GoStringUngarbler: garble で難読化されたバイナリ内の文字列の難読化解除
Mandiant
※この投稿は米国時間 2025 年 3 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
概要
FLARE チームは日々の業務において、Go で記述されており、garble を使用して保護されたマルウェアによく遭遇します。近年、IDA Pro などのツールによる Go の分析が進歩したことで分析プロセスは簡素化されたものの、garble には、バイナリのストリッピング、関数名のマングリング、文字列の暗号化など、独自の課題が存在します。
garble の文字列暗号化は比較的単純ですが、静的分析を大きく妨げます。このブログ投稿では、garble の文字列変換と、それらを自動的に難読化解除するプロセスについて詳しく説明します。
また、GoStringUngarbler についても紹介します。これは、Python で記述されたコマンドライン ツールで、garble により難読化された Go バイナリで見つかった文字列を自動的に復号します。このツールは、すべての文字列が復元され書式なしテキストで表示される難読化解除されたバイナリを生成することで、リバース エンジニアリング プロセスを合理化し、静的分析、マルウェア検出、分類を簡素化できます。
garble 難読化コンパイラ
GoStringUngarbler ツールについて詳しく説明する前に、garble コンパイラが Go バイナリのビルドプロセスをどのように変更するのかを簡単に説明したいと思います。garble は、公式の Go コンパイラをラップすることで、Go の go/ast ライブラリを使用して抽象構文ツリー(AST)を操作し、コンパイル時にソースコードの変換を行います。ここでは、難読化コンパイラがプログラム要素を変更して生成されたバイナリを難読化しますが、プログラムのセマンティックな整合性は維持されます。garble により変換されたプログラムの AST は、Go コンパイル パイプラインにフィードバックされ、リバース エンジニアリングや静的分析がより困難な実行可能ファイルが生成されます。
garble はソースコードにさまざまな変換を適用できますが、このブログ投稿では「リテラル」変換に焦点を当てます。garble を -literals フラグで実行すると、ソースコードとインポートされた Go ライブラリのすべてのリテラル文字列が難読化された形式に変換されます。各文字列はエンコードされ、復号関数でラップされるため、静的な文字列分析を妨害します。
各文字列に対して、難読化コンパイラは次のリテラル変換のいずれかをランダムに適用します。以降のセクションでは、それぞれについて詳しく説明します。
-
スタック変換: この方法では、スタックに直接保存される文字列にランタイム エンコードを実装します。
-
シード変換: この方法では、シード値が暗号化されたバイトごとに進化する動的シードベースの暗号化メカニズムを使用して、相互に依存する暗号化オペレーションのチェーンを作成します。
-
分割変換: この方法では、暗号化された文字列が複数のチャンクに分割され、メインの switch 文のブロック内でそれぞれ個別に復号されます。
スタック変換
garble のスタック変換では、シンプル、スワップ、シャッフルという 3 つの異なる変換タイプを使用してスタック上で直接動作するランタイム暗号化手法を実装します。これらの名前は、garble のソースコードから直接取得されます。これらは 3 つともスタックにある文字列で暗号オペレーションを実行しますが、それぞれ複雑さやデータ操作へのアプローチが異なります。
-
シンプル変換: この変換では、ランダムに生成された数学演算子と、入力文字列と同じ長さのランダムに生成された鍵を使用して、バイト単位のエンコードを適用します。
-
スワップ変換: この変換では、バイトペアのスワッピングと位置依存のエンコードを組み合わせて適用します。バイトペアはシャッフルされ、動的に生成されたローカル鍵を使用して暗号化されます。
-
シャッフル変換: この変換では、ランダム鍵でデータをエンコードし、暗号化されたデータとその鍵をインターリーブします。そして XOR ベースのインデックス マッピングで順列を適用し、暗号化されたデータと鍵を最終出力全体に分散させることで、複数レイヤの暗号化を適用します。
シンプル変換
この変換は、AST レベルで単純なバイトレベルのエンコード スキームを実装します。以下は、garble リポジトリの実装を示しています。図 1 と、以降の garble リポジトリから取得したコードサンプルでは、読みやすくするために著者によるコメントを追加しています。
// 入力文字列と同じ長さのランダム鍵を生成する
key := make([]byte, len(data))
// 鍵をランダムバイトで埋める
obfRand.Read(key)
// 暗号化に使用する演算子(XOR、ADD、SUB)をランダムに選択する
op := randOperator(obfRand)
// ランダム演算子を使用して、データの各バイトを鍵で暗号化する
for i, b := range key {
data[i] = evalOperator(op, data[i], b)
}図 1: シンプル変換の実装
難読化コンパイラは、まず入力文字列と同じ長さのランダムな鍵を生成します。次に、エンコード処理全体で使用される可逆算術演算子(XOR、加算、減算)をランダムに選択します。
データと鍵のバイトを同時に反復処理し、選択した演算子を対応する各ペアの間に適用してエンコードされた出力を生成することで、難読化が実行されます。
図 2 は、この変換タイプの復号サブルーチンを IDA で逆コンパイルしたコードを示しています。
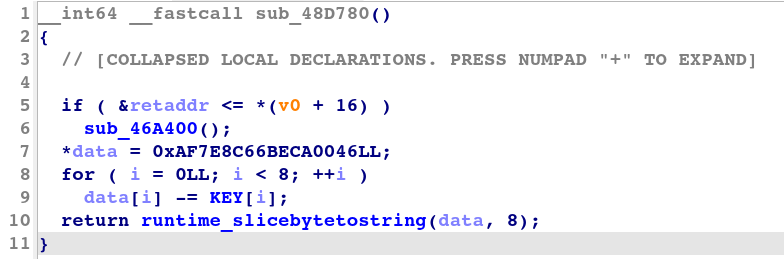
図 2: シンプル変換における復号サブルーチンの逆コンパイルされたコード
スワップ変換
スワップ変換では、バイトシャッフルと暗号化アルゴリズムを使用して文字列リテラルを暗号化します。図 3 は、garble リポジトリの実装を示しています。
// データの長さに基づいて実行するスワップ オペレーションの回数を決定する
func generateSwapCount(obfRand *mathrand.Rand, dataLen int) int {
// データの長さと同じ数のスワップ数から開始する
swapCount := dataLen
// 追加スワップの最大値を計算する(データの長さの半分)
maxExtraPositions := dataLen / 2
// 位置を追加できる場合は任意の値を追加する
if maxExtraPositions > 1 {
swapCount += obfRand.Intn(maxExtraPositions)
}
// 奇数の場合はインクリメントしてスワップ数が偶数になるようにする
if swapCount%2 != 0 {
swapCount++
}
return swapCount
}
func (swap) obfuscate(obfRand *mathrand.Rand, data []byte)
*ast.BlockStmt {
// 実行するスワップ オペレーションの回数を生成する
swapCount := generateSwapCount(obfRand, len(data))
// シフト鍵をランダムに生成する
shiftKey := byte(obfRand.Uint32())
// 暗号化に使用する可逆演算子をランダムに選択する
op := randOperator(obfRand)
// バイトをスワップするためのランダムな位置のリストを生成する
positions := genRandIntSlice(obfRand, len(data), swapCount)
// 位置のペアを逆順に処理する
for i := len(positions) - 2; i >= 0; i -= 2 {
// 各ペアの位置に依存するローカル鍵を生成する
localKey := byte(i) + byte(positions[i]^positions[i+1]) + shiftKey
// スワップと暗号化を実行する:
// - positions[i] と positions[i+1] をスワップする
// - 各位置のバイトをローカル鍵で暗号化する
data[positions[i]], data[positions[i+1]] = evalOperator(op,
data[positions[i+1]], localKey), evalOperator(op, data[positions[i]],
localKey)
}
...
図 3: スワップ変換の実装
変換は、偶数個のランダムなスワップ位置を生成するところからスタートします。この位置は、データの長さとランダムな追加位置数(データの長さの半分まで)に基づいて決定されます。次に、コンパイラはこの長さのランダムなスワップ位置のリストをランダムに生成します。
難読化のコアプロセスは、位置のペアを逆順に反復処理し、各ペアに対してスワップ オペレーションと暗号化の両方を実行することで動作します。反復処理ごとに、反復処理インデックス、現在の位置ペアの XOR 結果、ランダムなシフト鍵を組み合わせて、位置に依存するローカル暗号鍵を生成します。このローカル鍵は、ランダムに選択された可逆演算子を使用して、スワップされたバイトを暗号化するために使用されます。
図 4 は、IDA によって生成された、スワップ変換の復号サブルーチンの逆コンパイルされたコードを示しています。
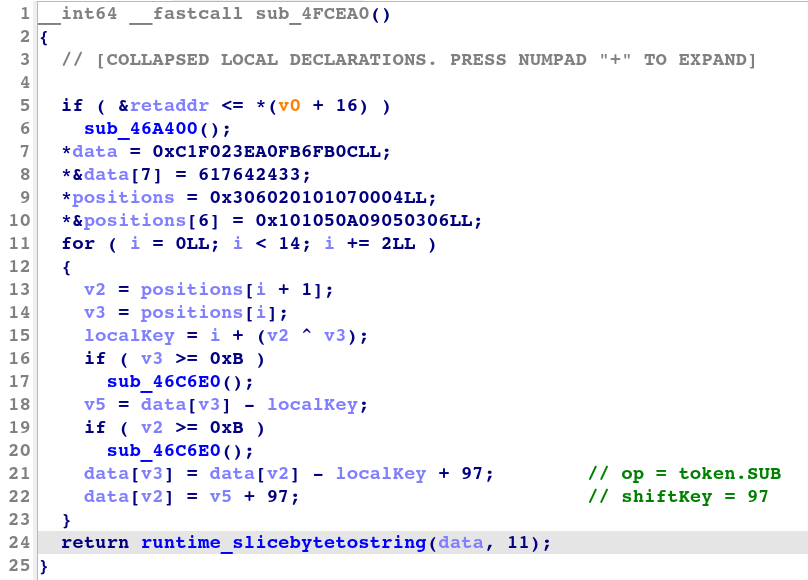
図 4: スワップ変換における復号サブルーチンの逆コンパイルされたコード
シャッフル変換
シャッフル変換は、3 つのスタック変換タイプの中で最も複雑です。ここで、garble は元の文字列をランダム鍵で暗号化し、その鍵で暗号化されたデータをインターリーブして、暗号化データと鍵を最終出力全体に分散させることで難読化を適用します。図 5 は、garble リポジトリの実装を示しています。
// 元の文字列と同じ長さのランダム鍵を生成する
key := make([]byte, len(data))
obfRand.Read(key)
// インデックス鍵のサイズ境界の定数
const (
minIdxKeySize = 2
maxIdxKeySize = 16
)
// インデックス鍵のサイズを最小値に初期化する
idxKeySize := minIdxKeySize
// 入力データの長さに応じてインデックス鍵のサイズが大きくなる可能性がある
if tmp := obfRand.Intn(len(data)); tmp > idxKeySize {
idxKeySize = tmp
}
// インデックス鍵のサイズの上限を指定する
if idxKeySize > maxIdxKeySize {
idxKeySize = maxIdxKeySize
}
// インデックス スクランブル用のセカンダリ鍵(インデックス鍵)を生成する
idxKey := make([]byte, idxKeySize)
obfRand.Read(idxKey)
// 暗号化されたデータと鍵の両方を保持するバッファを作成する
fullData := make([]byte, len(data)+len(key))
// 完全なデータバッファ内の各位置に対して演算子をランダムに生成する
operators := make([]token.Token, len(fullData))
for i := range operators {
operators[i] = randOperator(obfRand)
}
// データを暗号化し、対応する鍵で保存する
// 前半には暗号化されたデータ、後半には鍵が含まれる
for i, b := range key {
fullData[i]、fullData[i+len(data)] = evalOperator(operators[i],
data[i], b), b
}
// インデックスのランダム順列を生成する
shuffledIdxs := obfRand.Perm(len(fullData))
// 順列を適用して暗号化されたデータと鍵を分散させる
shuffledFullData := make([]byte, len(fullData))
for i, b := range fullData {
shuffledFullData[shuffledIdxs[i]] = b
}
// 復号用の AST 式を準備する
args := []ast.Expr{ast.NewIdent("data")}
for i := range data {
// インデックス鍵からランダムなバイトを選択する
keyIdx := obfRand.Intn(idxKeySize)
k := int(idxKey[keyIdx])
// 復号用の AST 式を構築する
// 1. インデックス鍵と XOR を使用してデータと鍵の実際の位置を
見つける
// 2. reverse 演算子を適用し、対応する鍵を使用してデータを
復号する
args = append(args, operatorToReversedBinaryExpr(
operators[i],
// XOR インデックスを使用して暗号化されたデータにアクセスする
ah.IndexExpr("fullData", &ast.BinaryExpr{X: ah.IntLit(shuffledIdxs[i]
^ k), Op: token.XOR, Y: ah.CallExprByName("int", ah.IndexExpr("idxKey",
ah.IntLit(keyIdx)))}),
// XOR インデックスを使用して対応する鍵にアクセスする
ah.IndexExpr("fullData", &ast.BinaryExpr{X:
ah.IntLit(shuffledIdxs[len(data)+i] ^ k), Op: token.XOR, Y:
ah.CallExprByName("int", ah.IndexExpr("idxKey", ah.IntLit(keyIdx)))}),
))
}
図 5: シャッフル変換の実装
garble は、まず 2 種類の鍵を生成します。1 つはデータ暗号化用の入力文字列と同じ長さのメイン鍵で、もう 1 つはインデックス スクランブル用の短いインデックス鍵(2~16 バイト)です。変換プロセスは、次の 4 つのステップで実行されます。
-
初期暗号化: 入力データの各バイトは、ランダムに生成された可逆演算子とそれに対応する鍵バイトを使用して暗号化されます。
-
データのインターリーブ: 暗号化されたデータと鍵のバイトが 1 つのバッファに結合され、暗号化されたデータが前半、対応する鍵が後半に配置されます。
-
インデックスの順列化: 鍵とデータのバッファにランダム順列を実行し、暗号化されたデータと鍵がバッファ全体に分散されます。
-
インデックスの暗号化: 並べ替えられたインデックスとインデックス鍵からランダムに選択されたバイトを XOR 演算することで、並べ替えられたデータへのアクセスをさらに難読化します。
図 6 は、IDA によって生成された、シャッフル変換の復号サブルーチンの逆コンパイルされたコードを示しています。
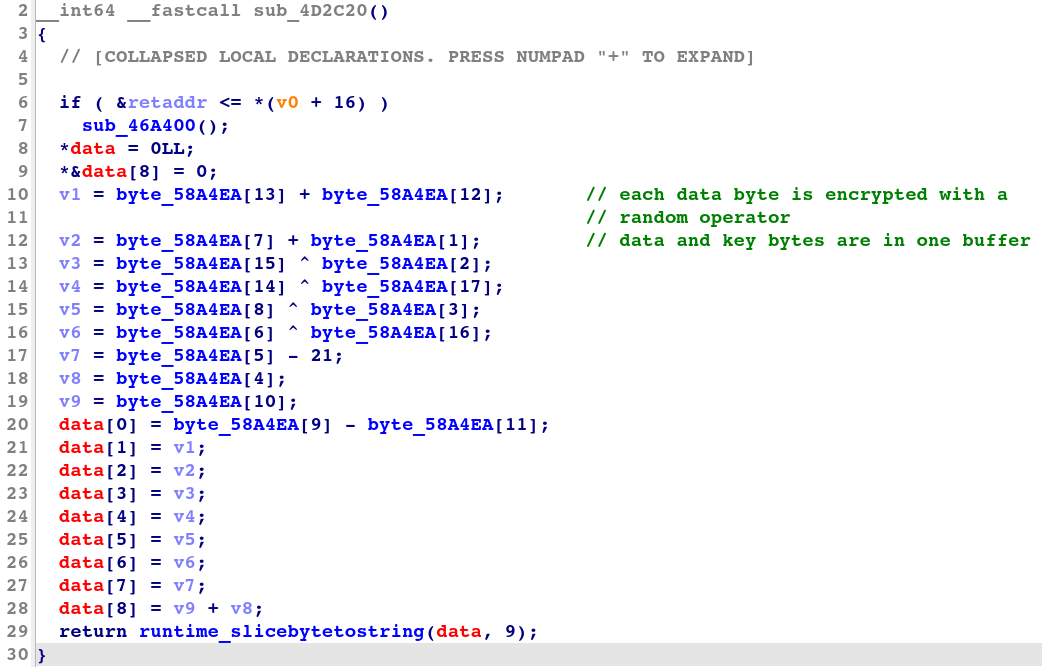
図 6: シャッフル変換における復号サブルーチンの逆コンパイルされたコード
シード変換
シード変換では、継続的に更新されるシード値を通じてバイトの暗号化が前の暗号化に依存する、連鎖的エンコード方式を実装します。図 7 は、garble リポジトリの実装を示しています。
// ランダムな初期シード値を生成する
seed := byte(obfRand.Uint32())
// 復号時に使用するため、元のシードを保存する
originalSeed := seed
// 暗号化に使用する可逆演算子をランダムに選択する
op := randOperator(obfRand)
var callExpr *ast.CallExpr
// 各バイトを暗号化しながら関数呼び出しのチェーンを構築する
for i, b := range data {
// 現在のシード値を使用して現在のバイトを暗号化する
encB := evalOperator(op, b, seed)
// 暗号化されたバイトを追加してシードを更新する
seed += encB
if i == 0 {
// 最初の暗号化バイトで関数呼び出しチェーンを開始する
callExpr = ah.CallExpr(ast.NewIdent("fnc"), ah.IntLit(int(encB)))
} else {
// 関数呼び出しチェーンに後続の暗号化バイトを追加する
callExpr = ah.CallExpr(callExpr, ah.IntLit(int(encB)))
}
}
...図 7: シード変換の実装
garble はまず、暗号化に使用するシード値をランダムに生成します。コンパイラが入力文字列を反復処理すると、現在のシードを使用してランダムな演算子を適用することで各バイトが暗号化され、暗号化されたバイトを追加することでシードが更新されます。このシード変換では、各バイトの暗号化が前のバイトの結果に依存し、継続的に更新されるシードを通じて依存関係の連鎖が形成されます。
復号設定では、図 8 の IDA で逆コンパイルされたコードに示されているように、難読化ツールが復号関数への呼び出しのチェーンを生成します。最初のバイトから始まる暗号化されたバイトごとに、復号関数は演算子を適用して現在のシードで復号し、暗号化されたバイトをシードに追加してシードを更新します。この設定により、この変換タイプのサブルーチンは復号プロセスで複数の関数呼び出しを行うため、逆コンパイラ ビューや逆アセンブリ ビューで簡単に認識できます。
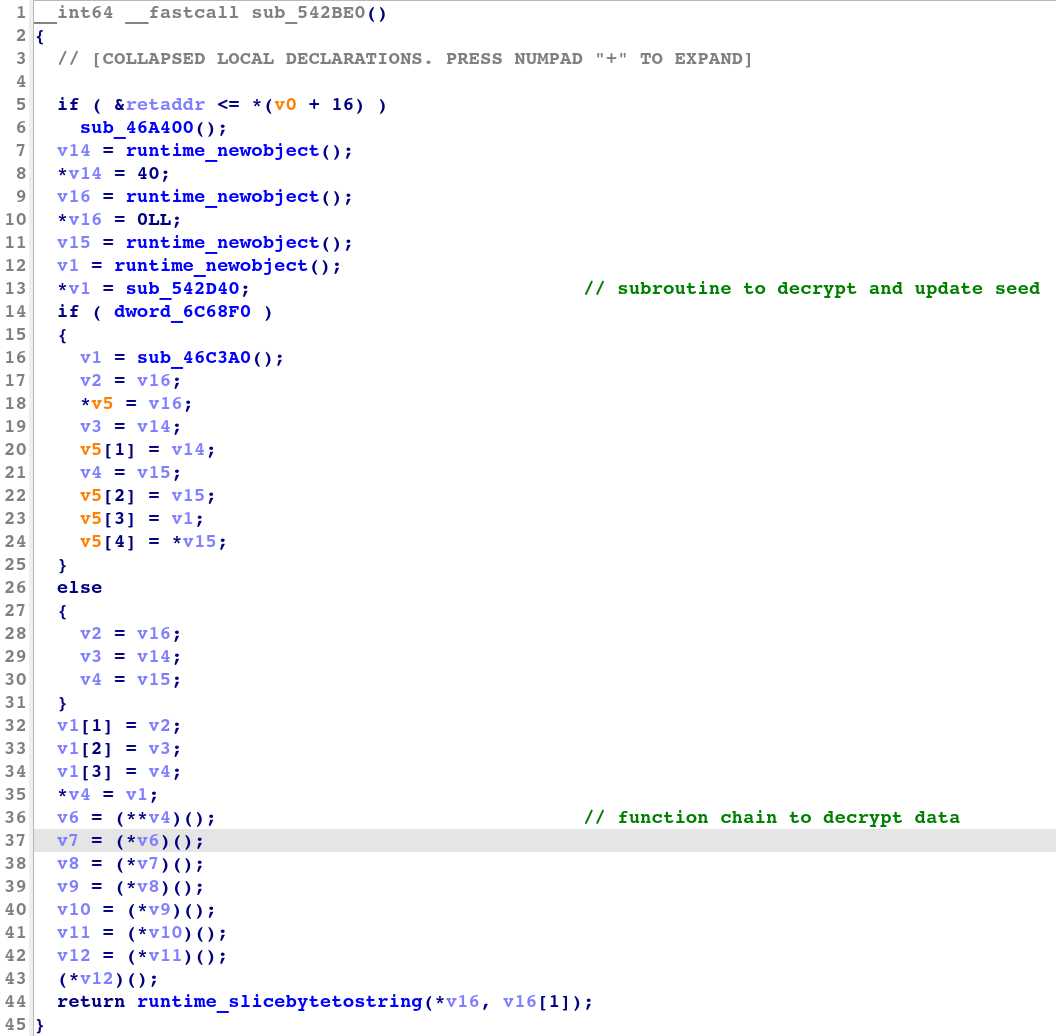
図 8: シード変換における復号サブルーチンの逆コンパイルされたコード

図 9: シード変換における復号サブルーチンの逆アセンブルされたコード
分割変換
分割変換は、garble を使用したより高度な文字列変換手法の一つで、データの断片化、暗号化、制御フローの操作を組み合わせた多層的アプローチを実装します。図 10 は、garble リポジトリの実装を示しています。
func (split) obfuscate(obfRand *mathrand.Rand, data []byte)
*ast.BlockStmt {
var chunks [][]byte
// 入力が小さい場合は、シングルバイトに分割する
// これにより、小さなペイロードでも十分な難読化が可能になる
if len(data)/maxChunkSize < minCaseCount {
chunks = splitIntoOneByteChunks(data)
} else {
chunks = splitIntoRandomChunks(obfRand, data)
}
// すべてのチャンクと 2 つの特殊なケースに対してランダム インデックスを生成する
// - 1 つは最後の復号オペレーション用
// - 1 つは終了条件用
indexes := obfRand.Perm(len(chunks) + 2)
// 復号鍵をランダムな値で初期化する
decryptKeyInitial := byte(obfRand.Uint32())
decryptKey := decryptKeyInitial
// 位置依存の値で XOR 演算して最終的な復号鍵を
計算する
for i, index := range indexes[:len(indexes)-1] {
decryptKey ^= byte(index * i)
}
// 暗号化に使用する可逆演算子をランダムに選択する
op := randOperator(obfRand)
// 選択した演算子と鍵を使用してすべてのデータチャンクを暗号化する
encryptChunks(chunks, op, decryptKey)
// 復号状態と終了状態のための特別なインデックスを取得する
decryptIndex := indexes[len(indexes)-2]
exitIndex := indexes[len(indexes)-1]
// データを再アセンブルする復号ケースを作成する
switchCases := []ast.Stmt{&ast.CaseClause{
List: []ast.Expr{ah.IntLit(decryptIndex)},
Body: shuffleStmts(obfRand,
// 終了ケース: 次の状態を終了に設定する
&ast.AssignStmt{
Lhs: []ast.Expr{ast.NewIdent("i")}},
Tok: token.ASSIGN,
Rhs: []ast.Expr{ah.IntLit(exitIndex)}},
},
// アセンブルされたデータを反復処理し、各バイトを復号する
&ast.RangeStmt{
Key: ast.NewIdent("y"),
Tok: token.DEFINE,
X: ast.NewIdent("data"),
Body: ah.BlockStmt(&ast.AssignStmt{
Lhs: []ast.Expr{ah.IndexExpr("data", ast.NewIdent("y"))},
Tok: token.ASSIGN,
Rhs: []ast.Expr{
// 暗号化の逆のオペレーションを適用する
operatorToReversedBinaryExpr(
op,
ah.IndexExpr("data", ast.NewIdent("y")),
// 位置依存の鍵での XOR
ah.CallExpr(ast.NewIdent("byte"), &ast.BinaryExpr{
X: ast.NewIdent("decryptKey"),
Op: token.XOR
Y: ast.NewIdent("y"),
}),
),
},
}),
},
),
}}
// データチャンクごとに switch ケースを作成する
for i := range chunks {
index := indexes[i]
nextIndex := indexes[i+1]
chunk := chunks[i]
appendCallExpr := &ast.CallExpr{
Fun: ast.NewIdent("append"),
Args: []ast.Expr{ast.NewIdent("data")}]
}
...
// このチャンクの switch ケースを作成する
switchCases = append(switchCases, &ast.CaseClause{
List: []ast.Expr{ah.IntLit(index)},
Body: shuffleStmts(obfRand,
// 次の状態を設定する
&ast.AssignStmt{
Lhs: []ast.Expr{ast.NewIdent("i")}},
Tok: token.ASSIGN,
Rhs: []ast.Expr{ah.IntLit(nextIndex)}},
},
// このチャンクを収集したデータに追加する
&ast.AssignStmt{
Lhs: []ast.Expr{ast.NewIdent("data")}},
Tok: token.ASSIGN,
Rhs: []ast.Expr{appendCallExpr}、
},
),
})
}
// 最後のブロックでは、ステートマシンのループ構造を作成する
return ah.BlockStmt(
...
// 現在の状態とカウンタに基づいて復号鍵を更新する
Body: ah.BlockStmt(
&ast.AssignStmt{
Lhs: []ast.Expr{ast.NewIdent("decryptKey")}},
Tok: token.XOR_ASSIGN,
Rhs: []ast.Expr{
&ast.BinaryExpr{
X: ast.NewIdent("i"),
Op: token.MUL
Y: ast.NewIdent("counter"),
},
},
},
// ステートマシンの中核となるメインの switch 文
&ast.SwitchStmt{
Tag: ast.NewIdent("i"),
Body: ah.BlockStmt(shuffleStmts(obfRand, switchCases...)...),
}),図 10: 分割変換の実装
この変換ではまず、入力文字列をさまざまなサイズのチャンクに分割します。短い文字列は個々のバイトに分割され、長い文字列は最大 4 バイトのランダムなサイズのチャンクに分割されます。
次に、switch ベースの制御フローパターンを使用して復号メカニズムを構築します。コンパイラは、チャンクを順番に処理するのではなく、一連の switch ケースを通じてランダムな実行順序を生成します。各ケースは特定のデータチャンクを処理し、チャンクの位置とグローバル暗号鍵の両方から派生した位置依存の鍵で暗号化します。
復号設定では、図 11 の IDA で逆コンパイルされたコードに示されているように、まず難読化ツールが対応する順序で各チャンクを処理して暗号化されたデータを収集します。最後の switch ケースでは、コンパイラが暗号化されたバッファを XOR で復号するための最終パスを実行します。このパスでは、バイトの位置と switch 文の実行パスの両方に応じて継続的に更新される鍵を使用して、各バイトを復号します。
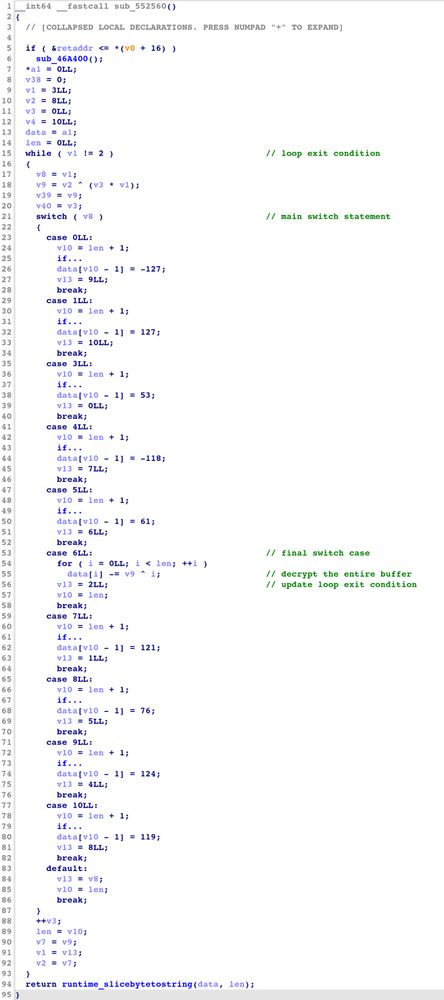
図 11: 分割変換における復号サブルーチンの逆コンパイルされたコード
GoStringUngarbler: 自動文字列難読化解除ツール
文字列の復号の自動化に体系的に取り組むために、まず手動で復号する方法について検討します。Google の経験から言える最も効率的な手動アプローチは、デバッガによる動的分析の活用です。復号サブルーチンを見つけたら、プログラム カウンタを操作してサブルーチンのエントリ ポイントをターゲットにし、ret 命令まで実行して、復号された文字列をリターン バッファから抽出します。
このプロセスを自動的に実行するうえでの大きな課題は、garble の変換によって導入されたすべての復号サブルーチンを特定することにあります。分析の結果、一貫したパターンが明らかになりました。復号された文字列は、復号サブルーチンによって返される前に常に Go の runtime_slicebytetostring 関数で処理されています。この分析結果から信頼できるアンカー ポイントが明らかになったことで、これらのサブルーチンを自動的に検出するための正規表現(regex)パターンの構築が可能になりました。
文字列暗号化サブルーチン パターン
逆アセンブルされたコードを分析することで、各文字列変換バリアントの一貫した命令パターンを特定しました。64 ビットバイナリの各変換では、rbx は復号された文字列ポインタを格納するために使用され、rcx には復号された文字列の長さが割り当てられます。各変換の主な違いは、runtime_slicebytetostring を呼び出す前にこの 2 つのレジスタに値が入力される方法です。
# Go コンパイラ v1.21 -> v1.23(x64)
# スタック変換エピローグ パターン
48 8D 5C ?? ?? lea rbx, [rsp+<num>] # 復号された文字列ポインタ
B9 ?? ?? ?? ?? mov ecx, <num> # 復号された文字列の長さ
E8 ?? ?? ?? ?? call runtime_slicebytetostring
48 83 ?? ?? add rsp, <num> # エピローグのクリーンアップ
5D pop rbp
C3 retn
---------------------------------------
# 分割変換エピローグ パターン
31 C0 xor eax, eax
48 89 ?? mov rbx, <reg> # 復号された文字列ポインタ
48 89 ?? mov rcx, <reg> # 復号された文字列の長さ
E8 ?? ?? ?? ?? call runtime_slicebytetostring
48 83 ?? ?? add rsp, <num>
5D pop rbp
C3 retn
---------------------------------------
# シード変換エピローグ パターン
48 8B ?? mov rbx, [<reg>] # 復号された文字列ポインタ
48 8B ?? ?? mov rcx, [<reg>+8] # 復号された文字列の長さ
31 C0 xor eax, eax
E8 ?? ?? ?? ?? call runtime_slicebytetostring
48 83 ?? ?? add rsp, <num>
5D pop rbp
C3 retn図 12: garble の復号サブルーチンのエピローグ パターン
図 12 のアセンブリ パターンを通じて、garble の各変換タイプに対応する正規表現パターンを開発します。これにより、文字列復号サブルーチンを高い精度で自動的に識別できます。
復号された文字列を抽出するには、サブルーチンのプロローグを見つけ、runtime_slicebytestring が呼び出されるまでこのエントリ ポイントから命令レベルのエミュレーションを実行する必要があります。Go バージョン v1.21 から v1.23 のバイナリでは、Go スタック チェックを実行するサブルーチン プロローグで、2 つの主な命令のパターンが見られます。
# Go プロローグ パターン 1
49 3B ?? ?? cmp rsp, [<reg>+<num>]
0F 86 ?? ?? ?? ?? jbe <offset>
------------------------
# Go プロローグ パターン 2
49 3B ?? ?? cmp rsp, [<reg>+<num>]
76 ?? jbe short <offset>図 13: Go サブルーチンのプロローグ命令パターン
Go プロローグにおけるこれらの命令パターンは、エミュレーションの信頼できるエントリ ポイント マーカーとして機能します。GoStringUngarbler の実装ではこれらの構造パターンを利用し、unicorn エミュレーション エンジンの信頼性の高い実行コンテキストを確立して、さまざまな garble 文字列変換で正確な文字列の復元を保証します。
図 14 は、GoStringUngarbler がすべての復号サブルーチンを特定してエミュレートできる自動抽出フレームワークの出力を示しています。

図 14: GoStringUngarbler の文字列抽出の出力
これらの命令パターンから、garble のリテラル変換で難読化されたサンプルを検出するための YARA ルールを導き出しました。このルールは、Mandiant の GitHub リポジトリで参照できます。
難読化解除: サブルーチン パッチ
難読化された文字列を抽出すると、シグネチャベースの分析によるマルウェア検出には有効ですが、これだけでは静的分析を行うリバース エンジニアリングには役立ちません。リバース エンジニアリングの取り組みを支援するために、Google はエミュレーションの結果を活用したバイナリ難読化解除アプローチを実装しました。
IDA プラグインを開発すれば開発プロセスを効率化できるものの、すべてのマルウェア アナリストが IDA Pro にアクセスできるわけではなく、また IDA Pro を好んで使用しているわけではないことも認識しています。Google のツールをより利用しやすくするために、garble で保護されたバイナリを処理するスタンドアロンの Python ユーティリティとして GoStringUngarbler を開発しました。このツールは、難読化を解除して、復元した文字列を書式なしテキストで保存した機能的に同一の実行可能ファイルを生成できるため、リバース エンジニアリング分析とマルウェア検出ワークフローの両方を改善できます。
特定された復号サブルーチンごとに、戦略的なパッチ適用方法を実装し、元のコードを最適化されたスタブに置き換え、残りのサブルーチン スペースを INT3 命令で埋めます(図 15)。
xor eax, eax ; clear return register
lea rbx, <string addr> ; Load effective address of decrypted string
mov ecx, <string len> ; populate string length
call runtime_slicebytetostring ; convert slice to Go string
ret ; return the decrypted string図 15: garble の復号サブルーチンにパッチを適用する関数スタブ
当初は、パッチを適用したサブルーチンから効率的に参照できるように、復元した文字列を既存のバイナリ セクションに保存することを検討していました。しかし、難読化されたバイナリを調べたところ、既存のセクション内には難読化解除された文字列を一貫して収容するのに十分なスペースがないことが判明しました。一方、新しいセクションを追加することは可能であるものの、それではツールが不必要に複雑化してしまいます。
代わりに、garble の文字列変換に固有の特性を利用した、より高度なスペース利用戦略を採用しています。Google のツールでは、復号ルーチンにより確保された使用可能なスペースを活用し、復号された文字列をパッチ適用したスタブの直後に書き込むことで、インプレース文字列ストレージを実装します。
-
スタック変換: 復号サブルーチンは、暗号化された文字列をスタックに保存して処理し、データ操作命令により十分なスペースを提供します。暗号化されたデータをスタックに push するために元々使用されていた命令は、復号された文字列に適した保存容量を作成します。
-
シード変換: 文字ごとに、復号サブルーチンは復号してシードを更新するための呼び出し命令を必要とします。これは、復号したバイトを保存するには十分な容量です。
-
分割変換: 復号サブルーチンには、断片化されたデータの復元と復号を処理するための複数の switch ケースが含まれています。これらの広範な命令シーケンスは、復号された文字列データに十分なスペースを確保します。
図 16 と図 17 は、Google のパッチ適用フレームワークにおける逆アセンブルと逆コンパイルの出力を示しています。ここでは、GoStringUngarbler が復号サブルーチンの難読化を解除して、復元された元の文字列を表示しています。
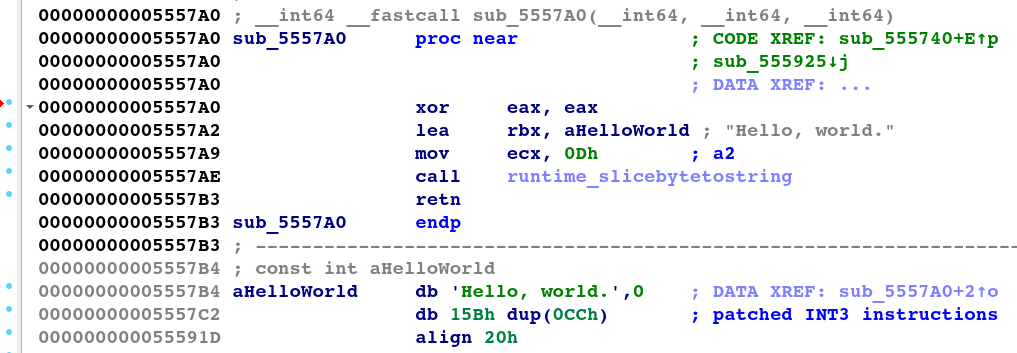
図 16: 難読化解除された復号サブルーチンの逆アセンブル ビュー

図 17: 難読化解除された復号サブルーチンの逆コンパイル ビュー
GoStringUngarbler をダウンロード
GoStringUngarbler は、Mandiant の GitHub リポジトリでオープンソース ツールとしてご利用いただけます。
インストールには、Python3 と requirements.txt ファイルの Python 依存関係が必要です。
今後の可能性
garble で生成されたバイナリの難読化解除には、特定の課題があります。難読化が Go コンパイラに依存しているため、Go のバージョン間で呼び出し規約が変わる場合があり、難読化解除プロセスで使用される正規表現パターンが無効になる可能性があるという点です。この問題を軽減するために、GoStringUngarbler はモジュール式のプラグイン アーキテクチャで設計されています。これにより、新しい Go リリースで導入されたバリエーションに対応するため、正規表現を更新して新しいプラグインを簡単に追加できます。この設計により、garble の出力に将来変更があった場合でも、ツールは長期的に適応していくことが可能です。
現在、GoStringUngarbler は、主に Go バージョン 1.21~1.23 でコンパイルされた garble 難読化 PE および ELF バイナリをサポートしています。Google は、Go コンパイラと garble の更新に伴ってこの範囲を拡大すべく継続的に取り組んでいます。
謝辞
GoStringUngarbler の開発を通じてレビューと継続的なフィードバックを提供してくれた Nino Isakovic 氏と Matt Williams 氏に心より感謝します。彼らの知見と提案は、ツールの最終的な実装を形作り、改良するうえで非常に貴重なものでした。
また、このブログ投稿の技術的な正確性と明確性を確認するためにレビューを行ってくれた FLARE チームのメンバーにも感謝しております。
garble の文字列暗号化に関する初期調査から得られた貴重な分析情報を提供してくれた OALabs にも感謝しております。
最後に、この難読化コンパイラに関する素晴らしい取り組みを行った garble の開発者たちに感謝の意を表します。彼らのソフトウェア保護分野への貢献は、Go バイナリ分析に関する攻撃的および防御的セキュリティ研究を大きく前進させました。
-Mandiant、執筆者: Chuong Dong
