Tensorflow でセルフサービスのテクニカル サポートを自動化

Google Cloud Japan Team
※この投稿は米国時間 2022 年 11 月 18 日に、Google Cloud blog に投稿されたものの抄訳です
問い合わせに対しどの記事が適切であるかをより効率的に解析して表示できる AI を活用することで、セルフサービスのテクニカル サポート コンテンツへのアクセスを高速化できます。
人間のサポート エージェントがチケットに対応する前に、AI エージェントが適切なセルフサービス記事を提案できたら、テクニカル サポートはどのようなものになるでしょうか?
Google は、それを確かめたいと考えていました。そこで機械学習チームに、人間がチケットに対応する前に、チケット システムに自動的に統合されたサポート ドキュメントを提案する方法の確立に取り組んでもらいました。
これはまさしく AI で対処すべき問題です。利用可能なデータが膨大な量に及び、意思決定を繰り返し行う必要があり、自然言語の要素が大きく、AI に任せることで、数万もの人時を生産性向上に回すことができます。Google が抱える他の IT 課題と比べて、影響力は大きいのに、それほど複雑ではありません。
サポートをより迅速に提供
Google 社員は、職場でよく直面する技術的な問題のトラブルシューティングや解決に、ナレッジベースのサポート記事を活用しています。このようなセルフサービス チャネルでは、繰り返し発生する問題が明確に文書化されているため、簡単に自己解決でき、同様の問題に繰り返し対応しなければならないストレスからエージェントを解放できます。セルフサービスの記事を利用しない場合、ユーザーはチャット チャネルやチケットを使い、エージェントが対応可能になるまで待つこともあり、またエージェントは問題解決の手順をユーザーに説明しなければならず、多くの時間を割くことになります。チャットやチケット チャネルでセルフサービス サポート記事を自動的に表示できれば、エージェントは検索時間を短縮でき、ユーザーには即時にヘルプが提供されるため、両者にとって効率的です。
時間と手間のかかる従来型の手動サポート
サポート エージェントは現在、いずれかのサポート記事を送信するか、情報を直接提供するという、手動の方法でチケットに対応しています。サポート記事が役立つかもしれない機会を特定しようとする正規表現(regex)ソリューションはすでにありますが、正規表現は手作りのルールであり、機械学習モデルほど堅牢ではありません。このシステムでは、誰かが新しいルールを手動で加えない限り、新たに発生する問題に適応できないのです。
ML で回答の提供を高速化
Google は、もっと優れたシステムを生み出しました。機械学習(ML)モデルで生成された回答を提供する新しいシステムは、既存のドキュメントを使用してほぼ瞬時に回答を提供し、プロセスを高速化できます。
サポート チケットを送信したユーザーは、人間によるサポートを受ける前に、ML から推奨されたヘルプセンターの記事を受け取ります。このモデルは、チケットにユーザーが記載した問題の説明を評価し、問題の解決につながる既存のヘルプセンター記事がある場合は、その記事をユーザーに即座にメールで送信します。
このプロセスのメリット:
モデルが失敗した場合でもユーザーに大きな影響を与えることなく、エージェントの時間を節約できる
最初の連絡時により多くのチケットを解決でき、Google 社員が人間によるサポートを待つ時間を大幅に削減できる
つまりチケットプール内のかなりの割合のチケットで、回答を 2~3 時間待つ代わりに、多くの場合 1 分以内に回答を得られるということになります。
Tensorflow と BERT
Google ではいくつかのタイプの機械学習モデルを試しました。TF-IDF の特徴量化を使用する完全に接続されたディープ ニューラル ネットワークが最も単純であり、微調整が必要な BERT モデルが最も複雑でした。意外なことに、TF-IDF が最もうまく機能したのですが、これは、BERT を完全に活用するにはトレーニング データが足りなかった(チケットが数十万件しかなかった)ためであると考えられます。双方に大きな違いはありませんでしたが、TF-IDF ではトレーニングとサービスの費用をかなり抑えることができます。TFX を使用して、最新データの取得、モデルのトレーニング、モデルのサービングをすべて自動的に行う完全なパイプラインを設定してあります。モデルのトレーニング データとして活用しているのは、エージェントがサポート記事を含む回答を手動で返信したチケットです。
Google のツールチェーンは最終的に、次のような構成となりました。
TensorFlow: ML モデリングに使用
TFX: モデルのプロトタイピング、再トレーニング、サービングに使用
Servomatic: モデルをサポート チームに提供するための内部ツール
Vizier: バッチサイズ、学習率、語彙サイズ、隠しレイヤなどのハイパーパラメータの調整に使用
TF Hub: BERT モデルのスピンアップに使用
TF Hub を活用することで、BERT モデルをすばやく実行でき、さまざまなタイプのモデルをテストして、Google の目標に最適なモデルを見つけることができました。
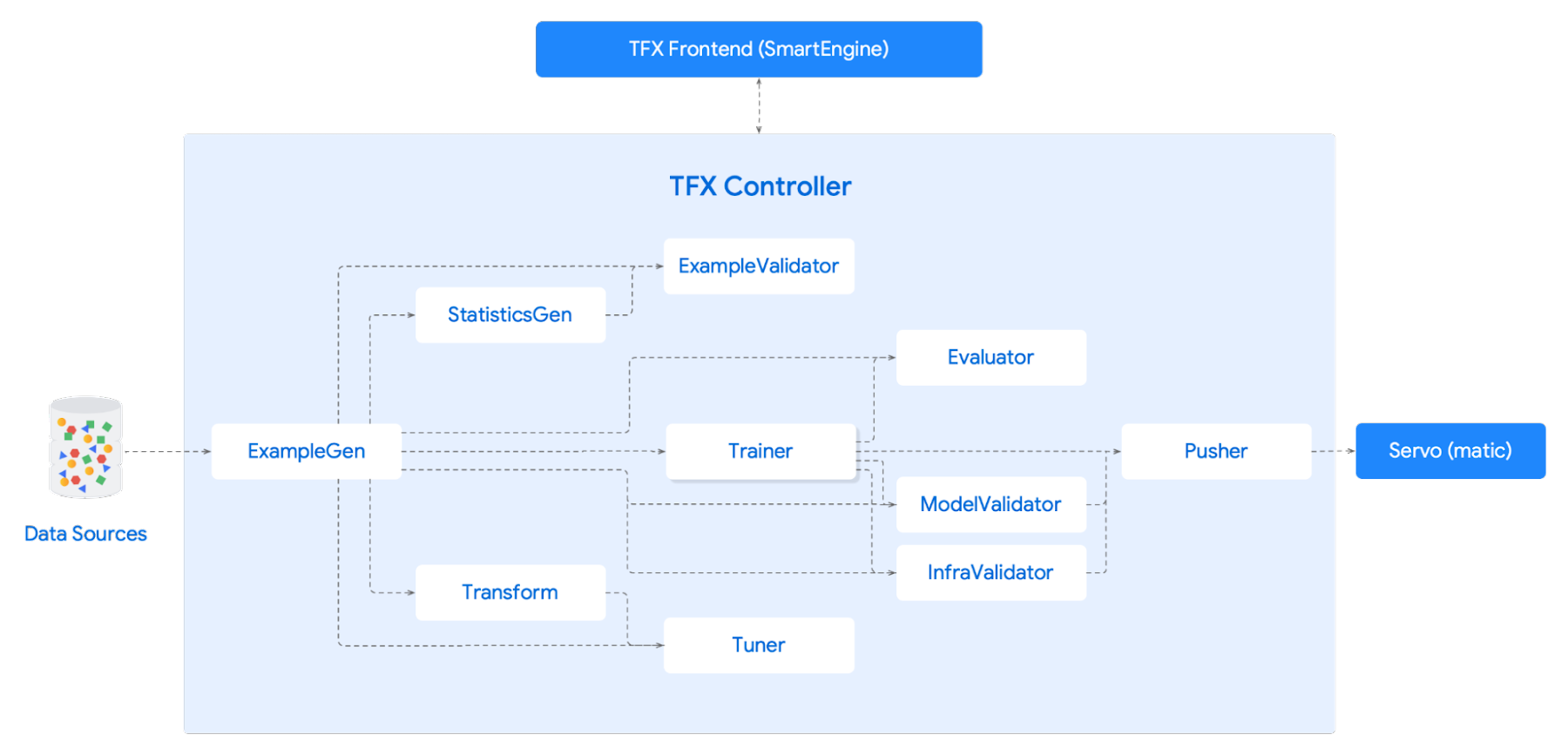
当初のパフォーマンスは予想を下回るものでした。モデルを詳しく調べると、不適切な回答の原因はモデルではなく、入力したデータにあることがわかりました。データの問題だったのです。
エージェントが記事を提案せず、手動で情報を提供したチケットが原因で、トレーニング データにノイズが含まれていました。この問題を解決するために、データセットの一部に人間がラベルを付けて、モデル検証用のチケットとラベルを手作りしました。これにより、極めて精度が高いことがわかっているデータを基に、モデルを調整できました。その結果、モデルが実際にはなかなかのパフォーマンスを発揮していることがわかりました。
もう 1 つの注意点は、役に立たない記事をモデルが提案する場合があることです。このような場合、ユーザーには多少の迷惑がかかる可能性がありますが、問題の解決に大幅な遅れが生じることはありません。自動回答後に問題が未解決のままであれば、人間によるサポートでフォローアップできるからです。
記事の提案を独自に構築する方法
同様のソリューションを作成するには、いくつかの重要な要素が必要です。
データ - Google では数十万の例を使用しているが、データは多ければ多いほど、パフォーマンスが向上する。サポート担当者が既存の記事のリンクを提供して解決したチケットが必要
NLP 対応の ML ライブラリ - 埋め込みまたは bag-of-words 変換を処理できるもの
モデルのサービング - 任意のリクエストに対してモデルを実行し、その結果を返す方法
自然言語モジュールを含む Google の AutoML サービスはすぐに使い始めることができ、この種の拡張機能が Google での例のようにヘルプデスクの役に立つかどうかをすぐにテストできます。Tensorflow を使用した基本的なテキスト分類のチュートリアルをご覧ください。これを BERT で解決して、結果をより迅速に得たい場合は、TPU の使用を試してみてください。
必ず反復処理を行ってください。Google では、最初の試行ではうまくいかず、さまざまなオプションを試したり比較したりして、理想的なソリューションを見つけました。最終目標に焦点を合わせて、試行錯誤することをおすすめします。
- デベロッパーリレーションズ エンジニア Max Saltonstall