Ironwood TPU と AI Hypercomputer の新しいイノベーションのご紹介

Mark Lohmeyer
VP & GM, AI & Computing Infrastructure
George Elissaios
VP, Product Management, Compute Engine & AI Infrastructure
※この投稿は米国時間 2025 年 4 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
今日のイノベーションは、研究室や設計図から生まれるのではありません。AI インフラストラクチャの基盤の上に構築されるのです。AI ワークロードには、新しい独自の要件があります。これらの要件に対処するには、大規模レベルでのパフォーマンスと効率性を実現する、ハードウェアとソフトウェアの緻密な組み合わせと、必要に応じてこのインフラストラクチャにアクセスするための使いやすさと柔軟性が求められます。Google Cloud では、AI Hypercomputer を通じてこれを実現しています。
AI Hypercomputer は、Google の 10 年以上にわたる AI に関する専門知識を活用した統合型スーパー コンピューティング システムです。Google Cloud で実行されるほぼすべての AI ワークロードを支えているのが AI Hypercomputer です。Vertex AI を使用している場合は内部で実行されます。また、AI Hypercomputer のパフォーマンスが最適化されたハードウェア、オープン ソフトウェア、柔軟な使用量モデルに直接アクセスしてインフラストラクチャをきめ細かく制御することもできます。これらはすべて、AI ワークロードのトレーニングとサービングにおいて、さらなるインテリジェンスを低価格で提供できるように設計されています。この統合システム アプローチは市場で差別化されており、Gemini Flash 2.0 が GPT-4o よりも 1 ドルあたり 24 倍、DeepSeek-R1 よりも 5 倍高いインテリジェンスを実現できる一因となっています1。
今回は、AI ワークロードに対して 1 ドルあたりの最高水準のインテリジェンスを提供するために連携して設計された、AI Hypercomputer スタック全体にわたる新しいイノベーションをご紹介します。
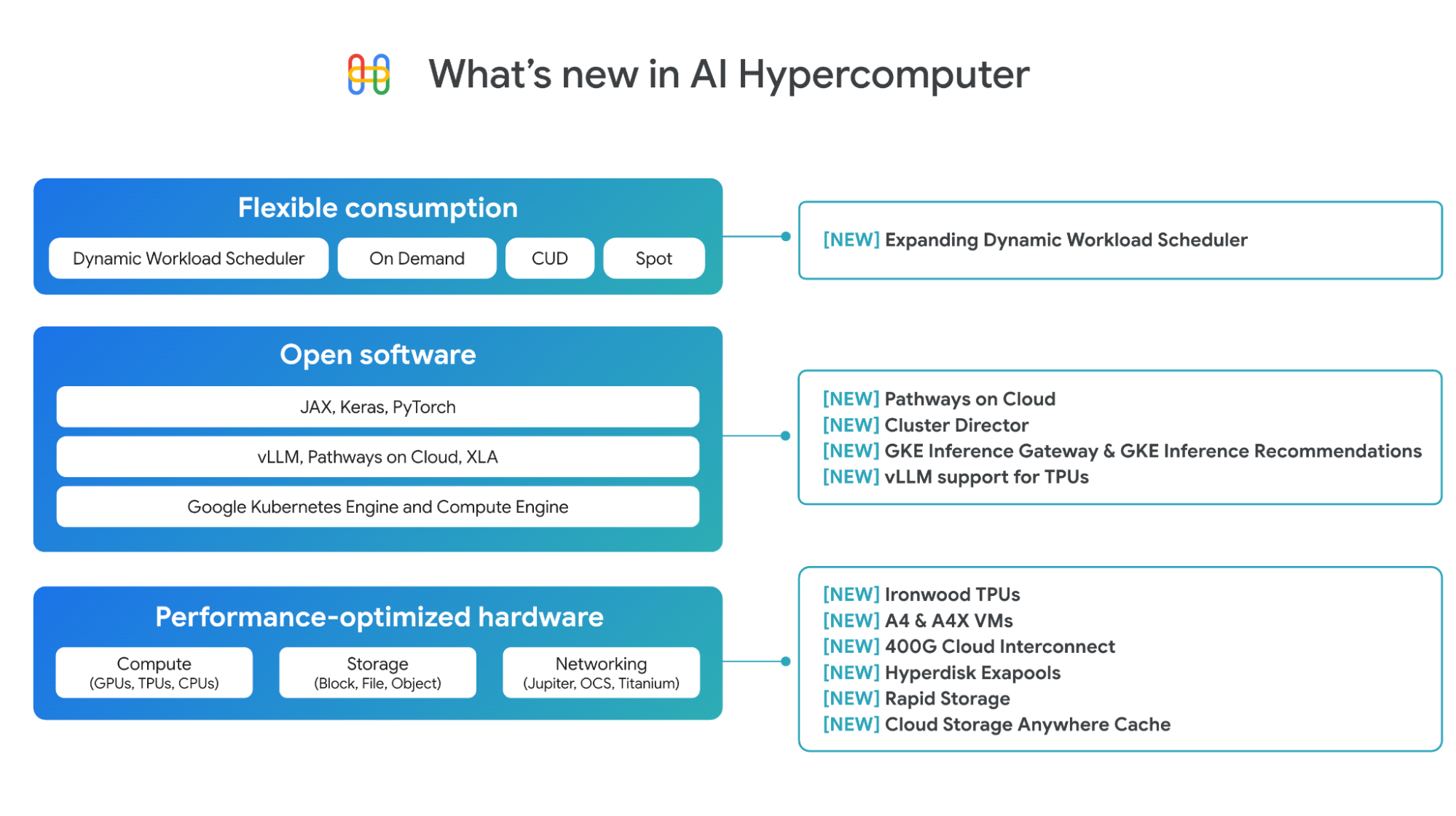
パフォーマンス最適化ハードウェアにおける進化
Google は、パフォーマンスが最適化されたハードウェアのポートフォリオを拡大し続け、コンピューティング、ネットワーキング、ストレージに関する幅広いオプションを提供しています。
第 7 世代 TPU Ironwood: Ironwood は推論用に構築されており、前世代の Trillium と比較してピーク時のコンピューティング容量が 5 倍、高帯域幅メモリ(HBM)容量が 6 倍になっています。Ironwood には 256 個のチップと 9,216 個のチップの 2 つの構成があり、それぞれ単一のスケールアップ Pod として利用できます。大きい方の Pod は、驚異的な 42.5 エクサフロップのコンピューティング能力を実現します。Ironwood は、Trillium と比較して電力効率が 2 倍になり、ワットあたりの価値が大幅に向上しています。デベロッパーは、PyTorch と JAX にまたがる最適化されたスタックを通じて Ironwood にアクセスできます。この画期的な TPU の詳細については、こちらをご覧ください。

A4 VM と A4X VM: Google Cloud は、A4 VM と A4X VM で NVIDIA B200 と GB200 NVL72 GPU の両方を提供した最初のハイパースケーラーです。先月の NVIDIA GTC で A4 VM(NVIDIA B200)の一般提供を発表し、A4X VM(NVIDIA GB200)は現在プレビュー版で提供しています。A4 と A4X の詳細については、こちらをご覧ください。
ネットワーキングの強化: AI ワークロードに必要な超低レイテンシをサポートするために、新しい 400G の Cloud Interconnect と Cross-Cloud Interconnect は、100G の Cloud Interconnect と Cross-Cloud Interconnect よりも最大 4 倍の帯域幅を提供し、オンプレミスまたは他のクラウド環境から Google Cloud への接続を可能にします。詳しくは、こちらの昨今のネットワーキングに関するブログ投稿をご覧ください。
Hyperdisk Exapools: あらゆるハイパースケーラーの中で AI クラスタあたりのパフォーマンスと容量が最も優れたブロック ストレージ。単一のシン プロビジョニング プールで最大エクサバイトのブロック ストレージ容量と数 TB/秒のスループットをプロビジョニングできます。
Rapid Storage: 主要ストレージを TPU や GPU と同じ場所に配置して使用状況を最適化する、新しい Cloud Storage のゾーンバケット。Cloud Storage のリージョン バケットと比較して、ランダム読み取りデータの読み込みが最大 20 倍高速になります。
Cloud Storage Anywhere Cache: 既存のリージョン バケットで動作する、強整合性のある新しい読み取りキャッシュ。選択したゾーン内でデータをキャッシュに保存します。Anywhere Cache は、データをアクセラレータの近くに保持することでレイテンシを 70% 短縮し、応答性の高いリアルタイムの推論のやり取りを可能にします。
トレーニングと推論のためのオープン ソフトウェア機能
ハードウェアの真の価値は、協調設計されたソフトウェアによって発揮されます。AI Hypercomputer のソフトウェア レイヤを使用することで、AI 実務担当者やエンジニアは、PyTorch、JAX、vLLM、Keras などのオープンで一般的な ML フレームワークとライブラリによる作業を迅速化できます。インフラストラクチャ チームの場合は、デリバリー時間が短縮され、優れた費用効率でリソースを活用できます。Google は、AI のトレーニングと推論の両方でソフトウェアに大きな進歩をもたらしました。
Pathways on Cloud: Google DeepMind が開発した Pathways は、Google 社内の大規模なトレーニングと推論のインフラストラクチャを支える分散ランタイムであり、Google Cloud で初めて利用可能になりました。推論については、分離型サービングなどの機能が含まれます。これにより、推論ワークロードのプレフィルとデコードのステージを個別のコンピューティング ユニットで動的にスケーリングし、それぞれ独立してスケーリングすることで超低レイテンシと高スループットを実現できます。これは、高スループットと低レイテンシの推論ライブラリである JetStream を通じてお客様に提供されます。Pathways は、トレーニング ワークロードを障害時に自動的にスケールダウンし、復旧時にスケールアップして継続性を確保する、弾力性のあるトレーニングも可能にします。Pathways アーキテクチャのその他のユースケースなど、Pathways on Cloud の詳細については、ドキュメントをご覧ください。
高いパフォーマンスと信頼性でモデルをトレーニング
トレーニング ワークロードとは、数千のノードにわたって実行される高度に同期されたジョブのことです。1 つのノードがデグレードされると、ジョブ全体が中断され、製品化までの時間の延長と費用の増加につながる可能性があります。クラスタを迅速にプロビジョニングするには、特定のモデル アーキテクチャに合わせてチューニングされた、近い距離にある VM が必要です。また、ノード障害を予測して迅速にトラブルシューティングし、障害が発生した場合にワークロードの継続性を確保する機能も必要です。
Cluster Director for GKE と Cluster Director for Slurm。Cluster Director(旧 Hypercompute Cluster)では、物理的に同じ場所に配置された VM、ターゲットを絞ったワークロード配置、高度なクラスタ メンテナンス制御、トポロジーを考慮したスケジューリングの機能を活用してアクセラレータのグループを単一のユニットとしてデプロイおよび管理できます。今回は、今年リリースされる Cluster Director の新しいアップデートについてお知らせします。
-
Cluster Director for Slurm: Slurm クラスタをプロビジョニングして運用する、シンプルな UI と API を備えたフルマネージド Slurm サービス。デプロイの信頼性と再現性を高める、ソフトウェアが事前構成された一般的なワークロードのブループリントが含まれています。
-
360° オブザーバビリティ機能: クラスタの使用率、健全性、パフォーマンスを可視化するダッシュボードに加え、AI 健全性予測やストラグラー検出などの高度な機能により、個々のノードに至るまで、障害を事前に検出して修正できます。
-
ジョブ継続性機能: フリートを継続的にモニタリングし、異常なノードを事前に置き換えるエンドツーエンドの自動ヘルスチェックなど。より迅速に保存、取得するための複数ティアのチェックポインティングにより、クラスタが劣化してもトレーニングが中断されることはありません。
Cluster Director for GKE では、新しい Cluster Director 機能が利用可能になると、ネイティブにサポートします。Cluster Director for Slurm は、今後数か月以内に利用可能になる予定で、GPU と TPU の両方のサポートも含まれます。早期アクセスに登録してください。
あらゆる規模で推論ワークロードを効率的に実行
AI 推論はここ 1 年で急速に進化しました。長くて変動性の高いコンテキスト ウィンドウにより、さらに高度なインタラクションが可能になってきています。また、推論やマルチステップ推論により、コンピューティングの新たな需要(結果的にコストも)はトレーニングから推論時間(テスト時間のスケーリング)にシフトしています。エンドユーザーにとって有益な AI アプリケーションを実現するには、現在および将来のインタラクションを効率的に処理できるソフトウェアが必要です。
GKE での AI 推論機能の発表: Inference Gateway と Inference Quickstart。
-
GKE Inference Gateway は、インテリジェントなスケーリングとロード バランシング機能を備えており、生成 AI モデル対応のスケーリングとロード バランシングの手法でリクエストのスケジューリングとルーティングを処理できます。
-
GKE Inference Quickstart を使用すると AI モデルと必要なパフォーマンスを選択でき、GKE は、それに合わせて適切なインフラストラクチャ、アクセラレータ、Kubernetes リソースを構成します。
どちらの機能も現在プレビュー版で利用可能で、併用すると他のマネージド サービスやオープンソースの Kubernetes サービスと比較して、サービングの費用を 30% 以上、テール レイテンシを 60% 削減し、スループットを最大 40% 向上させることができます。
TPU の vLLM サポート: vLLM は、高速で効率的な推論ライブラリとしてよく知られています。本日より、vLLM を使用して TPU で推論を簡単に実行し、ソフトウェア スタックを変更することなく、わずかな構成変更だけで TPU のコスト パフォーマンスのメリットを享受できるようになります。vLLM は、Compute Engine、GKE、Vertex AI、Dataflow でサポートされています。また、GKE のカスタム コンピューティング クラスを使用すると、同じ vLLM のデプロイ内で TPU と GPU を連携して使用できます。
消費をさらに柔軟に
Dynamic Workload Scheduler(DWS)は、リソース管理とジョブ スケジューリングのプラットフォームであり、アクセラレータに簡単に、手頃な価格でアクセスできるようにします。このたび、DWS でアクセラレータのサポートを拡大し、TPU v5e、Trillium、A3 Ultra(NVIDIA H200)、A4(NVIDIA B200)VM を Flex Start モードでプレビュー版として、また TPU の Calendar モードを今月中にサポートすることをお知らせします。さらに、Flex Start モードでは、リソースを即座にプロビジョニングして動的にスケールできる新しいプロビジョニング方法がサポートされるようになり、長時間実行される推論ワークロードや幅広いトレーニング ワークロードに適したものとなりました。この方法は、すべてのノードを同時にプロビジョニングする必要がある Flex Start モードのキューに格納されたプロビジョニング方法に加えて使用できます。
Next ‘25 で AI Hypercomputer について学ぶ
最新情報をお見逃しなく。すべてのお知らせと詳細情報は、イベント ウェブサイトでご確認いただけます。まずは、コンピューティングと AI インフラストラクチャの今後をご覧いただき、その後、以下のブレイクアウト セッションをご覧ください。
1. arXiv(LMArena)、Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference、Wei-Lin Chiang、Lianmin Zheng、Ying Sheng、Anastasios 1 Nikolas Angelopoulos、Tianle Li、Dacheng Li、Hao Zhang、Banghua Zhu、Michael Jordan、Joseph E. Gonzalez、Ion Stoica、2024 年。2025 年 3 月 19 日時点の正確な情報です。このベンチマークでは、モデル出力の品質(人間のレビュアーによる評価)と、出力を生成するために必要な 100 万トークンあたりの価格を比較して、効率性を比較しています。Google では、「インテリジェンス」をモデル出力の品質に対する人間の認識として定義しています。
-コンピューティングおよび AI インフラストラクチャ担当、バイス プレジデント兼ゼネラル マネージャー、Mark Lohmeyer
-プロダクト マネジメント、Compute Engine および AI インフラストラクチャ担当バイス プレジデント、George Elissaios

