Dataform 用に SQL を SQLX に変換する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 2 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
SQL での開発には、他の言語やフレームワークと比較して大きな問題があります。異なるスクリプトでステートメントを再利用することは容易ではなく、データの整合性を確保するテストを作成する方法が用意されていません。また、依存関係の管理には外部のソフトウェア ソリューションが必要になります。開発者は通常、何千行もの SQL を記述して、データが正しい順序で処理されるようにします。また、ドキュメントやメタデータについては、外部カタログで管理する必要があるため、後で作成することになります。
こうした問題を解決するため、Google Cloud は Dataform と SQLX を提供しています。
Dataform は、データ アナリストが BigQuery でデータ変換を行う複雑な SQL ワークフローをテスト、開発、デプロイするためのサービスです。Dataform を使用すると、データ統合の ELT(抽出、読み込み、変換)プロセスにおけるデータ変換を管理できます。また、ソースシステムから抽出して BigQuery に読み込んだ元データを、明確に定義、テスト、ドキュメント化した一連のデータテーブルに変換できます。
SQLX は SQL のオープンソース拡張機能で、Dataform で主要なツールとして使われています。SQLX は SQL の拡張機能であるため、SQL ファイルはすべて、有効な SQLX ファイルでもあります。SQLX は SQL に追加機能を提供し、開発の高速化、信頼性とスケーラビリティの向上を実現します。依存関係管理、自動データ品質テスト、データのドキュメント化などの機能も用意されています。
SQL を素早く SQLX に変換すれば、Dataform が提供するメリットをすべて享受できます。このブログ投稿では、入門ガイドを通じてこのプロセスの概要をご説明します。
このガイドの手順では、Google Cloud コンソールで Dataform を使用します。以下の手順をそのまま行っても、独自の SQL スクリプトに実装してもかまいません。
はじめに
以下は、SQLX に変換する SQL スクリプトの例です。このスクリプトは、Reddit のデータを格納したソーステーブルを作成します。データをクリーンアップして重複を除去し、パーティションのある新しいテーブルに挿入します。
1. SQLX ファイルを新規作成して SQL を追加する
このガイドでは、SQLX ファイルを comments_partitioned.sqlx という名前にします。
以下のように、依存関係グラフにはあまり情報がありません。
2. DDL を削除して SELECT のみを使用するよう SQL をリファクタリングする
SQLX では、SELECT ステートメントしか記述しません。ビューやテーブルなど、スクリプトの出力を何にするかは、config ブロックで指定します。他の出力タイプも指定できます。CREATE OR REPLACE や INSERT のような定型ステートメントの追加は、Dataform が行います。
3. メタデータを含む config オブジェクトを追加する
config オブジェクトには、出力タイプ、説明、スキーマ(データセット)、タグ、列とその説明、BigQuery 関連の構成が含まれます。以下の例をご覧ください。
4. 任意のソーステーブルの宣言を作成する
今回の SQL スクリプトでは、reddit_stream.comments_stream を直接記述しています。SQLX では宣言を使用して、ソースデータと Dataform で作成したテーブルの間の関係を構築します。この宣言を行うため、プロジェクトに以下の comments_stream.sqlx ファイルを新たに追加します。
この宣言を次の手順で使用します。
5. 宣言、テーブル、ビューへの参照を追加する
これは、依存関係グラフの構築に役立ちます。今回の SQL スクリプトでは、宣言への参照は 1 つだけです。単純に reddit_stream.comments_stream を ${ref("comments_stream")} に置き換えます。
ref 関数を使って依存関係を管理することには、多くの利点があります。
依存関係ツリーがシンプルになります。開発者は
ref関数を使って依存関係を列挙するだけで済みます。千行単位の長いクエリではなく、より小さくて再利用性の高い、モジュール化されたクエリを記述できます。そのため、パイプラインのデバッグが容易になります。
依存関係の欠落や循環的な依存関係といった問題について、リアルタイムでアラートを受け取ることができます。
6. データ検証のアサーションを追加する
SQLX ファイルの config ブロックから直接、アサーションと呼ばれるデータ品質テストを定義できます。アサーションを使用すると、一意性、null 値、任意のカスタムの行条件をチェックできます。依存関係ツリーでは、可視性のためのアサーションを追加します。
今回の例のアサーションは、以下のようになります。
このアサーションでは、comment_id が一意のキーで、comment_text が null ではなく、すべての行の total_words が 0 より大きい場合に合格します。
7. 再利用可能な SQL とパラメータ化のために JavaScript を使用する
今回の例では、重複除去の SQL ブロックを使用しています。ここで、他の SQLX ファイルでこの機能を参照するための JavaScript 関数を作成することをおすすめします。このシナリオでは includes フォルダを作成し、以下の内容の common.js ファイルを追加します。
これで SQLX ファイル内で、このコードブロックを以下のような関数呼び出しに置き換えることができます。
${common.dedupe("t1", "comment_id")}
場合によっては、SQLX ファイルで定数を使用したいときがあります。その場合は、constants.js ファイルを includes フォルダに追加し、コストセンター ディクショナリを作成しましょう。
これを使用して、BigQuery の出力テーブルにコストセンターのラベルを付けます。以下は、SQLX の config ブロックで定数を使用する例です。
8. 最終的な SQLX ファイルとコンパイルされた依存関係グラフを検証する
上記の手順が完了したら、最終的な SQLX ファイルを確認しましょう。
comments_stream.sqlx
comments_partitioned.sqlx
依存関係グラフを検証し、演算の順序が正しく見えることを確認しましょう。
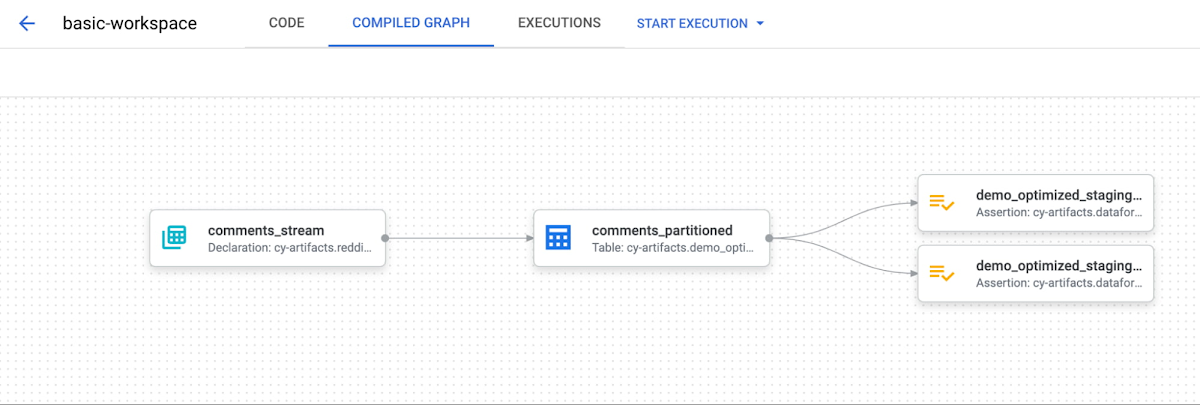
これで、ソースデータ、comments_partitioned の出力タイプ、実行されるデータ品質テストを簡単に可視化できるようになりました。
次のステップ
このガイドでは、レガシー SQL ソリューションを SQLX と Dataform に移行し、メタデータ管理の改善、包括的なデータ品質テスト、効率的な開発を行うための最初の手順を概説しました。Dataform を導入すると、クラウド データ ウェアハウスのプロセス管理が効率化されるため、分析に注力し、インフラストラクチャ管理の負担を軽減できるようになります。詳細については、Google Cloud の Dataform の概要をご覧ください。また、Dataform の公式ガイドと Dataform のサンプル スクリプト ライブラリでは、さらに実践的に学ぶことができます。
- 戦略的クラウド エンジニア、Christian Yarros
- Cloud テクニカル レジデント、Kidus Adugna




