TPU v5e で ML トレーニングを高速化する Accurate Quantized Training(AQT)のご紹介
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
AI モデルは拡大し続けており、エクサフロップス(10^18 FLOPS)単位の演算能力を持つ大規模なコンピューティング クラスタが求められています。大規模モデルによって新しい能力が可能になるなか、AI モデルのトレーニングやサービングの費用を引き下げることが、イノベーションのスピードを維持するのに重要になっています。
一般に、テンソル オペレーション(op)1とは、大規模な AI モデルのコンピューティングを最も駆使する部分です。最近発表された Cloud TPU v5e では、INT8 のテンソル op がデフォルトの BFLOAT16 のテンソル op よりも、最大 2 倍のスピードで実行できます。同様に、NVIDIA の一部の GPU でも、FLOAT8 または INT8 のテンソル op が BFLOAT16 のテンソル op よりも、最大 2 倍のスピードで実行可能です。これらの能力をうまく活用するには、特に本番環境で、包括的なソフトウェアのサポートが必要となります。
ここで重要になるのが量子化です。量子化によって、精度を下げた(例: INT8)オペレーション(すなわちテンソル オペレーション)ができるようになります。量子化は、最新の ML ハードウェアの効率を大幅に向上させる数少ない効果的な方法の一つです。量子化トレーニングによって、ML モデルのトレーニングのハードウェアにかかる費用を削減できます。
量子化トレーニングのスピードアップは難しい
モデル量子化アルゴリズムには、以下 3 つのファミリーがあります。
- ポストトレーニング量子化(PTQ)
- 量子化認識トレーニング(QAT)
- 量子化トレーニング(QT)
PTQ は、重み付けを BFLOAT16 から INT8(または同様の形式)に変換する処理です。トレーニング データやトレーニング用ハードウェアにアクセスする必要がないことが利点です。しかし、実際にサービングされるものとは違うモデルでトレーニングするため、しばしば品質の低さに悩まされます。高速の INT8 のテンソル オペレーションも通常使用しません。
QAT は、トレーニングやファインチューニング前のフォワードパスに量子化ロジックを導入し、PTQ を改良しています。そのためトレーニングでは量子化数値が考慮され、それに沿って学習できます。この処理によって容易にモデルの品質を向上できるようになります。QAT は、テンソル オペレーションの両方の入力を量子化することもでき、TPU v5e で推論時に INT8 のテンソル アクセラレーションを使用できるようになります。QAT のトレーニング期間は変わりません。
QT では、量子化をさらに一歩進めています。フォワードパスだけでなく、バックワード パス(勾配バックプロパゲーション)も量子化されています。これにより、QAT の利点すべてを維持しながら、トレーニング自体を加速できます。
適切なアルゴリズムがあったとしても、ソフトウェアの複雑さと量子化の計算オーバーヘッドのため、稼働中の実際のハードウェアで QT を動作させるのは困難です。これまでのところ、QT(バックプロパゲーションによる量子化含む)は、主として研究論文に限られています。しかし、オープンソースの AQT ライブラリでは、ソフトウェアやアルゴリズムの複雑さが背後に隠されているため、どんな本番環境モデルのオーナーでも QT の利点を得られます。ユーザーに対する TPU v5e の価値を高めて、QT の研究も大幅に簡素化できます。
Accurate Quantized Training(AQT)ライブラリの紹介
オープンソースの Accurate Quantization Training(AQT)ライブラリでは、JAX で、テンソル オペレーションを簡単に量子化するのに必要なソフトウェアをサポートしています。
AQT ライブラリの主な目的は、以下を同時に実現することです。
- 本番環境でのトレーニング パフォーマンスを向上
- 手作業のチューニングなしで、モデルの品質を向上
- シンプルで柔軟な API で本番環境、量子化の研究の両方に対応
詳細については、AQT README.md をご参照ください。
AQT の INT8 モードでハードウェアのパフォーマンスを向上
AQT のおかげで、大規模言語モデル(LLM)トレーニングのスピードが飛躍的に向上しました。以下の数値は、MaxText 16B と MLPerfTM 3.1 のトレーニングで計測した BFLOAT16 / INT8 のステップ時間率を示しています。
- MaxText 16B トレーニング: 9,054 ms / 7,268 ms = 124%
- MLPerfTM 3.1 GPT-3 175B トレーニング: 11,798 ms / 8,431 ms = 139%
AQT 構成と MaxText のモデル構成に関する詳細は、付録でご確認ください。すべて Google Cloud TPU v5e で実行されています。
MaxText のテストは、MLPerfTM 3.1 に追加の AQT 最適化(ローカル AQT)を実装する前に実施済みです。
AQT でモデルの品質を向上
AQT の INT8 と BFLOAT16 モデルでトレーニング損失の悪化として測定される品質の違いは、長時間のトレーニングでもほぼまったくありません。
わずかなモデルの違いを測定
量子化によるわずかな悪化を測定するには、トレーニングの損失から他の変動要因を取り除く必要があります。モデルの初期化とデータ生成のランダム化を制御し、決定的に学習するように MaxText を構成しました。この 2 つのいずれかによるトレーニング損失の変動は、量子化によるトレーニング損失の悪化よりも大きくなっています。
結果
量子化によるトレーニングの損失から量子化の品質を測定します。つまり、BF16 モデルと INT8 モデルのトレーニングの損失の差を測定します。トレーニングの損失において、量子化による悪化は 0.00133 です。これは、最終的なトレーニング損失の 0.1% 以下に相当します。この比較的軽微な損失と引き換えに、トレーニングのパフォーマンスは大幅に向上しており、AQT と INT8 の技術が、量子化されていない BFLOAT16 トレーニングと比較して有効であることがわかります。
以下のグラフは、量子化された 16B モデルと、量子化されていない 16B モデルのログ損失を示しています(構成詳細は付録参照)。
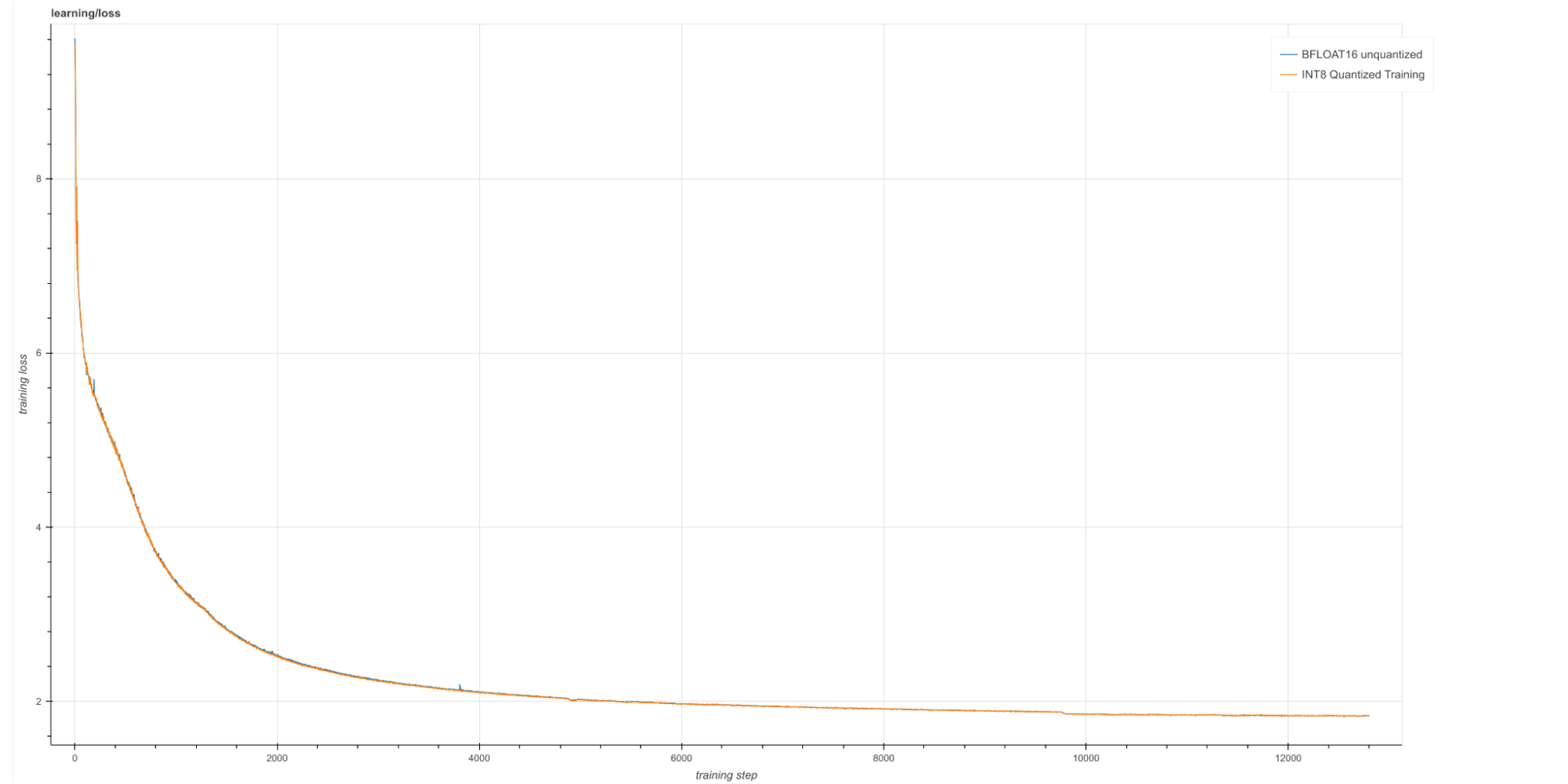
曲線が重なってしまうため、画像を拡大して見てみます。以下のグラフより、モデルの品質は実によく似ていることがわかります。
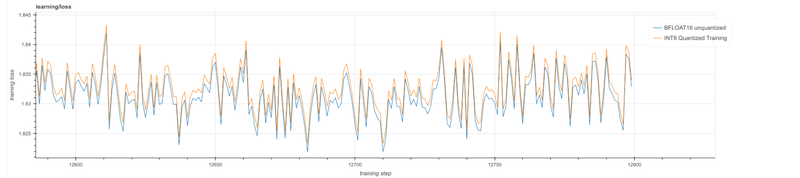
両者の違いをまとめるため最後の 500 のステップのトレーニング損失を平均すると、次のようになります。
- 1.8321251 - BFLOAT16 モデル
- 1.8334553 - AQT INT8 モデル
トレーニングとサービングするモデルが同じ
最後になりますが、AQT では、量子化されたモデルのフォワードパスは、トレーニング中もサービング中もまったく同じになります。これにより、一般的に PTQ で見られる量子化によるトレーニングとサービングでのバイアスによる問題を回避できます。
上述の全テストで、フォワードパスのほぼすべてのテンソル オペレーション(8 件中 7 件が対象、Transformer のアテンション モジュール内のテンソル オペレーション 1 件を除く)と、対応するバックワード パスのテンソル オペレーションも量子化しました。トレーニングの高速化とは別に、直接的な結果として、トレーニング済みモデルはすでに量子化されているため、推論ハードウェアの INT8 アクセラレーションの恩恵を受けているといえます。
AQT は誰でも利用可能な JAX で簡単に使える
JAX のテンソル オペレーションを量子化するのに必要なのは、jax.lax.dot_general 関数の量子化バリアントだけです。Google は、代替の dot_general を挿入できるように JAX を修正しました。量子化挿入は、Flax や Pax などのフレームワークや、NVIDIA の FP8 Transformer Engine などの量子化ライブラリで採用されています。
AQT のメインの API は、構成に基づき量子化された dot_general を作成する関数です。
以下の簡素化された MLP ブロックは、Flax Transformer モデルから引用され、AQT 挿入を使用したモデルの量子化がどれほど簡単かを示しています。
AQT は本番環境にも研究にも柔軟に対応
上記の例は、特定のデフォルト構成を使用していますが、構成システムにはもっと柔軟性があります。
次の config.DotGeneral では、フォワードパスのテンソル オペレーションと対応するバックワード パスのテンソル オペレーションを別々に構成できます。
それぞれの config.DotGeneralRaw で、各テンソルの量子化を個別に構成し、使用するハードウェアの dtype を構成できます(例: jnp.bfloat16、jnp.float16、jnp.float8_e4m3fn、jnp.float8_e5m2、jnp.int8、jnp.int4)。
config.Tensor では、各テンソルに使用される数値を構成できます(ビット数、調整アルゴリズム、確率的丸め、その他の量子化パラメータなど)。本稿公開時点では config.Tensor をリファクタリング中のため、コードは公開できません。現在の状況を確認するには、AQT README.md をご確認ください。
量子化研究: config.Tensor では、量子化の研究者がアルゴリズムの任意の部分にカスタムコードを挿入することもできます。これにより、大幅にコードを修正せず、カスタムの量子化アルゴリズムを簡単に試行できます。
以下の論文では、AQT の旧バージョンを適用しています。
- Pareto-Optimal Quantized ResNet Is Mostly 4-bit
- PokeBNN: A Binary Pursuit of Lightweight Accuracy(ImageNet 二値化)
- Binarized Neural Machine Translation(Transformer 二値化)
ハードウェア研究: AQT は柔軟性があり、すべてのハードウェア ベンダーに対応します。たとえ数値が公開されていなくても、最適な数値のものが各ベンダーのハードウェアから JAX で利用できます。
結論と次のステップ
AQT は、本番環境での品質の低下を最小限に抑えつつ INT8 を使用してトレーニングと推論を高速化する初のライブラリです。
詳細については、AQT README.md をご確認ください。
謝辞
この記事の執筆にご協力くださった Rafi Witten 氏、Matt Davidow 氏、Marcello Maggioni 氏、Tammo Spalink 氏に心より感謝いたします。
付録: モデル構成
MaxText のモデル構成
- 160 億のパラメータ: 32 層のデコーダーのみの Transformer。5,120 の埋め込みディメンション。
Chinchilla レベルのトレーニングが完全にできる最大モデル。 - C4 データセット
- 3,550 億のパディングされていないトークンで学習(「Chinchilla」のスケーリング「#tokens = 20x #weights」を使用)
- 4,096 の v5e TPU
量子化の構成
定義: 「INT8 量子化テンソル op」とは、テンソル オペレーションが両方の入力を INT8 として受け取り、INT32 か BF16 で累積することです。AQT の INT8 で使用されている計算の最も単純なバリアントに関する詳細は、本投稿の最後のセクションで説明します。
フォワードパスでは、各アテンションの特に影響を受けやすいテンソル オペレーション一つを除き、各 Transformer 層のすべてのテンソル オペレーションを INT8 で量子化しています。モデルのヘッド部分「ロジット」層も量子化しています。
フォワードパスの各テンソル オペレーションには、バックワード パスのテンソル オペレーションが 2 つあります。前の層の勾配を計算するオペレーション(バックプロップ スパイン)と、オプティマイザーに重みの勾配を与えるオペレーションです。
フォワードパスで量子化された各テンソル オペレーションには、バックプロップのテンソル オペレーションの一つを INT8 で量子化します。もう一つは BF16 の入力を使用します。
すでにローカル AQT がある MLPerf のテストでは、両方のバックプロップのテンソル オペレーションを量子化しました。
付録: AQT の仕組みについて
このセクションのコードは、Google Colab で実行できます。稼働するコードを提示していますが、AQT のチュートリアルではありません。本コードは、AQT の内部の動作と、高い品質を実現できる理由を説明します。
コード
このセクションでは、下記について説明します。
- JAX で量子化アクセラセーションを実現する方法
- AQT INT8 の内部動作の解説(最もシンプルな INT8 構成を使用)
- シンプルな例でコード実行
matmul_true_int8 は、入力として true の INT8 を受け取り、INT32 を返します。これが、JAX で量子化された matmul のハードウェア アクセラレーションを実現する方法です。
ランダムなデータを次に生成します。
これが最もシンプルな構成での AQT の内部の仕組みです。
「batch」、「channels」、「w」、「a」など、ニューラル ネットワークを連想する名前を使用していますが、aqt_matmul_int8 アルゴリズムは、DNN に特化したものではありません。
batch の各例と channel の各出力は、それぞれ個別のスケールになります。これにより「w」と「a」の外れ値の影響が、1 行または 1 列のみに減り、厳密なキャリブレーションと品質の高い量子化を実現できます。
aqt_matmul_int8 と float matmul を比較すると以下のとおりです。
出力結果は非常に近いものでした。
本コードを分析すると、なぜ AQT がこれほど効率的なのか、その理由がわかります。特に、AQT をサンプルごとのスケールと、出力チャンネルごとのスケールで調整しています。これにより量子化が厳密に行えるようになり、量子化ノイズに惑わされることも減ります。重要なのは、分散型(collective)matmul の場合、マシン間の通信も減らすことができます。
1.この投稿における「テンソル オペレーション」とは、Transformer で使用される行列乗算、畳み込み、高次アナログのことです。例: jnp.einsum、flax.DenseGeneral、その他 JAX のテンソル オペレーション。Relu や LayerNorm のようなベクトル オペレーションは含まれません。現時点では、AQT はテンソル オペレーションのみを量子化します。
- 量子化研究者 Lukasz Lew
- 量子化研究者 Yichi Zhang

