Google Cloud と Spring AI 1.0

Dan Dobrin
Enterprise App Modernization Architect, Google
Josh Long
Spring Developer Advocate, Broadcom
※この投稿は米国時間 2025 年 5 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
このブログ投稿の作成にご協力くださった Fran Hinkelmann と Aaron Wanjala に感謝します。
集中的な開発期間を経て、Spring AI 1.0 が正式にリリースされました。AI エンジニアリングのための堅牢で包括的なソリューションが、Java エコシステムに導入されたことになります。これは単なるライブラリではなく、Java と Spring を AI 革命の最前線に位置付けるための布石となるものです
すでに圧倒的多数の企業が Spring Boot を利用しており、AI を既存のビジネス ロジックやデータに統合するプロセスは、かつてないほどスムーズになっています。Spring AI 1.0 によって、デベロッパーはアプリケーションを最先端の AI モデルにシームレスに接続し、インテグレーションに関する一般的な課題に直面することなく、新しい可能性を切り開くことができます。インテリジェントな機能で JVM アプリケーションを進化させましょう。

Spring AI は、さまざまな AI モデルやテクノロジーに対応しています。
-
画像モデルは、提供されたテキスト プロンプトから画像を生成できます。
-
音声文字変換モデルは、音声ファイルをテキストに変換できます。
-
エンベディング モデルは、任意のデータをベクトルに変換できます。ベクトルは、セマンティック類似性検索用に最適化されたデータ型です。
-
チャットモデルについては、ご存じのとおりです。どこかで一度は短い会話を交わしたことがあるでしょう。
汎用性が高く、ドキュメントの校正や詩作など、何でもサポートしてもらえます。優れた機能ですが、欠点もいくつかあります。
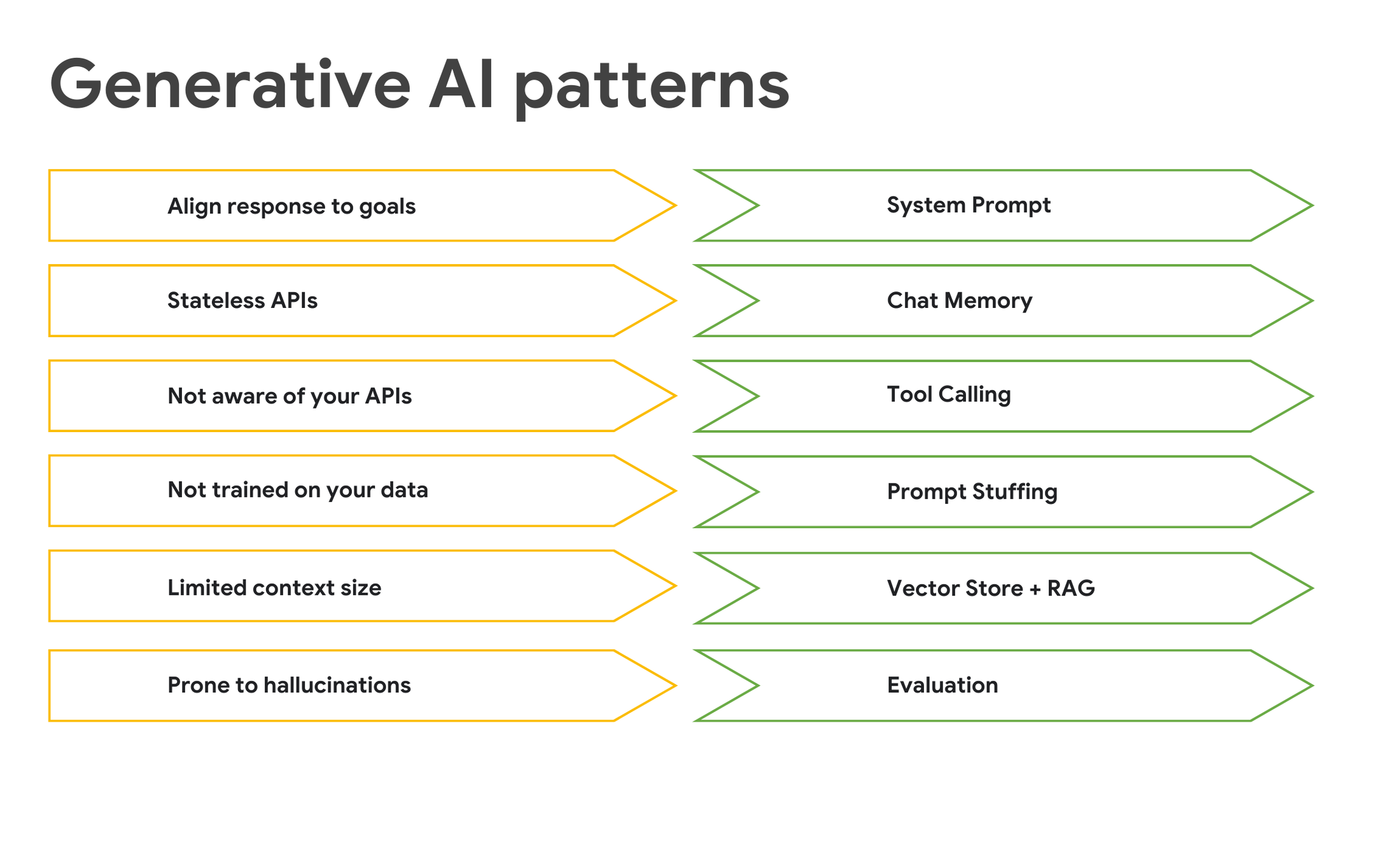
チャットモデルは柔軟な対応が可能ですが、散漫になりがちです。次の機能を追加することで、チャットモデルの管理に役立てることができます。
-
チャットモデルを適切に動作させる: システム プロンプトを使用して、チャットモデルの動作を定義します。
-
メモリに記憶させる: 会話のコンテキストを追跡するメモリを実装します。
-
AI モデルが外部関数にアクセスできるようにする: ツールの呼び出しを有効にします。
-
リクエスト内で関連情報を直接提供する: プライベート データにはプロンプト スタッフィングを使用します。
-
特定の企業データを取得して利用する: 検索拡張生成(RAG)のためにベクトルストアを活用します。
-
精度を確保する: 評価では別のモデルを使用して出力を検証します。
-
AI アプリケーションを他のサービスに接続できるようにする: Model Context Protocol(MCP)を使用します。MCP はアプリケーションのプログラミング言語に関係なく機能するため、複雑なタスク向けにエージェント ワークフローを構築できます。
Spring AI は Spring Boot とスムーズに統合し、Spring Initializr から、おなじみの抽象化と開始条件の依存関係を提供します。これにより、構成よりも規約を重視した環境が期待どおりに実現します。Spring Boot アプリケーション内で、既存のロジックとデータを AI モデルに簡単に接続できます。
Spring AI を使用すると、堅牢なソリューションを活用してチャットモデルをより効果的にし、これらのモデルをより大規模なシステムに深く統合できます。
前提条件
Vertex AI で Gemini モデルを呼び出すには、使用するサービスの認証情報を取得した後、ローカル開発環境を構成する必要があります。
まず、Google Cloud 環境を設定します。
-
Google Cloud コンソールで、Google Cloud プロジェクトを作成または選択します。
-
プロジェクトの課金を有効にします。生成 AI モデルの使用には通常、請求先アカウントが必要です。
-
コンソールで Vertex AI API を有効にします。
-
ターミナルで gcloud CLI をインストールします。これは、アプリケーションを実行するローカル開発環境でリソースを管理し、認証を設定するために不可欠です。
次のコマンドを実行して、アプリケーションのデフォルト認証情報を設定します。
設定が完了しました。次はビルドです。
ビルド
まず、Google Cloud 向けに最適化された Spring AI のシンプルなアプリケーションをビルドします。
-
Spring Initializr に移動します。
-
[Artifact] フィールドに「
google」と入力します。 -
[Project] のタイプで、Apache Maven(このブログ記事で使用)または Gradle を選択します。
-
[ADD DEPENDENCIES] をクリックし、Spring
Web、Spring Boot ActuatorActuator、GraalVMNative Support、Spring Data JDBC、Vertex AIGemini、Vertex AIEmbeddings、PGvector Vector Database、MCP Client、Docker Compose Supportの依存関係を選択します。 -
使用する Java のバージョンを選択します。利用可能な最新バージョンを使用することをおすすめします。このブログ記事では GraalVM を使用します。これは、コードを各マシンの OS とアーキテクチャに固有のイメージにコンパイルできる追加のユーティリティを備えた OpenJDK のディストリビューションです。これらのイメージは、通常の JRE ベースのアプリケーションと比較して、RAM の使用量が大幅に少なく、起動時間も短くなります。sdkman.io を使用する場合は、次のコマンドを使用してローカルマシンにインストールできます。
sdk install java 24-graalce -
[
GENERATE] をクリックし、IDE で開くことができる .zip ファイルを保存します。
必要な依存関係の追加
-
ダウンロードした .zip ファイルを解凍し、
pom.xml -
pom.xmlファイルで、<dependencyManagement>の最後に以下の行を追加します。
構成
pom.xml ファイルで、application.properties から始まる次の構成値を更新する必要があります。
更新したセクションの詳細は次のとおりです。
-
アプリでサポートされているアクチュエータを構成する: Spring Boot のオブザーバビリティ インテグレーションである Spring Boot Actuator に、すべての Actuator エンドポイントを公開するよう指示します。 -
Docker Compose の構成: 組み込みの Docker Compose Support を活用します。Spring Boot は、ディレクトリのルートにあるcompose.ymlファイルを自動的に検出し、アプリケーションの起動前に Docker イメージを実行します。Spring Initializr によって Dockercompose.ymlファイルは生成済みです。しかし、PostgreSQL はサーバーレスではないため、Spring Boot が毎回コンテナを再起動するのは望ましくありません。コンテナが実行されていない場合にのみコンテナを起動するように Spring Boot に指示します。 -
チャットモデルとエンベディング モデルを構成する:Vertex エンベディングとVertex チャットの値は、Google Cloud の Gemini で使用する Gemini チャットモデルと Gemini エンベディング モデルを構成します。この例では、ユースケースに適した 2 つのモデルを使用しています。 -
ベクトルストア内のスキーマを初期化する:vector型をサポートするプラグインで読み込まれた PostgreSQL を使用するようにアプリを構成します。Spring AI には、さまざまなベクトルストアへのデータの書き込みを処理するVectorStoreという抽象化オブジェクトがあります。この構成により、PostgreSQL をベクトルストアとして扱うために必要なストレージが Spring AI によって確実に初期化されます。 -
データベース接続パラメータ: SQL データベースへの接続を構成します。厳密に言えば、この設定は必要ではありません。Spring Boot の Docker Compose Support により、SQL データベースに自動的に接続されるためです。ご参考までに記載しました。
データベース
データのない SQL データベースがあるとします。データベースにデータがない場合、それは本当にデータベースでしょうか。それとも単なる「ベース」でしょうか。Spring Boot でデータベースを初期化するには、起動時に SQL コマンドを実行して、いくらかのデータをインストールします。起動時に実行されるファイルは、src/main/resources/schema.sql と /src/main/resources/data.sql の 2 つです。まず、schema.sql ファイルです。
単純にdog テーブルを定義しています。次に src/main/resources/data.sql ファイルで、犬の情報を追加します。
いいですね。データベースは再起動のたびに初期化されます。この構成では、再起動のたびにテーブルを削除し、同じ行を再挿入することで、重複データを回避できます。これが実際のデータベースであれば、upsert を使用することもできます。PostgresSQL は insert on conflict... do 構文でこれをサポートしています。
データアクセス リポジトリとエンティティをすばやく構築するには、Spring Data JDBC を使用します。Dog というエンティティを作成して、リポジトリのデータをモデル化およびマッピングします。
GoogleApplication.java ファイルで、GoogleApplication の後に以下の行を追加します。
アシスタント
ここからが重要です。
チャット クライアントの追加
まず、AssistantController クラスを構築します。そのために、GoogleApplication.java ファイルの最後に次のコードを追加します。
前のコードで追加した ChatClient は、チャットモデルとのすべてのやり取りをワンストップで行うためのものです。この ChatClient は、(自動構成される)ChatModel を使用して、Google の Gemini と対話します。通常は、アプリケーションに ChatModel を 1 つのみ構成しますが、複数の ChatClient を構成し、それぞれに異なるデフォルトやシナリオを適切に構成することもできます。ChatClient.Builder を使用して新しい ChatClient を作成し、前のコードでコンストラクタに挿入できます。
HTTP エンドポイントの設定
次に、HTTP エンドポイント /{user}/inquire を設定します。リクエストが届くと、システム プロンプトを使用して、モデルが架空の犬の保護施設「Pooch Palace」の実際の従業員のように振る舞うようにします。
以下のメソッドを AssistantController コントローラ クラス ファイルに追加します。
このメソッドは、特定のユーザーとモデルとの間で話されたすべての内容を追跡する PromptChatMemoryAdvisor を定義します。その後、後続のリクエストのたびに、その文字起こしをリマインダーとしてモデルに送信します。
エンドポイントのテスト
次のリクエストを試してください。
そして
ここでは、名前が Lee であると適切に判断できることが確認されるはずです。そしてさらに、犬を引き取るという目標を達成できるようにサポートしてくれることもあります。他にできることを見てみましょう。次のように質問します。
Pooch Palace のどの拠点にも犬に関する情報はないと返信されます。この場合、地域の施設リストをチェックするよう促されることもありえます。
ソースデータ
問題は、データベースのデータにアクセスできないことです。通常は、すべてのデータを渡すべきではないでしょう。
あるいは、すべてのデータを渡してもいいのかもしれません。このデータベースには 18 件ほどのレコードしかありません。これなら、すべてではなくても、ほとんどの LLM のトークン制限に簡単に収まります。Google の LLM の大規模コンテキスト ウィンドウに送信されるリクエストには確実に適合します。
すべての LLM に「トークン」というコンセプトがあります。これは、LLM によって利用および生成されるデータ量の概算値です。Google Gemini 2.5 Pro はトークンサイズが非常に大きくなっています。ローカルで実行できる Gemma オープンモデルのようなローカルモデルを使用している場合、モデル実行にかかる負担は、その複雑さと CPU 負荷のみです。Gemini のようなホスト型モデルを実行する場合は金銭的コストも発生します。
したがって、これらのモデルのいずれかに、リクエストとともにすべてのデータを送信することは可能であっても、送信するデータをできるだけ少なくするのが原則です。代わりに、すべてをベクトルストアに保存し、リクエストに関連する可能性のあるものを見つけ、最後にそのデータのみを検討のためにモデルに送信します。データベースからデータを取得し、モデルが生成する回答にそのデータを利用するこのプロセスは、検索拡張生成(RAG)と呼ばれます。
クラスのコンストラクタに VectorStore vectorStore 型のパラメータを追加します。dog テーブルからすべてのデータを読み取り、PostgreSQL を基盤とする VectorStore 実装にすべて書き出します。コンストラクタの一番上に次のコードを追加します。
残る作業は、モデルへのリクエストの本文に含める関連データについて最初に VectorStore を確認するように ChatClient に指示することだけです。これはアドバイザーを使用して行います。ChatClient の定義を次のように変更します。
再度のテストとソリューションの改良
プログラムを実行して、再度質問します。
今度は、私たちの希望に合った Prancer という名の陽気な犬が保護施設にいるという回答が得られるはずです。
次にすべきことは、当然、この犬を引き取ることです。しかし、いつ、この犬をお迎えに行けるでしょうか。ここで LLM を、特許申請中の業界最高水準のスケジューリング アルゴリズムに接続する必要があります。
DogAdoptionsScheduler クラスを GoogleApplication.java ファイルに追加します。
メソッドに Spring AI の @Tool と @ToolParam のアノテーションを付けました。これらのアノテーションによって、モデルが使用する説明と、メソッドの形状とともに、モデルが有用かどうかを直感的に判断できます。これらのツールが利用可能であることをモデルに伝えることも必要です。GoogleApplication.java ファイルから、新しく定義した DogAdoptionScheduler スケジューラをコントローラのコンストラクタに挿入し、ChatClient の定義に以下を追加します。
プログラムを再起動して試してみます。Prancer についてもう一度質問します。
回答に情報が含まれるようになったので、次に Prancer を引き取る方法を尋ねます。
3 日後に引き渡しの予約が可能であると確認できましたか?これで完了です。これで、サービスのデータとビジネス ロジックにモデルからアクセスできるようになりました。
Model Context Protocol のご紹介
このサービスはすべて Spring で記述され、Spring AI を使用していますが、もちろん他の言語やテクノロジー スタックもあります。これらのスタックから、この業界をリードする特許出願中のスケジューリング アルゴリズムを利用したい場合もあるでしょう。その場合は、Model Context Protocol を使用して、その機能を抽出し、LLM とのすべてのインタラクションで使用できるツールにします。このプロトコルは Anthropic によって最初に設計されたもので、ツールがどのプログラミング言語で記述されているかに関係なく、LLM のツールボックスに統合するための簡単な方法を提供します。
Spring Initializr に戻り、新しいプロジェクトを設定します。
1. scheduler という名前の新しいプロジェクトを生成します。
2. Spring Web と MCP Server を依存関係として追加します。
3. 前と同じように、最新バージョンの Java と Maven を選択します。
4. 生成された .zip ファイルを解凍して、IDE で開きます。
5. google プロジェクトから DogAdoptionsScheduler コンポーネントを切り取って、この新しいプロジェクトの SxchedulerApplication.java ファイルに貼り付けます。
6. 別のポートで新しいプロジェクトを起動します。application.properties に server.port=8081 を追加します。
7. SchedulerApplication で次の bean を定義します。
8. アプリケーションを起動します。
9. アシスタントに戻り、以前使用していたコンポーネントの代わりにリモート サービスを使用するようにアシスタントを変更します。
10. GoogleApplication.java クラスに次の bean 定義を追加します。
11. AssistantController のコントローラを変更して、以前の DogAdoptionsScheduler の代わりに McpSyncClient クライアントを挿入します。それに応じて ai の定義を変更します。
12. アプリケーションを再起動してから、もう一度操作を試します。
モデルの回答は基本的に前回と同じですが、リクエストが google サービスではなく、新しく作成した scheduler コンポーネントで処理されたことが確認できます。計画がうまくまとまると気持ちがいいですね。
本番環境に適した AI
アプリケーションを本番環境にデプロイする際、Google Cloud では PostgreSQL と互換性のある 2 つの優れた選択肢が用意されており、どちらも pgVector 機能をサポートしています。まず、Google Cloud SQL を使用できます。これは基本的に Google がホストする PostgreSQL です。他に必要なものはあるでしょうか?多くのユースケースでは、ほとんどないと考えられます。ただし、さらに優れたパフォーマンス、可用性、スケーラビリティを求めるのであれば、Google Cloud の AlloyDB が最適です。
AlloyDB はあらゆる規模にスケーラブルで、メンテナンスを含む 99.99% の可用性 SLA を提供します。また、AI ワークロードに特化した設計になっています。この例では Docker イメージで PostgreSQL を使用していますが、デプロイするときは AlloyDB インスタンスをスピンアップします。
コードベース
このチュートリアルのコードは GitHub で入手できます。
次のステップ
Spring AI と Google を活用して、本番環境に適した AI 対応のアプリケーションを短時間でビルドできました。これはほんの始まりにすぎません。Spring AI 1.0 を Spring Initializr で今すぐチェックし、Google Cloud の詳細についてもご確認ください。
関連情報
-Google、エンタープライズ アプリ モダナイゼーション担当アーキテクト、Dan Dobrin
-Broadcom、Spring デベロッパー アドボケイト、Josh Long 氏



