À quel point votre IA est-elle performante ? Guide d’évaluation de l’IA générative étape par étape
Ivan Nardini
Developer Relations Engineer
Irina Sigler
Product Manager, Cloud AI
Progressivement, l’IA est passée du stade d’expérimentation prometteuse à celui de levier stratégique pour l’entreprise. Cette évolution modifie la nature des enjeux : la vraie question aujourd’hui n’est plus « Que peut-elle faire ? », mais « À quel point est-elle efficace dans ce qu’elle fait ? ».
Garantir la qualité, la fiabilité et la sécurité de vos applications IA est devenu un impératif stratégique. Pour y parvenir, l’évaluation continue doit devenir un réflexe et s’imposer comme une pratique structurante, capable de guider vos décisions à chaque étape du cycle de développement. De la formulation du « bon » prompt au choix du « bon » modèle, du « tuning » à l’analyse des agents, seule une évaluation rigoureuse permet d’y voir clair et de faire les bons choix.
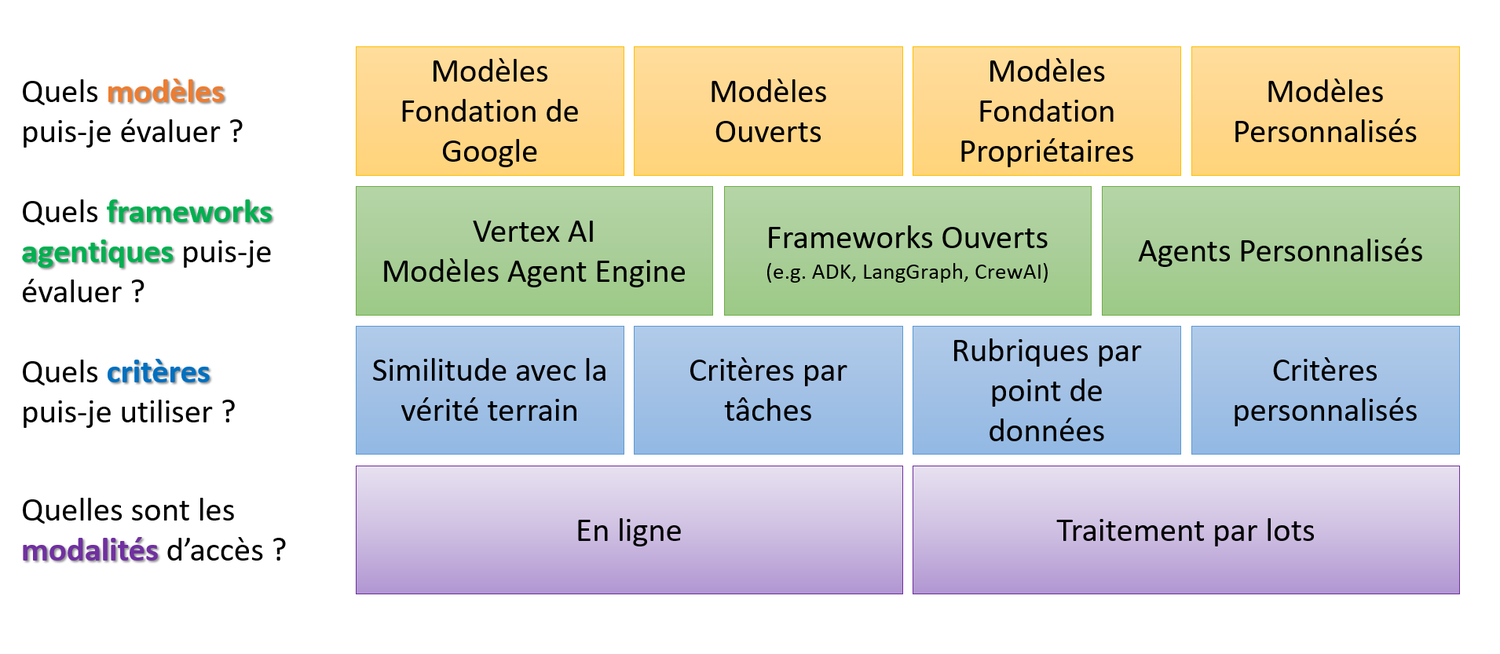
Il y a un an, nous avons lancé Gen AI Evaluation Service, solution permettant de mesurer la performance de différents types de modèles, à commencer par celle des modèles fondation de Google mais aussi des modèles open source, des modèles fondation propriétaires ou encore des modèles personnalisés. Ce service proposait jusqu’ici des modes d’évaluation en ligne, basés sur des critères individuels (pointwise) et comparatifs (pairwise), en utilisant des calculs automatisés et un évaluateur intelligent « Autorater ».
Depuis, nous avons attentivement écouté vos retours et concentré nos efforts sur vos priorités en matière d’évaluation. C’est pourquoi nous sommes ravis de présenter aujourd’hui les nouvelles fonctionnalités dans Gen AI Evaluation Service, conçues pour vous aider à passer à l’échelle, évaluer et personnaliser votre « Autorater » avec des rubriques et grilles de scoring, et mesurer l’efficacité de vos agents en conditions réelles.
1. Évaluez l’IA générative à grande échelle avec le mode batch
En matière d’IA, les développeurs se posent régulièrement la question suivante : « Comment évaluer à grande échelle ? ». Jusqu’à présent, la mise en œuvre de ce genre d’évaluation supposait un gros travail d’ingénierie avec des infrastructures lourdes à maintenir et donc une explosion des coûts. Il fallait souvent construire sa propre architecture pour gérer les traitements batch en combinant plusieurs services Google Cloud.
Notre nouvelle fonctionnalité d’évaluation en mode batch simplifie radicalement ce processus. Elle propose une API unique pour traiter efficacement des jeux de données volumineux, tout en exploitant l’ensemble des méthodes et métriques proposées par le service Gen AI Evaluation Service de Vertex AI. Le tout, avec des performances optimisées et un coût réduit par rapport aux approches précédentes.
Vous pouvez en savoir plus sur l’évaluation batch avec l’API Gemini dans Vertex AI en consultant ce tutoriel.
2. Examinez votre “Autorater” à la loupe et construisez la confiance
Autre question récurrente - et fondamentale - que se posent les développeurs : « Comment personnaliser et évaluer réellement mon “Autorater” ? ». Utiliser un LLM pour évaluer une application basée sur un autre LLM permet de gagner en efficacité et de rapidement passer à l’échelle. C’est le principe même de l’Autorater. Mais cela soulève aussi des interrogations légitimes autour des limites de la solution, de sa robustesse ou encore des biais que cette approche peut introduire. Dès lors, la question centrale devient celle de la fiabilité des résultats produits.
Cette confiance ne se décrète pas : elle se construit, par la transparence et le contrôle. Forts de cette conviction, nous avons prévu de nouveaux outils qui permettent d’analyser en profondeur votre Autorater et de l’améliorer. Ils reposent sur deux fonctionnalités clés :
- Evaluation de la qualité de votre Autorater. Tout d’abord, en constituant un jeu de données de référence annoté par des humains, vous pouvez comparer directement les évaluations de l’Autorater à votre « vérité de terrain ». Cela vous permet de calibrer ses performances, de mesurer son alignement avec vos attentes et d’identifier précisément les axes d’amélioration.
- Amélioration de l’alignement de votre Autorater. Dans un second temps, vous pouvez personnaliser son comportement en utilisant différentes approches : affiner le prompt en y intégrant des critères précis, un raisonnement en chaîne de pensée (chain-of-thought reasoning) ou encore des grilles de scoring détaillées ; exploiter des réglages avancés ; importer vos propres jeux de données de référence afin d’entraîner ou d’ajuster l’Autorater. Et ainsi vous vous assurez qu’il s’adapte réellement à vos besoins et couvre tous les cas d’usage, y compris les plus spécifiques.
Les nouvelles options de personnalisation d’Autorater ouvrent la voie à des analyses sur mesure. Voici un aperçu du type d’analyse que vous pouvez désormais construire grâce à ces fonctionnalités évoluées :

Pour en savoir plus sur ce sujet, consultez notre série sur la personnalisation avancée des modèles de notation, « Advanced judge model customization series », dans la documentation officielle : vous y découvrirez en détail comment évaluer et configurer votre modèle d’évaluation (Autorater). Pour un exemple concret, ce tutoriel montre comment personnaliser vos évaluations à l’aide d’un Autorater en open source pour Vertex AI Gen AI Evaluation.
3. Evaluer avec une grille de notation (scoring)
Évaluer des applications d’IA complexes peut vite devenir frustrant : comment appliquer un ensemble de critères fixes quand chaque entrée est différente ? Dès que l’on traite des cas multimodaux sophistiqués, comme la compréhension d’images, une simple liste de critères génériques s’avère insuffisante pour saisir toutes les subtilités. Pour dépasser ce problème, notre fonctionnalité d’évaluation pilotée par « grille de scoring » décompose le processus en deux étapes :
- Étape 1 — Génération de grilles de scoring sur mesure
Au lieu d’obliger l’utilisateur à fournir une liste figée de critères, le système se comporte comme un concepteur de tests personnalisés. Pour chaque point de données de votre jeu d’évaluation, il produit automatiquement une grille de scoring unique : des critères précis et mesurables adaptés au contenu concerné. Vous pouvez ensuite vérifier ces grilles et les ajuster si besoin. - Étape 2 — Évaluation ciblée par l’Autorater
L’Autorater applique ensuite ces grilles personnalisées pour évaluer la réponse de l’IA : il agit un peu comme un enseignant qui adapte l’énoncé à chaque élève selon le sujet de sa dissertation, plutôt que de poser les mêmes questions génériques à toute la classe.
Ce processus garantit que chaque évaluation reste contextualisée et apporte des enseignements pertinents. Il renforce l’interprétabilité : chaque score est relié à des critères directement adaptés à la tâche, ce qui vous permet d’obtenir une mesure beaucoup plus fidèle de la performance réelle de votre modèle.
Voici, ci-dessous, un aperçu concret du type d’évaluation comparative et structurée que vous pourrez orchestrer, en vous appuyant sur une grille de critères, grâce au service d’évaluation Gen AI intégré à Vertex AI.

Pour aller plus loin, n’hésitez pas à consulter nos exemples d’évaluations basées sur une grille de scoring appliquées au suivi d’instructions, aux scénarios multimodaux et à la qualité du texte. Par ailleurs, nous avons collaboré avec notre équipe de recherche afin de déployer un Autorater piloté par grille de scoring pour les cas text-to-image (du texte à l’image) et text-to-video (du texte à la vidéo).
4. Évaluer vos agents
Nous entrons dans l’ère agentique avec des agents IA capables de raisonner, de planifier et d’utiliser des outils pour exécuter des tâches complexes en toute autonomie. Leur évaluation soulève de nouveaux défis. Il ne suffit plus d’examiner la réponse finale, il faut valider l’ensemble du processus décisionnel. L’agent a-t-il choisi le bon outil ? A-t-il suivi une séquence logique d’étapes ? A-t-il stocké et exploité les informations de façon efficace pour proposer une réponse personnalisée ? Ces questions clés déterminent la fiabilité d’un agent.
Pour relever ces défis, Gen AI Evaluation Service dans Vertex AI propose de nouvelles fonctionnalités dédiées à l’évaluation d’agents. Vous pouvez non seulement analyser la réponse finale de l’agent, mais aussi examiner sa « trajectoire », autrement dit la succession d’actions et d’appels d’outils qu’il utilise. Avec des métriques spécialisées sur cette trajectoire, vous pouvez évaluer la pertinence de son raisonnement.
Que vous travailliez avec Agent Development Kit, LangGraph, CrewAI ou tout autre framework, hébergé localement ou sur Vertex AI Agent Engine, vous pouvez vérifier si les actions de l’agent sont logiques et si les bons outils sont mobilisés au bon moment. Tous les résultats sont intégrés à Vertex AI Experiments, système robuste pour suivre, comparer et visualiser les performances, afin de concevoir des agents IA toujours plus fiables et efficaces.
En suivant ce lien, vous trouverez une documentation détaillée avec plusieurs exemples d’évaluation d’agents réalisés avec Gen AI Evaluation Service sur Vertex AI.
Enfin, nous sommes tout à fait conscients que l’évaluation demeure un terrain de recherche encore largement inexploré. Pour relever ces nouveaux défis, la collaboration est essentielle. C’est pourquoi nous travaillons avec des partenaires tels que Weights & Biases, Arize et Maxim AI. Ensemble, nous cherchons à résoudre des défis, tels que le problème du cold-start data (difficulté à évaluer ou entraîner un modèle avec peu ou pas de données initiales), l’évaluation multi-agents (comment évaluer des systèmes où plusieurs agents interagissent entre eux) ou encore la validation par la simulation d’agents en conditions réelles (créer des environnements réalistes pour tester les agents IA comme s’ils étaient en production).
Passez à l’action dès aujourd’hui
Prêt à déployer des applications LLM fiables et parées pour une mise en production sur Vertex AI ? Gen AI Evaluation Service répond aux besoins les plus fréquemment exprimés par les utilisateurs et propose une suite complète et puissante pour évaluer votre application IA. En vous permettant de passer vos évaluations à l’échelle, de renforcer la confiance dans votre Autorater et d’analyser des cas d’usage multimodaux ou pilotés par des agents, nous voulons renforcer la confiance et l’efficacité — afin que vos applications basées sur des LLM atteignent le niveau de performance attendu en production.
Consultez la documentation détaillée ainsi que les exemples de code pour tirer pleinement parti de Gen AI Evaluation Service.

