本番環境 AI への効率的な道: JAX と Cloud TPU を使用した Kakao の取り組み
Minho Ryu, Nayeon Kim
Language Model Research Engineers, Kakao
Srikanth Kilaru
Senior Product Manager, Google ML Frameworks
※この投稿は米国時間 2025 年 8 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
韓国の人口の 93% にあたる 4,900 万人ものユーザーを抱えるメッセージング プラットフォーム Kakao にとっては、一つひとつの技術的な意思決定に大きな責任が伴います。既存のインフラストラクチャで重大な制限に直面した Kakao のエンジニアリング チームは、この重責をひしひしと実感しました。Kakao の取った解決策は、JAX フレームワークを使用した Google Cloud TPU への戦略的な移行です。これにより当面のスケーラビリティのニーズが解決されただけでなく、高度な AI モデル開発に向けた新たな可能性が開かれました。
Kakao のアプローチは、大規模な AI モデル開発に高パフォーマンスの配列コンピューティング フレームワークである JAX を活用した優れた事例です。主なトレーニング環境は GPU ベースでしたが、同社は費用と効率を最適化するために、Google Cloud TPU で JAX スタックを採用するという戦略的な決定を下しました。
この取り組みが同社独自の Kanana モデル ファミリーの開発の基礎を築き、最近 Kanana-MoE を含むいくつかの Kanana モデルが Hugging Face Hub でオープンソースとしてリリースされました。
この投稿では、Kakao の Ryu Minho 氏と Kim Nayeon 氏が、Kakao の技術的な取り組みについて詳しく説明し、JAX 大規模言語モデル フレームワークと MaxText のカスタムデータ パイプラインへの導入から、混合エキスパート(MoE)モデルのトレーニングに関する作業まで、具体的な実装の詳細をご紹介します。
カカオの取り組み
Kakao のエンジニアとして、私たちはテキストをはるかに超えるサービスを提供するプラットフォームである KakaoTalk に役立つモデルを開発しています。Kakao の豊富なエコシステムには、70 万点以上の画像とステッカー(絵文字)を使用したチャット、音声通話とビデオ通話、金融、ナビゲーションなどが含まれます。

KakaoTalk の規模と複雑さから、当社の言語モデルには高い効率性はもちろんのこと、韓国語への優れた理解や、多様なアプリケーションに対応できる柔軟性が求められます。こうした実世界におけるプロダクト要件が技術的な意思決定に直接影響し、カスタマイズ可能なトレーニング フレームワークが必要であるという判断にもつながりました。
JAX の利用を検討し始めたころ、当社は重要な転換期を迎えており、既存の GPU ベースのインフラストラクチャは、処理能力と予算の容量の上限に達しつつありました。選択肢は 2 つ。GPU インフラストラクチャを拡張して既存のコードベースを維持するか、費用対効果においてメリットを提供する一方、新しいツールチェーンが必要な Cloud TPU を採用するかです。当社は、短期的な投資が長期的な費用対効果のメリットに見合うものと判断して Cloud TPU を選択し、JAX 上にスタックを構築しました。
Kubernetes クラスタの管理には XPK を使用して、Kubernetes の専門知識がなくても、GKE でのジョブの作成と管理が簡単にできるようにしています。データ パイプラインには、決定的な動作をする Grain を採用し、長時間実行される AI モデルのトレーニング ジョブに不可欠な安定性を確保しました。

また、MaxText フレームワークを当社の具体的な研究ニーズと互換性ニーズに合わせて調整することに重点を置き、パイプラインに 2 つの重要なカスタマイズを加えました。
1. マルチソースのデータブレンド: MaxText を使用したトレーニングの検討を始めた当初は、事前に混合された単一のコーパスを想定していました。当社の研究では、さまざまなトレーニング フェーズで、ウェブテキスト、コード、数学などのさまざまなデータソースを、特定の動的に調整された重みでブレンドする必要があります。テストごとにテラバイト単位のデータを再処理することなく、この柔軟性を実現するために、Grain の mix 関数を使用したソリューションを実装しました。このアプローチでは、構成でブレンド比率を定義できるため、反復的な研究プロセスに不可欠な適応性が得られます。MaxText でこの機能をネイティブにサポートするための PR を提出し、それがその後こちらに組み込まれました。

2. 効率と互換性を重視したトークン処理: 既存の Megatron-LM パイプラインとの互換性を維持し、効率を向上させるために、MaxText のトークン処理ロジックを変更しました。Kakao のデータ準備方法では、後続のシーケンスの最初のトークンを追加することで、各トレーニング シーケンスを構築します。これにより、重複する連続したシーケンスが作成され、境界で情報が失われることがなくなり、データ利用が最大化されます。
新しい TPU ベースのワークフローを検証するために、2 つのモデルをトレーニングしました。まず、パラメータ数が 21 億の Kanana モデルをゼロからトレーニングした結果、当社の MaxText 実装は、各段階で既存の GPU ベースの Megatron-LM パイプラインに匹敵するパフォーマンスを達成しました。次に、既存の 8B モデルから 9.8B アーキテクチャへ、事前トレーニングを継続した深度アップスケーリングを行いました。どちらのアプローチも成功し、さまざまなベンチマークで一貫した改善が見られ、GPU での結果が TPU で効果的に再現できることが確認されました。
アプローチの進化: MaxText を使用した混合エキスパート(MoE)モデルのトレーニング
コア パイプラインの検証の完了後、高いパフォーマンスと高い推論効率を両立させたモデルを構築するために、より高度なアーキテクチャ、具体的には MoE モデルのテストを開始しました。目標は、既存の高密度モデルを MoE 構造にアップサイクルできるかどうかを調査し、このタスクに対する TPU と MaxText スタックの適合性を評価することです。
この実験では、2.1B の高密度モデルを、64 のエキスパート(トークンあたり 8 つのアクティブ エキスパート)を持つパラメータ数 134 億(23 億がアクティブ)の MoE アーキテクチャにアップサイクルしました。アーキテクチャの変更による影響を分離するため、モデルのトレーニングには元の高密度モデルとまったく同じデータセットを使用しています。トレーニングは、v5e TPU 上の、完全シャーディング データ並列処理(FSDP)を行う MaxText で実行されました。
実装プロセスは簡単で、Flax、Optax、Orbax 上に構築された MaxText の柔軟な設計が、MoE 研究に必要な幅広いアブレーションに最適であることがわかりました。詳細は以下のとおりです。
-
統合カーネル: Megablocks MoE カーネルは、Group GEMM などの最適化された MoE 機能をサポートしており、すでに JAX に統合されています。
- スケジュールの結合: optax.join_schedules 関数を使用して、複数の学習率スケジュール(ウォームアップ、定数、アニーリングなど)を 1 つのカスタム スケジュールに結合し、トレーニング実行に使用しました。異なるスケジュールを組み合わせることができるため、さまざまなトレーニング戦略を試すのに非常に便利です。

- コードのカスタマイズ: 疎行列乗算の実装で、ロード バランシングの損失を有効にする必要がありました。そのため、MaxText の MoE ブロック内の permute 関数に 1 行のコードを挿入して、ルーターのロジットから直接損失を計算できるようにしました。

結果は、特にコードと数学のベンチマークでパフォーマンスが向上していることを示しており、エキスパートの間でドメインの専門化が進んでいることを示唆しています。

パフォーマンス評価
目標が達成され、高度なモデル開発における JAX スタックの有用性をさらに実証できました。現在、この取り組みをさらに拡大し、共有エキスパートのテストや、初期の MoE レイヤを密なレイヤに置き換えるテストを行っています。これらの変更は、MaxText フレームワーク内で簡単に実装できます。
パフォーマンスの改善と重要なポイント
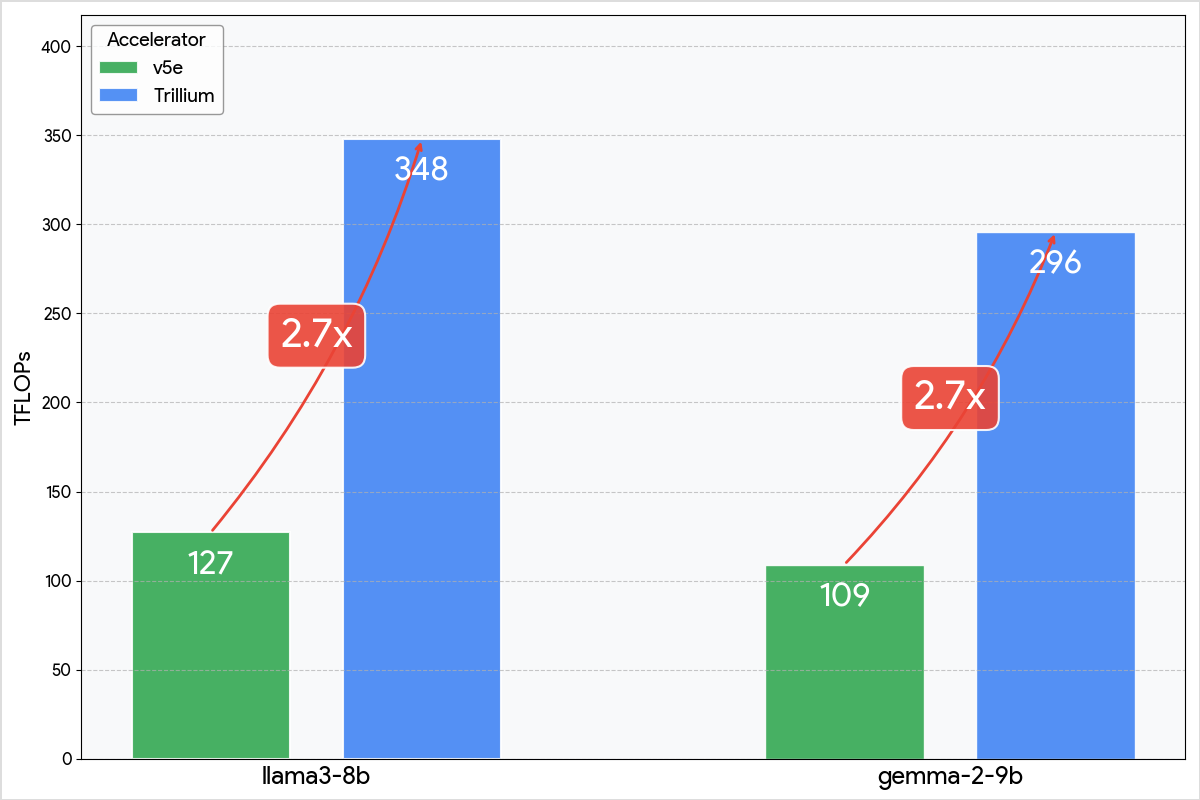
この取り組みの中で、Trillium TPU の早期アクセス権を得ました。XPK クラスタとワークロードの構成でいくつかのパラメータを変更することで v5e からの移行を実現すると、すべてのモデルで、即座にスループットが 2.7 倍と大幅に増加し、費用対効果も向上しました。
当社の経験では、TPU 上の JAX スタックが、AI モデル開発のための包括的かつ効率的な環境を提供することが示されました。チームにとっての主なメリットは次のとおりです。
-
パフォーマンスとスケーラビリティ: JAX と XLA の組み合わせにより、ジャストインタイム コンパイルが実現します。MaxText は、SPMD や FSDP などをサポートする大規模な並列コンピューティング向けに最適化されています。
-
カスタマイズ性と制御性: コードベースは純粋な Python であり、Flax、Optax、Orbax などのライブラリ上に構築されているため、直感的で簡単に変更できます。これにより、最小限のオーバーヘッドでカスタム データ パイプライン、トレーニング戦略、新しいアーキテクチャを実装することが可能になります。
-
機能の迅速な導入: MaxText フレームワークは、最先端の新しいモデルの機能で迅速に更新されるため、常に最先端の研究を行うことが可能です。
こうした強みがあってこそ、JAX スタックは Kakao で大規模言語モデルをトレーニングするための、強力かつ柔軟な基盤となっているのです。
JAX エコシステムで言語モデルを構築する
Kakao の取り組みは、MaxText、Flax、Optax、Orbax などの JAX エコシステムのモジュール設計が、カスタマイズされたデータブレンドから MoE アーキテクチャを使用した迅速なテストまで、本番環境パイプラインと高度な研究の両方に必要なカスタマイズ性をどのように実現するかを示しています。
貴重なエンジニアリングの取り組みを共有してくださった Ryu 氏、Kim 氏、そしてそのチームに心より感謝申し上げます。Google は、このように世界中の大手企業が、JAX エコシステムを使用して次世代の強力かつ効率的な言語モデルを構築していくのを楽しみにしています。
ー Kakao、言語モデル リサーチ エンジニア Ryu Minho 氏、Kim Nayeon 氏
ー Google ML フレームワーク、シニア プロダクト マネージャー Srikanth Kilaru