GKE のサージ アップグレードで運用効率が大幅に改善
Google Cloud Japan Team
※この投稿は米国時間 2020 年 4 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
Kubernetes 環境の正常性を確保するには、定期的にアップグレードを実施することが重要です。Google Cloud では、GKE のユーザーのためにクラスタ コントロール プレーンを自動的にアップグレードしていますが、クラスタ内の個々のノードや、ノードにインストールされた追加のソフトウェアのアップグレードについては、ユーザー自身で行う必要があります。ノードの自動アップグレードを有効にし、これらの更新をバックグラウンドで実行するように選択することもできますが、最近導入された「サージ ノード アップグレード」機能を使用してアップグレード プロセスをきめ細かく制御すれば、GKE 環境が中断されるリスクを最小限に抑えられ、またアップグレード プロセスを高速化できます。
このことは、多くの組織が外的な圧力によりビジネスをデジタル限定の環境に移行せざるを得なくなっている状況において特に重要であり、可用性がビジネス継続性の鍵となります。サージ アップグレードは、既存のワークロードの中断を低減しながら、最新のバージョン、セキュリティ パッチ、バグの修正でクラスタを最新の状態に保ちます。
ノードのアップグレードの重要性
ノードは、Kubernetes ワークロードが実行される場所です。オープンソースの Kubernetes では、新しいマイナー バージョンは約 3 か月ごとにリリースされ、パッチはこれより高い頻度でリリースされます。GKE では、これと同じリリース スケジュールに従ってセキュリティ パッチとバグの修正を提供しているため、ユーザーはこれらを適用することで、定期的なセキュリティの脆弱性、バグ、コントロール プレーンとノード間でのバージョン スキューの発生を低減できます。
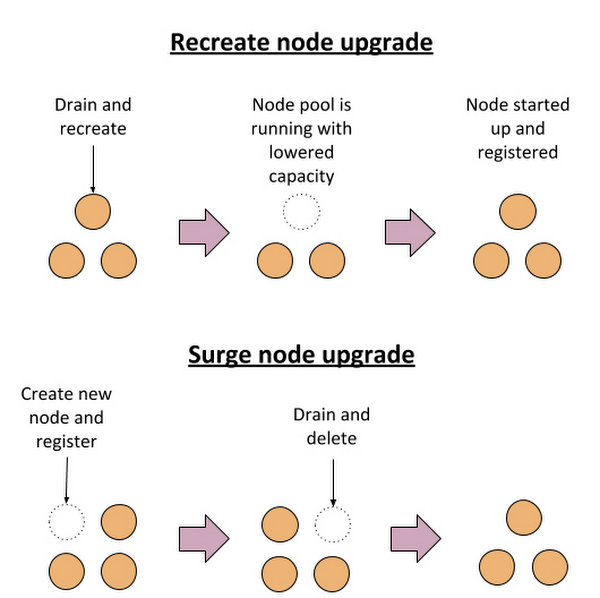
この重要なタスクを実行するために、一般的にはノードの自動アップグレードを有効にします。ノードプールのアップグレード プロセスでは、ノードプール内のすべての VM が、ローリング アップデート方式で新しい(アップグレードされた)VM イメージで再作成されます。これを行うために、特定のノードで実行されているすべてのポッドはシャットダウンされます。大半のユーザーは十分な冗長性を備えてワークロードを実行しており、ポッドの移動や再起動のプロセスに Kubernetes が役立ってはいますが、実際には、一時的に減少したレプリカ数ではすべてのトラフィックを処理するのに不十分になり、結果として本番環境でインシデントが発生する可能性があります。
一部の GKE ユーザーにとっては、単にノードの自動アップグレードを有効にするだけでは十分ではありません。FACEIT は独立したオンライン対戦ゲーム用プラットフォームを提供しており、プレーヤーがコミュニティを作成して、トーナメント、リーグ、マッチでできるだけ迅速かつスムーズに対戦できるようにしています。毎月 100 万人を超えるアクティブ ユーザーを抱える FACEIT では、GKE を利用してプラットフォームの俊敏性と簡単で自動化されたスケーラビリティを実現しています。しかし、ダウンタイムの可能性を排除するために、FACEIT ではノードの自動アップグレード機能を使用していませんでした。代わりに、次のような手動プロセスを使用していました。
同一のノードプールを新しく作成し、新しいバージョンで実行する
古いノードプール内のノードを閉鎖する
ノードをドレインして、ポッドの強制排除を開始する。これにより、Kubernetes はポッドを新しいノードプール内のノードに再スケジュールする
最後に、すべてのノードがドレインされたら、古いノードプールを削除する
この手動プロセスにより、FACEIT はアップグレード速度のバランスを保ち、中断を回避できていました。
サージ アップグレードの導入
すべてのノードのアップグレードを正常にかつタイムリーに完了できるように、GKE ではサージ アップグレードをご利用いただけるようになりました。サージ アップグレードは、古いノードをドレインする前に新しいノードを起動することで中断の可能性を低減するとともに、複数ノードの同時アップグレードをサポートします。サージ アップグレードを正常に完了できるように、必要なすべてのリソース(VM)が保護された後にのみアップグレードが開始されます。サージ アップグレードは 2020 年 4 月 20 日からデフォルトで有効になり、またこの四半期の後半には既存のノードプールも移行する予定です。
新しいサージ アップグレード機能は、主に次の 2 つの方法でワークロードの中断を減少させるのに役立ちます。
1. ノードのアップグレード中に容量が減少しない
サージ アップグレードでは、ノードプールは、アップグレード プロセスの開始時よりも容量が少ない状態になり得ません(maxUnavailable の設定は 0 と想定)。
一方、サージ アップグレードでない場合は、ノードを再作成することでノードのアップグレードが行われます。そのため、アップグレード プロセス中にクラスタでノードが使用不可になる期間があります。クラスタに十分な冗長性があれば、これによってワークロードの中断が生じることはありません。ただし、ワークロードやインフラストラクチャで他の障害(関係のないノードの障害など)が発生すると、中断が生じる可能性があります。
サージ アップグレードのこの機能は、上記の機能によって生じた結果と言えます。同等の追加容量(つまり、サージノード)が使用可能であるため、強制排除されたポッドをいつでもスケジュールできます。
前述したように、ノードのアップグレードは、新しいインスタンス テンプレートを使用して Compute Engine インスタンスを再作成してから、ポッドを強制排除して再スケジュールする(それらをスケジュールする容量がある場合)ことで行われます。
スケジュールされずに残っているポッドが 1 つ以上あるということは、実行しているレプリカの数が必要な数よりも少ないワークロードが 1 つ以上あるということになります。これはワークロードの正常性に影響を与える可能性があります(つまり、システムがレプリカの損失を許容できない場合があります)。いずれにしても、高可用性を確保するには、レプリカ数を減らした状態でワークロードが実行されている時間を短くする必要があります。
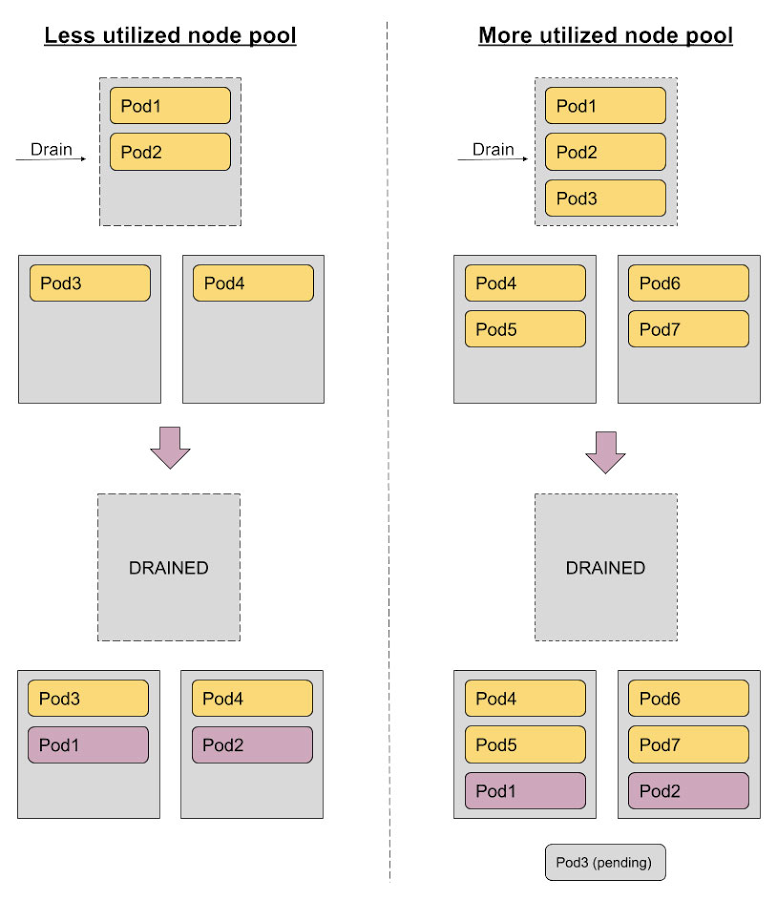
アップグレード中にサージノードがないと、必ずしもポッドがスケジュール不可になるわけではありません。ノードプールに使用可能な容量が十分にある場合は、それが使用されます。
下の図では、左側のノードプールには十分な容量があり、最初のノードがドレインされるとすぐに、強制排除されたすべてのポッドを再スケジュールできます。右側のノードプールには使用可能な容量はありますが、十分ではないため、すぐに再スケジュールできるのは強制排除された 3 つのポッドのうち 2 つだけです。Pod3 はノードのアップグレードが完了するのを待つ必要があり、その後、再度スケジュールされます。
サージノードがあることで状況がどのように変わるか見てみましょう。使用率の低いノードプールの場合、ポッドにすでに十分な容量があるため、サージノードはポッドのスケジューリングには役立ちません。ただし、ノードプールの使用率が高い場合、強制排除されたポッドをすぐにスケジュールできるようにするには、追加の容量が必要です。
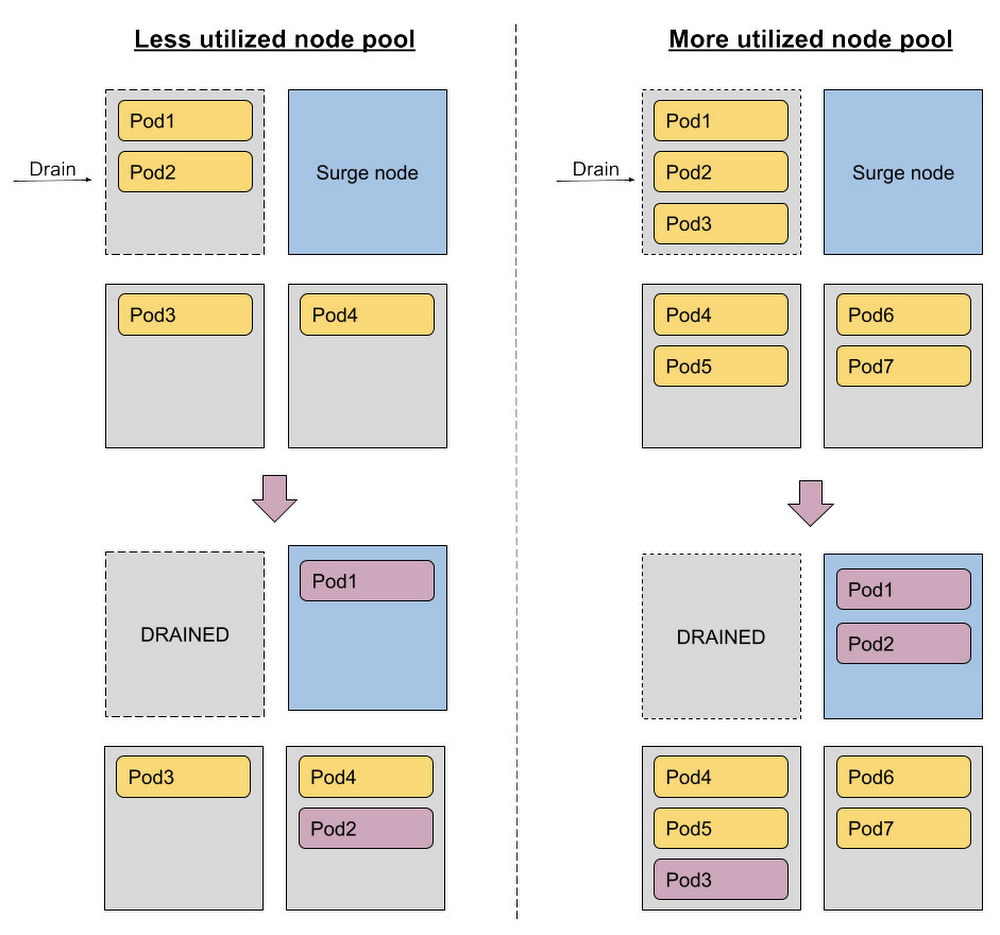
サージ容量はアップグレードだけでなく、他の要求でも「消費」される可能性があるので注意してください。たとえば、アップグレード中に負荷が急上昇した場合にアプリケーションを迅速にスケールアップするために使用されることもあります。
アップグレードのタイミングだけでなく方法も制御
GKE のノードの自動アップグレード機能により、管理者は最新のパッチとアップデートで環境を最新の状態に保つことができます。サージ アップグレードを使用することで、これらのアップグレードを正常に、そして本番環境ワークロードに影響を与えずに行えるようになりました。
FACEIT を始めとするアーリー アドプターにより、この強化されたアップグレード プロセスは信頼性が高いだけでなく、ノードの同時アップグレードが可能なため、より高速であることが報告されています。
FACEIT のエンジニアリング担当バイス プレジデントである Emanuele Massara 氏は、次のように述べています。「サージ アップグレードを導入するまでは、1 つの環境のアップグレードが完了するのに 7 時間程かかっており、これに環境の数を掛けた時間を要していました。そのため、すべての FACEIT 環境をアップグレードするのに約 2 週間を費やしていました。サージ アップグレードでは、全部のプロセスが 1 日もかからずに完了するため、チームをアップグレード業務から解放して他のタスクに専念させることができます。」以来、FACEIT は手動によるアップグレード プロセスを廃止しています。
サージ アップグレードを、正しく構成された PDB(ポッド停止予算)と組み合わせて使用することで、アップグレード プロセス中のアプリケーションの可用性も確保できると、DevOps およびサービス提供担当マネージャーの Bradley Wilson-Hunt 氏は述べています。「PDB を使用しなくても、Kubernetes は新しいポッドの準備が完了するのを待たずにデプロイのポッドを再スケジュールできますが、これによってサービスが中断する可能性があります。」
サージ アップグレードの使用について詳しくは、アップグレードを構成するパラメータの決定方法に関するガイドラインをご覧ください。また、こちらのチュートリアルを採用したデモ アプリケーションを使用して、ご自身でサージ アップグレードを試していただけます。
- By Tamas Ragoncsa, Software Engineer and Kobi Magnezi, Product Manager, Google Kubernetes Engine
