Searce と連携して PostgreSQL から Cloud SQL へのテラバイト規模の移行を最適化する

Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud では、Database Migration Service(DMS)を使用して PostgreSQL データベースを Cloud SQL へ移行できます。DMS を使用すると、移行元が本番環境で稼働している間に、継続的に移行先のデータベースにデータを複製することが可能になるため、ダウンタイムを最小限に抑えながら移行できます。
しかし、テラバイト規模の移行は複雑になる可能性があります。たとえば、使用している PostgreSQL データベースに ラージ オブジェクトが含まれている場合、DMS の制限により、それらのラージ オブジェクトを手動で移行するためのダウンタイムが必要になります。DMS には他にもいくつかの制限があります。詳しくは、 DMS の既知の制限事項をご確認ください。これらの手順で慎重に対処しなければ、カットオーバー中のダウンタイムが長引き、移行元のインスタンスのパフォーマンス低下や、プロジェクト納期の遅延につながるおそれがあります。つまり、ビジネスに深刻な影響が及んでしまうかも知れません。
Searce は、クラウド、データ、AI を活用してアプリケーションやデータベース インフラストラクチャをモダナイズすることを専門分野とする、テクノロジー コンサルティング企業です。Searce は、ビジネスの未来に向かって加速できるようにお客様のサポートを行っています。これまでに多くのお客様の Cloud への移行をサポートしてきましたが、先に述べた理由のとおり、テラバイト規模の移行が最も困難を極めるものでした。
このブログ投稿では、ある企業のお客様をサポートした Searce の取り組みを中心に取り上げます。このお客様は、数十テラバイト規模のミッション クリティカルな PostgreSQL データベースを、最小限のダウンタイムで Cloud SQL に移行することを希望されていました。データベースのサイズは最大 20 TB で、すべてのデータベースにラージ オブジェクトを保存したテーブルが含まれていました。また、テーブルには主キーがないものもありました。なお、このプロジェクトが進行していた当時、DMS は主キーのないテーブルの移行をサポートしていない、という制限がありました。主キーのないテーブルの移行をサポートする拡張機能は、2022 年 6 月にリリースされました。
このブログでは、お客様の移行にベスト プラクティスを取り入れていただけるように、Searce がこれまでに得た移行の簡素化や最適化の方法についての知見をお伝えします。ここでは、自動化スクリプトを使用して、DMS で処理されないオペレーションに要するダウンタイムを最大 98% 削減するメカニズムを探ります。また、DMS のパフォーマンスを最適化して、移行にかかる総時間数を最大 15% 短縮できる、PostgreSQL のデータベース フラグについても詳しく見ていきます。
データベース フラグを使用した DMS パフォーマンスの最適化
このお客様が PostgreSQL データベースを Google Cloud SQL に移行することを決定した後、ビジネスへの影響を決定する、移行作業と移行時間という 2 つの重要な要因について検討しました。PostgreSQL データベースの移行にかかる労力を最小限に抑えるために、Google Cloud の DMS(Database Migration Service)を活用しました。このプロダクトは非常に使いやすく、 移行元のデータベースが本番環境で稼働している間に、移行元のデータベースから移行先の Cloud SQL インスタンスにデータを継続的に複製することで手間のかかる作業を行ってくれるためです。
移行時間についてはどうなったでしょう?テラバイト規模のデータベースの場合、データベースの構造によっては、移行が大幅に長時間化する可能性があります。長年の経験から、DMS では 1 TB のデータベースを移行するのに約 3 時間かかることがわかりました。お客様のデータベース構造がより複雑な別の事例では、移行により多くの時間がかかりました。幸いなことに、DMS は移行元データベースが本番環境で稼働している間にこのレプリケーションを実行するため、このときダウンタイムは必要ありません。それでも、お客様は移行元データベースと移行先データベースの両方の費用を負担する必要があり、大規模なデータベースの場合は相当な額になる可能性がありました。一方、データベースのサイズが大きくなると、レプリケーションにさらに多くの時間を要することになり、カットオーバーのオペレーション中に発生するダウンタイムが原因でお客様のメンテナンスの時間枠を逃してしまうリスクが高まりました。このお客様のメンテナンスの時間枠は 1 か月ごとに設定されていたため、次のメンテナンスの時間枠までさらに 30 日間待たなければならず、お客様はその 30 日分について両方のデータベースの料金を負担しなければならない状況でした。さらに、リスク管理の観点から言うと、移行期間が長くなるほど、問題発生のリスクが高まります。そのため、移行時間を短縮できるオプションを検討し始めました。移行時間をほんのわずか短縮するだけでも、コストとリスクを大幅に削減できます。
移行元データベースでの PostgreSQL データベース フラグの調整に関するオプションを調査しました。DMS では、一連の前提条件フラグが移行元のインスタンスとデータベース向けに独自に用意されています。また、shared_buffers、wal_buffers、maintenance_work_mem を活用して DMS によるレプリケーション プロセスを高速化できることがわかりました。これらのフラグの利点を最大限に引き出すためには、それぞれに特定の値を設定する必要があります。設定後、こうしたフラグの累積的な効果により、DMS が 1 TB のデータベースのレプリケーションにかかる時間が最大 4 時間削減されました。つまり、データベースが 20 TB の場合は 3.5 日も削減できることになります。それぞれについて詳しく見ていきましょう。
共有バッファ
PostgreSQL は、2 つのバッファ(独自の内部バッファとカーネル バッファ IO)を使用します。つまり、そのデータはメモリに 2 回保存されます。この内部バッファは shared_buffers と呼ばれ、データベースがオペレーティング システムのキャッシュに使用するメモリの量を決定します。このバッファのデフォルト値は、低く抑えて設定されています。しかし、ユースケースに合うように移行元データベースでこの値を大きくすると、読み取り負荷の高いオペレーションのパフォーマンスが向上しました。これは、ジョブが初期化されたときに DMS が行う動作とまったく同じです。
何度か反復処理を行ったところで、この値をデータベース インスタンス RAM の 55% に設定すると、レプリケーション パフォーマンス(読み取り負荷の高いオペレーション)が大幅に向上し、データのレプリケーションに必要な時間が短縮されることがわかりました。
WAL バッファ
PostgreSQL では、ログ先行書き込み(WAL)によってデータの整合性を確保しています。WAL レコードはバッファに書き込まれ、その後ディスクにフラッシュされます。フラグ wal_buffers は、まだディスクに書き込まれていない WAL データ(まだフラッシュされていないレコード)に使用する共有メモリの容量を決定します。wal_buffers の値を、デフォルト値の 16 MB から、データベース インスタンスの RAM の約 3% に増やすことで、トランザクションの commit ごとにディスクに書き込まれるファイル数は減りますが、サイズが大きくなるため、書き込みパフォーマンスが大幅に向上することがわかりました。
メンテナンス作業メモリ
PostgreSQL のメンテナンス オペレーション(VACUUM、CREATE INDEX、ALTER TABLE ADD FOREIGN KEY など)は、それぞれが特定のメモリを消費します。このメモリは maintenance_work_mem と呼ばれます。他のオペレーションとは異なり、PostgreSQL のメンテナンス オペレーションは、データベースによる段階的な実行にのみ対応しています。デフォルト値である 64 MB よりもかなり大きい値を設定すると、メンテナンス オペレーションが DMS ジョブをブロックしなくなります。maintenance_work_mem は、値が 1 GB のときに最適に機能することがわかりました。
移行元インスタンスのサイズを変更してパフォーマンスへの影響を回避
これら 3 つのフラグは、PostgreSQL がメモリリソースをどのように使用するかを調整します。そのため、これらのフラグを設定する前に、移行元のデータベース インスタンスをサイズアップして、フラグに対応できるようにする必要がありました。これらのフラグが管理するプロセスにデータベース メモリの合計の半分以上が割り当てられるため、データベース インスタンスのサイズを大きくしなければ、アプリケーションのパフォーマンスが低下する可能性がありました。
前述のフラグが必要とするメモリを計算したところ、フラグに設定されている既存の値に関係なく、各フラグを移行元インスタンスのメモリに対して特定の割合に設定する必要があることがわかりました。
- shared_buffers: 移行元インスタンスのメモリに対して 55%
- wal_buffers: 移行元インスタンスのメモリに対して 3%
- maintenance_work_mem: 1 GB
フラグごとにそれぞれのメモリ要件を追加したところ、RAM の 58% 以上をこれらのメモリフラグが消費していることが明らかになりました。たとえば、移行元インスタンスが 100 GB のメモリを使用した場合、58 GB を shared_buffers と wal_buffers が、さらに 1 GB を maintenance_work_mem が占有することになります。これらのフラグの初期値は 200 MB と大変低かったため、移行が本番環境のアプリケーションのソース パフォーマンスに影響を与えないようにするために、移行元データベースのインスタンスの RAM を 60% 拡大しました。
WAL 送信者タイムアウト フラグで接続エラーを防止
Google Cloud の DMS を使用しているときに、DMS ジョブが「完全なダンプの処理中」に DMS と Cloud SQL インスタンス間の接続が切断された場合、その DMS ジョブは失敗するため、最初から始めなければなりません。特にテラバイト規模のデータベースの移行中にタイムアウトが発生すると、数日分の移行が失われ、カットオーバー計画が遅れることになります。たとえば、20 TB のデータベースを移行する DMS ジョブの接続が開始から 10 日後に失われた場合、DMS ジョブを最初からやり直す必要があり、10 日分の移行作業が失われることになります。
WAL 送信者のタイムアウト フラグ(wal_sender_timeout)を調整することで、完全なダンプ処理のフェーズで長時間非アクティブだったレプリケーション接続が中断するのを回避できました。このフラグのデフォルト値は 60 秒です。これらの接続が中断するのを回避し、このような影響の大きい障害を防止するために、データベースの移行中はこのフラグの値を 0 に設定します。こうすることで、接続が切断されるのを防ぎ、DMS ジョブによるスムーズなレプリケーションが可能になります。
通常、ここで説明したすべてのデータベース フラグについて、移行の完了後にはデフォルトのフラグ値に戻すようお客様にアドバイスしました。
DMS の制限によって必要となるダウンタイムを自動化で削減
DMS は、移行元データベースのインスタンスが本番環境で稼働している場合、連続してレプリケーションを行うことでデータベース移行の大部分を実行します。ただし、DMS にはデータベースが稼働している場合に対処できない特定の移行制限があります。PostgreSQL の DMS での既知の制限事項には次のものが含まれます。
- DMS ジョブが初期化された後に移行元の PostgreSQL データベースで新しく作成されたテーブルは、移行先の PostgreSQL データベースには複製されません。
- 移行元の PostgreSQL データベースの主キーのないテーブルは移行されません。これらのテーブルに関して、DMS はスキーマのみを移行します。なお、2022 年 6 月の製品アップデート以降、この制限は解消されています。
- ラージ オブジェクト(LOB)データ型は DMS ではサポートされていません。
- マテリアライズド ビューはスキーマのみが移行され、データは移行されません。
- 移行されたすべてのデータは、cloudsqlexternalsync のオーナー権限のもとに作成されます。
データベース移行のこれらの制限に関しては、手動で対応する必要がありました。このお客様の場合、ラージ オブジェクト データ型、主キーのないテーブル、DMS では移行できない頻繁に変わるテーブル構造がデータベースに含まれていたため、DMS で残されたデータ移行のほとんどの部分を行った後、手動でそれらのデータを移行しなければなりませんでした。この部分のデータベース移行では、データの損失を避けるためにダウンタイムが必要でした。テラバイト規模のデータベースでは、このデータは数百 GB におよぶ可能性があるため、移行時間が長くなり、その結果ダウンタイムも長時間化します。さらに、移行対象のデータベース数が多い場合、カットオーバー期間中に人間がこれらの操作を行うと、負荷がかかりエラーが発生しやすくなる可能性があります。
そこで窮地を救ったのが自動化でした。ダウンタイム期間中の移行作業を自動化することで、手作業にかかる労力やエラーのリスクが軽減されただけでなく、何百もの PostgreSQL データベースのインスタンスを Cloud SQL に移行するために活用できるスケーラブルなソリューションも使用できるようになりました。さらに、マルチプロセスとマルチスレッドを活用することで、数百 GB のデータの移行での合計ダウンタイムを 98% 削減し、お客様のビジネスへの影響を軽減できました。
実現方法
ダウンタイム中、つまり、DMS ジョブが移行元からターゲットへのレプリケーションを完了してから、移行されたデータベースにアプリケーションをカットオーバーするまでの間に実行する必要があるすべての手順をレイアウトしました。図 1 に、ダウンタイム期間中に実行される一連のオペレーションをマッピングしたチャートを示します。
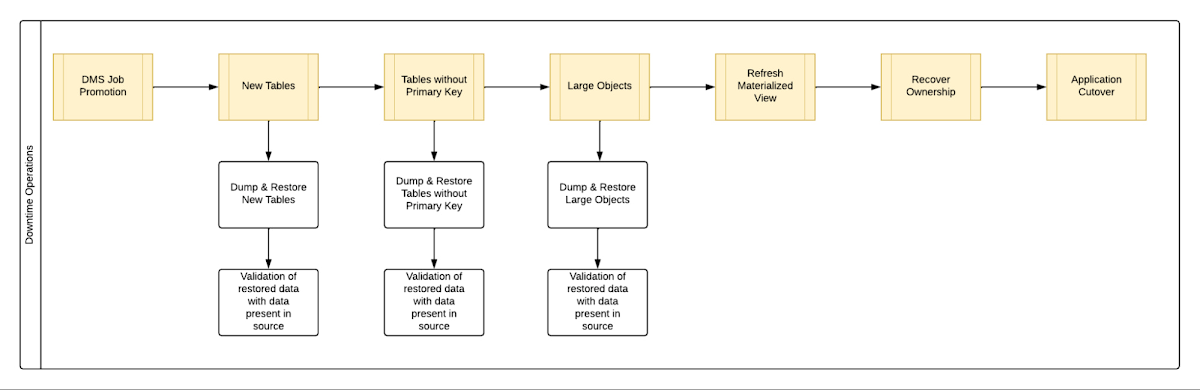
この段階的アプローチでのすべてのダウンタイム オペレーションを自動化することにより、1 TB のデータベースでは、ダウンタイム フロー全体を実行するのに 13 時間かかることがわかりました。これには、新しいテーブルの 250 MB、主キーのないテーブルの 60 GB、ラージ オブジェクトの 150 GB の移行が含まれます。
観測で得られた重要な事実の一つは、すべてのステップのうち、ほとんどの時間を費やしたのは、新しいテーブルの移行、主キーなしのテーブルの移行、および大きなオブジェクトの移行の 3 つのステップだけだったということです。これらすべてのステップで、それぞれのテーブルのダンプおよび復元オペレーションを行う必要があったため、最も時間がかかりました。ただし、これらの 3 つの手順は、個々に異なるテーブルを対象としているため、相互に強い依存関係はありませんでした。そのため、図 2 に示すように、それらの手順を並行して実行してみました。しかし、それに続く手順、つまり「マテリアライズド ビューのリフレッシュ」と「所有権の回復」は、データベース全体を対象としているため、段階的に実行する必要がありました。
ただし、これら 3 つのステップを並行して実行するには、各ステップで十分なリソースを利用できるように Cloud SQL インスタンスのサイズを大きくする必要がありました。これにより、Cloud SQL インスタンスの vCPU を 50%、メモリを 40% 増やすことができました。これは、エクスポートとインポートのオペレーションがメモリ消費ではなく vCPU 消費に大きく依存しているためです。
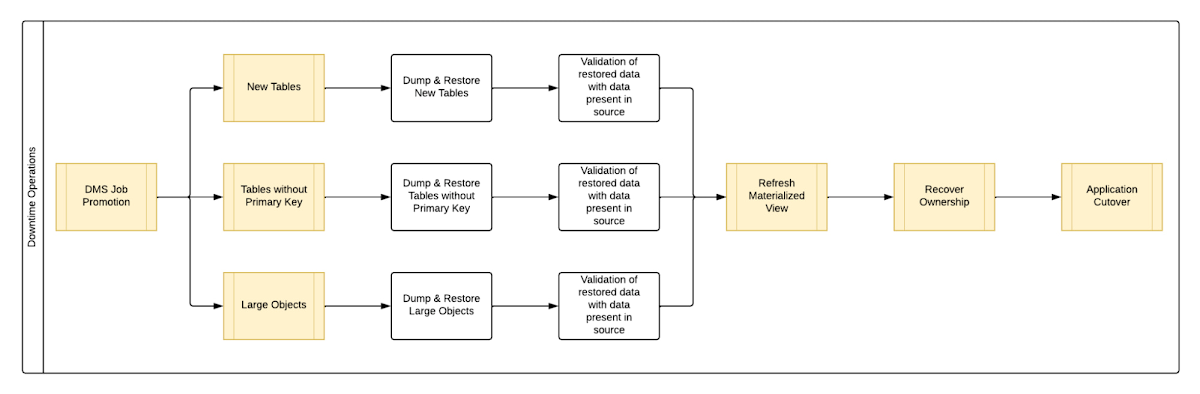
図 2: ダウンタイムの移行 - ハイブリッド アプローチ
新しいテーブル(DMS ジョブが開始された後に作成されたテーブル)と主キーのないテーブルの移行は、PostgreSQL が提供するネイティブ ユーティリティ(pg_dump と pg_restore)を利用できるため簡単でした。どちらのユーティリティも、複数のスレッドを使用してテーブルを並行して処理します。つまり、テーブル数が多いほど、並行して実行できるスレッドの数が多くなり、移行を高速化できます。この修正版のアプローチでは、同じ 1 TB のデータベースで、ダウンタイム フロー全体を実行するのに 12.5 時間かかりました。
この改善により、カットオーバー中のダウンタイムが短縮されましたが、すべての手順を完了するには 12.5 時間の期間が必要であることがわかりました。その後、ダウンタイムの時間の 99% が、150 GB のラージ オブジェクトのエクスポートとインポートというたった 1 つのステップで占められていることを発見しました。マルチスレッドは、ダンプを高速化して PostgreSQL のラージ オブジェクトを復元するのには使用できないことが明らかになりました。そのため、ラージ オブジェクトを単独で移行すると、移行のダウンタイムが数時間延長されました。幸い、私たちはその回避策を見つけることができました。
ラージ オブジェクトの PostgreSQL データベースからの移行を最適化
PostgreSQL には、特別なラージ オブジェクト構造に保存されたデータにストリーム様式で接続できるラージ オブジェクト機能が備わっています。ラージ オブジェクトは、保存時に複数のチャンクに分割され、データベースのさまざまな行に格納されますが、単一のオブジェクト ID(OID)によって接続されます。この OID は、保存された任意のラージ オブジェクトへのアクセスに使用できます。ユーザーはデータベース内の任意のテーブルにラージ オブジェクトを追加できますが、PostgreSQL の内部では、データベース内のラージ オブジェクトをすべて pg_largeobjects と呼ばれる単一のテーブルに物理的に格納します。
ラージ オブジェクトのエクスポートとインポートに pg_dump と pg_restore を利用している間、この 1 つのテーブル(pg_largeobject)がボトルネックになります。これは、PostgreSQL ユーティリティが 1 つのテーブルであり、並列処理のために複数のスレッドを実行できないためです。通常、これらのユーティリティのオペレーション順序は次のようになります。
1. pg_dump がエクスポート対象のデータを移行元のデータベースから読み取る
2. pg_dump が実行されているクライアントのメモリに、pg_dump がそのデータを書き込む
3. pg_dump がメモリからクライアントのディスクに書き込む(2 回目の書き込みオペレーション)
4. pg_restore がクライアントのディスクからデータを読み取る
5. pg_restore が移行先データベースにデータを書き込む
通常、これらのユーティリティは、競合するプロセスによるデータの損失やデータの破損を避けるために、段階的に実行する必要があります。これにより、ラージ オブジェクトの移行時間がさらに長くなります。
このシングルスレッド プロセスのための回避策として、2 つの要素を取り入れました。まず、Searce のソリューションによって、2 回目の書き込み、つまりメモリからディスクへの書き込み(上記 3 番目)オペレーションを排除しました。代わりに、データの読み取りとメモリへの書き込みが完了すると、プログラムはインポート プロセスを開始し、データを移行先データベースに書き込みます。次に、pg_dump と pg_restore では複数のスレッドを使用して pg_largeobjects テーブル内のラージ オブジェクトを処理することができなかったため、マルチスレッドを使用できるソリューションを開発することにしました。スレッド数は、テーブル内の OID の数(pg_largeobjects)に基づいており、その単一のテーブルを並列実行のために小さなチャンクに分割しました。
このアプローチにより、ラージ オブジェクトの移行オペレーションが数時間から数分に短縮されたため、同じ 1 TB のデータベースの場合、DMS で処理できないすべてのオペレーションを完了するために必要なダウンタイムが 13 時間からわずか 18 分に短縮されました。必要なダウンタイムが 98% 短縮されたことになります。
まとめ
最適化とドライランを何回も実行し、お客様がビジネスへの影響を最小限に抑えながら数十テラバイト規模の PostgreSQL データベースを Google Cloud SQL に移行するための手順を開発できました。データベース フラグを使用して DMS ベースの移行を 15% 最適化し、自動化とイノベーションを利用してダウンタイムを 98% 削減する手法を開発しました。これらのプラクティスを、PostgreSQL データベースから Google Cloud SQL へのテラバイト規模の移行に活用することで、移行を加速し、ダウンタイムを最小限に抑え、ミッション クリティカルなアプリケーションのパフォーマンスへの影響を回避できます。
- Searce テクニカル プログラム マネージャー Chinmay Joshi
- Searce クラウド アーキテクト Karan Kaushik
