This tutorial explains the recommended method of creating a clustered Looker configuration for customer-hosted instances.
Overview
Customer-hosted deployments of Looker can run single-node or clustered:
- A single-node Looker application, the default configuration, has all the services that make up the Looker application running on a single server.
- A clustered Looker configuration is a more complex configuration, usually involving database servers, load balancers, and multiple servers running the Looker application. Each node in a clustered Looker application is a server running a single Looker instance.
There are two primary reasons an organization would want to run Looker as a cluster:
- Load balancing
- Improved availability and failover
Depending on the scaling issues, a clustered Looker may not provide the solution. For example, if a small number of large queries are using up the system memory, the only solution is to increase the available memory for the Looker process.
Load balancing alternatives
Before load balancing Looker, consider increasing the memory and possibly the CPU count of a single server that runs Looker. Looker recommends setting up detailed performance monitoring for memory and CPU utilization to ensure that the Looker server is properly sized for its workload.
Large queries need more memory for better performance. Clustering can provide performance gains when many users are running small queries.
For configurations with up to 50 users who use Looker lightly, Looker recommends running a single server at the equivalent of a large-sized AWS EC2 instance (M4.large: 8 GB of RAM, 2 CPU cores). For configurations with more users or many active power users, watch whether the CPU spikes or if users notice slowness in the application. If so, move Looker to a larger server or run a clustered Looker configuration.
Improved availability/failover
Running Looker in a clustered environment can mitigate downtime in the case of an outage. High availability is especially important if the Looker API is used in core business systems or if Looker is embedded into customer-facing products.
In a clustered Looker configuration, a proxy server or load balancer will reroute traffic when it determines that one node is down. Looker automatically handles nodes leaving and joining the cluster.
Required components
The following components are required for a clustered Looker configuration:
- MySQL application database
- Looker nodes (servers running the Looker Java process)
- Load balancer
- Shared file system
- Proper version of the Looker application JAR files
The following diagram illustrates how the components interact. At a high level, a load balancer distributes network traffic between clustered Looker nodes. The nodes each communicate to a shared MySQL application database, a shared storage directory, and the Git servers for each LookML project.
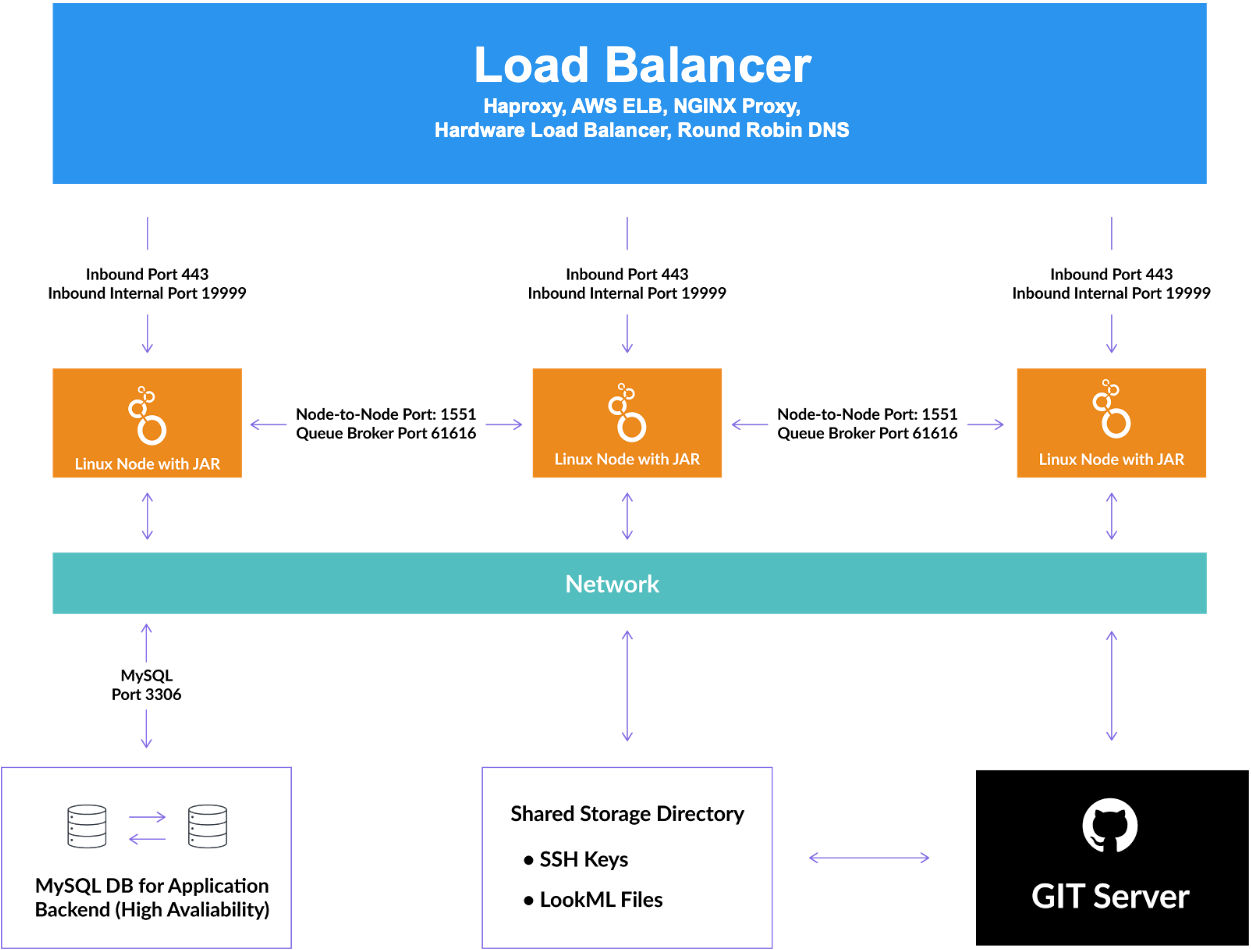
MySQL application database
Looker uses an application database (often called an internal database) to hold application data. When Looker is running as a single-node application, it normally uses an in-memory HyperSQL database.
In a clustered Looker configuration, each node's Looker instance must point at a shared transactional database (the shared application or internal database). Support for the application database for clustered Looker is as follows:
- Only MySQL is supported for the application database for clustered Looker instances. Amazon Aurora and MariaDB are not supported.
- MySQL versions 5.7+ and 8.0+ are supported.
- Clustered databases such as Galera are not supported.
Looker does not manage the maintenance and backups of that database. However, since the database hosts almost all the Looker application configuration data, it should be provisioned as a high-availability database and backed up at least daily.
Looker nodes
Each node is a server with the Looker Java process running on it. The servers in the Looker cluster need to be able to reach each other and the Looker application database. The default ports are listed in Open the ports for the nodes to communicate on this page.
Load balancer
To balance the load or redirect requests to available nodes, a load balancer or proxy server (for example, NGINX or AWS ELB) is required to direct traffic to each Looker node. The load balancer handles health checks. In the event of a node failure, the load balancer must be configured to reroute traffic to the remaining healthy nodes.
When choosing and configuring the load balancer, ensure that it can be configured to operate as Layer 4 only. The Amazon Classic ELB is one such example. In addition, the load balancer should have a long timeout (3,600 seconds) to prevent queries from being killed.
Shared file system
You must use a POSIX-compliant shared file system (such as NFS, AWS EFS, Gluster, BeeGFS, Lustre, or many others). Looker uses the shared file system as a repository for various pieces of information used by all the nodes in the cluster.
Looker application (JAR executable)
You must use a Looker application JAR file that is Looker 3.56 or later.
Looker strongly recommends that each node in a cluster run the same Looker release and patch version, as discussed in Start Looker on the nodes on this page.
Setting up the cluster
The following tasks are required:
- Install Looker
- Set up a MySQL application database
- Set up the shared file system
- Share the SSH key repository (depending on your situation)
- Open the ports for the nodes to communicate
- Start Looker on the nodes
Installing Looker
Ensure that you have Looker installed on each node, using the Looker application JAR files and the directions on the Customer-hosted installation steps documentation page.
Setting up a MySQL application database
For a clustered Looker configuration, the application database must be a MySQL database. If you have an existing non-clustered Looker instance that is using HyperSQL for the application database, you must migrate the application data from the HyperSQL data to your new shared MySQL application database.
See the Migrating to MySQL documentation page for information about backing up Looker and then migrating the application database from HyperSQL to MySQL.
Setting up the shared file system
Only specific file types — model files, deploy keys, plugins, and potentially application manifest files — belong in the shared file system. To set up the shared file system:
- On the server that will store the shared file system, verify that you have access to another account that can
suto the Looker user account. - On the server for the shared file system, log in to the Looker user account.
- If Looker is running, shut down your Looker configuration.
- If you were previously clustering using inotify Linux scripts, stop those scripts, remove them from cron, and delete them.
- Create a network share and mount it on each node in the cluster. Make sure that it is configured to automount on each node, and that the Looker user has the ability to read and write to it. In the following example, the network share is named
/mnt/looker-share. On one node, copy your deploy keys, and move your plugins and the
looker/modelsandlooker/models-user-*directories, which store your model files, to your network share. For example:mv looker/models /mnt/looker-share/ mv looker/models-user-* /mnt/looker-share/For each node, add the
--shared-storage-dirsetting to theLOOKERARGS. Specify the network share, as shown in this example:--shared-storage-dir /mnt/looker-shareLOOKERARGSshould be added to$HOME/looker/lookerstart.cfgso that the settings are not affected by updates. If yourLOOKERARGSare not listed in that file, then someone may have added them directly to the$HOME/looker/lookershell script.Each node in the cluster must write to a unique
/logdirectory — or at least a unique log file.
Sharing the SSH key repository
- You are creating a shared file system cluster from an existing Looker configuration, and
- You have projects that were created in Looker 4.6 or earlier.
Set up the SSH key repository to be shared:
On the shared file server, create a directory called
ssh-share. For example:/mnt/looker-share/ssh-share.Make sure the
ssh-sharedirectory is owned by the Looker user and the permissions are 700. Also, make sure that directories above thessh-sharedirectory (like/mntand/mnt/looker-share) are not world-writable or group-writable.On one node, copy the contents of
$HOME/.sshto the newssh-sharedirectory. For example:cp $HOME/.ssh/* /mnt/looker-share/ssh-shareFor each node, make a backup of the existing SSH file and create a symlink to the
ssh-sharedirectory. For example:cd $HOME mv .ssh .ssh_bak ln -s /mnt/looker-share/ssh-share .sshBe sure to do this step for every node.
Opening the ports for the nodes to communicate
Clustered Looker nodes communicate to each other over HTTPS with self-signed certificates and an additional authentication scheme based on rotating secrets in the application database.
The default ports that must be open between cluster nodes are 1551 and 61616. These ports are configurable by using the startup flags listed here. We highly recommend restricting network access to these ports to allow traffic only between the cluster hosts.
Starting Looker on the nodes
Restart the server on each node with the required startup flags.
Available startup flags
The following table shows available startup flags, including the flags that are required to start or join a cluster:
| Flag | Required? | Values | Purpose |
|---|---|---|---|
--clustered |
Yes | Add flag to specify that this node is running in clustered mode. | |
-H or --hostname |
Yes | 10.10.10.10 |
The hostname that other nodes use to contact this node, such as the node's IP address or its system hostname. Must be different from the hostnames of all other nodes in the cluster. |
-n |
No | 1551 |
The port for inter-node communication. The default is 1551. All nodes must use the same port number for inter-node communication. |
-q |
No | 61616 |
The port for queueing cluster-wide events. The default is 61616. |
-d |
Yes | /path/to/looker-db.yml |
The path to the file that holds the credentials for the Looker application database. |
--shared-storage-dir |
Yes | /path/to/mounted/shared/storage |
The option should point to the shared directory setup earlier on this page that holds the looker/model and looker/models-user-* directories. |
Example of LOOKERARGS and specifying database credentials
Place the Looker startup flags in a lookerstart.cfg file, located in the same directory as the Looker JAR files.
For example, you might want to tell Looker:
- To use the file named
looker-db.ymlfor its database credentials, - that it is a clustered node, and
- that the other nodes of the cluster should contact this host on IP address 10.10.10.10.
You would specify:
LOOKERARGS="-d looker-db.yml --clustered -H 10.10.10.10"
The looker-db.yml file would contain the database credentials, such as:
host: your.db.hostname.com
username: db_user
database: looker
dialect: mysql
port: 3306
password: secretPassword
And, if your MySQL database requires an SSL connection, the looker-db.yml file also requires the following:
ssl: true
If you don't want to store the configuration in the looker-db.yml file on disk, you can configure the environment variable LOOKER_DB to contain a list of keys and values for each line in the looker-db.yml file. For example:
export LOOKER_DB="dialect=mysql&host=localhost&username=root&password=&database=looker&port=3306"
Finding your Git SSH deploy keys
Where Looker stores Git SSH deploy keys depends on the release in which the project was created:
- For projects created prior to Looker 4.8, the deploy keys are stored in the server's built-in SSH directory,
~/.ssh. - For projects created in Looker 4.8 or later, the deploy keys are stored in a Looker-controlled directory,
~/looker/deploy_keys/PROJECT_NAME.
Modifying a Looker cluster
After creating a Looker cluster, you can add or remove nodes without making changes to the other clustered nodes.
Updating a cluster to a new Looker release
Updates may involve schema changes to Looker's internal database that wouldn't be compatible with previous versions of Looker. To update Looker, there are two methods.
Safer method
- Create a backup of the application database.
- Stop all of the cluster's nodes.
- Replace the JAR files on each server.
- Start each node one at a time.
Faster method
To update using this faster but less complete method:
- Create a replica of Looker's application database.
- Start a new cluster pointed at the replica.
- Point the proxy server or load balancer to the new nodes, after which you can stop the old nodes.