EDA フローをスケール: Google Cloud でより高速な検証を実現する方法
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
企業がクラウド内のインフラストラクチャのモダナイズに着手する主な理由は、1)プロダクト提供の加速、2)システムのダウンタイムの削減、3)イノベーションの実現の 3 つです。これらは電子設計自動化(EDA)ワークロードを扱うチップ設計者にとっての目標でもあり、クラウドを利用することでチップ設計者は大きな恩恵を得られます。
チップの設計と製造の過程では複数のツールが使用され、求められるコンピューティング能力やメモリの使用量には幅があります。レジスタ転送レベル(RTL)の設計とモデリングは、設計プロセスで特に時間のかかるステップの一つであり、設計サイクル全体に要する時間の半分以上を占めます。RTL 設計者は、SystemVerilog や VHDL などのハードウェア記述言語(HDL)を使用して設計を作成します。この設計においてさまざまなツールが用いられます。完全な RTL 検証のフローには、静的分析(テストベクターを使用せずに設計の完全性をチェックする)、フォーマル プロパティ検証(設計プロパティを数学的に証明または反証する)、動的シミュレーション(実際の設計のテストベクター ベースのシミュレーション)、エミュレーション(最終版のチップの動作を模倣する複雑なシステム、特にソフトウェア スタックの機能の検証に有用)が含まれます。
動的シミュレーションは間違いなく、設計チームのデータセンターの計算能力を最も多く使用しています。Google Cloud テクノロジーと、オープンソースの設計およびソリューションを使用して簡単なセットアップを作成し、以下の 3 つの重要なポイントについてご説明します。
コンピューティング能力の増強でシミュレーションをどの程度加速できるか
自動スケーリング クラウド クラスタは検証チームにどのようなメリットをもたらすか
クラウドの弾力性を効果的に活用して、使用率の高いテクノロジー インフラストラクチャをどのように構築できるか
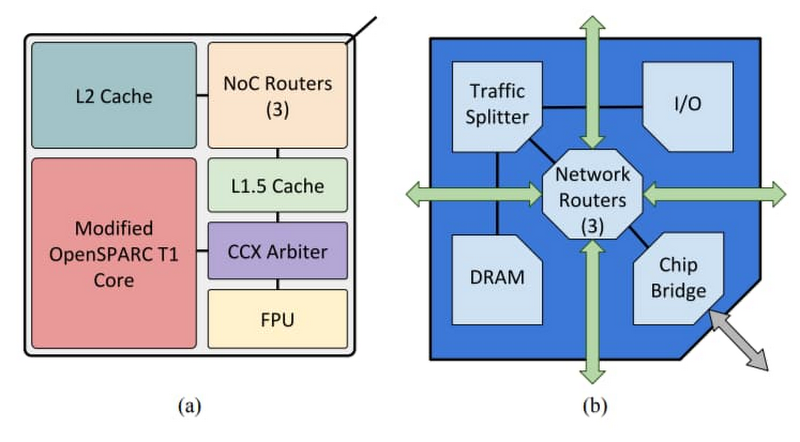
さまざまなツール(OpenPiton 設計検証スクリプト、Icarus Verilog シミュレータ、SLURM ワークロード管理ソリューション、Google Cloud 標準コンピューティング構成)を使用してこれを行いました。
OpenPiton は、世界初のオープンソースの汎用マルチスレッド化メニーコア プロセッサ兼フレームワークです。プリンストン大学で開発されたこの OpenPiton はスケーラビリティとポータビリティを備え、最大 5 億コアまでスケールアップできます。OpenPiton は研究コミュニティで非常に人気があり、設計フローの一般的手順(動的シミュレーション、論理合成、物理合成など)を実行するためのスクリプトが付属しています。
Icarus Verilog(iverilog とも呼ばれます)は、オープンソースの Verilog シミュレーションおよび合成ツールです。
Simple Linux Utility for Resource Management(SLURM)は、オープンソースの Linux クラスタ向けクラスタ管理およびジョブ スケジューリング システムです。フォールト トレラントで高いスケーラビリティを有しています。SLURM は、コンピューティング ノードへのユーザー アクセスの有効化、保留中の作業のキューの管理、ジョブの開始とモニタリングのためのフレームワークなどの機能を提供します。SLURM クラスタの自動スケーリングは、クラスタ マネージャーがノードをオンデマンドで起動し、ジョブの完了後にノードを自動的にシャットダウンする機能です。
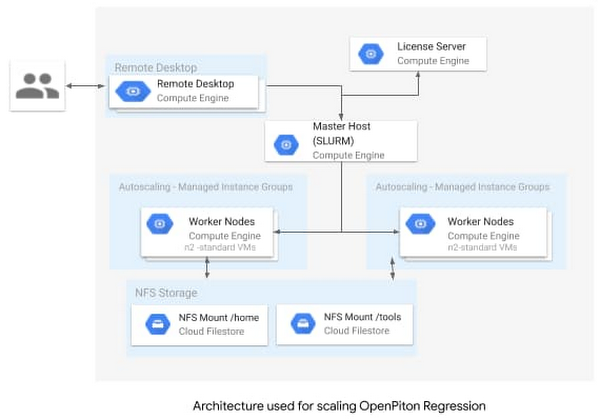
セットアップ
基盤となるインフラストラクチャには、ごく基本的なリファレンス アーキテクチャを使用しました。シンプルですが、目標を達成するには十分でした。標準の N1 マシン(2 つの vCPU、7.5 GB のメモリを備えた n1-standard-2)を使用し、10 個のコンピューティング ノードに自動スケーリングするように SLURM クラスタをセットアップしました。以下の図は、このリファレンス アーキテクチャを示しています。必要なすべてのスクリプトは、この github リポジトリから提供されています。
OpenPiton 回帰の実行
OpenPiton 回帰の実行の最初のステップとして、github リポジトリで概説されているステップに従い、このプロセスを正常に完了させます。
その次に、設計ファイルと検証ファイルをダウンロードします。手順は、github リポジトリで確認できます。ダウンロードしたら、以下の 3 つの簡単なセットアップ タスクを実行します。
PITON_ROOT 環境変数を設定します(%export PITON_ROOT=<location of root of OpenPiton extracted files>)
シミュレータ ホームを設定します(%export ICARUS_HOME=/usr)。プロビジョニングされたマシンへの Icarus のインストールは、github リポジトリで提供されるスクリプトにより実行されます。このような簡素化されたマシン構成は、クラウドのもう一つの利点であると言えます。
最後に、必要な設定を取得します(%source $PITON_ROOT/piton/piton_settings.bash)
この検証では、OpenPiton のシングルタイル設定、OpenPiton バンドルで提供される回帰スクリプト「sims」、「tile1_mini」回帰を使用しました。実行には、順次と同時の 2 種類を行いました。同時実行の管理は SLURM で行いました。
順次実行は、以下のコマンドを使用して行いました。
また、分散実行を以下のコマンドを使用して行いました。
結果
「tile1_mini」回帰には 46 種類のテストがあります。46 種類の tile1_mini テストすべてを順次実行した場合、平均で 120 分かかりました。10 個の自動スケーリングされた SLURM ノードを使用して tile1_mini を同時実行した場合、21 分でこれを完了できました。これは、6 倍の改善です。
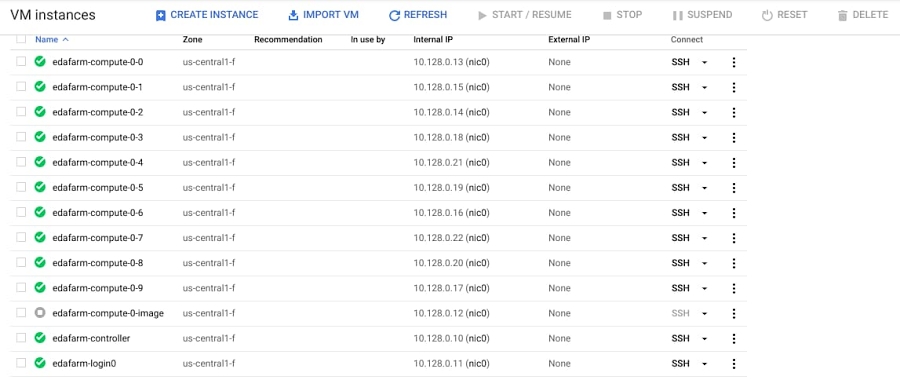
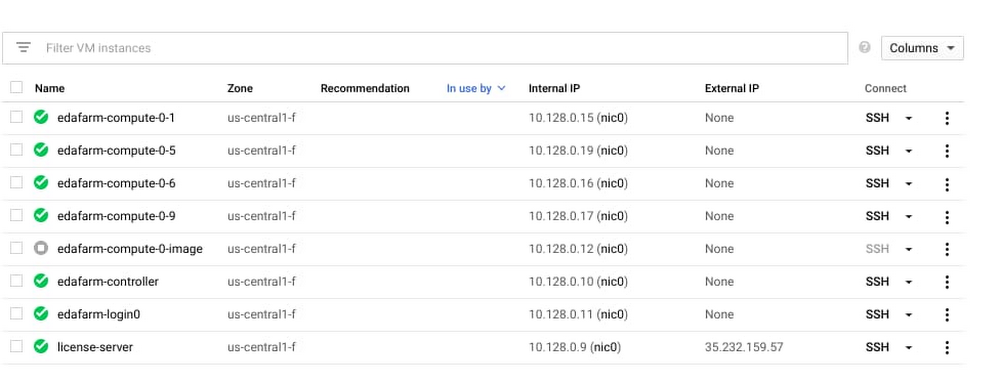
GCP Console での VM インスタンスの表示。ノード インスタンス edafarm-compute0-<0-9> は、回帰が開始されたときに作成される
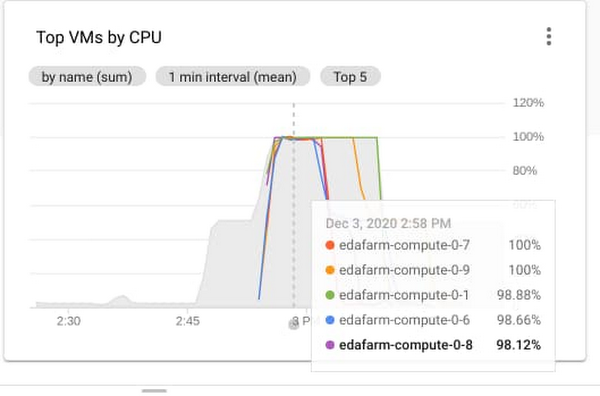
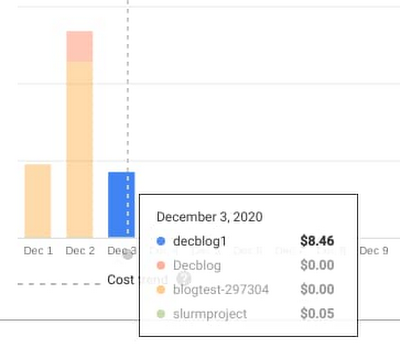
次に、自動スケーリングに関しても言及しておきましょう。この SLURM クラスタは、2 個の静的ノードと 10 個の動的ノードでセットアップされています。動的ノードは、分散実行が開始された直後に起動してアクティブになりました。ジョブがない場合はノードがシャットダウンされるため、実行が完了した後、クラスタは 0 ノードに自動スケーリングされます。このシミュレーションで使用した動的ノードにかかる追加コストは $8.46 でした。
上述の例は、ごく標準的なマシンを使用した単純な回帰実行を示しています。10 台を超えるマシンにスケールする機能を実装すれば、所要時間のさらなる改善が見込めます。実際には、プロジェクト チームにより何百万回ものシミュレーションがなされることが通常です。柔軟なコンピューティング能力を利用できるようになれば、検証プロセスを大幅に削減し、検証のサインオフを数か月単位で短縮できます。
その他の考慮事項
一般的なシミュレーション環境には、マルチコア マシンと大規模なコンピューティング ファームを幅広く活用する商用シミュレータが使用されます。Google Cloud インフラストラクチャであれば、さまざまなコア数、ディスクタイプ、メモリを使用して、種類豊富なマシンタイプ(多くの場合、「シェイプ」と呼ばれます)を構築できます。また、シミュレーションではシミュレータが正常に実行されたかどうかという情報しかわからないにもかかわらず、検証チームにはシミュレーションの結果を検証するというタスクがついて回ります。すべてのシミュレーション結果をキャプチャし、結果に基づいてフォローアップ タスクを提供する精巧なインフラストラクチャは、検証プロセス全体における必要不可欠な要素です。Cloud SQL や Bigtable などの Google Cloud ソリューションを使用すれば、高性能でスケーラビリティに優れた、フォールト トレラントなシミュレーションおよび検証環境を構築できます。さらに、AutoML Tables などのソリューションを使用すれば、検証フローに ML を組み込めます。
ご興味がありましたらぜひお試しください。
必要なスクリプトはすべて公開されています。試用するのにクラウドの経験はいりません。無料の Google Cloud クレジットを含め、Google Cloud には始めるために必要なものがすべて用意されています。Google Cloud のハイ パフォーマンス コンピューティング(HPC)の詳細については、こちらをクリックしてください。
-シリコン ソリューション チーフ アーキテクト Sashi Obilisetty
-ビッグデータ ソリューション アーキテクト Mark Mims
