Google SRE が Gemini CLI を使用して実際の障害を解決している方法

Riccardo Carlesso
Developer Advocate
Ramón Medrano Llamas
Software Engineer
※この投稿は米国時間 2026 年 1 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
Google のサイト信頼性エンジニアリング(SRE)において私たちがよく使うモットーの一つに、「トイルを排除する」があります。
チューリッヒのミニキッチンやマウンテンビューの廊下でも耳にすることがあるこのモットーには、反復的な手作業をエンジニアリングされたシステムに置き換えるという SRE の使命が表れています。ただし、あるシニア SRE が説明していましたが、これは単に問題を 1 回解決するスクリプトを書くということではありません。そのスクリプトを正確なタイミングでトリガーする自動化を構築するということです。たいていは、これが最も難しい部分です。
AI はすでにコードの書き方に革命をもたらしていますが、コードの運用方法についてはどうでしょう?AI は運用上の問題を安全に解決できるでしょうか?プレッシャーのかかる障害発生時に、制御不能になることなくオペレーターを支援できるでしょうか?
この記事では、Google SRE が現在、どのように Gemini 3(最新の基盤モデル)と Gemini CLI(エージェント機能をターミナルに導入するための定番ツール)を使用して問題を解決しているのか、実際のシナリオについて詳しくご説明します。
シナリオ:「ユーザーに悪影響が及ぶ時間」を短縮する
Ramón をご紹介します。コア SRE である Ramón は、Google のすべてのプロダクトの基盤となるインフラストラクチャを開発するエンジニアリング グループで働いています。このインフラストラクチャは、複数のサービスの安全性、セキュリティ、アカウント管理、データ バックエンドを支えています。
このレイヤのインフラストラクチャに問題が発生すると、すぐに広範囲のプロダクトに影響がおよびます。迅速な対応がきわめて重要であり、ユーザーに悪影響が及ぶ時間として測定されます。サービスが低下している間中、エラー バジェットが消費されます。
これに対処するため、Google は MTTM(平均緩和時間)を重視しています。完全な修復に焦点を当てる平均修復時間(MTTR)と異なり、MTTM はスピード、つまりどれだけ早く悪影響を阻止できるかに焦点を当てています。この領域において、SRE は通常、ページを認識するだけで 5 分というサービスレベル目標(SLO)が設定され、その後すぐに緩和しなければならないという大きなプレッシャーにさらされます。
インシデント対応はたいてい、次の 4 つの段階に沿って進行します。
-
ページング: SRE にアラートが送信されます。
-
緩和: ユーザーに悪影響が及ぶ時間を短縮するため、「止血」します。多くの場合、障害の原因が判明する前に行います。
-
根本原因: ユーザーへの悪影響を解消したら、根本的なバグを調査して完全に修正します。
-
ポストモーテム: インシデントを文書化し、エンジニアリング チームに対する広範なアクション アイテムを追加します。これらのアイテムは、インシデントの再発を防止するために高い優先順位が付けられます。
実際の(シミュレーションの)サービス停止を例に、Gemini CLI がこのプロセスの各ステップをどのように加速させ、MTTM を短く抑えるかを見ていきましょう。
ステップ 1: ページングと初期調査
状況: 午前 11 時。Ramón のページャーがインシデント s_e1vnco7W2 を知らせる。
ページが届くと、タイマーがスタートします。最優先事項はコードの修正ではなく、ユーザーへの影響を緩和することです。Google SRE による汎用的な緩和策への幅広い取り組みのおかげで、定義済み緩和策のクローズドな標準クラス群(トラフィックのドレイン、ロールバック、再起動、容量の追加など)がすでに用意されています。
これは LLM に最適なタスクです。症状を分類し、緩和ハンドブックを選択します。緩和ハンドブックは、エージェントが本番環境を安全に変更できるよう、動的に作成される手順です。これらのハンドブックには、実行するコマンドだけでなく、変更によって問題が効果的に解決することを確認する手順や、変更をロールバックする手順も含まれています。
Ramón はターミナルを開き、Gemini CLI を使用します。Gemini は、ProdAgent(Google の社内エージェント フレームワーク)から fetch_playbook 関数を直ちに呼び出します。この関数は、複数のツールを連結してコンテキストを構築します。
-
get_incident_details: インシデント対応管理システムからアラートデータを取得します(説明、メタデータ、前のインスタンスなど)。 -
causal_analysis: さまざまな時系列の動作と一般的な緩和ラベルの間の因果関係を見つけます。 -
timeseries_correlation: 相関関係のある時系列のペアを見つけます。これは、エージェントが根本原因と緩和策を見つけるのに役立ちます。 -
log_analysis: ログのパターンとボリューム分析を使用して、サービスのログストリーム上の異常を特定します。
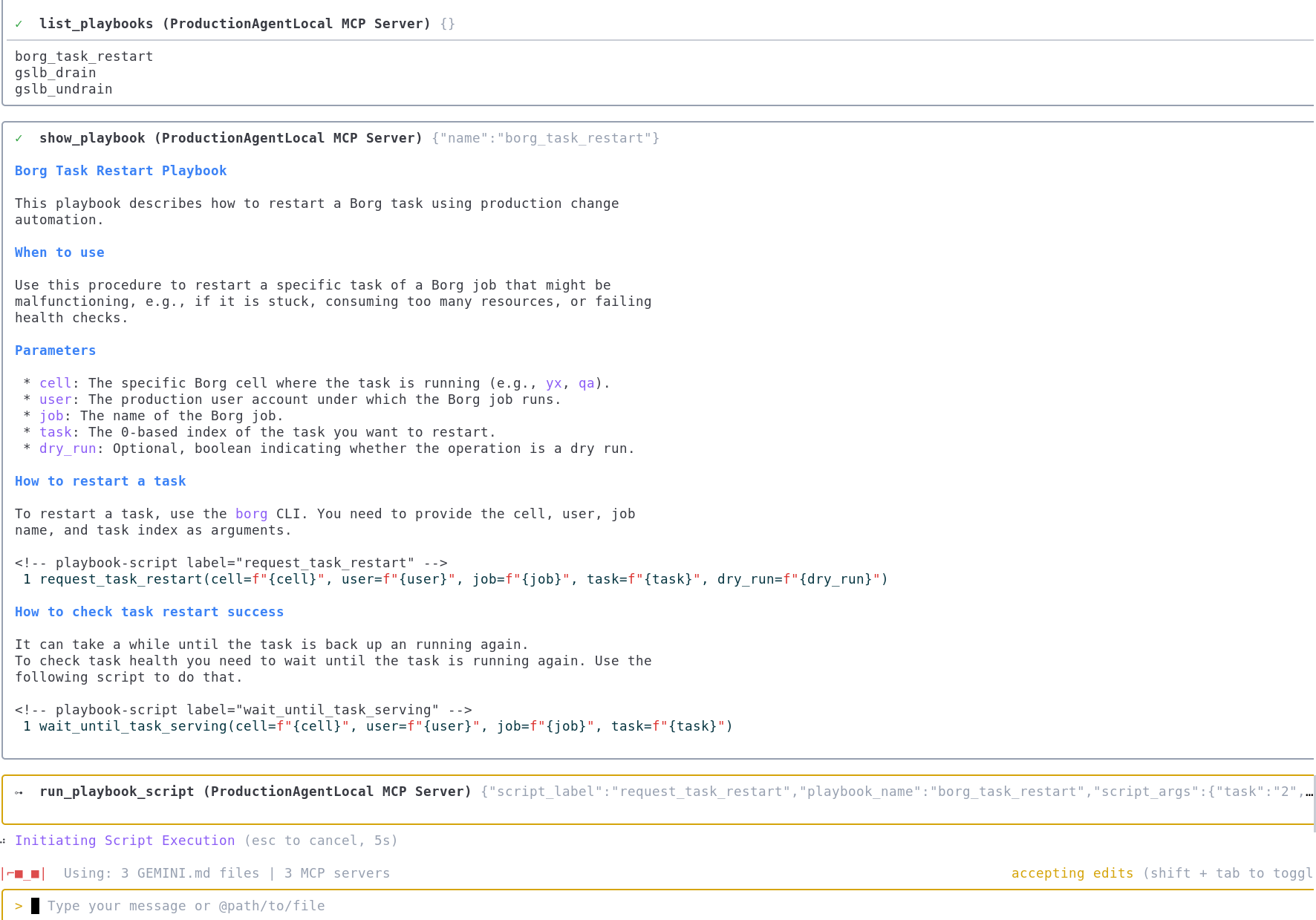
症状を踏まえ、Gemini は即時の緩和策として borg_task_restart ハンドブック(Kubernetes Pod の再起動に類似)を提案します。Gemini は、アラートのコンテキストに基づいて入力すべき変数を正確に把握しています。
Gemini は次のアクションを提案します。
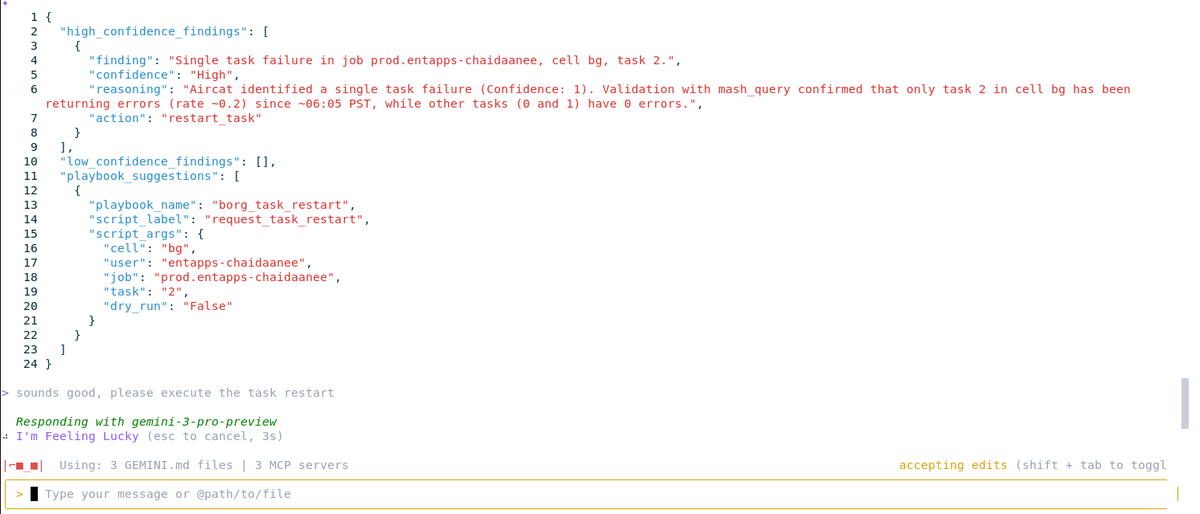
Ramón はプランを確認します。問題はなさそうです。彼は次のように入力します。
「SGTM、再起動を実行して」
現時点では、人間参加型であることが重要です。これにより、実行される緩和策が合理的なものであり、システムに適用しても安全であるかどうかを検証できます。将来的には、エージェントとその能力、そして新たなエージェント型安全システムに対する信頼が高まるにつれて、この状況は変わっていくでしょう。
ステップ 2: 緩和(止血する)
安全確認: 自動操縦ではなく副操縦士
実行する前に、安全性を確保する必要があります。自律型エージェントを本番環境インフラストラクチャで自律的に動作させることはできません。ある条件やシステム状態では安全なコマンドが、別の状況では安全でない可能性があるからです(たとえば、バイナリのロールバックは一般的には安全ですが、サービスが構成を push で受信している場合は安全ではありません)。
ここで真価を発揮するのが CLI アプローチです。CLI は、エージェントが自動操縦ではなく、責任ある副操縦士として機能するよう、多層的な安全戦略を実装しています。
-
決定論的ツール: エージェントは Bash スクリプトをランダムに記述するのではなく、
borg_task_restartのような厳密に型指定されたツール(Model Context Protocol 経由)を選択します。 -
リスク評価: 各ツールの定義には、潜在的な影響に関するメタデータ(安全性、可逆性、破壊性など)が含まれています。システムは、より厳格な確認ができるよう、リスクの高いアクションを自動的に報告します。
-
ポリシーの適用: エージェントが有効なコマンドを実行しようとした場合でも、ポリシーレイヤは現在のコンテキストで許可されているかどうかを確認します(例: 「トラフィックのピーク時にグローバルな再起動は行わない」や「2 人の承認が必要」など)。
-
人間参加型: 最後に、CLI は確認ステップを強制します。エージェントが変更を提案し、Ramón がそれを承認します。これにより、人間が責任を保持しながら AI の処理速度で対応できます。
-
監査証跡: すべてのアクションが CLI を介してプロキシされるため、AI が提案した内容と人間が承認した内容が正確かつ自動的に記録され、コンプライアンス要件を満たすことができます。
実行
理論を実行に移すと、問題が発生することがよくあります。この例では、再起動に失敗します。
手動で実行すると、MTTM が大幅に増加します。オペレーターは、コンテキストを切り替え、新しいダッシュボードを開き、手動でログを grep しなければなりません。貴重な時間が失われると同時に、ユーザーに悪影響が及ぶ時間が増えていきます。
一方、Gemini CLI はエラーをキャッチして処理の流れを維持します。直ちに障害を分析し、「このセルで障害が発生しているのはこのジョブだけであり、他のジョブは正常である」といったパターンを把握します。
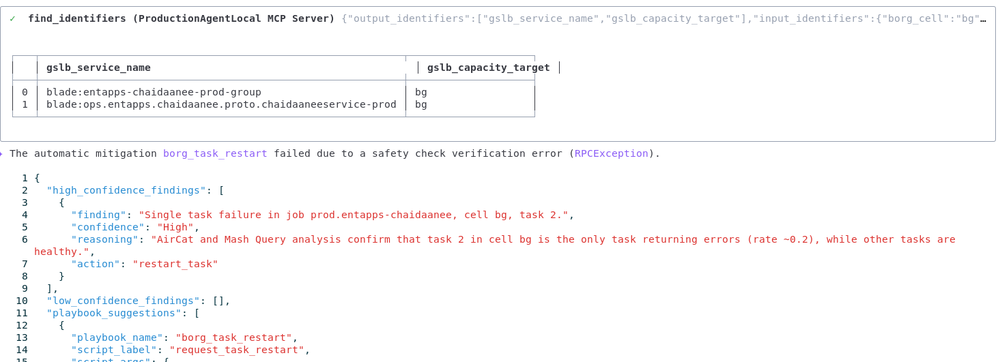
この分析情報は非常に重要です。これは、問題がクラスタではなく、特定のバイナリまたは構成にあることを示唆しています。Gemini は分単位ではなく秒単位で結果を示すため、誤った方向に進むことを回避できます。ここで「止血」フェーズを停止し、最小限の時間の損失で調査へと進みます。
ステップ 3: 根本原因と長期的な解決策
単純な再起動では解決しないことがわかったので、バグを見つける必要があります。インフラストラクチャは正常であるため、不具合はアプリケーション ロジックにあるはずです。Ramón は Gemini に特定のソースコードを示します。Google は大規模な monorepo を使用しているため、特定のフォルダをコンテキストとして渡せることは非常に便利です。
「/path/to/service/... の変更をチェックして」


Gemini はファイルの取得を開始し、最近の変更を分析して、先ほど pull した本番環境ログと相互参照します。2 分もかからずに、原因は最近の構成 push のロジックエラーであることが判明しました。
Ramón は次のように依頼します。
「その問題を修正する CL を作成して」
(注: CL(変更リスト)は、GitHub の pull リクエストに相当する Google の用語です)
Gemini がパッチを生成し、不適切な構成を元に戻して安全措置を適用する CL を作成します。

Gemini は、次のような手順を示します。
-
CL を確認して承認する。
-
CL を送信する。
-
自動的にロールアウトされるまで待つ。
コードの修正が行われ、ロールアウトが始まり、サービスが復元されます。
ステップ 4: ポストモーテム
問題は解決しましたが、作業はまだ終わっていません。SRE の文化は、ポストモーテムが基盤となっています。ポストモーテムとは、何が問題だったのかを分析し、そこから教訓を得るための、過失を責めないドキュメントです。
ポストモーテムの作成は、タイムスタンプの収集、ログの関連付け、特定のアクションの想起など、手間のかかる作業になることがあります。Gemini CLI では、カスタム コマンドを使用してこれを自動化します。
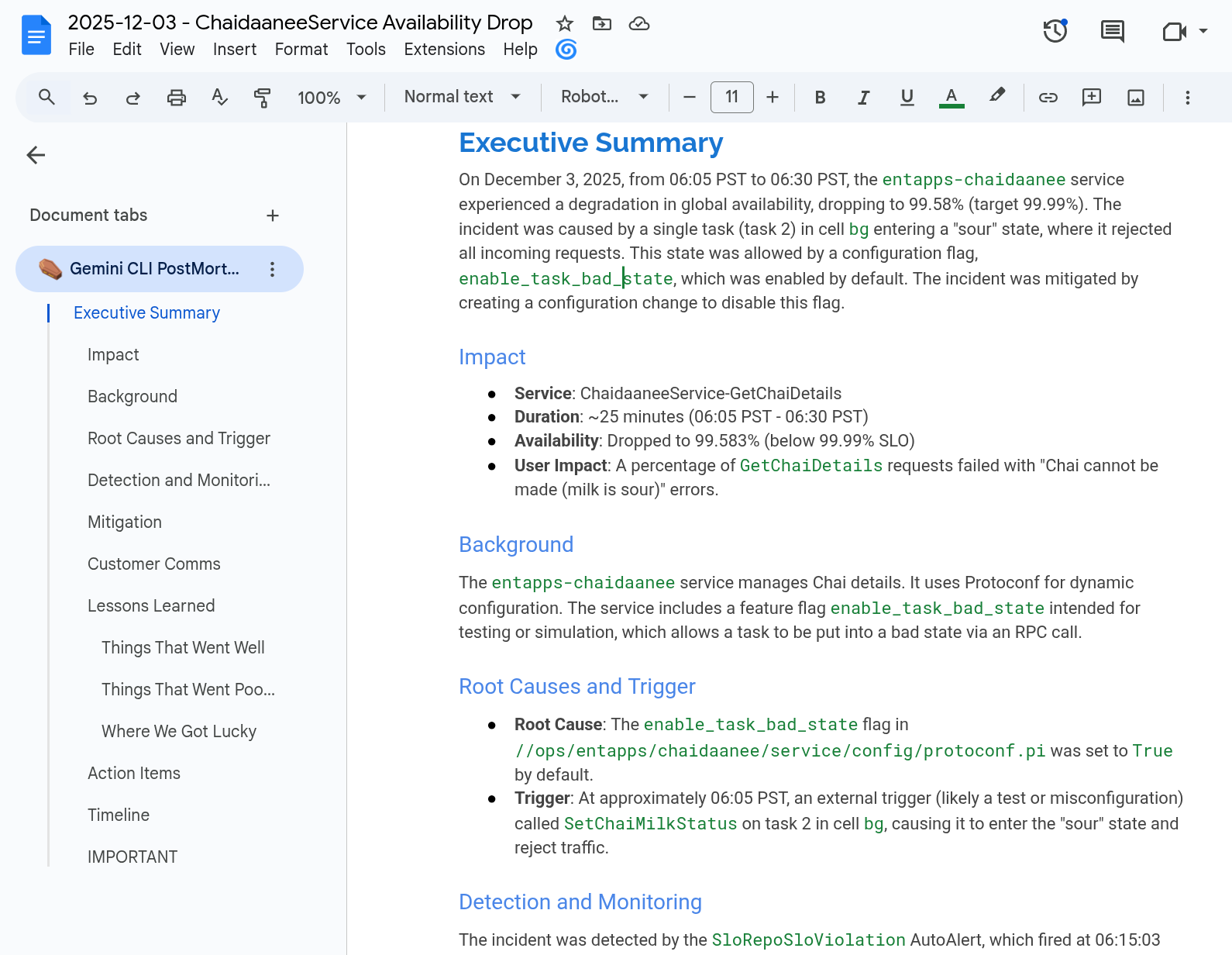
ここで Riccardo の登場です。Riccardo は長年にわたり Google Cloud SRE と連携して、いくつかのサービス停止を公式に宣言し、多くのポストモーテムに貢献してきました。また、デベロッパー アドボケイトとして、ポストモーテムの技術、SLO の技術、インシデント管理をオペレーターに伝授しています。彼は、ProdAgent 内でカスタム コマンドを作成しました。これは、ポストモーテムの作成、タイムラインの構築、アクション アイテムの作成に役立ちます。
Ramón は、Riccardo が作成したポストモーテム コマンドを実行します。ツールは、以下の処理を行います。
-
インシデントから会話履歴、指標、ログをスクレイピングする。
-
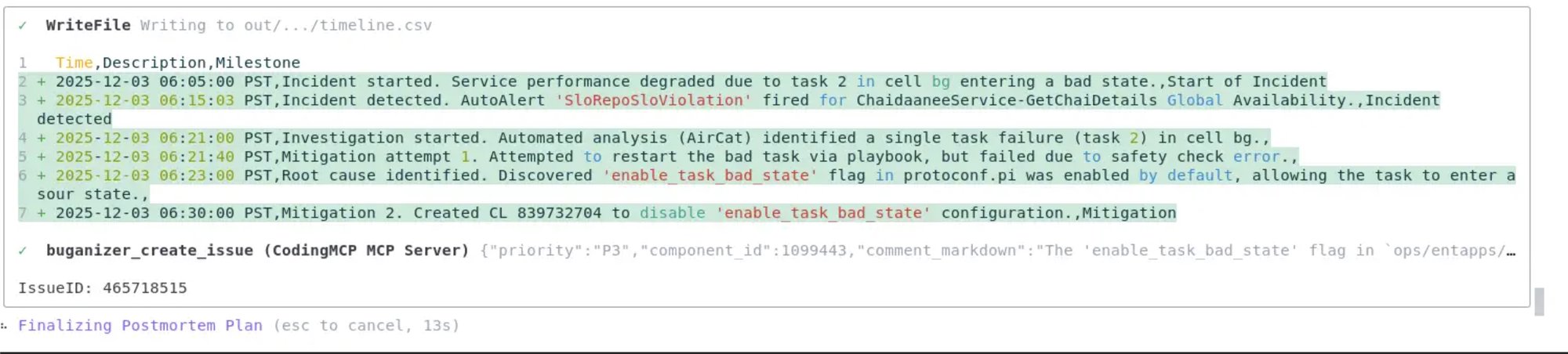
関連するすべてのイベントのタイムラインを CSV で生成する。
-
標準の SRE ポストモーテム テンプレートに基づいてマークダウン ドキュメントを生成する。
-
再発防止のためのアクション アイテム(AI)を提案する。
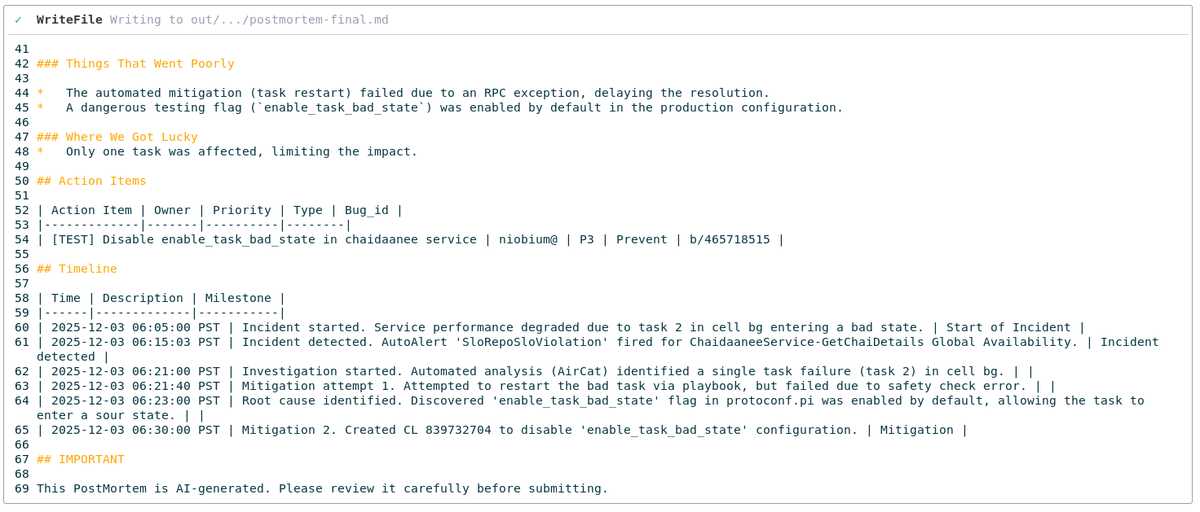
最後に、Gemini は Model Context Protocol(MCP)を使用して Issue Tracker とやり取りします。
-
バグの作成: アクション アイテムを Issue Tracker に実際のバグとして登録します。
-
オーナーの割り当て: 関係するエンジニアに割り当てます。
-
ドキュメントのエクスポート: 最終的なポストモーテムを Google ドキュメントに push します。
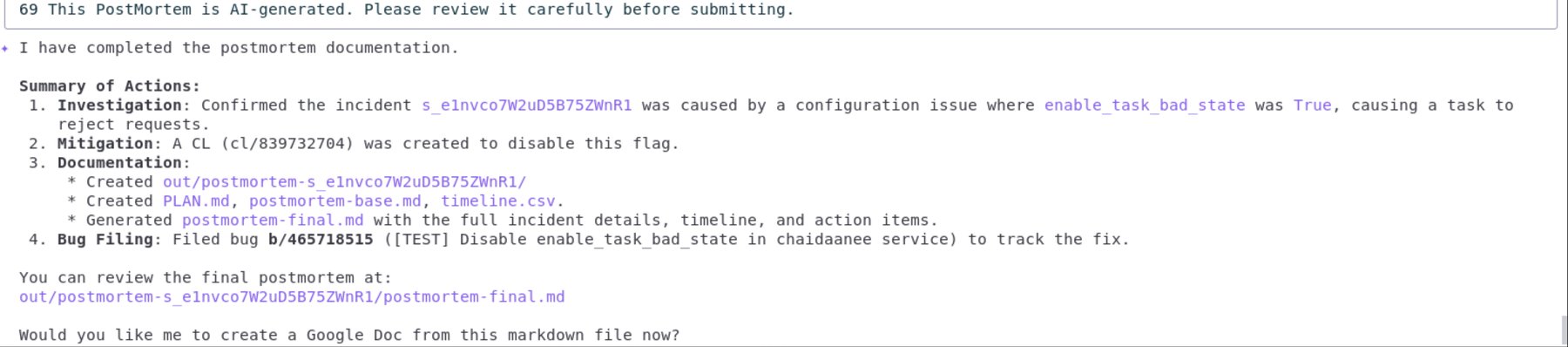
まとめ
これで、午前 3 時の混乱したページングから最終的なポストモーテムまで、インシデントのライフサイクル全体をターミナルからすべて実行しました。
Gemini CLI を使用して、Gemini 3 の推論能力と実際の運用データを結び付けました。chatbot にアドバイスを求めただけでなく、エージェントを使用してツールの実行、ライブログの分析、コードパッチの生成を行い、本番環境にロールアウトしました。この直接的な統合により、MTTM を大幅に短縮し、ユーザーに悪影響が及ぶ時間を最小限に抑えることができます。
この事例では Google の社内ツールを使用しましたが、そのパターンは普遍的です。このワークフローは今すぐ構築できます。
-
Gemini CLI は誰でも利用可能です。
-
MCP サーバーを介して、Gemini を独自のツール(Grafana、Prometheus、PagerDuty、Kubernetes など)に接続できます。
-
カスタム コマンドを使用すると、ポストモーテム ジェネレーターのように特定のチーム ワークフローを自動化できます。
好循環
おそらく最も魅力的なのは、この後に起きる部分です。先ほど生成したポストモーテムはトレーニング データになります。過去のポストモーテムを Gemini にフィードバックすることで、自己改善する好循環が生まれます。今日の調査結果が、明日の解決策のインプットになるのです。
さあ、geminicli.com でスタックの拡張機能を見つけて、トイルの排除を始めましょう。
- デベロッパー アドボケイト、Riccardo Carlesso
- ソフトウェア エンジニア、Ramón Medrano Llamas



