GKE ワークロードのサイズ適正化を利用したリソース使用率の確認と修正
Google Cloud Japan Team
※この投稿は米国時間 2023 年 3 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
クラウドに移行するビジネスが増えるにつれて、Kubernetes はコンテナ化アプリケーションを効率的に管理およびスケーリングできるプラットフォームとして人気を集めるようになりました。Kubernetes への移行でよく直面する問題の一つに、ワークロードの不適切なサイズ設定が挙げられます。この問題は、ワークロードの信頼性とパフォーマンスの低下や、リソースの浪費と費用高騰の原因になるアイドル状態のクラスタの放置につななります。
GKE には、プロジェクト内にあるクラスタのワークロードのサイズを適正化できるツールが組み込まれています。このブログでは、GKE の組み込みツールを使用して、複数のプロジェクトおよびクラスタ間で横断的かつ大規模に、費用、パフォーマンス、信頼性を最適化する方法をご紹介します。なかでも、ワークロードのサイズ適正化と、アイドル状態のクラスタの特定に焦点を当てます。
大規模なワークロードのサイズ適正化に関する推奨事項
VerticalPodAutoscaler(VPA)の最適化案インテリジェンス ダッシュボードは、Cloud Monitoring が提供するインテリジェントな推奨事項を GKE 費用最適化のベスト プラクティスと組み合わせて使用するもので、次のような疑問の解決に役立ちます。
ワークロードのサイズ適正化に投資する価値はあるか
ワークロードのサイズ適正化にはどの程度の労力が必要か
どこから着手するとよいか
プロビジョニングが過剰または不十分なワークロードはそれぞれいくつあるか
不正確にリクエストされたリソースのために、信頼性やパフォーマンスのリスクにさらされているワークロードはいくつあるか
ワークロードのサイズ適正化を以前より効果的に行えているか
ダッシュボードには、すべてのプロジェクトのすべてのクラスタの概要が 1 か所に表示されます。リソースの使用状況を最適化するためには、リソースのリクエストを調整する前に、ワークロードに実際に何が必要かをしっかりと把握しておいてください。
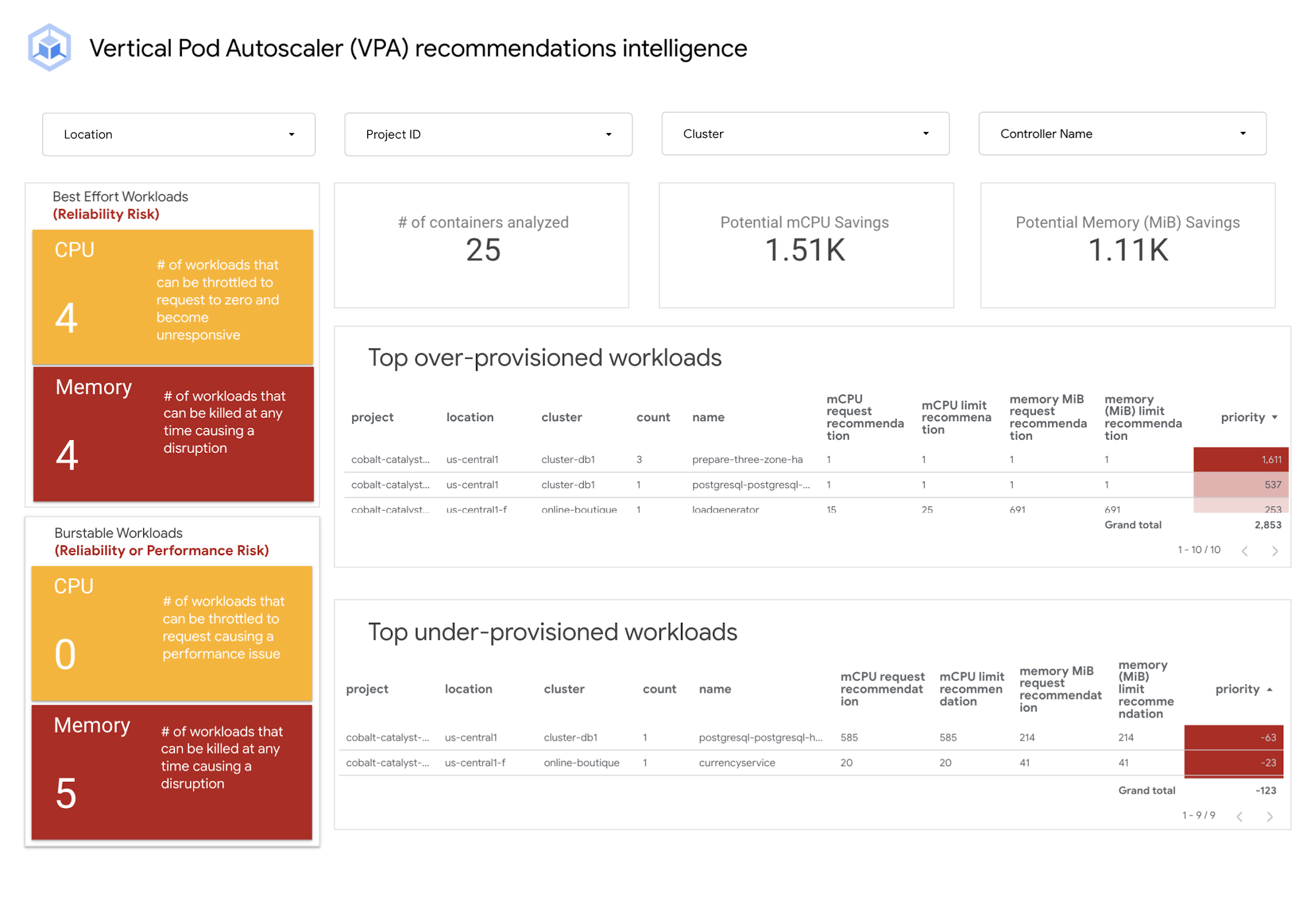
次のセクションでは、ダッシュボードの概要と、最適化の工程におけるデータの使用方法について説明します。
ベスト エフォート型ワークロード(信頼性のリスク)
リソースのリクエストや上限が構成されていないワークロードは、メモリ不足や、CPU のスロットリングがゼロになることにより、失敗する危険性が高くなります。
改善する方法
1. VPA コンテナ推奨事項の詳細ビュー ダッシュボードに移動します。
2. メモリフィルタの [QoS] を使用し、[BestEffort] でフィルタします。
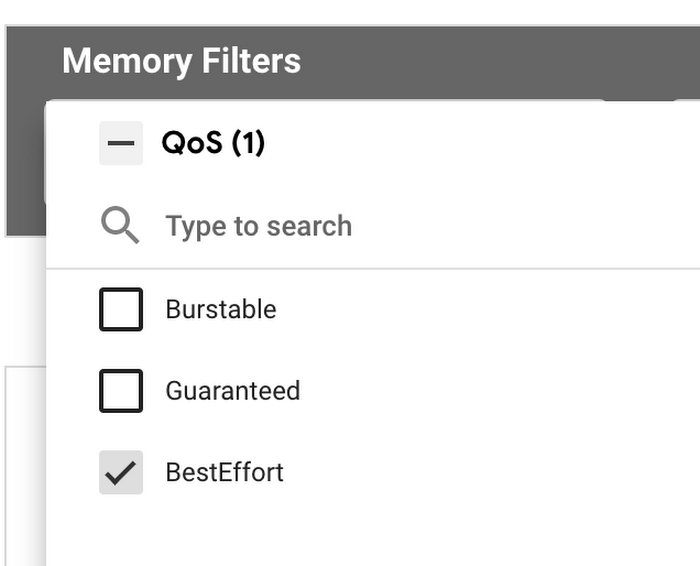
フィルタ結果から、どのワークロードのリソースに更新が必要かを特定できます。
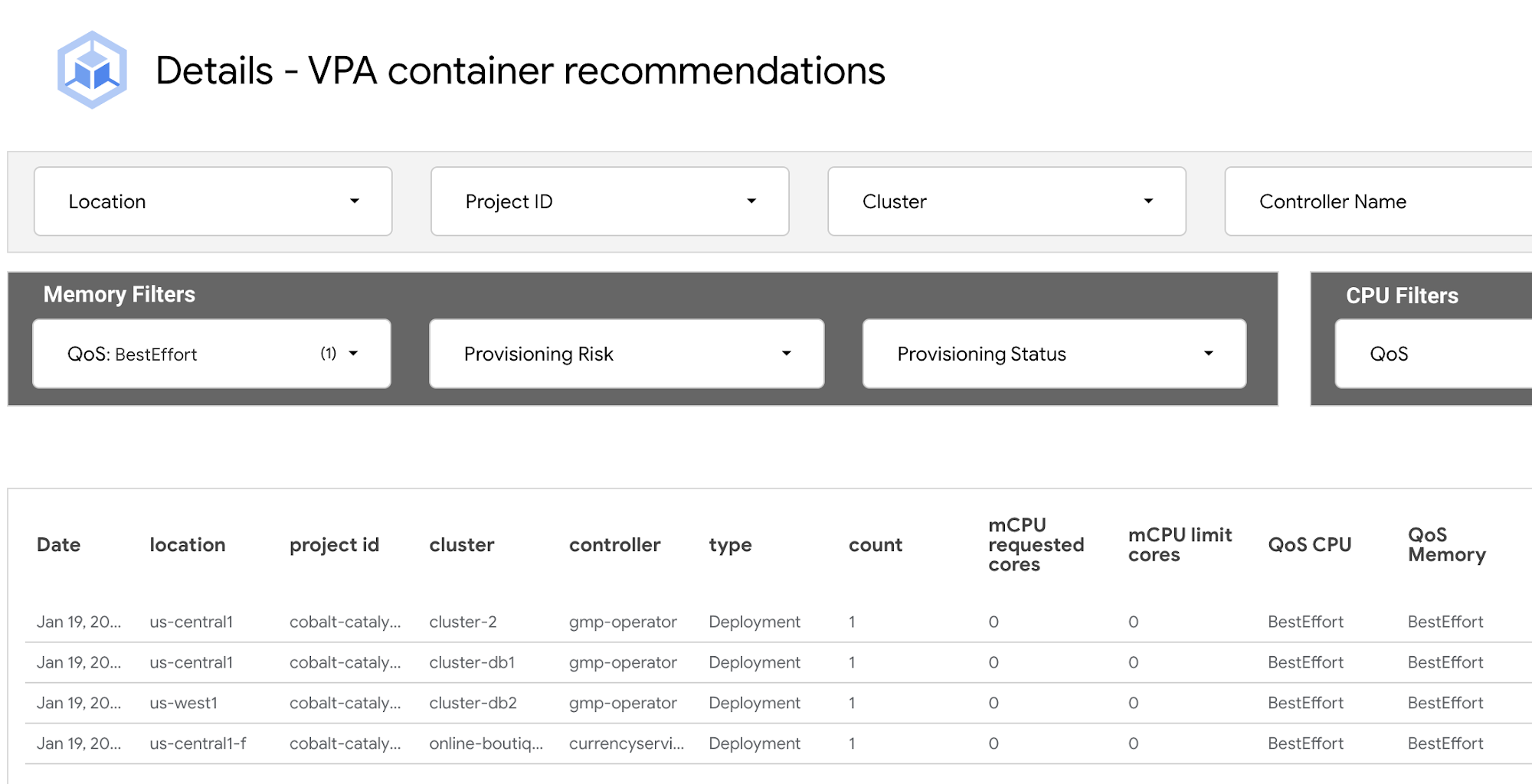
CPU やメモリリソースの更新は、アプリケーションやサービスのパフォーマンスをモニタリングしながら、段階的に少しずつ行うことをおすすめします。フィルタ結果に表示されたワークロードを更新するには:
3. この [memory (MiB) request recommendation] と [memory (MiB) limit recommendation] の値を使用して、メモリのリクエストと上限を設定します。メモリの構成におけるベスト プラクティスは、リクエストと上限を同量に設定することです。注: メモリユニットの値はすべて MiB 単位です。
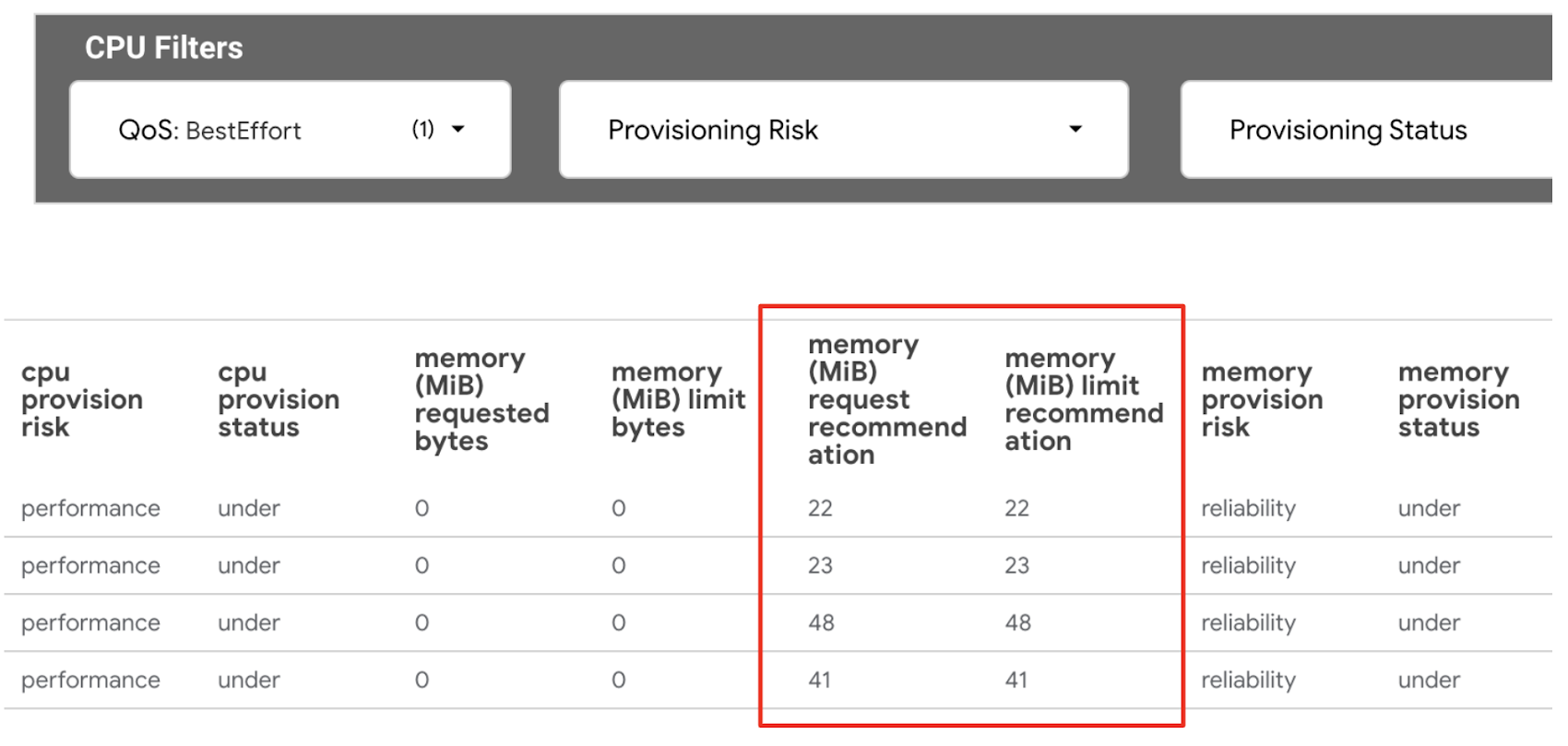
CPU の BestEffort ワークロードを特定するには:
4. CPU フィルタの QoS を [BestEffort] に設定し、[mCPU request recommendation] と [mCPU limit recommendation] の値をメモします。注: CPU の値はすべてミリコア単位です。

5. デプロイメントで、CPU のリクエストを mCPU request recommendation の値以上に設定し、CPU の上限を mCPU limit recommendation の値にするか、無制限のままにします。
バースト可能なワークロード(信頼性またはパフォーマンスのリスク)
CPU のバースト可能なワークロードは、CPU のリクエストが CPU の上限よりも少なく構成されている環境で実行することをおすすめします。これにより、(初期化時や想定外の高需要時に)ワークロードの負荷が突然増えても支障なく対応できます。
しかし、実際の CPU の必要量がリクエストを常時超えているワークロードがあると、パフォーマンスの問題を引き起こすだけでなく、システムの停止につながるおそれもあります。
改善する方法
1. VPA コンテナ推奨事項の詳細ビューを使用します。たとえば、信頼性リスクのあるメモリのワークロードに対応するには、メモリフィルタの [QoS] を [Burstable] に設定し、[Provisioning Risk] フィルタを [reliability] に設定します。
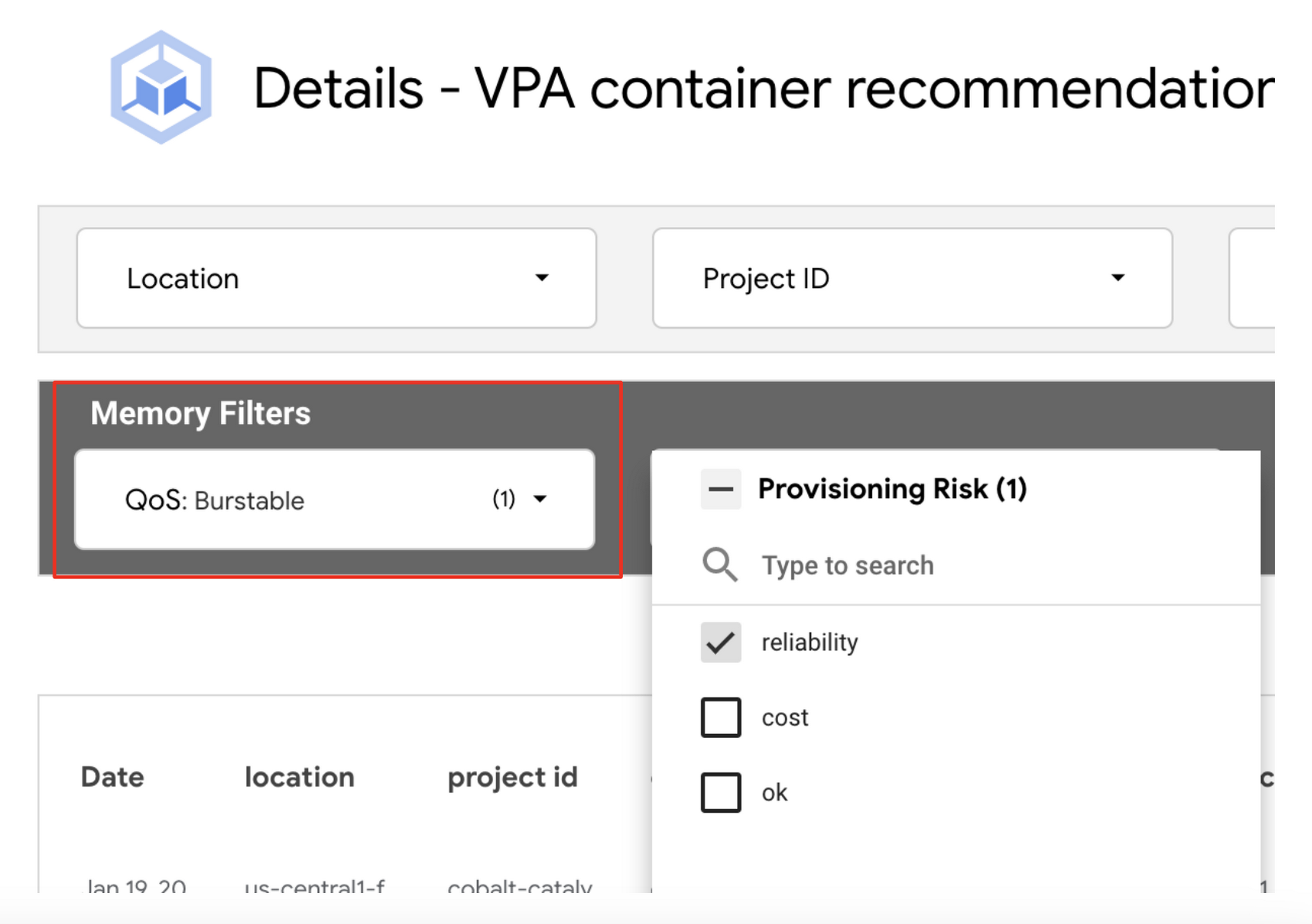
先に説明したとおり、コンテナ リソースの設定では、メモリのリクエストと上限を同じ量に設定し、CPU 上限をより大きい値にするか無制限にすることをおすすめします。
パフォーマンス リスクのあるバースト可能なワークロードを更新するには:
1. VPA コンテナ推奨事項の詳細ビューを使用します。たとえば、信頼性リスクのあるメモリのワークロードに対応するには、CPU フィルタの [QoS] を [Burstable] に設定し、[Provisioning Risk] フィルタを [performance] に設定します。
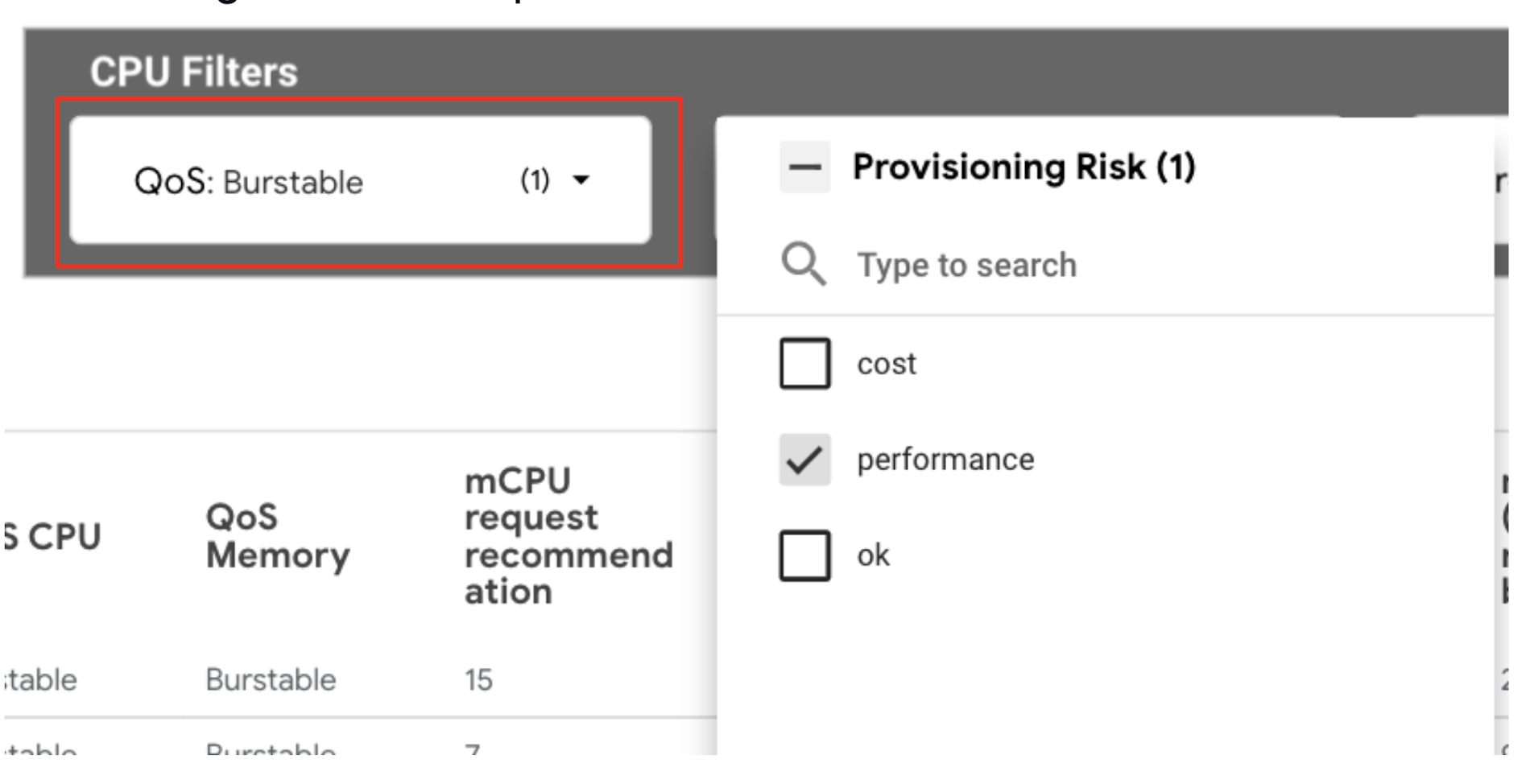
2. [mCPU request recommendation] 列と [mCPU limit recommendation] 列を参照し、ワークロードの CPU のリクエストと上限が VPA の推奨値以上になるように編集します。
節約できる CPU と節約できるメモリのタイル
これらのタイルが正の値のときは、費用を削減できる可能性があることを示しています。負の値の場合、現在のコンテナ設定はプロビジョニングが不足しており、ワークロードのリソースを修正することでパフォーマンスと信頼性が向上します。
改善する方法
1. VPA コンテナ推奨事項の詳細ビュー ダッシュボードに移動します。
2. 費用を削減できる機会を見つけるには、[Provisioning Risk] フィルタを使用し、[cost] でフィルタします。これらのワークロードはプロビジョニングが過剰で、リソースを浪費していると考えられます。
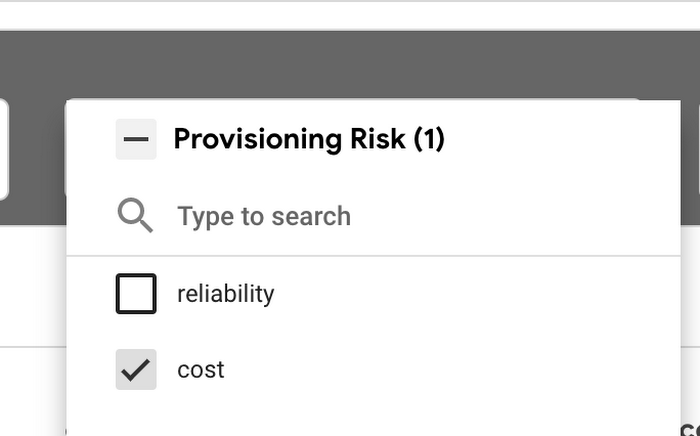
3. ワークロードのリソース構成を更新してコンテナの CPU とメモリのサイズを適正化します。これにより、これらのタイルに表示される値が少なくなります。
注: ワークロードの信頼性とパフォーマンスを維持するためには、それぞれのリスクに対処することが不可欠です。
Top over-provisioned workloads リスト
過剰にプロビジョニングされたワークロードがあると、GKE の請求額が増加します。このリストで、費用削減の優先度が高いワークロードを確認できます。CPU とメモリの現在のリクエスト値と推奨値の差が大きい順に、ワークロードがリスト表示されます。
改善する方法
1. 推奨事項の概要ページで、[Top over-provisioned workloads] リストから、ワークロードを特定します。
2. 表にリスト表示されたメモリと CPU のリクエストおよび上限の推奨値を確認します。

3. コンテナ構成のリクエストと上限の値を更新し、推奨値に近づけます。
ワークロードをより詳細に確認するには、VPA コンテナ推奨事項の詳細ビューで [Provisioning Status] を [over] に設定してフィルタします。
Top under-provisioned workloads リスト
プロビジョニングが不十分なワークロードはコンテナのエラーやスロットリングにつながります。このリストで、CPU とメモリのリクエストが VPA の推奨値を下回るワークロードを確認できます。
改善する方法
1. [Top over-provisioned workloads] と同様に、[Top under-provisioned workloads] でプロビジョニングが不十分なワークロードを特定します。
2. 表にリスト表示された CPU と上限の推奨値を確認します。
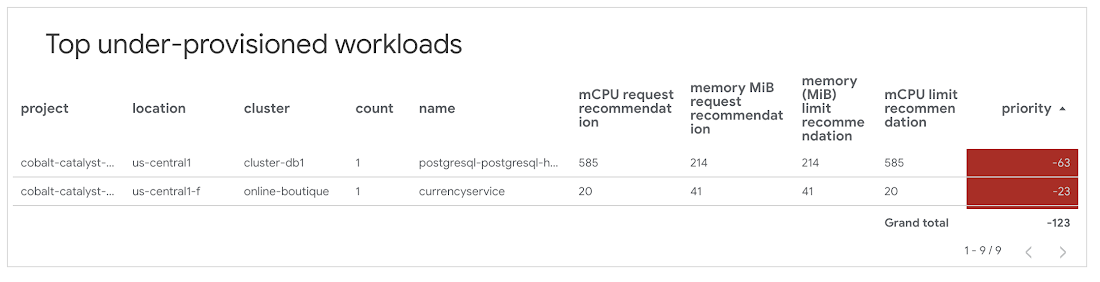
3. コンテナ構成のリクエストと上限の値を更新し、推奨値に近づけます。
注: プロビジョニングが過剰なリソースと不十分なリソースのどちらか一方ばかりに取り組んでいると、費用の削減や把握を正確に行えない可能性があります。費用対効果と信頼性を両立させるためには、プロビジョニングが過剰な上位ワークロードとプロビジョニングが不十分な上位ワークロードに交互に対応することを検討してください。両方のリストを活用することで、アプリケーションの節約と信頼性を最適化できます。
VPA コンテナ推奨事項の詳細ビュー
以下のように、すべてのプロジェクトのすべてのクラストの詳細ビューが表示されます。
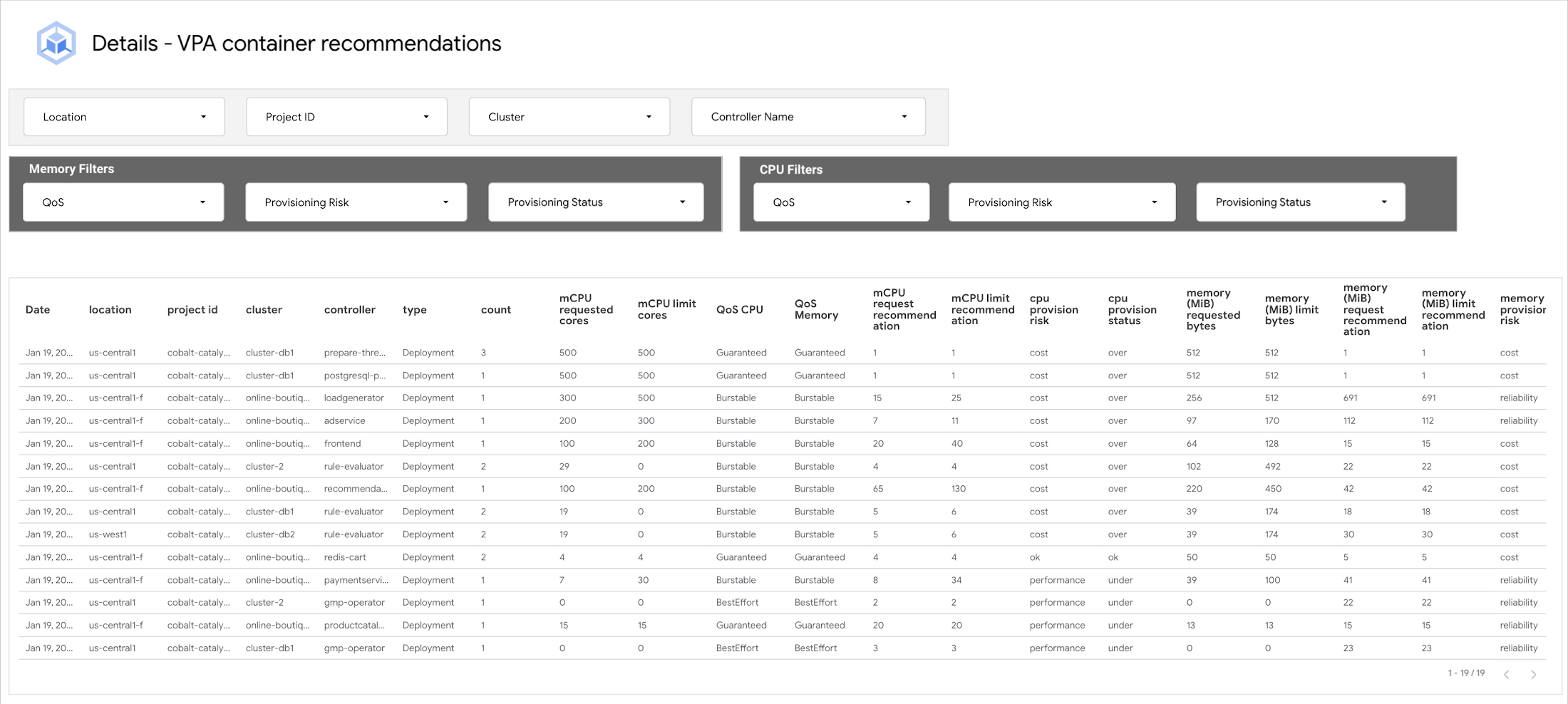
スムーズに最適化を開始できるよう、表には改善に着手するワークロードの順番を決めるのに役立つ列が 3 つ用意されています。
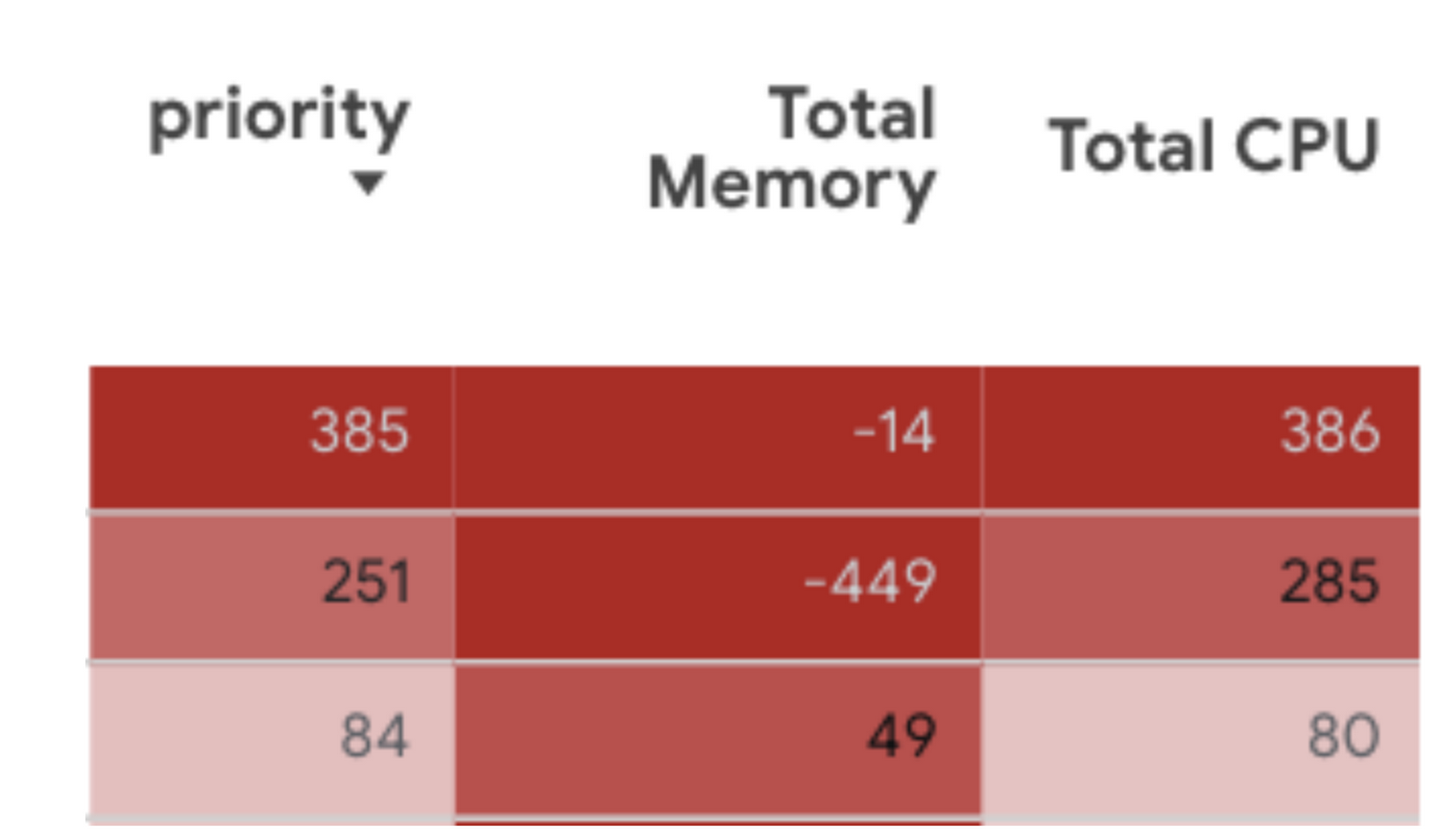
数式には、CPU とメモリのリクエストされた量と推奨される量の差が考慮されています。[priority] の値の計算には、事前定義された vCPU と事前定義されたメモリの比率が使用されます。
[Total Memory] 列と [Total CPU] 列は、メモリ / CPU の現在の構成値と、メモリ / CPU の VPA の推奨値との差を表しています。負の値は、ワークロードにおけるそのリソースのプロビジョニングが不十分であることを示し、正の値は、ワークロードにおけるそのリソースのプロビジョニングが過剰であることを示します。
Cloud Monitoring の GKE Active/Idle clusters ダッシュボード
従量課金制は、クラウド コンピューティングの重要なメリットの一つです。費用の最適化のためには、使用されなくなった GKE クラスタをシャットダウンできるよう、アクティブなクラスタとアイドル状態のクラスタを見分けることが不可欠です。その方法の一つは、Cloud Monitoring のサンプル ライブラリから「GKE Active/Idle clusters」ダッシュボードをインポートすることです。
ダッシュボードには 2 つのチャートがあります。一つは、一定期間内にユーザーの Namespace で実行されているコンテナをカウントします。もう一つは、ユーザー コンテナが同じ期間に消費する CPU 使用時間を示します。コンテナ数がゼロで、CPU 使用率が 1% 未満などと低い場合は、そのクラスタをアイドル状態だとみなして問題ないでしょう。
以下のスクリーンショットで例を示します。注記のパネルから詳細を知ることができます。ダッシュボードをインポートしてから、Cloud Monitoring で、ユースケースに基づいてチャートを編集できます。ソースファイルを調整して直接インポートすることもできます。すべての GKE 関連のサンプル ダッシュボードは、GitHub のサンプル リポジトリで確認できます。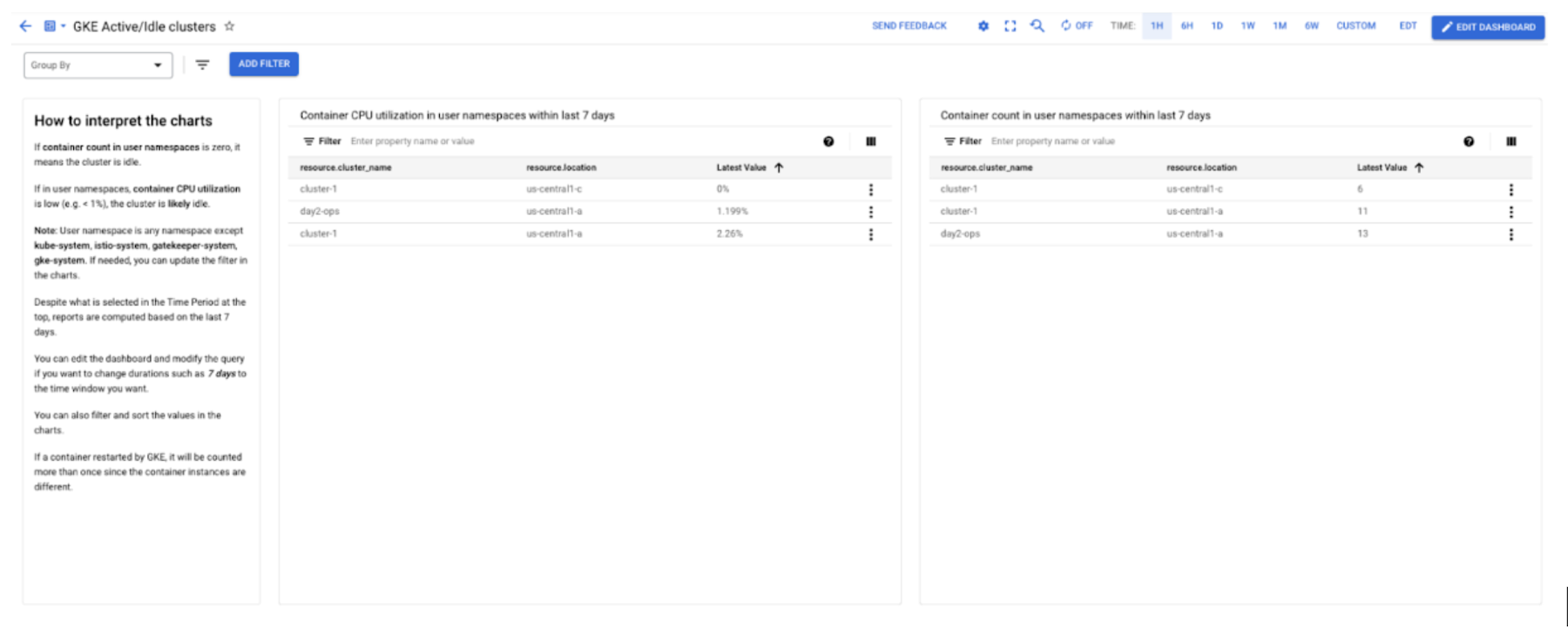
使ってみる
VPA 推奨事項のダッシュボードをデプロイし、最適化を開始するには、こちらのステップごとに説明されているチュートリアルをご確認ください。
このソリューションを使用した GKE ワークロードのサイズ適正化をぜひご検討ください。コンソールから Cloud Monitoring に移動すると、この GKE ダッシュボードをお試しになれます。GKE 最適化について詳しくは、費用対効果の高い Kubernetes アプリケーションを実行するためのベスト プラクティスや、YouTube シリーズにて説明しています。また、オーバー プロビジョニングを減らすための GKE のベスト プラクティスもご覧ください。
皆様のご意見やご質問をお待ちしております。Google Cloud コミュニティの Cloud Operations グループへの参加も、ぜひご検討ください。
- ソリューション アーキテクト Xiang Shen
