CFG に効果的に変換されます。
たとえば、図 42 と図 43 は、プラグイン マネージャー システムのコンポーネントであるバックドア ペイロード内の重要な関数を変換する前と変換した後を示しています。出力を詳細に分析することで、機能を特定できるようになります。Google の難読化解除プロセスがなければ、機能の詳細を正確に説明することは不可能です。

図 42: 元の難読化された shadow::PluginProtocolCreateAndConfigure ルーチン

図 43: 完全に難読化解除され、機能する shadow::PluginProtocolCreateAndConfigure ルーチン
インポートの復元
元のインポート テーブルの復元では、どのインポート位置がどのインポート ディスパッチャー スタブに関連付けられているかを特定する作業を中心に行います。スタブ ディスパッチャーで該当する obf_imp_t 参照を解析すると、そのディスパッチャーが表す保護されたインポートを判断できます。
ここで追及するのは次のロジックです。
-
インポートに関連付けられている有効な call / jmp の位置をそれぞれ特定する
-
これらのメモリ ディスプレースメントは、該当するディスパッチャー スタブを指します。
-
ヘッダーレス モードでは、最初にフィックスアップ テーブルを解決して、そのディスプレースメントが有効なディスパッチャー スタブを指していることを確認する必要があります。
-
有効な位置ごとに、ディスパッチャー スタブを走査して obf_imp_t を抽出する
-
obf_imp_tには、暗号化された DLL 名と API 名の RVA が含まれています。 -
文字列復号ロジックを実装する
-
DLL 名と API 名を復元するには、復号ロジックを再実装する必要があります。
-
これは、最初の「インポート保護」セクションですでに行っています。
以下の RecoveredImport データ構造体を使用して、インポートの復元をカプセル化します。

図 44: RecoveredImport 型の定義
RecoveredImport は、復元する各インポートで生成される結果として機能します。難読化解除されたイメージの生成時に元のインポート テーブルを再構成するために使用する、すべての関連データが格納されています。
保護されたインポートの call サイトと jmp サイトの場所を特定する
保護された各インポート位置には、間接的な near call(FF/2)または間接的な near jmp(FF/4)のどちらかが反映されます。

図 45: インポートの call 表現と jmp 表現の逆アセンブリ
間接的な near call と near jmp が属する FF グループ オペコードでは、ModR/M バイトに含まれる Reg フィールドが、このグループに固有の演算を特定します。
-
/2:CALL r/m64に相当 -
/4:JMP r/m64に相当
たとえば間接的な near call を分解すると、次のようになります。
1. FF: グループ オペコード。
2. 15: RIP 相対アドレス指定で CALL r/m64 を指定する ModR/M バイト。
-
15はバイナリで00010101としてエンコードされます。 -
Mod(ビット 6~7):
00 -
RIP 相対の直接ディスプレースメントであるか、ディスプレースメントなしのメモリアドレス指定であるかを示します。
-
Reg(ビット 3~5):
010 -
グループに対する call 演算を特定します。
-
R/M(ビット 0~2):
101 -
Mod
00と R/M101の 64 ビットモードでは、これが RIP 相対アドレス指定であることを示します。
3. <32 ビットのディスプレースメント>: 絶対アドレスを計算するために RIP に追加されます。
保護された各インポート位置とその関連ディスパッチャー スタブを見つけるために、単純なブルート フォース スキャナを実装して、推定されるすべての間接的 near call / jmp の位置をその最初の 2 つのオペコードで特定します。

図 46: 推定されるすべてのインポート位置を特定するブルート フォース スキャナ
この図に記載されているコードは、保護されたバイナリのコード セクションをスキャンし、間接的な call 命令と jmp 命令に関連付けられているオペコード パターンを持つすべての位置を特定して記録します。この最初のステップに基づいて、これが有効なインポート サイトであることを保証するための追加の検証を適用します。
インポート フィックスアップ テーブルの解決
ヘッダーレス モードで保護されたインポートの復元時には、どのインポート位置がどのディスパッチャーに関連付けられているのかを特定するために、フィックスアップ テーブルを解決する必要があります。保護されたインポート サイトでのメモリ ディスプレースメントは、テーブル内の解決された位置とペアになっています。このディスプレースメントをテーブル参照として使用して、対応する解決済みの位置を見つけます。
特定のインポートへの jmp 命令を例に、この仕組みを見ていきましょう。

図 47: jmp インポート命令の例(インポート フィックスアップ テーブルの該当エントリと関連ディスパッチャー スタブを含む)
この jmp 命令のディスプレースメントでは、ガベージデータを指すメモリ位置 0x63A88 を参照しています。メモリ ディスプレースメントを使用して、フィックスアップ テーブル内のこのインポートのエントリを調べると、このインポートに関連付けられているディスパッチャー スタブの位置は 0x295E1 であることがわかります。ローダは 0x63A88 にある参照先データを 0x295E1 で更新するため、jmp 命令が呼び出されると、このディスパッチャー スタブにコードの実行が適切にリダイレクトされます。
図 48 は、フィックスアップ テーブルを解決するローダ内の難読化解除されたコードを示しています。各インポート位置を適切なディスパッチャーに関連付けるには、この動作を模倣する必要があります。
$_Loop_Resolve_ImpFixupTbl:
mov ecx, [rdx+4] ; DLL、API、または ImpStub のいずれかのフィックスアップ
mov eax, [rdx] ; 「フィックスアップ」が必要なターゲット参照の場所
inc ebp ; カウンタを更新
add rcx, r13 ; フィックスアップを完全に計算(r13 は imgbase)
add rdx, 8 ; 次のペアエントリ
mov [r13+rax+0], rcx ; ターゲット参照位置を完全なフィックスアップで更新
movsxd rax, dword ptr [rsi+18h] ; imptbl の合計サイズ(バイト数)をフェッチ
shr rax, 3 ; サイズをペアエントリとして考慮
cmp ebp, eax ; すべてのエントリの処理が完了したかどうかをチェック
jl $_Loop_Resolve_ImpTbl図 48: インポート フィックスアップ テーブルを解決するために使用するアルゴリズムの難読化解除された逆アセンブリ
インポート フィックスアップ テーブルを解決するには、まず、保護されたバイナリ内のデータ セクションと、インポート テーブルを識別するメタデータ(IMPTBL_OFFSET、IMPTBL_SIZE)を特定する必要があります。フィックスアップ テーブルへのオフセットは、データ セクションの開始位置を基準としています。

図 49: インポート フィックスアップ テーブルを解決するために使用するアルゴリズムの Python 再実装
フィックスアップ テーブルの開始位置がわかったら、一度に 1 つのエントリを反復処理し、どのインポート ディスプレースメント(location)がどのディスパッチャー スタブ(fixup)に関連付けられているのかを特定します。
インポートの復元
ブルート フォース スキャンで推定されるすべてのインポート位置を取得し、ヘッダーレス モードでの再配置を考慮したら、最終的な検証に進んで、保護されたそれぞれのインポートを復元できます。この復元プロセスは次のように実施されます。
1. インポート位置を有効な call または jmp 命令にデコードする
-
デコードの失敗は、その位置に有効な命令がないことを意味するため、無視してかまいません。
2. メモリ ディスプレースメントを使用して、インポートのスタブの位置を特定する
-
ヘッダーレス モードでは、各ディスプレースメントが、それぞれのディスパッチャーへのフィックスアップ テーブルのルックアップ キーの役割を果たします。
3. ディスパッチャー内の obf_imp_t 構造体を抽出する
-
この構造体を抽出するために、ディスパッチャーの逆アセンブリ リスティングを静的に走査します。
-
最初に出現する
lea命令に、obf_imp_tへの参照が含まれています。
4. obf_imp_t を処理して DLL 名と API 名の両方を復号する
-
この構造体に含まれている 2 つの RVA を使用して、DLL 名と API 名の暗号化された blob を見つけます。
前に説明したインポート復号ルーチンを使用して blob を復号します。

図 50: 保護された各インポートを復元するループ
この Python コードは、推定されるすべてのインポート位置(potential_stubs)を反復処理し、インポートへの推定される call 命令または jmp 命令をそれぞれデコードしようと試みます。命令のデコードエラーやその他の例外が生じた場合にこれを処理するために、try / except ブロックを使用しています。ここでは、エラーは復元プロセスに対する理解が間違っていることを意味し、無視してかまわないことを前提としています。完全なコードでは、エラーが発生した場合にエラーをログに記録して追跡し、さらに分析できるようにします。
次に、このコードは GET_STUB_DISPLACEMENT ヘルパー関数を呼び出して、インポートに関連付けられているディスパッチャーの RVA を取得します。保護モードに応じて、以下のルーチンのいずれかが使用されます。

図 51: 保護モードに基づいてスタブの RVA を取得するルーチン
recover_import_stub 関数を使用してインポート スタブの制御フローグラフ(CFG)を再構成し、_extract_lea_ref でその CFG 内の命令を調べて、obf_imp_t への lea 参照を見つけます。GET_DLL_API_NAMES 関数は GET_STUB_DISPLACEMENT と同じように動作しますが、保護モードによる若干の違いを考慮しています。

図 52: 保護モードに基づいて DLL および API の blob を復号するルーチン
復号された DLL 名と API 名を取得した後、このコードは、保護によって隠されているインポートを明らかにするうえで必要なすべての情報を処理します。各インポート エントリの最終出力が RecoveredImport オブジェクトと次の 2 つのディクショナリにキャプチャされます。
-
d.imports -
このディクショナリは、保護された各インポートのアドレスを復元された状態のインポートにマッピングします。これにより、完全な復元の詳細を、バイナリ内でインポートが行われる特定の位置に関連付けることができます。
-
d.imp_dict_builder -
このディクショナリは、各 DLL 名を対応する一連の API 名にマッピングします。インポート テーブルの再構築時にこのディクショナリを使うことで、バイナリが使用する DLL と API の固有の組み合わせが反映されます。
この体系的な収集と編成により、難読化解除された出力で元の機能を復元するために必要なデータを準備します。図 53 と図 54 に示している 2 つのコンテナを見ると、復元が成功した後の構造がわかります。

図 53: 復元が成功した後の d.imports ディクショナリの出力

図 54: 復元が成功した後の d.imp_dict_builder ディクショナリの出力
最終結果の確認
最後のステップでは、上記のデータを使用してインポート テーブルを再構築します。このステップは、pefile_utils.py ソースファイル内の build_import_table 関数によって行われます。この部分の説明は長くなり、単調なステップが多く含まれるため、このブログ投稿では説明を省略します。しかし、インポート テーブルの再構築に必要なあらゆる側面を示すために、コードを適切に構造化し、細かくコメントを残しています。
以下の図は、完全に機能するバイナリをヘッダーレス モードで保護された入力からどのように生成するのかを示しています。前述したとおり、ヘッダーレス モードで保護された入力は未処理のヘッダーレス PE バイナリであり、シェルコード blob とほぼ同様です。この blob から、インポート保護を完全に復元した、まったく新しい機能するバイナリを生成します。この完全な復元は、すべての保護モードで実現できます。

図 55: ヘッダーレス モードで保護されたバイナリの完全に復元されたインポート テーブルの表示
難読化解除されたバイナリでの再配置の構築
保護されたバイナリの CFG を完全に復元し、元のインポート テーブルの完全な復元に対応できるようになったので、難読化解除の最後のフェーズでは、これらの要素を結合して、難読化解除された機能するバイナリを生成します。このプロセスを担当するコードは、recover_output64.py と pefile_utils.py の Python ファイル内にカプセル化されています。
この再構築プロセスは、次の 2 つのステップからなります。
-
出力イメージ テンプレートを作成する
-
再配置を構築する
1. 出力イメージ テンプレートを作成する
難読化解除されたバイナリを生成するには、出力イメージ テンプレートを作成することが不可欠です。そのために必要な主なタスクは 2 つあります。
-
PE テンプレート イメージ: 難読化されたすべてのコンポーネントの復元機能を含む出力バイナリのコンテナの役割を果たす、ポータブル実行可能(PE)テンプレート。メモリ内の PR 実行可能ファイルとファイル上の PE 実行可能ファイルの間で異なるすべての特性についても、認識しておく必要があります。
-
さまざまな保護モードへの対処: 保護モードと入力ごとに異なる要件があります。
-
ヘッダーレス モードのバリエーションでは、ファイル ヘッダーが取り除かれます。機能するバイナリを正確に復元するには、これらのバリエーションを考慮する必要があります。
-
選択的保護モードでは、元のインポートを維持して機能を保つと同時に、選択された関数内で使用するすべてのインポートに対して特定のインポート保護を組み込みます。
2. 再配置を構築する
再配置の構築は、難読化解除プロセスの重要かつ複雑な部分です。このステップでは、難読化解除されたバイナリ内のすべてのアドレス参照が、機能を維持するよう正しく調整されるようにします。このステップは一般的に、次の 2 つのフェーズを中心に展開されます。
-
再配置可能なディスプレースメントを計算する: バイナリ内のメモリ参照のうち、再配置する必要があるものをすべて特定します。ここでは、これらの参照が指す新しいアドレスも計算します。ここで使用する手法では、元のメモリ参照を新しい再配置可能なアドレスにマッピングするルックアップ テーブルを生成します。
-
フィックスアップを適用する: バイナリのコードに変更を加えて、新しい再配置可能なアドレスを反映させます。それには、前述のルックアップ テーブルを使用して、メモリを参照するすべての命令ディスプレースメントに対して必要なフィックスアップを適用します。これにより、バイナリ内のすべてのメモリ参照が意図された場所を正しく指すようにします。
ここでは意図的に、出力バイナリ イメージの再ビルドについての説明を省略します。難読化解除において重要なプロセスではありますが、比較的単純で単調なプロセスなため、ここでは細かく確認しません。代わりに、再配置に焦点を当てます。再配置にはもう少し細かい配慮が必要であり、一見明らかではないけれど、バイナリの書き換え時には理解しておく必要がある重要な特性を提示するからです。
再配置プロセスの概要
難読化解除されたバイナリを実行可能な状態に復元するうえで、再配置の再構築は不可欠なステップです。このプロセスでは、コードが移動または変更された後に、すべてのメモリ参照が正しい場所を指すようにコード内のメモリ参照を調整します。x86-64 アーキテクチャで主に重要となるのは、RIP 相対アドレス指定を使用する命令です。このモードでは、メモリ参照は命令ポインタを基準とした相対アドレスとなります。
難読化解除の際にコードが挿入、削除、シフトされるなどしてバイナリのレイアウトが変わった場合は、再配置が必要になります。この難読化解除アプローチでは難読化コンパイラから元の命令を抽出するため、復元された各命令を新しいコード セグメントに適切に再配置する必要があります。こうすることで、難読化解除された状態ですべてのメモリ参照が引き続き有効であることが保証され、元の制御およびデータフローの精度が維持されます。
命令の再配置の理解
命令の再配置は、次の要素を中心に行われます。
-
命令のメモリアドレス: 命令が存在する、メモリ内の位置です。
-
命令のメモリのメモリ参照: 命令のオペランドで使用するメモリ位置への参照です。
例として、次の 2 つの命令について考えてみましょう。

図 56: 再配置が必要となる 2 つの命令のイラスト
-
-
無条件
jmp命令: この命令はメモリアドレス0x10000x4E22にある分岐ターゲットを参照しています。命令内にエンコードされたディスプレースメントは 0x3E1D です。これを使用して、命令の位置を基準とした分岐ターゲットの相対アドレスを計算します。この命令は RIP 相対アドレス指定を使用しているため、宛先を計算するには、命令の長さとそのメモリアドレスにディスプレースメントを加算します。 -
lea命令: これは、0x4E22に位置するjmp命令の分岐ターゲットです。この命令には、データ セグメントへのメモリ参照と、エンコードされたディスプレースメント0x157が含まれています。
これらの命令を再配置する際は、次の側面の両方に対処する必要があります。
-
命令のアドレスを変更する: 再配置プロセスで命令を新しいメモリ位置に移動すると、本質的にそのメモリアドレスも変更することになります。たとえば、この命令を
0x1000から0x2000に再配置すると、命令のアドレスは0x2000になります。
メモリ ディスプレースメントを調整する: 命令内のディスプレースメント(
jmpの場合は0x3E1D、leaの場合は0x157)は、命令の元の位置とその参照の位置に基づいて計算されます。命令が移動すると、ディスプレースメントは正しいターゲット アドレスを指さなくなります。したがって、ディスプレースメントを再計算して、命令の新しい位置を反映させる必要があります。 -

図 57: 再配置のデモのイラスト
難読化解除プロセスで命令を再配置するときは、正確な制御フローとデータアクセスを実現する必要があります。そのためには、命令のメモリアドレスと、他のメモリ位置を参照するディスプレースメントの両方を調整しなければなりません。これらの値を更新しないと、復元された CFG が無効になります。
RIP 相対アドレス指定とは
RIP 相対アドレス指定とは、命令が RIP(命令ポインタ)レジスタを基準としたオフセットに位置するメモリを参照するモードのことです。RIP レジスタは、次に実行される命令を指します。このモードでは、命令が絶対アドレスを使用する代わりに、現在の命令ポインタからの署名付き 32 ビット ディスプレースメントで参照先アドレスをカプセル化します。
命令ポインタを基準とした相対アドレス指定は x86 でも使用されますが、この場合に使用される対象は、相対ディスプレースメントをサポートする制御転送命令のみです(JCC 条件付き命令、near call、near jmp など)。x64 ISA はこれを拡張し、ほぼすべてのメモリ参照を RIP 相対アドレスとして考慮します。たとえば、x64 Windows バイナリ内のほとんどのデータ参照は RIP 相対アドレスとなっています。
デコードされた Intel x64 命令の複雑さを可視化する優れたツールとして、ZydisInfo を使用できます。ここではこのツールを使用して、lea 命令(488D151B510600 としてエンコードされています)が 0x6511b に位置する RIP 相対メモリを参照する方法を説明します。

図 58: lea 命令の ZydisInfo 出力
ほとんどの命令では、ディスプレースメントを命令の末尾の 4 バイトにエンコードします。即値がメモリ位置に保存される場合は、その即値がディスプレースメントの後に続きます。即値は最大 32 ビットに制限されています。つまり、ディスプレースメントの後に 64 ビットの即値を使用することはできません。一方、このエンコード方式では 8 ビットと 16 ビットの即値がサポートされています。

図 59: 即値オペランドを保存する mov 命令の ZydisInfo 出力
制御転送命令のディスプレースメントは、即値オペランドとしてエンコードされ、RIP レジスタが暗黙的に基準として機能します。この暗黙的な役割は、jnz 命令をデコードすると明らかになります。この命令では、ディスプレースメントが命令内に直接エンコードされて、現在の RIP を基準に計算されます。

図 60: 即時オペランドをディスプレースメントとして使用する jnz 命令の ZydisInfo 出力
再配置プロセスのステップ
再配置を再構築するために、次のアプローチを取ります。
1. コード セクションを再構築して、再配置マップを作成する: 復元された CFG とインポートでの変更を、完全に難読化解除されたコードを含む新しいコード セクションに commit します。その方法は次のとおりです。
-
関数ごとの処理: 各関数を一度に 1 つずつ再構築します。こうすることで、各命令の再配置をそれぞれの関数内で管理できます。
-
命令の位置の追跡: 各関数の再構築時に、各命令の新しいメモリ位置を追跡します。ここでは、元の命令のアドレスを難読化解除されたバイナリ内の新しいアドレスにマッピングするグローバル再配置ディクショナリを維持します。このディクショナリは、フィックスアップ フェーズで正確に参照を更新する際に不可欠となります。
2. フィックスアップを適用する: コード セクションを再構築して再配置マップを作成したら、命令に変更を加えて、その命令のメモリ参照が難読化解除されたバイナリ内の正しい位置を指すようにして、バイナリの完全な機能を復元します。これは、命令で使用しているコードまたはデータへのメモリ参照を調整することで実現します。
コード セクションを再構築して、再配置マップを作成する
難読化解除された新しいコード セグメントを作成するために、復元された関数のそれぞれを反復処理して、固定されたオフセット(たとえば、0x1000)から、すべての命令を順にコピーします。このプロセス中に、各命令を再配置後のアドレスにマッピングするグローバル再配置ディクショナリ(global_relocs)を作成します。このマッピングは、フィックスアップ フェーズでメモリ参照を調整する際に不可欠となります。
global_relocs ディクショナリはルックアップ キーとしてタプルを使用します。各キーには、そのキーが表す命令の再配置後のアドレスが関連付けられます。このタプルを構成する 3 つのコンポーネントは次のとおりです。
-
関数の元の開始アドレス: 保護されたバイナリ内での関数が開始されるアドレス。このアドレスは、命令が属する関数を識別します。
-
関数内での元の命令のアドレス: 保護されたバイナリ内での命令のアドレス。関数内の最初の命令の場合、このアドレスは関数の開始アドレスと同じです。
- 合成境界 JMP フラグ: 命令が正規化の際に導入された合成境界ジャンプであるかどうかを示すブール値。これらの合成命令は、元の難読化されたバイナリには存在していなかったものです。したがって、元のアドレスがないため、再配置の際は特に考慮する必要があります。

図 61: 新しいコード セグメントと再配置マップの生成方法を示すイラスト
以下の Python コードで、図 61 に示されているロジックを実装します。簡潔にするために、エラー処理とロギングコードは省略しています。

図 62: コード セグメントの構築と再配置マップの生成を実装する Python ロジック
-
現在のオフセットを初期化するコード セクションが配置される、新しいイメージ バッファ内の開始位置を設定します。変数
curr_offはstarting_off(通常は0x1000)に初期化されます。これは、PE ファイルに含まれる.textセクションの従来の開始アドレスを表します。選択的保護モードでは、これは保護された関数の開始位置までのオフセットになります。 -
復元された関数を反復処理する難読化解除された制御フローグラフ(
d.cfg)内の復元された各関数をループ処理します。func_eaは元の関数のエントリー アドレスです。rfn は、復元された関数の命令とメタデータをカプセル化するRecoveredFuncオブジェクトです。 -
まず関数の開始アドレスを処理する
-
関数の再配置後の開始アドレスを設定する: 現在のオフセットを
rfn.reloc_eaに割り当てて、この関数が新しいイメージ バッファで開始する位置をマークします。 -
グローバル再配置マップを更新する: グローバル再配置マップ
d.global_relocsにエントリを追加して、元の関数のアドレスをその新しい位置にマッピングします。 -
復元された各命令を反復処理する関数内の命令の正規化されたフローをループ処理します。
normalized_flowを使用している理由は、命令を新しいイメージに適用する際に、各命令を線形に反復処理できるためです。 -
命令の再配置後のアドレスを設定する: 現在のオフセットを
r.reloc_eaに割り当てて、この命令が新しいイメージ バッファ内で存在する場所を示します。 -
グローバル再配置マップを更新する: 命令のエントリを
d.global_relocsに追加して、命令の元のアドレスを再配置後のアドレスにマッピングします。 -
出力イメージを更新する: 命令のバイト数を新しいイメージ バッファ
d.newimgbufferの現在のオフセットに書き込みます。難読化解除の際に命令が変更されている場合は、変更後の命令のバイト数(r.updated_bytes)を使用します。命令が変更されていない場合は、元のバイト(r.instr.bytes)を使用します。 -
オフセットを進める: 命令のサイズの分だけ
curr_offを増分して、バッファ内の次の空いている位置を指します。残りの位置がすべて使用されるまで、オフセットを次の命令に進めていきます。 -
現在のオフセットを 16 バイトの境界に合わせる: 関数内のすべての命令を処理したら、
curr_offを次の 16 バイトの境界に合わせます。ここでは、最後の命令からの任意のポインター サイズの値として 8 バイトを使用してパディングするため、次の関数が前の関数の最後の命令と競合することはありません。この設定は、次の関数での適切なメモリ アライメントも実現します。適切なメモリ アライメントは、x86-64 アーキテクチャでのパフォーマンスと正確さには非常に重要となります。すべての関数を処理し終えるまで、ステップ 2 からプロセスを繰り返します。
この段階的なプロセスにより、難読化解除されたバイナリの実行可能なコード セクションが正確に再構築されます。各命令を再配置することで、次のフィックスアップ フェーズで使用する出力テンプレートをコードで準備できます。この場合、参照は正しい位置を指すように調整されています。
フィックスアップを適用する
難読化解除されたコード セクションを構築して、復元された各関数を完全に再配置したら、フィックスアップを適用して復元されたコード内のアドレスを修正します。このプロセスで、新しい出力イメージ内の命令のバイト数を調整して、すべての参照が正しい場所を指すようにします。これは、難読化解除された機能するバイナリを再構築する際の最後のステップです。
主にフィックスアップが制御フロー命令とデータフロー命令のどちらに適用されるかに基づいて、フィックスアップを 3 種類のカテゴリに分類しています。制御フロー命令については、標準の分岐命令と、インポート保護を介して難読化コンパイラによって導入された分岐命令の 2 種類があります。それぞれに固有の微妙な違いがあり、各カテゴリに正確なロジックを適用するには、カスタマイズされた処理が必要となります。
-
インポートの再配置: 復元されたインポートの呼び出しと、これらのインポートへのジャンプを行います。
-
制御フローの再配置: 標準のすべての制御フローの分岐命令。
-
データフローの再配置: 静的なメモリ位置を参照する命令。
これら 3 つのカテゴリを使用したコアロジックは、次の 2 つのフェーズに要約されます。
1. ディスプレースメント フィックスアップの解決
-
即値オペランドとしてエンコードされたディスプレースメント(分岐命令)と、メモリ オペランドに含まれるディスプレースメント(データアクセスとインポート呼び出し)を区別します。
-
前に生成した
d.global_relocsマップを使用して、これらのディスプレースメントに対する正しいフィックスアップ値を計算します。
2. 出力イメージ バッファの更新
-
ディスプレースメントが解決されたら、更新後の命令のバイト数を新しいコード セグメントに書き込んで、変更を恒久的に反映させます。
このロジックを実現するために、複数のヘルパー関数とラムダ式を使用しています。以下に示されているコードに、フィックスアップを計算して命令のバイト数を更新する方法が順を追って説明されています。
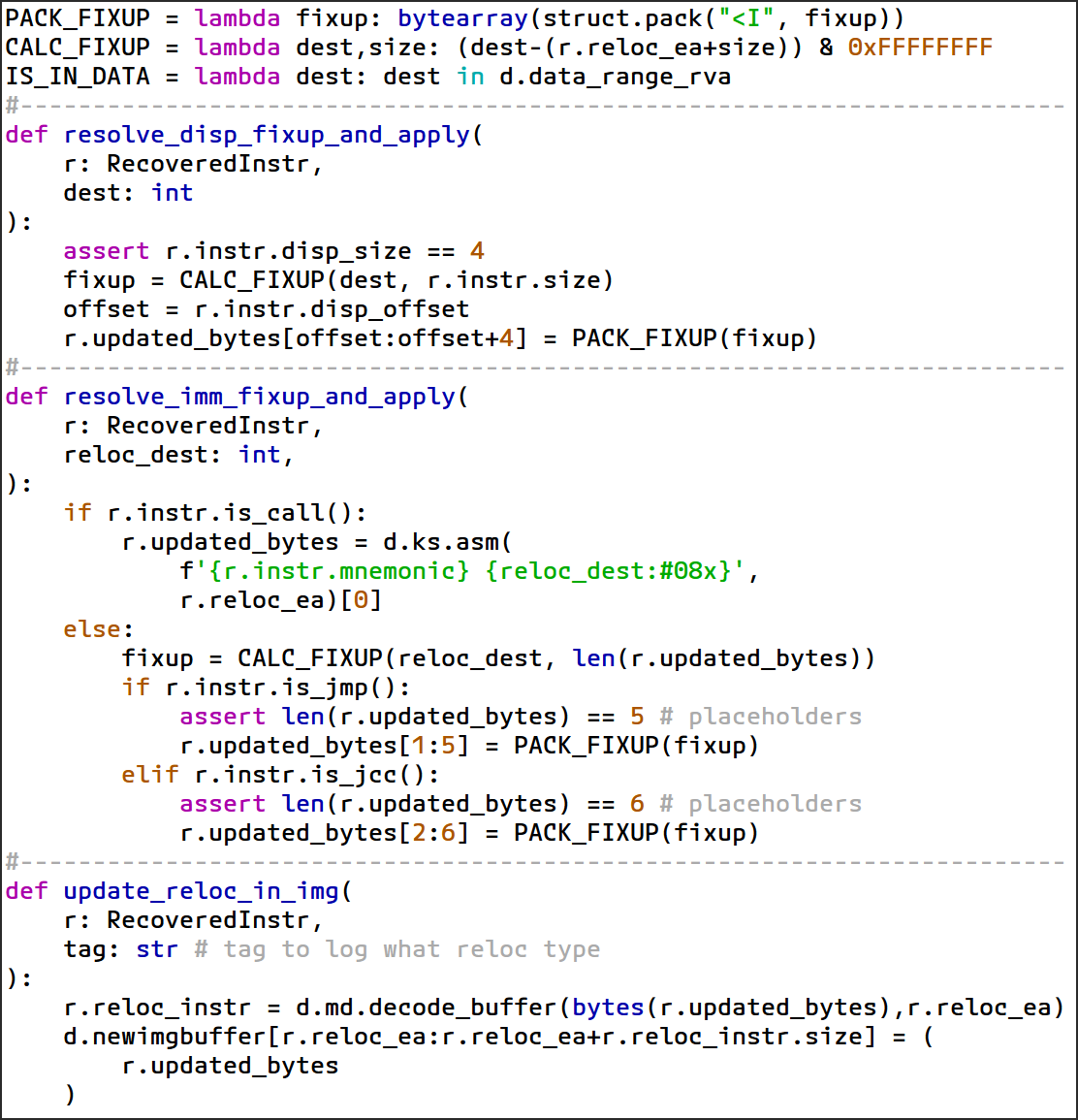
図 63: フィックスアップの適用を支援するヘルパー ルーチン
-
ラムダヘルパー式を定義する
-
PACK_FIXUP: 32 ビットのフィックスアップ値をリトル エンディアン バイト配列にパッキングします。 -
CALC_FIXUP: 宛先アドレス(dest)と現在の命令の終了位置(r.reloc_ea + size)の差を計算し、32 ビットに収まるようにフィックスアップ値を計算します。 -
IS_IN_DATA: 所定のアドレスがバイナリのデータ セクション内にあるかどうかをチェックします。データ セクションは元の位置に維持するため、これに該当するアドレスの再配置を除外します。 -
命令ごとのフィックスアップを解決する
-
インポートとデータフローの再配置
-
resolve_disp_fixup_and_applyヘルパー関数を、エンコードとしても、メモリ オペランド内のディスプレースメントとしても使用します。 -
制御フローの再配置
-
resolve_imm_fixup_and_applyヘルパーを、即値オペランドにエンコードされたディスプレースメントとして使用します。 -
CFG 復元の際に、1 バイトの短い分岐の欠点を回避するために、それぞれの
jmp命令とjcc命令を near jmp に相当するものに変換しました(2 バイトから 6 バイトに変換)。 -
すべてのフィックスアップに十分な範囲を確保するために、各分岐に 32 ビットのディスプレースメントを強制します。
-
出力イメージ バッファを更新する
-
更新後の命令のバイト数をデコードして、その命令を表す
RecoveredInstr内で更新を反映させます。 -
更新後のバイト数を新しいイメージ バッファに書き込みます。
-
updated_bytesが、完全に再配置された命令の最終的なオペコードを反映します。
これらのヘルパーを揃えた以下の Python コードが、各再配置タイプの最終的な処理を実装します。

図 64: 各再配置カテゴリに対処する 3 つのコアループ
-
インポートの再配置: 最初の for ループで、インポートの復元フェーズで生成されたデータを使用して、インポートの再配置のフィックスアップを処理します。
rfn.relocs_importsキャッシュ内の復元された命令 r のそれぞれを反復処理し、次のアクションを実行します。 -
更新後の命令のバイト数を準備する: 元の命令のバイト数の可変コピーで
r.updated_bytesを初期化して、修正で使用するバイト数を準備します。 -
インポート エントリとディスプレースメントを取得する: インポート ディクショナリ
d.importsからインポート エントリを取得し、インポートの API 名を使用してd.import_to_rva_mapから新しい RVA を取得します。 -
フィックスアップを適用する:
resolve_disp_fixup_and_applyヘルパーを使用して、新しい RVA のフィックスアップを計算し、適用します。これにより、命令のディスプレースメントを調整して、インポートされる関数を正しく参照するようにします。 -
イメージ バッファを更新する:
update_reloc_in_imgを使用して、r.updated_bytesを新しいイメージに書き込みます。これで、出力イメージ内の命令のフィックスアップが終了します。 -
制御フローの再配置: 2 つ目の for ループは、制御フロー分岐の再配置(
call、jmp、jcc)のフィックスアップを処理します。rfn.relocs_ctrlflow内の各エントリを反復処理して、次のアクションを実行します。 -
宛先を取得する: 元の分岐の宛先ターゲットを即値オペランドから取得します。
-
再配置後のアドレスを取得する: 再配置ディクショナリ
d.global_relocsを参照して、分岐ターゲットの再配置後のアドレスを取得します。呼び出しターゲットの場合は、具体的には呼び出される関数の開始位置に対応する再配置後のアドレスを検索します。 -
フィックスアップを適用する:
resolve_imm_fixup_and_applyを使用して、分岐ターゲットをその再配置後のアドレスに調整します。 -
バッファを更新する:
update_reloc_in_imgを使用してr.updated_bytesを新しいイメージに書き込み、フィックスアップを終了します。 -
データフローの再配置: 最後のループは、
rfn.relocs_dataflow内に保存されているすべての静的メモリ参照の解決を処理します。まず、データ参照の再配置が必要となるKNOWN命令のリストを作成します。該当する命令は多岐にわたるため、前述の分類でアプローチを簡素化し、保護されたバイナリに存在する可能性があるすべての命令を包括的に理解できるようにします。続いて、ロジックでインポートと制御フローの再配置のロジックをミラーリングし、該当する命令のそれぞれを体系的に処理して、各命令のメモリ参照を正確に調整します。
コード セクションを再構築して再配置マップを作成したら、難読化解除されたバイナリ内の再配置用に分類された各命令を調整します。これが、出力バイナリの完全な機能を復元する際の最終ステップです。このステップによって、各命令が意図されたコードまたはデータ セグメントを正しく参照するようになりました。
結果の確認
ScatterBrain の難読化解除ライブラリのデモを行うために、このライブラリの機能を紹介する試験的調査を実施します。この試験的調査では 3 つのサンプルとして、POISONPLUG.SHADOW ヘッダーレス バックドアと 2 つの組み込みプラグインを選択します。
難読化解除ライブラリを使用し、これまで説明した復元手法のすべてを実装する example_deobfuscator.py という Python スクリプトを開発しました。図 65 と図 66 では、サンプルの難読化解除ツールに含まれるコードを紹介しています。

図 65: example_deobfuscator.py 内の Python コードの前半

図 66: example_deobfuscator.py 内の Python コードの後半
example_deobfuscator.py を実行すると、以下の出力が表示されます。このコードでは、ヘッダーレス バックドア内で検出された 16,000 超の命令ディスパッチャーをエミュレートしなければならないため、多少時間がかかります。
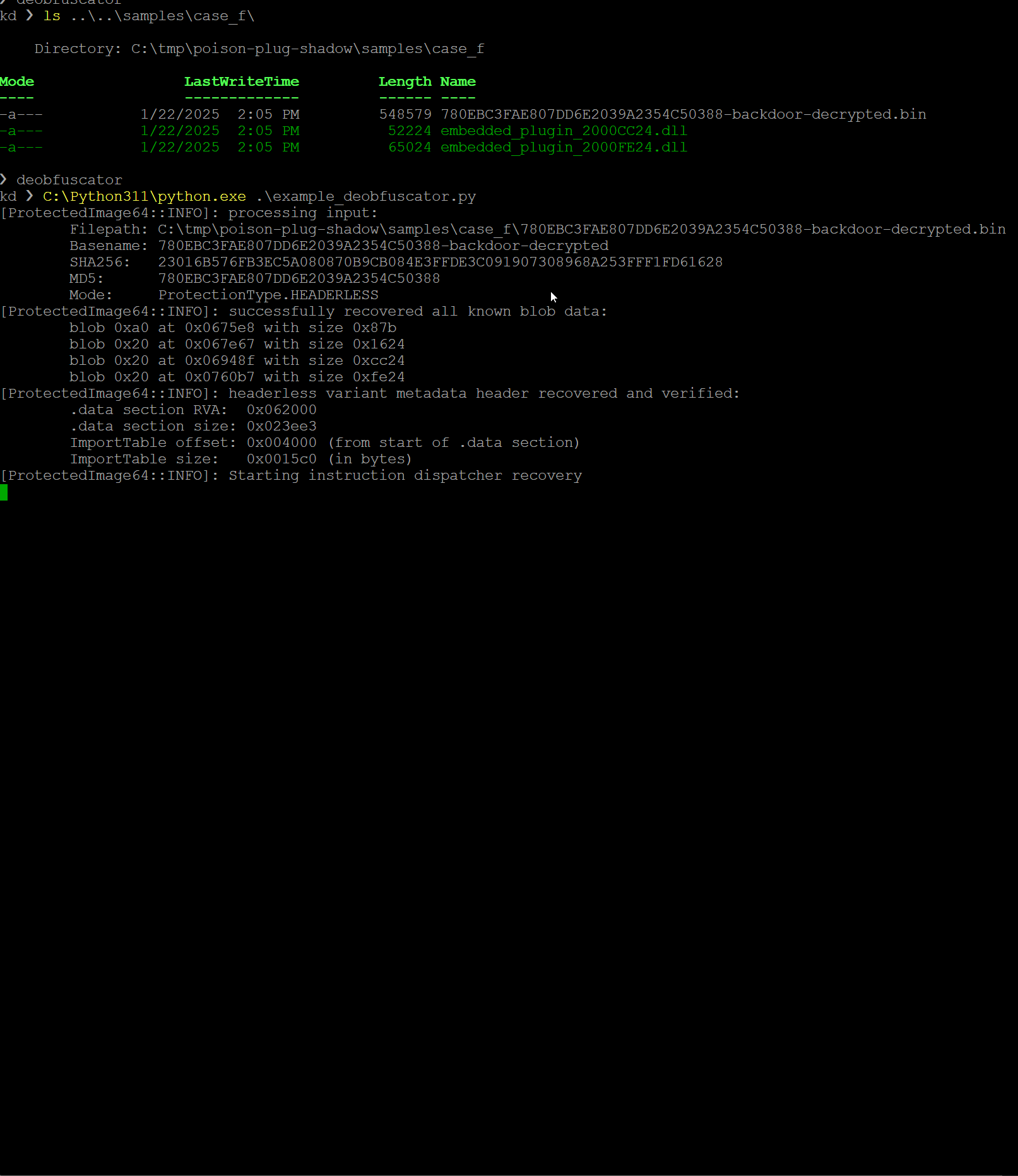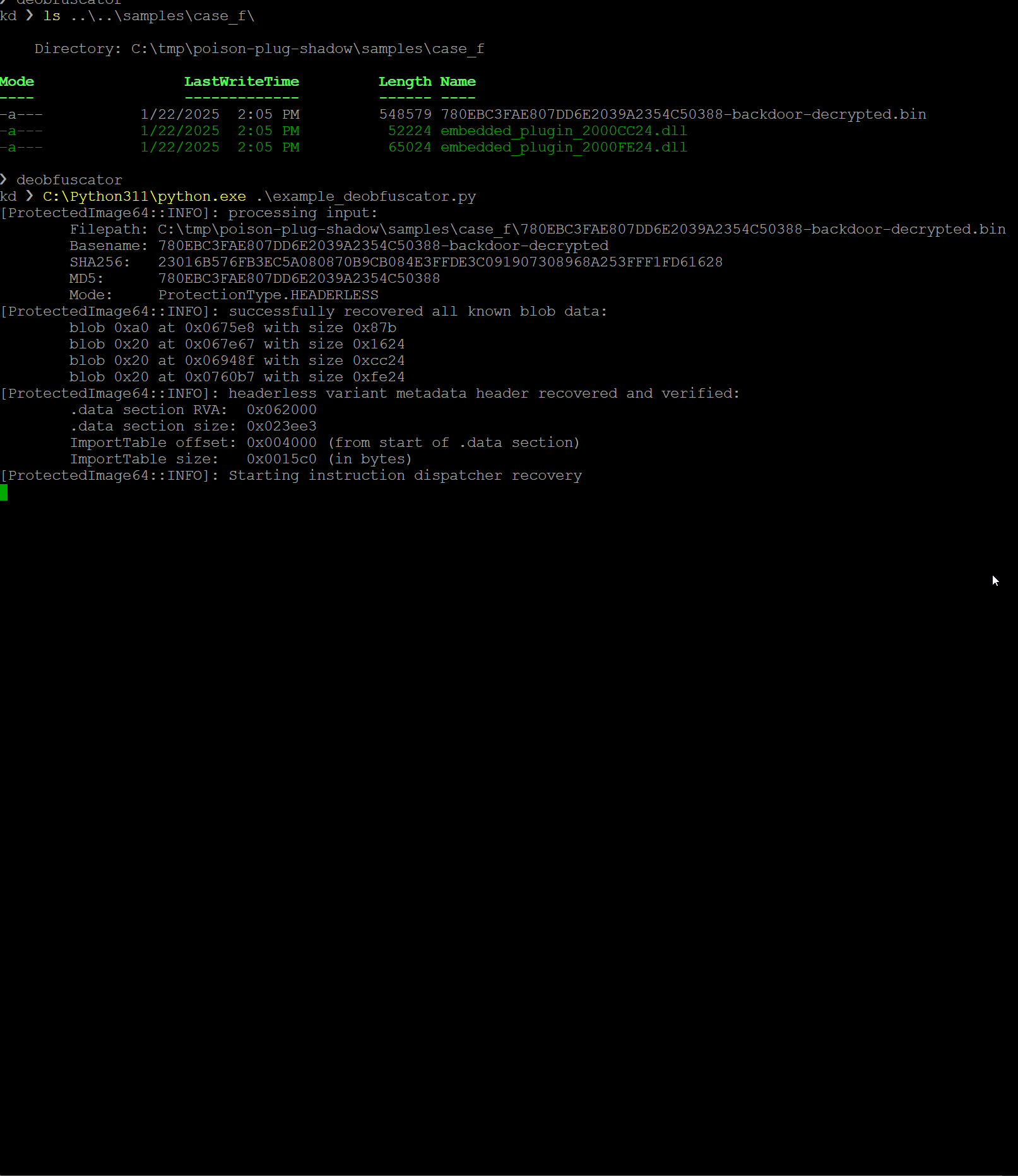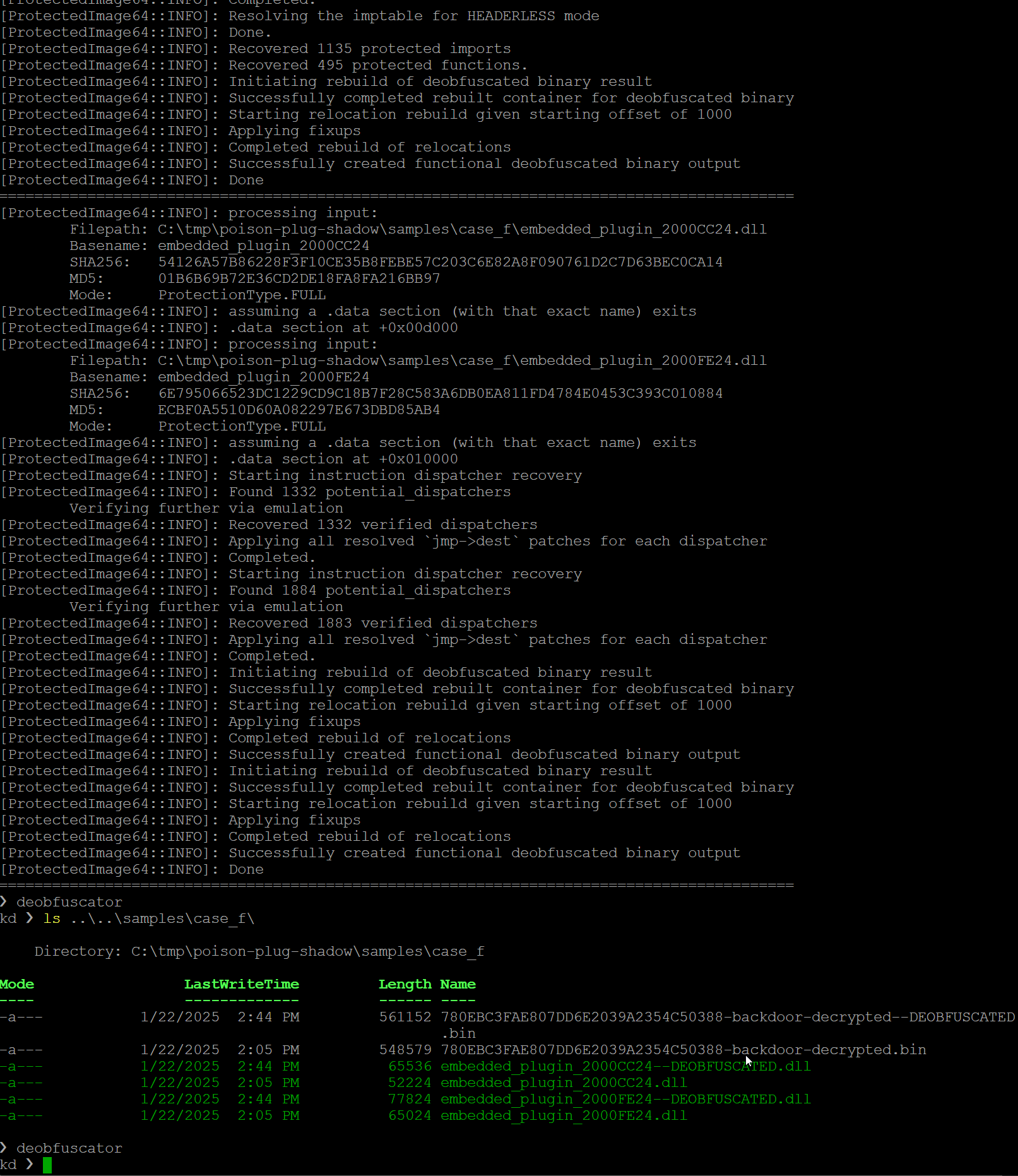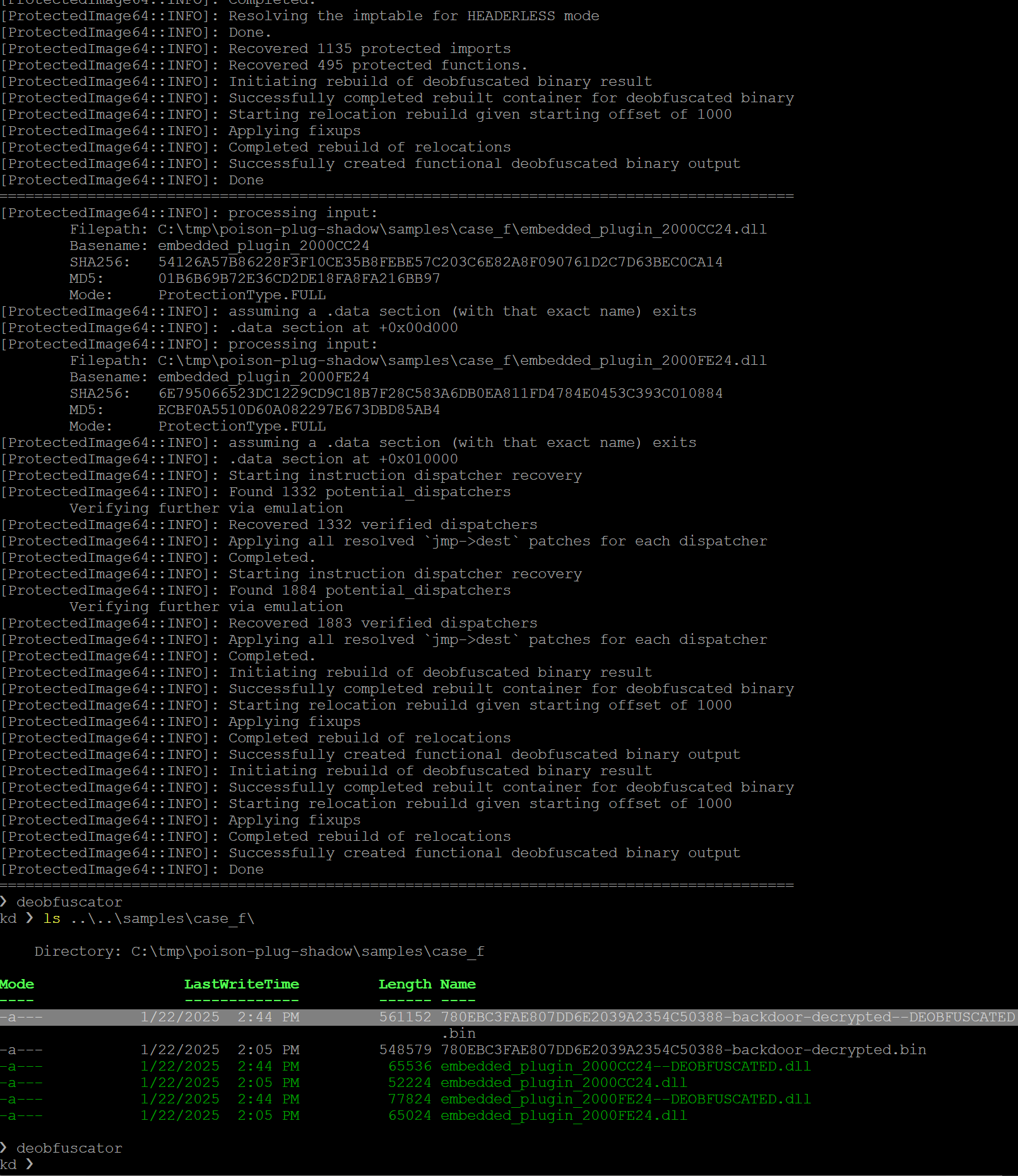
図 67: 各再配置カテゴリに対処する 3 つのコアループ
簡潔にするため、ここでは最も高度な難読化解除が必要なヘッダーレス バックドアに焦点を絞ります。まず、その初期状態を IDA Pro 逆アセンブラで観察してから、難読化解除ツールによる出力結果を調べます。分析をほぼ完全にブロックしていることがわかります。
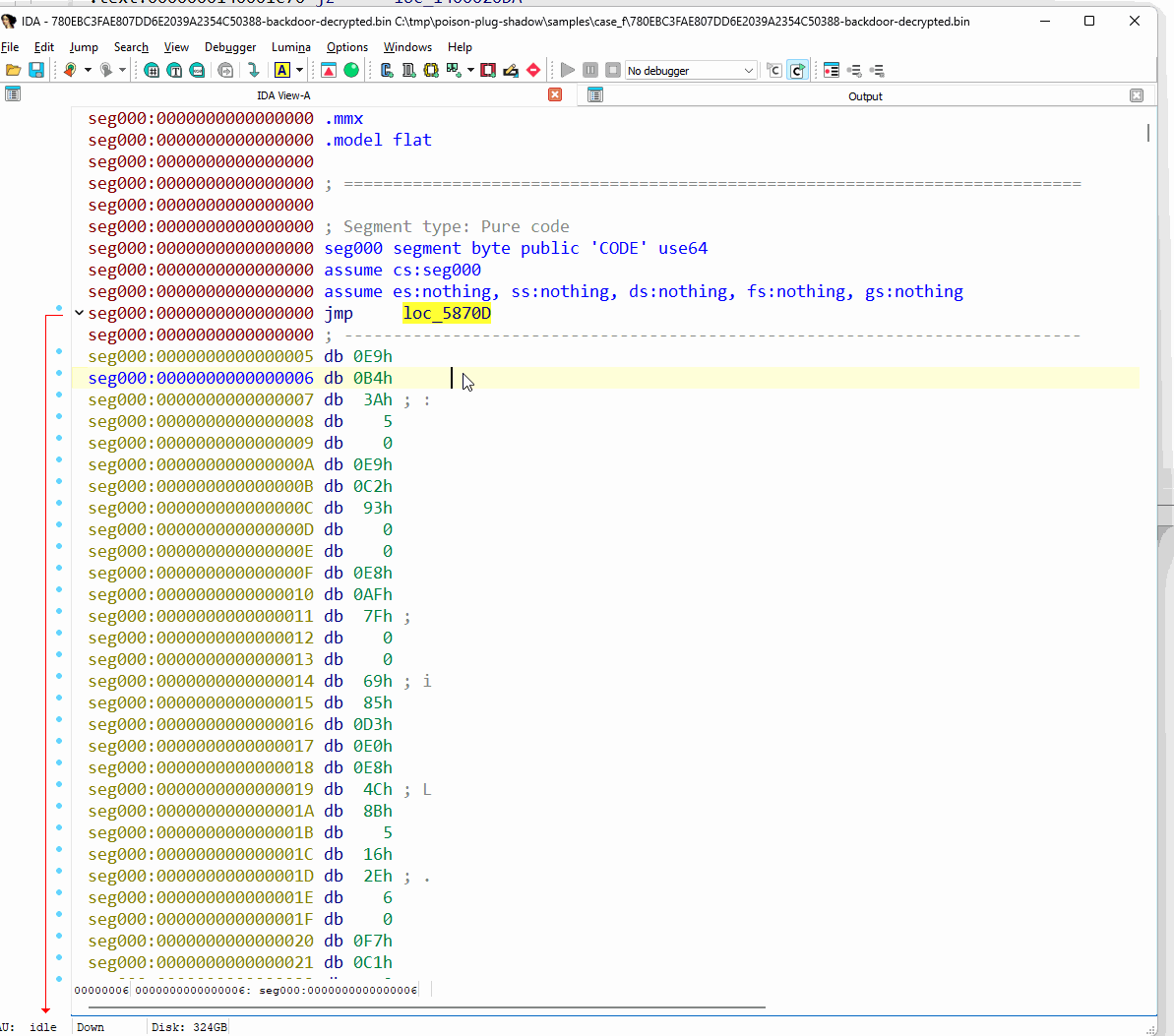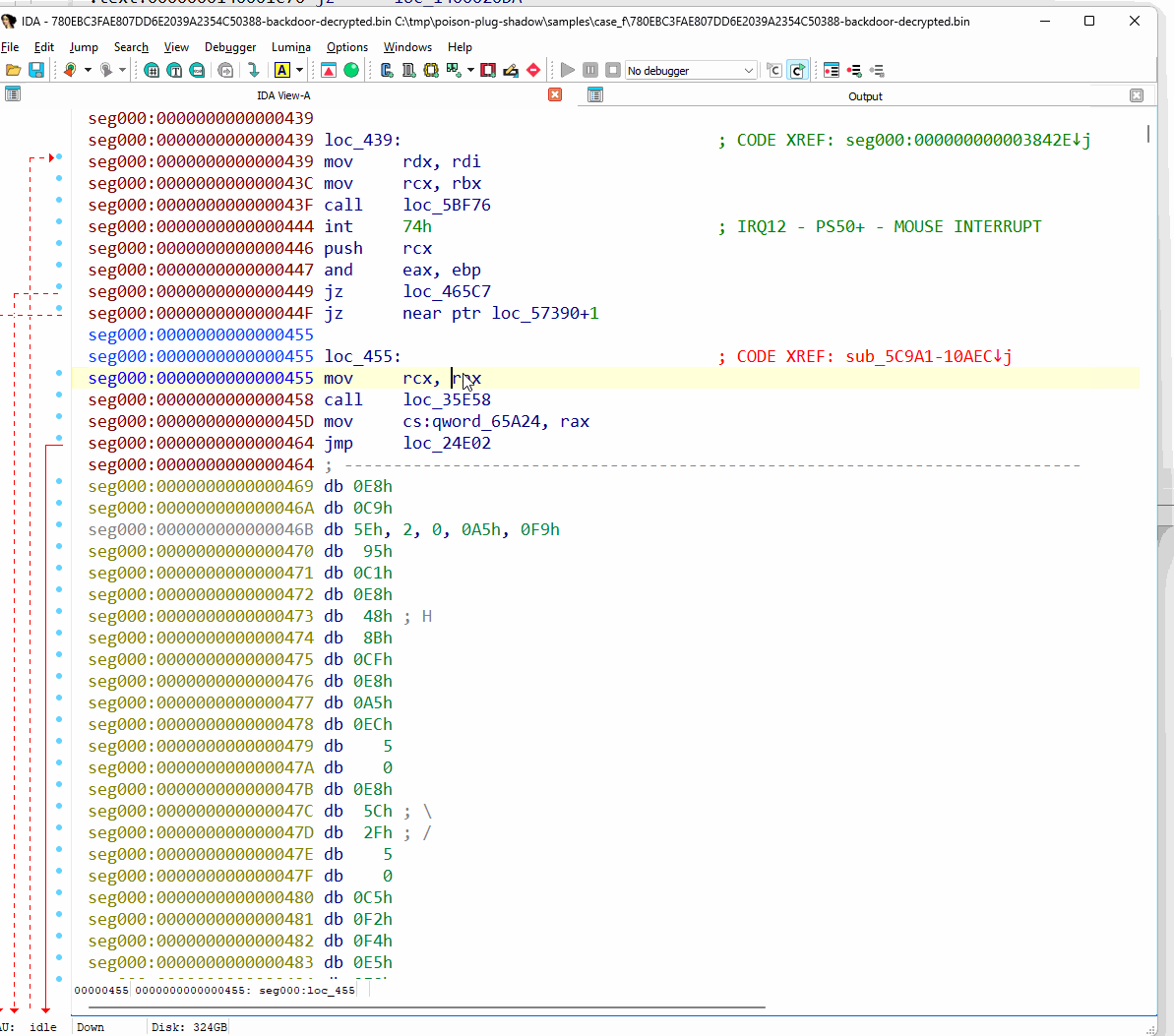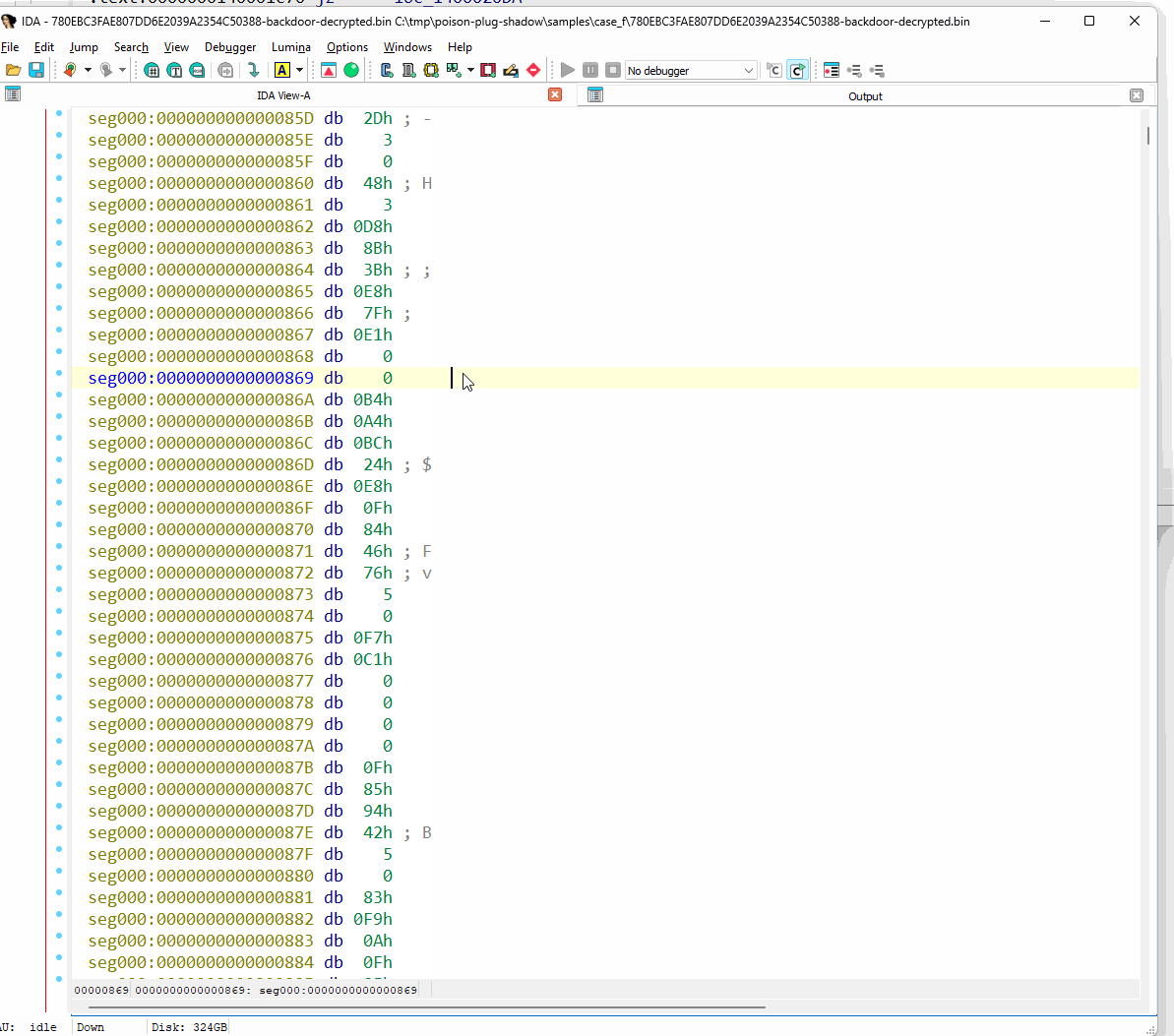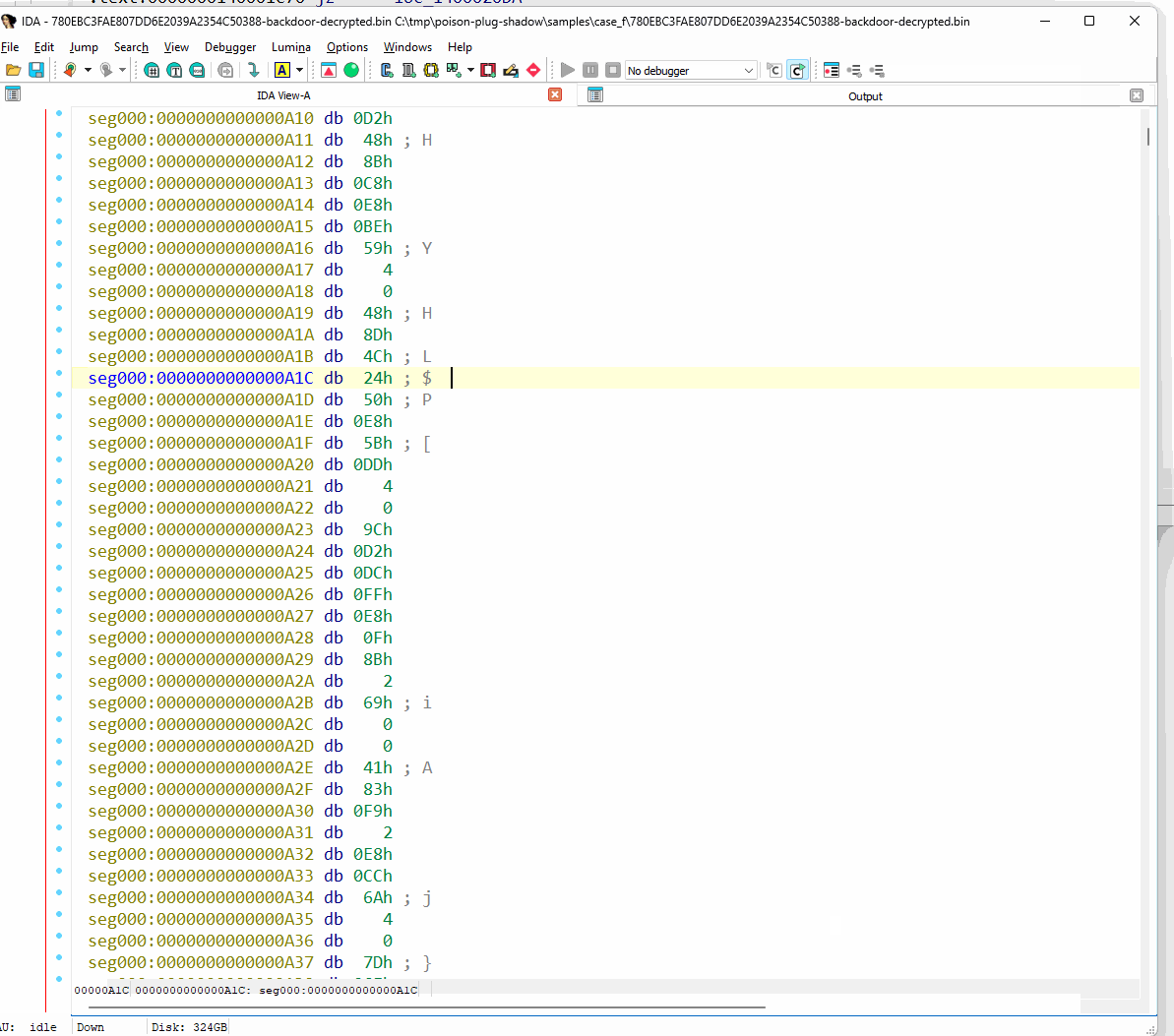
図 68: IDA Pro における難読化されたヘッダーレス バックドアの確認
Google のサンプル難読化解除ツールを実行し、難読化解除されたまったく新しいバイナリを生成すると、出力が劇的に変わります。元の制御フロー全体が復元され、保護されたすべてのインポートも復元されて、必要なすべての再配置が適用されています。また、ScatterBrain によって意図的に削除されるヘッダーレス バックドアの PE ヘッダーも考慮されています。
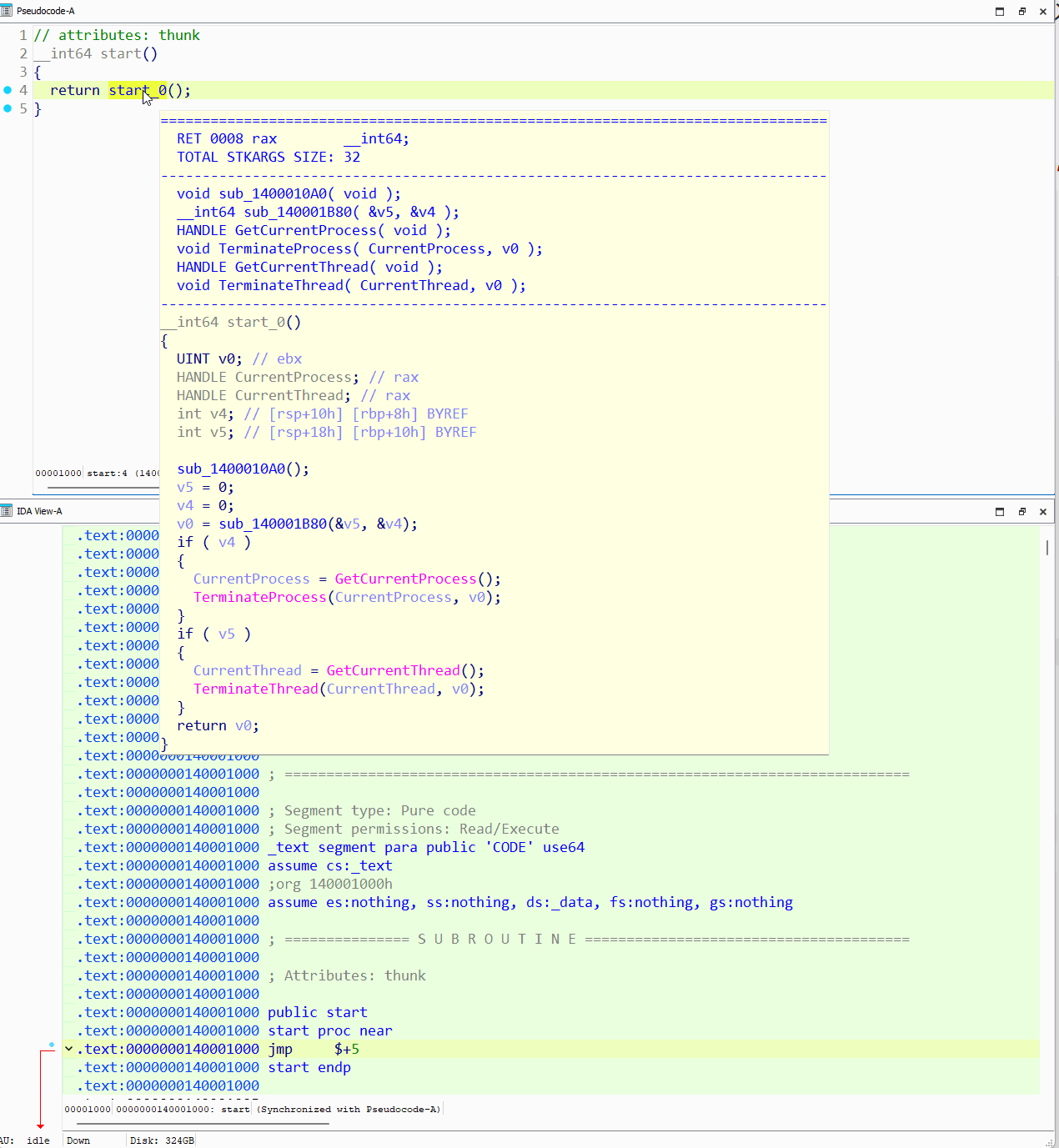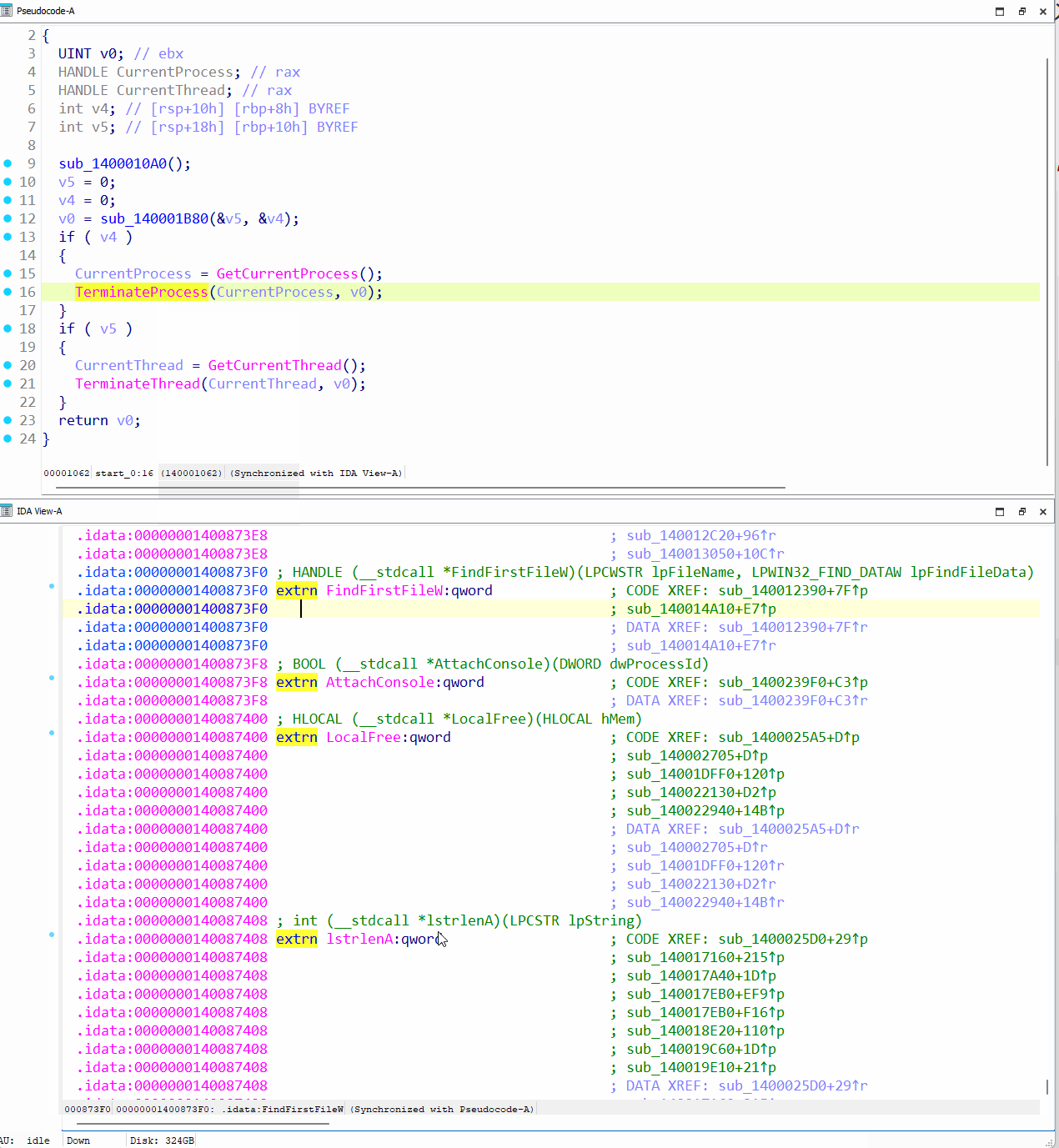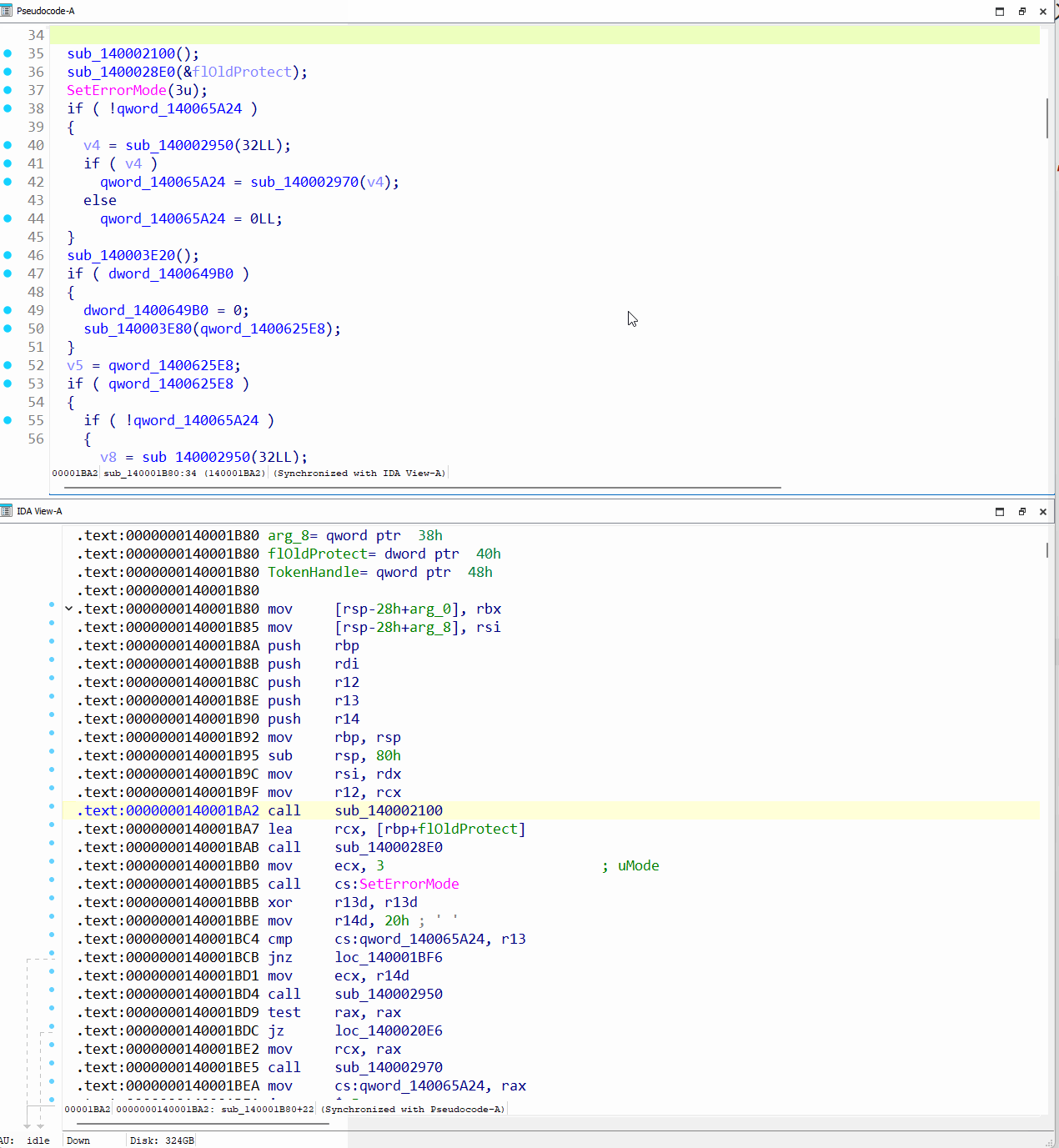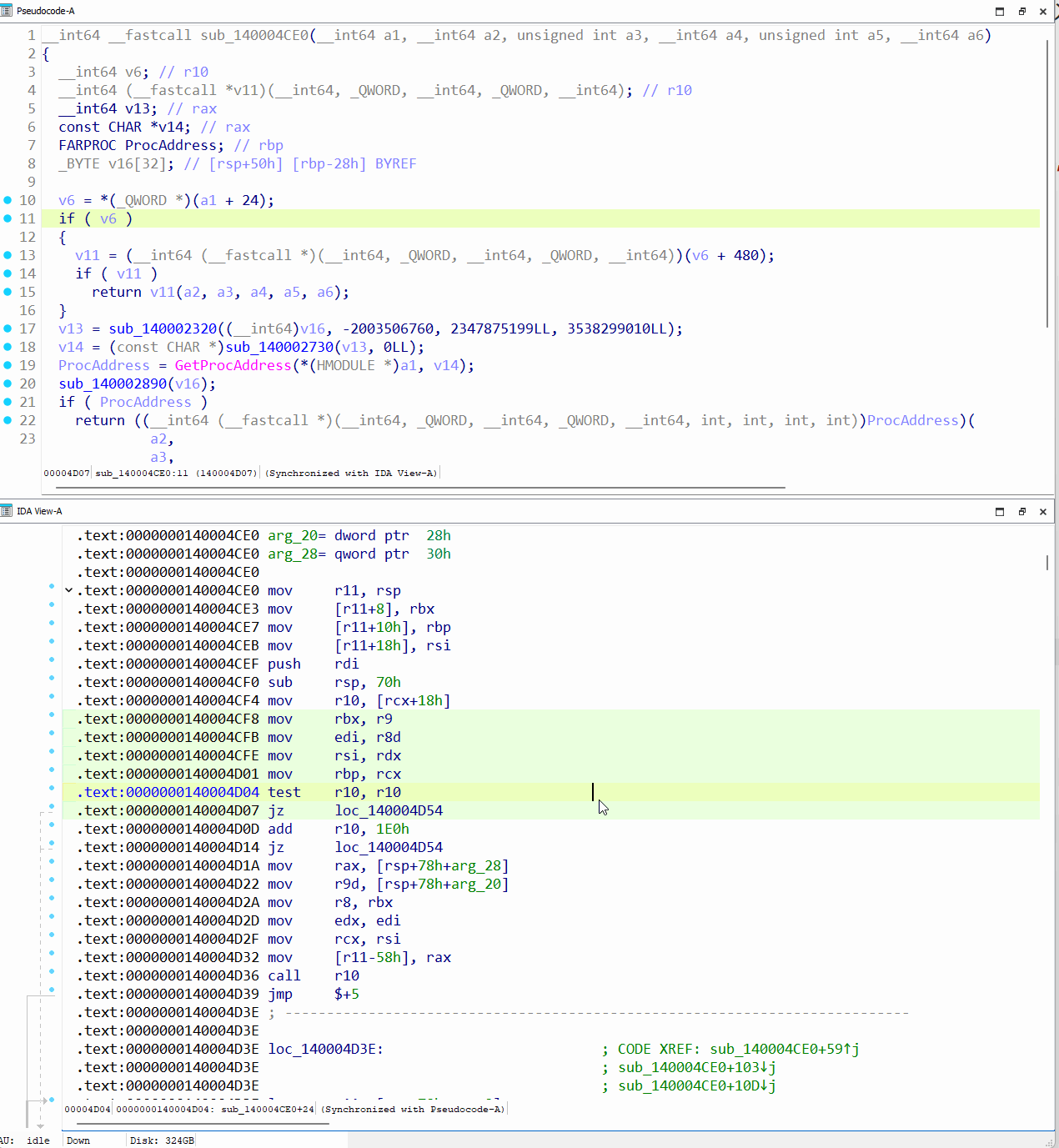
図 69: IDA Pro における難読化解除されたヘッダーレス バックドアの確認
機能するバイナリが出力の一部として生成されるため、以降に難読化解除されたバイナリは、直接実行することも、使い慣れたデバッガ内でデバッグすることもできます。
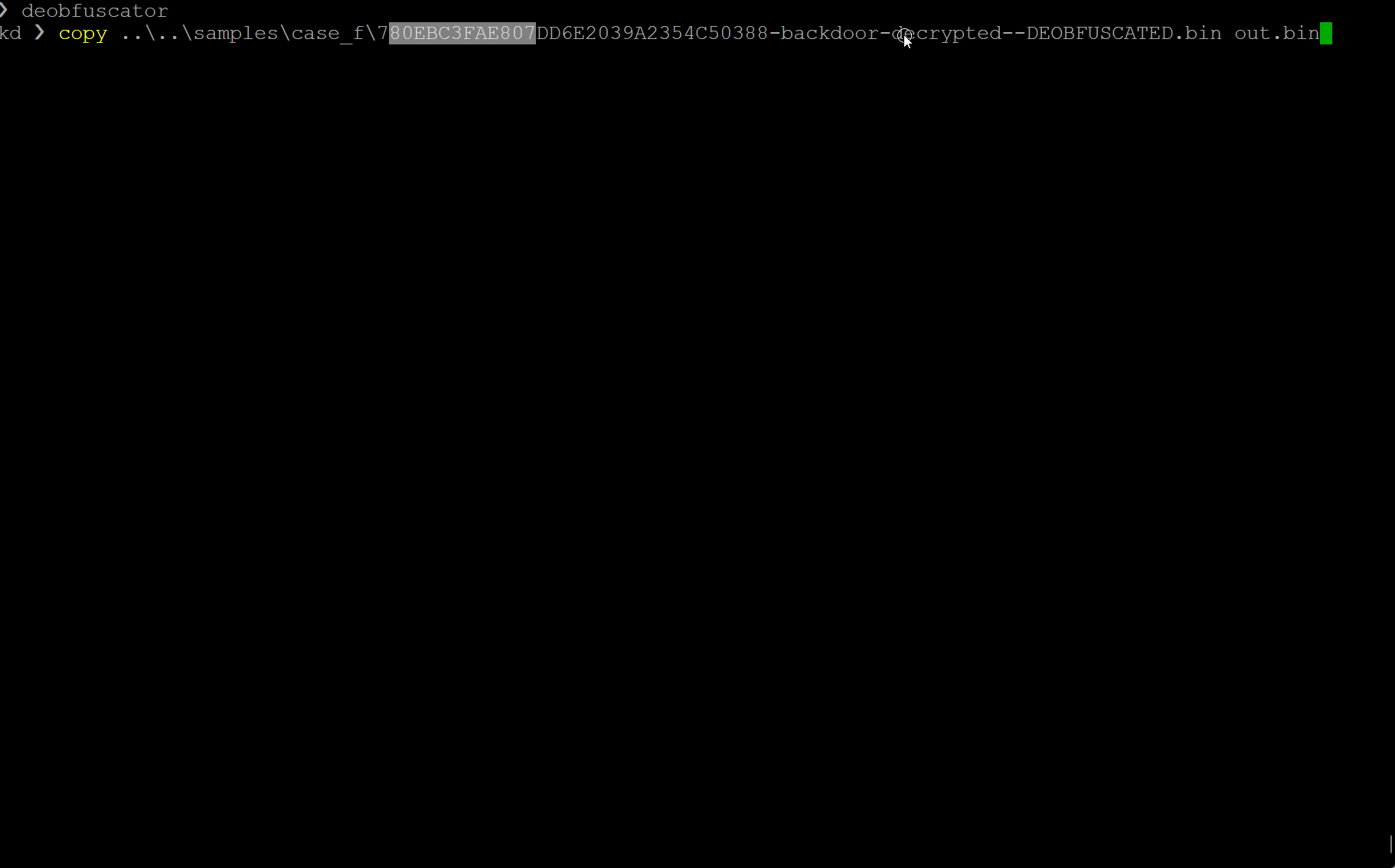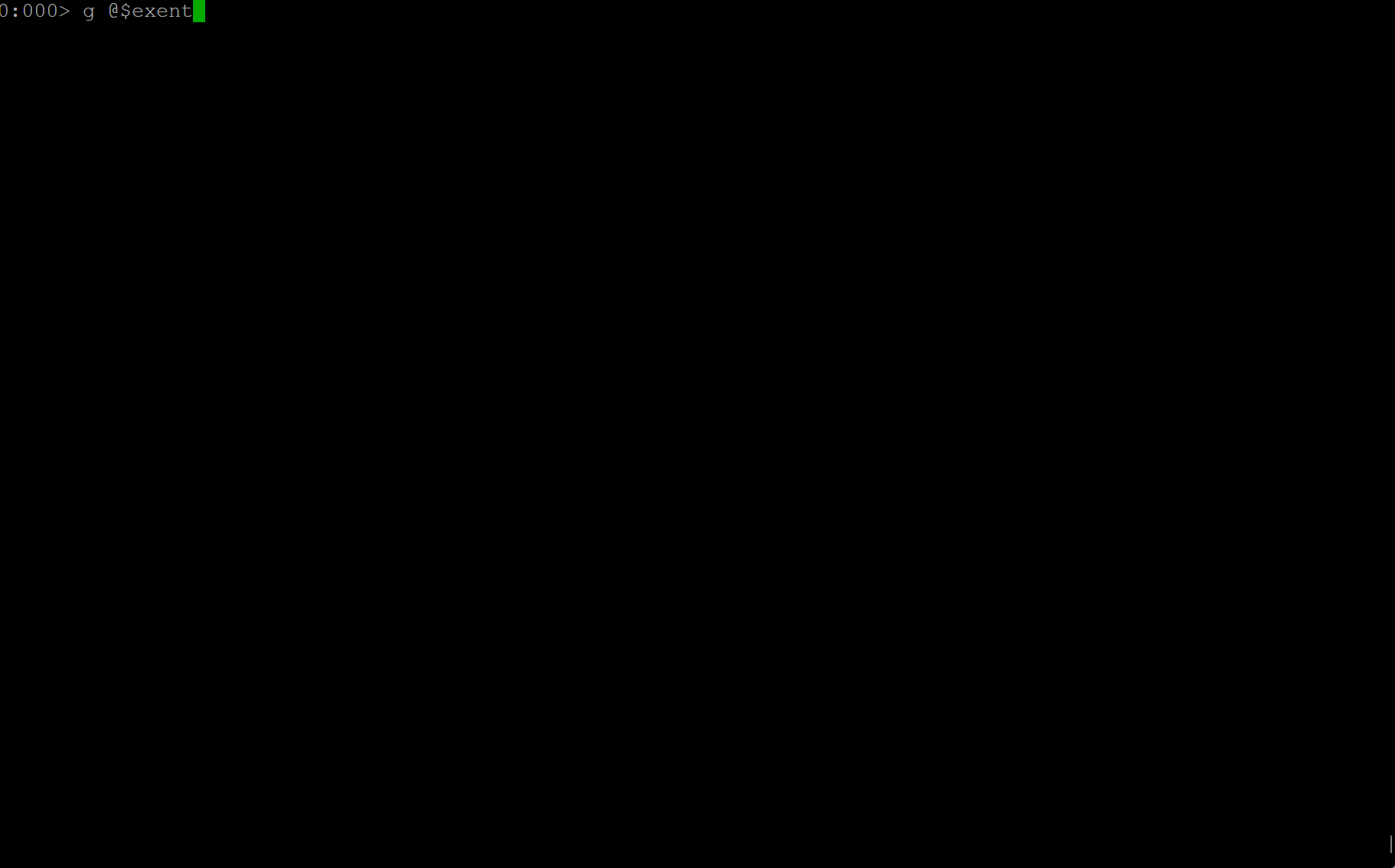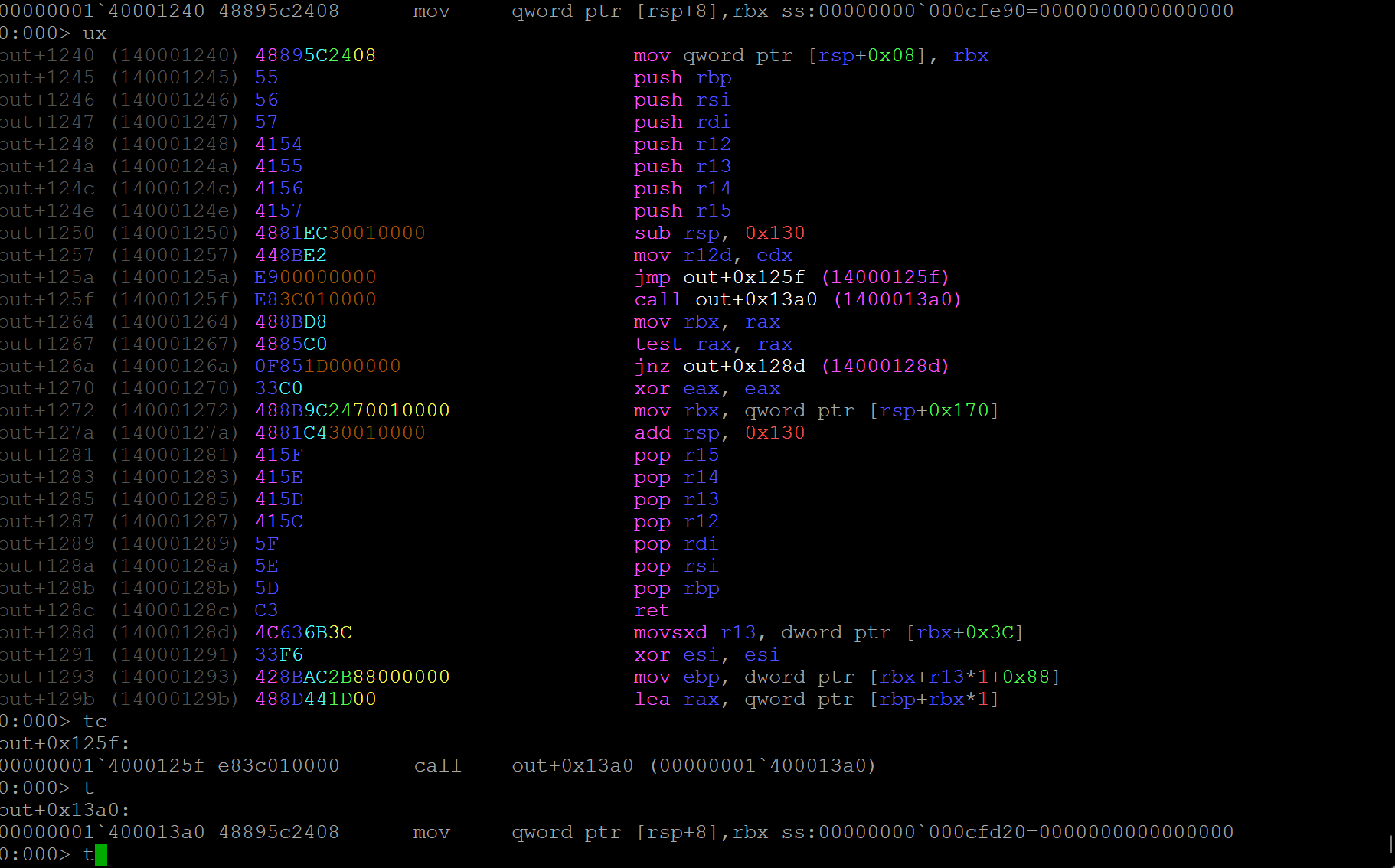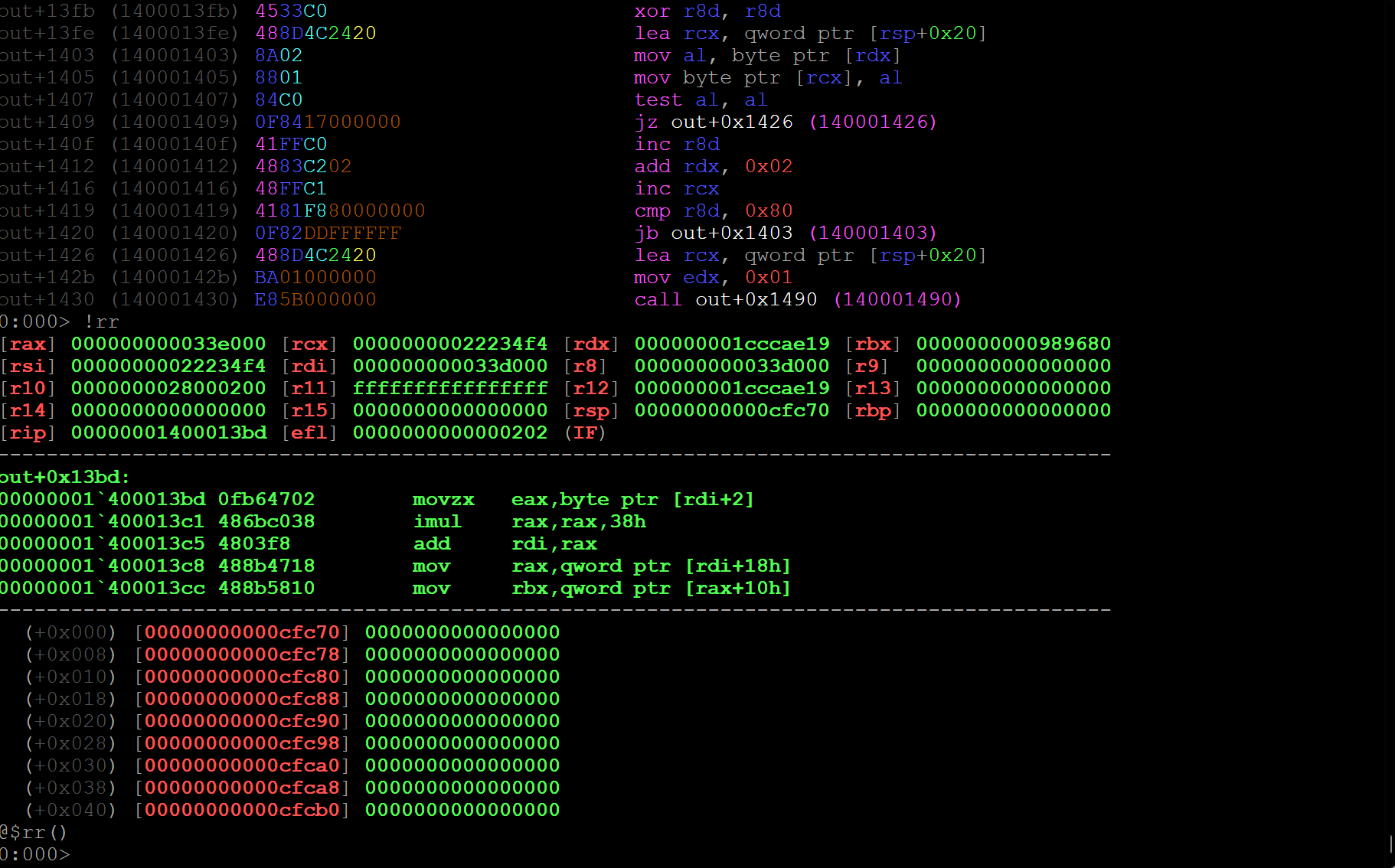
図 70: 使い慣れたデバッガ内での難読化解除されたヘッダーレス バックドアのデバッグ
まとめ
このブログ投稿では、POISONPLUG.SHADOW で使用されている高度な ScatterBrain 難読化コンパイラについて詳しく説明しました。POISONPLUG.SHADOW は、中国との関連が疑われる特定の脅威アクターが使っている高度なモジュール型バックドアであり、GTIG はこれを 2022 年から追跡しています。ScatterBrain の調査では、この難読化コンパイラが防御者に突きつける課題の複雑さが明らかになりました。それぞれの保護メカニズムを体系的に取り上げて対処することで、効果的な難読化解除ソリューションを作成するには大規模な取り組みが必要になることを説明しました。
この取り組みによって、最終的にアナリストとサイバーセキュリティの専門家の皆様に貴重な分析情報と実用的なツールを提供できることを願っています。Google では、さまざまな手法の進化と共同イノベーションの推進に尽力し、今後も最前線に立って POISONPLUG.SHADOW のような高度な脅威に対抗していきます。今回の包括的な調査と難読化解除ツールの紹介を通して、高度に難読化されたマルウェアがもたらすリスクを軽減し、進化し続ける敵対的な戦術に対するサイバーセキュリティ防御のレジリエンスを強化するための継続的な取り組みに貢献していきます。
セキュリティ侵害インジケーター
この投稿で説明した活動に関連するセキュリティ侵害インジケーター(IoC)を備えた Google Threat Intelligence コレクションをご利用いただけるようになりました。
ホストベースの IoC
謝辞
POISONPLUG の脅威を理解してこれに対抗するための Mandiant と Google 双方の取り組みに貢献してくれた、Google Threat Intelligence グループの Conor Quigley と Luke Jenkins に深く感謝します。また、Google のさまざまなチームの継続的なサポートと献身にも感謝の言葉を述べたいと思います。チームの総力を結集した取り組みは、高度な攻撃者に対するサイバー セキュリティ防御を強化するうえで不可欠なものとなっています。
- Mandiant、執筆者: Nino Isakovic
