Google Kubernetes Engine で Managed Lustre を使用するときのベスト プラクティス 5 つ
Nishtha Jain
Engineering Manager
Dan Eawaz
Senior Product Manager
※この投稿は米国時間 2025 年 9 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Kubernetes Engine(GKE)は、スケーラブルな AI とハイ パフォーマンス コンピューティング(HPC)のワークロードをオーケストレートするための強力なプラットフォームです。しかし、クラスタが拡大し、ジョブのデータ集約度が高まるにつれて、ストレージの I/O がボトルネックになる可能性があります。また、強力な GPU と TPU がデータの到着を待つ間、アイドル状態になり、コストが増加してイノベーションが遅れる可能性があります。
Google Cloud Managed Lustre は、この問題を解決するために設計されています。多くのオンプレミス型 HPC 環境はすでに並列なファイル システムを使用しており、Managed Lustre を使うと、これらのワークロードをクラウドに移行するのがより簡単になります。また、マネージド Container Storage Interface(CSI)ドライバにより、Managed Lustre と GKE のオペレーションが完全に統合されます。
そして、高性能かつ並列なファイル システムへの移行を最適化することで、初日から投資を最大限に活用できます。
デプロイする前に、Managed Lustre を使用するタイミングと、Google Cloud Storage などの他のプロダクトを使用するタイミングを把握しておくと便利です。ほとんどの AI / ML ワークロードでは、Managed Lustre が推奨ソリューションであり、非常に低いレイテンシ(1 ミリ秒未満)と小さなファイルに対する高いスループットが求められるトレーニングとチェックポイントのシナリオで優れた力を発揮します。ただし、それゆえに高価なアクセラレータは引き続き完全に活用することになります。データ アーカイブや、レイテンシが高くなっても問題がない大きなファイル(50 MB 超)を使用するワークロードには、Anywhere Cache を使用する Cloud Storage FUSE も別の選択肢となりえます。
初期のお客様との取り組みとチームからの学びに基づいて、GKE で Managed Lustre を確実に最大限に活用するためのベスト プラクティスを 5 つご紹介します。
1. データのロケーションを考慮した設計
パフォーマンスが重要なアプリケーションの場合、コンピューティング リソースとストレージは可能な限り近くに配置する必要があります。特定のリージョン内の同じゾーンに配置することが理想的です。ボリュームを動的にプロビジョニングする場合、StorageClass の volumeBindingMode パラメータが最も重要な決め手となります。このパラメータを WaitForFirstConsumer に設定することを強くおすすめします。GKE には、デフォルトで WaitForFirstConsumer バインディング モードを使用する Managed Lustre 用の組み込み StorageClass が用意されています。
生成された YAML:
ベスト プラクティスである理由: WaitForFirstConsumer を使用すると、Lustre インスタンスを必要とする Pod がスケジュールされるまで、その Lustre インスタンスのプロビジョニングを遅らせることを求める指示が GKE に届きます。その後、スケジューラは Pod のトポロジ制約(つまり、Pod がスケジュールされているゾーン)を使用して、そのゾーンに Lustre インスタンスを作成します。これにより、ストレージとコンピューティングのコロケーションが保証され、ネットワーク レイテンシが最小限に抑えられます。
2. ティアでパフォーマンスを適正化
すべての高パフォーマンス ワークロードが同一なわけではありません。Managed Lustre には複数のパフォーマンス ティア(ストレージ 1 TiB あたりの読み取り / 書き込みスループット(MB/秒))があるため、コストをパフォーマンス要件に直接整合させることができます。
-
1,000 & 500 MB/秒/TiB: I/O 帯域幅が主なボトルネックとなる、基盤モデルのトレーニングや大規模な物理シミュレーションなど、スループットが重要なワークロードに最適です。
-
250 MB/秒/TiB: バランスの取れた費用対効果が高いティアであり、一般的な HPC ワークロードや AI 推論サービング、データ量が多い分析パイプラインに最適です。
- 125 MB/秒/TiB: ピーク時のスループット達成よりも、POSIX 準拠の大規模なファイル システムがあることが重要な大型のユースケースに最適です。これは、オンプレミスのコンテナ化されたアプリケーションを修正せずに移行する場合にも役立ち、オンプレミスのワークロードをクラウド ストレージに移行するのがより簡単になります。
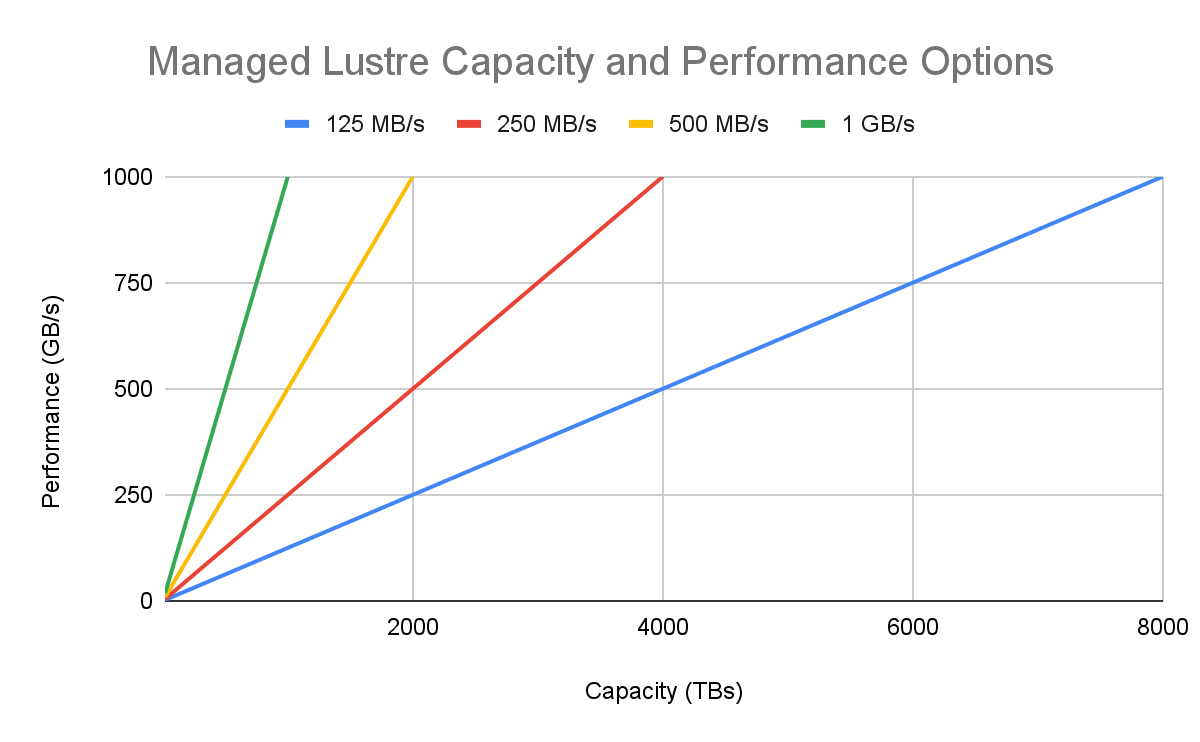
ベスト プラクティスである理由: デフォルトで最上位のティアを選択することが、必ずしも費用対効果の高い戦略とは限りません。ワークロードの I/O プロファイルを分析することで、総所有コストを大幅に最適化できます。
3. ネットワーキングの基礎を習得
並列なファイル システムは、ネットワークに接続しているリソースです。ネットワーキングを最初から適切に設定することで、トラブルシューティングに費やす時間を大幅に節約できます。プロビジョニングする前に、ドキュメントに記載されているセットアップ手順に沿って VPC を確実に正しく構成してください。これには、ドキュメントで詳しく説明されている 3 つの主要な手順が含まれます。
サービス ネットワーキングを有効にする。
-
VPC ピアリングのIP 範囲を作成する。
-
Lustre のネットワーク ポート(TCP 988 または 6988)でその範囲からのトラフィックを許可するファイアウォール ルールを作成する。
ベスト プラクティスである理由: これは、GKE ノードが Managed Lustre サービスと通信できるようにするセキュリティが確保されたピアリング接続を確立する、VPC ごとの 1 回限りの設定です。
4. シンプルな場合は動的プロビジョニングを、長期的に共有するデータには静的プロビジョニングを
Managed Lustre CSI ドライバには、ストレージを GKE ワークロードに接続するための 2 つのモードがあります。
-
動的プロビジョニング: ストレージが特定のワークロードまたはアプリケーションのライフサイクルに密接に結び付いている場合に使用します。StorageClass と PersistentVolumeClaim(PVC)を定義すると、GKE が Lustre インスタンスのライフサイクルを自動的に管理します。これは最もシンプルで自動化されたアプローチです。
-
静的プロビジョニング: 複数の GKE クラスタと Job で共有する必要がある、存続期間の長い Lustre インスタンスがある場合に使用します。Lustre インスタンスを一度作成したら、クラスタ内に PersistentVolume(PV)と PVC を作成して、そのインスタンスにマウントします。これにより、ストレージのライフサイクルが単一のワークロードから切り離されます。
ベスト プラクティスである理由: データのライフサイクルを考慮することは、適切なパターンを選択するのに役立ちます。シンプルさを重視してデフォルトとして動的プロビジョニングを使用し、ファイル システムを組織全体で永続的な共有リソースとして扱う必要がある場合は静的プロビジョニングを選択します。
5. Kubernetes Job を使用した並列処理のアーキテクチャ設計
データの前処理やバッチ推論など、多くの AI および HPC に関するタスクは並列実行に適しています。1 つの大きな Pod を実行する代わりに、Kubernetes Job リソースを使用して、作業を多くのより小さな Pod に分割します。
次のパターンを考えてみましょう。
-
Managed Lustre インスタンスの PersistentVolumeClaim を 1 つ作成し、クラスタで利用できるようにします。
-
Kubernetes Job の並行処理を高い数値(例: 100)に設定して、定義します。
-
Job によって作成された各 Pod は、同じ Lustre PVC をマウントします。
-
各 Pod がデータの異なるサブセットで動作するようにアプリケーションを設計します(例: 異なる範囲のファイルやデータチャンクを処理する)。
ベスト プラクティスである理由: このパターンでは、Lustre インスタンス用に 1 つの PVC を作成し、Job によって作成された各 Pod が同じ PVC をマウントします。各 Pod がデータの異なるサブセットで動作するようにアプリケーションを設計することで、GKE クラスタを強力な分散データ処理エンジンに変えることができます。GKE Job コントローラは並列なタスク オーケストレーターとして機能し、Managed Lustre は高速なデータ バックボーンとして機能するため、大規模な集計スループットを実現できます。
使ってみる
GKE のオーケストレーション機能と Managed Lustre のパフォーマンスを組み合わせることで、AI と HPC 向けの真にスケーラブルで効率的なプラットフォームを構築できます。これらのベスト プラクティスに従うことで、強力であるだけでなく、効率的で費用対効果が高く、管理しやすいソリューションを作成できます。
準備ができたら Managed Lustre のドキュメントを確認して、今すぐ最初のインスタンスをプロビジョニングしましょう。
ー エンジニアリング マネージャー、Nishtha Jain
ー シニア プロダクト マネージャー、Dan Eawaz
