Cinq trucs et astuces pour optimiser vos workloads IA
Sean Derrington
Group Product Manager, Storage
Maciej Strzelczyk
Developer Programs Engineer
L’information ne vous a probablement pas échappé. Mais, au cas où, Google a récemment annoncé l’arrivée d’une version sans frais à usage individuel de Gemini Code Assist, notre assistant IA d’aide au codage. Cette technologie jusqu’ici réservée aux plus grandes entreprises devient ainsi accessible au plus grand nombre et notamment aux start-ups et aux développeurs indépendants.
De même, les infrastructures techniques nécessaires aux projets IA/ML — GPU ultra performants, TPU spécialisés et systèmes de stockage ultra-rapides — ne sont désormais plus réservées aux grands groupes : elles sont aujourd’hui accessibles à tous.
Malgré cette tendance vers une plus grande accessibilité, les entreprises doivent continuer d’optimiser leurs gros workloads IA, les ressources nécessaires pouvant encore se révéler assez coûteuses. Dès lors, l’optimisation des workloads est non seulement une tâche pertinente mais aussi essentielle pour maîtriser les dépenses.
Dans cet article, nous vous proposons cinq conseils concrets pour optimiser vos workflows IA sur Google Cloud Platform.
À noter : toutes les suggestions présentées dans cet article ne s’appliquent pas forcément à tous les cas d’usage. Il ne s’agit pas de recommandations officielles.
1. Comparez les différentes plateformes pour entraîner et déployer vos modèles
Il y a encore quelques années, entraîner, affiner ou déployer un modèle IA impliquait de configurer manuellement un cluster de machines équipées de GPU ou de TPU, d’orchestrer l’ensemble du pipeline d’apprentissage et de gérer avec précision toutes les ressources mobilisées par le processus. Avec Kubernetes, vous pouviez alléger un peu la charge de travail mais, globalement, les services permettant de simplifier cette mise en œuvre étaient rares et peu accessibles. Conséquence : les coûts additionnels étaient importants, en raison du matériel monopolisé qu’il fallait financer mais aussi du temps consacré à la gestion de toute cette infrastructure.
Mais ce temps est révolu ! Google Cloud propose aujourd’hui un large éventail de solutions, allant d’environnements entièrement managés à des plateformes entièrement personnalisables. À vous de choisir l’approche la plus adaptée à vos besoins.
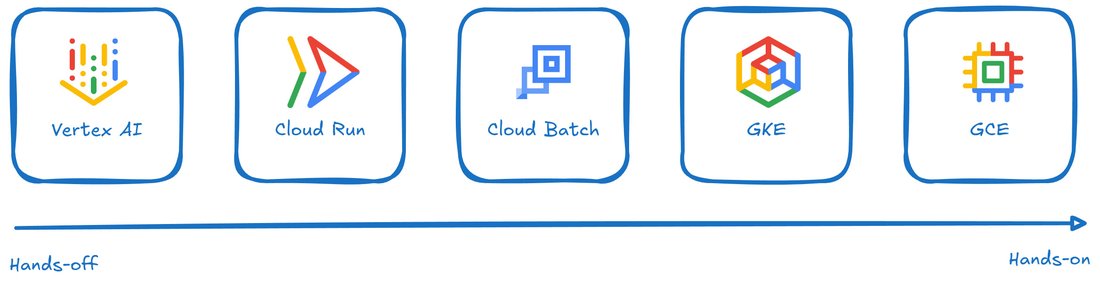
Voici un aperçu rapide des possibilités mises à votre disposition :
- Vertex AI est une plateforme unifiée et entièrement managée pour le développement de solutions IA. Entraînement, personnalisation, inférence : vous pouvez tout faire depuis une interface web simple et intuitive. Vous gagnez un temps précieux en déléguant à Google la gestion de l’infrastructure nécessaire à vos workloads IA. Et surtout, vous ne payez que ce que vous consommez — fini les GPU monopolisés à vide en attendant la prochaine tâche.
- Avec Cloud Run, vous pouvez désormais exécuter vos conteneurs sur des machines équipées de GPU. C’est la solution idéale pour déployer un service d’inférence scalable et entièrement managé, sans avoir à se familiariser avec de nouvelles plateformes.
- Cloud Batch permet également d’accéder à des GPU — une option particulièrement bien adaptée aux tâches longues, comme l’entraînement ou l’optimisation de modèles. Cloud Batch se charge automatiquement de provisionner l’infrastructure nécessaire, de relancer les jobs en cas d’erreur et de libérer les ressources une fois la tâche terminée. Combinée aux Spot Instances, la fonction de relance automatique des jobs peut entraîner une réduction significative des coûts.
- Google Kubernetes Engine (GKE) vous permet de conserver le contrôle sur l’infrastructure, tout en bénéficiant des avantages de l’automatisation sur le provisioning, la configuration et la gestion des ressources. C’est une solution particulièrement adaptée aux organisations qui utilisent déjà Kubernetes pour développer et exécuter leurs workloads IA et qui disposent de l’expertise nécessaire pour tirer pleinement parti du niveau de contrôle offert.
- Google Compute Engine (GCE) se situe à l’opposé de Vertex AI en matière de gestion automatisée. En accédant directement à des machines virtuelles équipées de GPU ou de TPU, vous gardez le contrôle total sur tous les aspects de vos workflows, de l’infrastructure aux paramètres d’exécution.
2. Optimisez le temps de démarrage de vos conteneurs d’inférence
Lorsque vous utilisez GKE ou Cloud Run, évitez d’intégrer directement vos modèles dans vos conteneurs. Minimiser la taille de vos conteneurs en externalisant le stockage des modèles sur des solutions telles Cloud Storage (with FUSE), Filestore ou des disques persistants en lecture seule.
Pourquoi ? Parce que des conteneurs trop volumineux, embarquant les modèles, ralentissent considérablement la montée en charge. Avant de pouvoir exécuter quoi que ce soit, les nœuds doivent télécharger ces images de conteneurs souvent très lourdes. Ce qui surcharge également le stockage local des nœuds, qui n’est pas conçu pour un très haut débit. En externalisant les modèles, vous les découplez du conteneur, ce qui accélère les temps de démarrage, facilite le scaling automatique et évite les points de contention sur les ressources locales.
Gardez à l’esprit que les conteneurs sont faits pour être temporaires et légers, et ne doivent contenir que l’essentiel. À l’inverse, les modèles sont volumineux et doivent être stockés sur le long terme. En les séparant et en optant pour un stockage externe, vous mettez en place un déploiement plus rapide, plus fluide, plus scalable et plus efficace.
Si vous ne pouvez pas modifier les conteneurs avec lesquels vous travaillez, GKE propose une option de disque de démarrage secondaire pour accélérer le lancement des nouveaux nœuds. Ces derniers démarrent alors avec un disque supplémentaire contenant déjà certaines images de conteneur préchargées. Et puisque l’on parle d’optimisation des temps de démarrage, jetez un œil à la fonctionnalité Image streaming de GKE, qui permet d’accélérer le lancement de n’importe quel workload — et pas uniquement ceux liés à l’IA.
3. Stocker n’est pas aussi simple qu’il y paraît
Les projets de machine learning nécessitent généralement d’énormes volumes de données — allant de plusieurs centaines de téraoctets à plusieurs pétaoctets — pour produire des résultats pertinents, en particulier lorsqu’ils impliquent des données non textuelles ou des modèles multimodaux. Maximiser l’utilisation des GPU/TPU lors de l’entraînement, du checkpointing (sauvegarde périodique de l’état des modèles en cours d’entraînement) ou de l’inférence est essentiel, mais la tâche est rarement triviale.
Pour des workloads IA plus modestes, avec quelques nœuds et quelques téraoctets de données, notre service Filestore offre une solution NFS simple et efficace.
Pour les entreprises dont les workloads IA ont été développés pour consommer directement du stockage objet, Cloud Storage est un service entièrement managé, capable de gérer des workloads IA/ML à très grande échelle. Toutefois, de nombreux cas d’usage IA requièrent une interface de type système de fichiers. Cloud Storage FUSE permet de monter des buckets Cloud Storage comme un système de fichiers local. Attention : Cloud Storage FUSE n’est pas entièrement conforme à la norme POSIX (Portable Operating System Interface), ce qui implique des limitations par rapport à un système de fichiers classique qu’il convient de bien comprendre. Cloud Storage FUSE permet néanmoins d’accéder aux données d’entraînement, aux modèles et aux checkpoints avec la scalabilité, les performances et les coûts optimisés de Cloud Storage.
Pour les workloads nécessitant une latence très faible et utilisant des fichiers de petite taille, Parallelstore est un système de fichiers parallèle temporaire, entièrement managé sur Google Cloud. C’est la solution idéale pour les charges IA/ML ayant besoin d’un accès en dessous de la milliseconde, avec un débit élevé et un grand nombre d’opérations d’E/S par seconde (IOPS). Vous pouvez consulter l’architecture de référence pour faciliter sa mise en œuvre en suivant ce lien.
Enfin, selon vos besoins en matière de mise en production, Hyperdisk ML est une solution de stockage haute performance, particulièrement adaptée aux tâches nécessitant un très haut débit agrégé (~1 To/s), avec un support jusqu’à 2 500 machines virtuelles en parallèle.
4- Exploitez DWS et/ou Future Reservations pour garantir l’accès aux ressources dont vous avez besoin
Ne pas disposer des ressources nécessaires pour exécuter des workloads intensifs peut rapidement entraîner des surcoûts. Vous avez tout préparé : les données sont prêtes, le pipeline est en place… mais il n’y a pas assez de GPU disponibles. Ce type d’imprévu ne génère pas toujours un coût direct immédiat, mais le temps perdu à réorganiser votre planning et à chercher les ressources manquantes ralentit votre projet — et le temps, c’est de l’argent. Pour éviter ce genre de problèmes, Google Cloud propose deux solutions : Dynamic Workload Scheduler et Future Reservations.
Future Reservations (réservations anticipées) fonctionne comme son nom l’indique : cette solution permet de réserver à l’avance des ressources cloud (GPU, TPU, etc.) que vous prévoyez d’utiliser ultérieurement. Une fois la réservation confirmée par le système, vous avez la garantie que les ressources seront disponibles au moment prévu. Elles vous sont allouées exclusivement, et vous pouvez les utiliser comme bon vous semble, tant que la réservation est active. Attention : ces ressources vous seront facturées, qu’elles soient utilisées ou non !
Dynamic Workload Scheduler (DWS) est une plateforme backend utilisée par plusieurs produits Google Cloud, conçue pour faciliter l’accès à du matériel très demandé. Grâce à ses modes Flex et Calendar, DWS vous évite de perdre du temps à attendre que des GPU se libèrent au compte-gouttes, au fur et à mesure qu’ils ne sont plus utilisés par d’autres clients. C’est un moyen efficace d’optimiser votre temps et vos coûts. Pour en savoir plus sur le fonctionnement de DWS et son intégration dans l’écosystème Google Cloud, vous pouvez consulter cette vidéo.
5- Utilisez des images disque personnalisées pour accélérer vos déploiements
Exécuter des workloads IA sur des machines virtuelles nécessite souvent une phase de configuration lourde. Il faut un système d’exploitation à jour, les bons pilotes GPU, ainsi que les frameworks IA comme JAX, PyTorch ou TensorFlow, installés et configurés correctement. Si vous partez d’une image système « propre », la mise en place complète de cette configuration peut facilement prendre jusqu’à une heure, — selon la version du système d’exploitation utilisé et les outils que vous choisissez d’installer. Autant dire qu’il serait bien plus logique de ne faire cette configuration qu’une seule fois, non ?
C’est précisément l’intérêt des images disque personnalisées. Une fois votre VM correctement configurée avec tous les logiciels nécessaires, vous pouvez l’arrêter, créer une image disque à partir de ce système, et ainsi lancer en quelques secondes de nouvelles instances prêtes à l’emploi à partir de cette image disque personnalisée.
Pour simplifier encore plus votre quotidien, vous pouvez utiliser nos services image families et managed instance groups. Google Cloud gérera alors automatiquement les mises à jour progressives de votre environnement de travail.
Pour aller plus loin
Pour rester informé des dernières actualités et évolutions de Google Cloud, voici quelques ressources utiles :
- Abonnez-vous à notre chaîne YouTube (ou à notre chaîne destinée à un public moins technique)
- Suivez notre blog ( ou via flux RSS)
- Inscrivez-vous à notre newsletter
- Rejoignez le programme Google Cloud Innovators

