Comment la détection de spam a amélioré notre support IT

Nicholaus Jackson
Business Analyst
Max Saltonstall
Developer Advocate
Essayer GCP
Les nouveaux clients peuvent explorer et évaluer Google Cloud avec des conditions exceptionnelles.
EssayerLes équipes IT, et particulièrement celles du support et du Helpdesk, ont besoin de pouvoir suivre les problèmes rencontrés par les utilisateurs. Dans l’idéal, elles doivent aussi pouvoir observer comment ces problèmes évoluent au fil du temps, notamment lors de changements de technologies ou de stratégies.
Imaginons un instant que vous soyez responsable d’une équipe chargée de distribuer les journaux dans un quartier. Chaque membre de l’équipe se voit attribuer une bicyclette et un itinéraire pour distribuer le journal à la bonne personne. Mais les itinéraires changent. Ils changent tous les jours. C’est le chaos !
Que faire quand les itinéraires changent constamment ? Dit autrement, comment fournir l’information nécessaire lorsque les contextes évoluent en permanence ?
En informatique aussi, nous rencontrons des défis similaires. Les frameworks spécialisés dans la gestion de ces problèmes, tels qu’ITIL 4, tendent à s’appuyer sur des catalogues de services prédéfinis et figés. Dans cette approche formalisée, chaque incident résolu par les IT est pris en compte et analysé. En combinant cette double approche – référentiel des services et comptabilisation documentée des incidents gérés par l’IT – , il est non seulement possible de comprendre la cause des problèmes rencontrés par un ou plusieurs utilisateurs mais également de déterminer comment pannes et incidents peuvent affecter tout un ensemble d’employés.
Chez Google, nous n’avons pas adopté cette démarche. Tout d‘abord, parce que nous plaçons les utilisateurs au centre de tout : notre priorité numéro 1 est de s’assurer qu’ils redeviennent productifs au plus vite en cas d’incident. Ensuite, parce que - tout comme les routes et les itinéraires ne sont jamais identiques même si les objectifs demeurent - les produits services et incidents évoluent sans cesse. Dit autrement, les utilisateurs se tournent vers notre Help Desk IT avec de nouveaux problèmes tous les jours.
Notre équipe du support technique, dénommée TechStop, est le guichet unique pour tous les problèmes informatiques. Elle assure le support des utilisateurs via les chats, l’email et les canaux vidéo. Elle doit sans cesse s’adapter aux nouveaux problèmes rencontrés par les Googlers et aux nouveaux produits que ces derniers utilisent. Afin d’anticiper les problèmes qui pourraient se poser, l'équipe TechStop a besoin d'un moyen pour cataloguer les outils, applications et services utilisés chez Google.
Si l’on reprend l’analogie avec les itinéraires de livraison des journaux, nous utilisions jusqu’ici une carte approximative, plutôt qu’une carte détaillée. Elle nous fournissait une taxonomie de services « suffisamment bonne » pour la plupart des cas d’usage. Et nous en tirions de la donnée utile mais qui manquait de granularité.
En quête d’innovation
La pandémie Covid-19 nous a poussés à porter un nouveau regard sur notre gestion évolutive des problèmes, notamment sur ceux informatiques rencontrés quotidiennement par les utilisateurs. Avec le confinement massif des collaborateurs et le développement à grande échelle du télétravail, nous avions besoin de vraiment mieux comprendre où les utilisateurs rencontraient des difficultés techniques. C’est un peu comme si tout un nouveau quartier était apparu du jour au lendemain mais que l’équipe de livraison des journaux restait la même avec davantage de territoire à couvrir et une carte des routes totalement nouvelle.
Par ailleurs, des outils de productivité utilisés quotidiennement, tels que Google Meet, ont connu une adoption exponentielle, provoquant des incidents et autres problèmes de montée en charge. Les équipes en charge de ces produits se sont tournées vers TechStop, cherchant de l’aide pour établir des priorités dans une liste de demandes de correction de bugs et de nouvelles fonctionnalités qui ne cessait de s’allonger jour après jour.
À cette occasion, nous avons réalisé que notre taxonomie « suffisamment bonne » des problèmes se révélait trop imprécise pour fournir de la donnée utile. Nous pouvions certes déterminer quels produits étaient les plus affectés mais pas réellement quels incidents nos utilisateurs rencontraient sur ces produits. Pire encore, les nouvelles difficultés propres au modèle du télétravail étaient masquées par le fait que notre catalogue ne pouvait être actualisé à temps pour tenir compte des évolutions rapides de l’éventail des problèmes.
S’inspirer de la Tech des Spams
En explorant d’autres initiatives lancées par Google, l’équipe TechStop a trouvé des exemples de solutions à des problèmes similaires, à savoir détecter rapidement de nouveaux modèles dans un environnement où les données évoluent très vite.
Gmail gère le filtrage du spam pour plus d'un milliard de personnes. Et ces ingénieurs ont depuis longtemps réfléchi à la question suivante : "Comment détecter rapidement une nouvelle campagne de spam ?". Les spammeurs envoient des messages en vrac très vite avec de légères variations de contenu (bruit, fautes d'orthographe, etc.). Dans la plupart des cas, les tentatives de classification des spams ressemblent à un jeu du chat et de la souris. Les experts ont besoin de temps pour établir de nouveaux modèles, temps mis à profit par les spammeurs pour faire varier leurs techniques.
L’utilisation d'un moteur d'identification de tendances axé sur du texte non structuré - s’appuyant sur un algorithme d’agrégation basée sur la densité (Density Clustering) non supervisé - a permis à Gmail de détecter plus rapidement les campagnes de spam éphémères.
Cette technique a inspiré TechStop, sa problématique étant similaire. Des produits qui changent rapidement entraînent en effet une très grande évolutivité des pratiques, tant chez les utilisateurs que chez les professionnels de l’IT chargés d’adresser leurs problèmes. Tout comme les campagnes de spam, les tickets saisis affichaient de légères différences d'orthographe et de choix de mots mais restaient similaires dans les problèmes exprimés.
Une question de densité
Contrairement à des approches plus rigides, telles que les algorithmes d’optimisation combinatoire basés sur un partitionnement en k-moyennes (algorithmes K-means), le partitionnement basé sur la densité se révèle mieux adapté aux grands ensembles de données très hétérogènes, susceptibles de contenir des partitions aux tailles radicalement différentes. Cette flexibilité permet d’adresser l’identification des problèmes à l’échelle de l’entreprise. Une telle identification requiert en effet d’être en mesure de détecter et isoler des incidents certes petits mais néanmoins significatifs parmi un ensemble vaste et stable de signaux.
Notre implémentation utilise ClustOn, une technologie interne avec une approche hybride qui intègre un partitionnement basé sur la densité. Mais un algorithme plus éprouvé comme DBSCAN — dont l’implémentation en open source est disponible via le module de clustering du kit scikit-learn — pourrait être exploité de manière très similaire.
Une solution intermédiaire avec le ML
S’appuyant sur les techniques de partitionnement de densité de Gmail, l’équipe TechStop a développé une solution robuste pour suivre les incidents et résoudre sa problématique de taxonomie. Avec un regroupement par densité, les groupes taxonomiques sont réorganisés en groupe de tendances fournissant un index des problèmes qui surgissent en temps réel au sein de l’entreprise. Plus important encore, ces groupes émergent naturellement et dynamiquement plutôt que d’être prédéfinis de façon empirique par les équipes du support technique.
En utilisant la technologie conçue pour adresser des milliards de comptes de messagerie, nous savions que nous pourrions gérer l'ampleur des demandes d'assistance de Google. Et les solutions seraient plus flexibles qu'une taxonomie bien définie, sans compromettre pour autant la pertinence ou la granularité.
L’équipe est allée encore plus loin en modélisant le comportement des partitionnements à l’aide d’une régression de Poisson (un célèbre modèle de prédiction utilisé sur les tableaux de contingence) afin d’implémenter des mesures de détection d’anomalies et alerter les équipes opérationnelles en temps réel des pannes et autres modifications mal exécutées. Avec une équipe réduite et cette nouvelle technologie, TechStop a pu automatiquement obtenir des informations granulaires qui auraient requis toute une équipe dédiée pour analyser manuellement chaque incident et les regrouper par similitude.
Combiner Machine Learning et Opérations a transformé les données de TechStop en une base de référence précieuse pour les gestionnaires de produits et les équipes d'ingénierie en charge de comprendre les problèmes auxquels les utilisateurs font face avec leurs produits, et ce à l’échelle de l’entreprise.
Comment fonctionne la solution
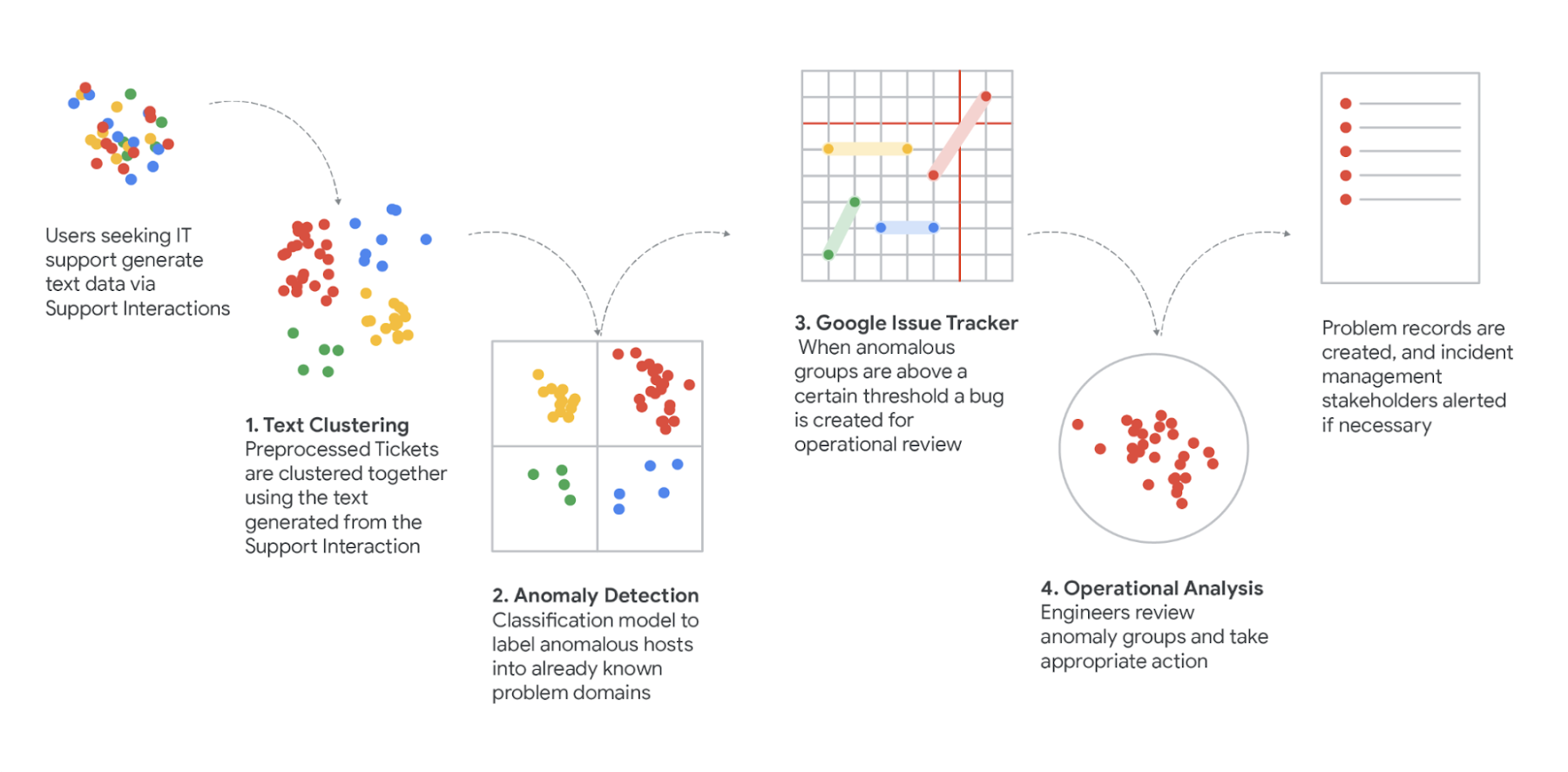
Pour assembler la solution, nous avons construit un pipeline ML dénommé Support Insights. Objectif : distiller automatiquement les données sommaires des nombreuses interactions et tickets reçus. Le pipeline Support Insights combine apprentissage machine (ML), validation humaine et analyse probabiliste en une approche unique de dynamique des systèmes.
Au fur et à mesure que les données traversent ce pipeline, elles sont :
- Extraites – en utilisant l’API BigQuery pour stocker, extraire, entraîner, charger et ingérer plus d’un million de données de support IT.
- Traitées avec un étiquetage morpho-syntaxique, une suppression des informations personnelles et une transformation des textes en chiffres (par une méthode TF-IDF) afin de modéliser les données de support pour nos algorithmes de regroupement.
- Regroupées à l’aide d’algorithmes de type K-Means exécutés par lots chronométrés avec une persistance des résultats des exécutions précédentes pour maintenir les identificateurs des regroupements et suivre le comportement de ces regroupements au fil du temps.
- Notées à l’aide d’une régression de Poisson pour modéliser à la fois le comportement à long terme et à court terme des tendances, mais aussi mesurer les écarts entre les deux. Ce score d'écart est utilisé pour détecter un comportement anormal dans une tendance.
- Exploitées – Les tendances avec un score anormal, autrement dit un score au-dessus d’un certain seuil, déclenchent une alerte via l’API IssueTracker. L’alerte est alors prise en charge par les équipes opérationnelles pour une analyse approfondie et un suivi de l’incident.
- Rééchantillonnées par des méthodes statistiques pour estimer les impacts d’expérience utilisateur (CUJs) au sein des tendances.
- Catégorisées/Cartographiées - Nous travaillons avec les équipes d'exploitation pour cartographier les impacts sur l’expérience utilisateur.
Dans un prochain billet, nous détaillerons les technologies et les méthodes que nous avons utilisées pour concrétiser ces sept étapes. Et nous expliquerons comment vous pouvez utiliser un pipeline similaire pour vos propres problématiques.
Mais avant cela, une étape préliminaire s’impose : chargez dès à présent vos données dans BigQuery et utilisez BigQuery ML pour regrouper vos données d'assistance.

