This page shows you how to resolve issues related to load balancing in Google Kubernetes Engine (GKE) clusters using Service, Ingress, or Gateway resources.
If you need additional assistance, reach out to Cloud Customer Care.BackendConfig not found
This error occurs when a BackendConfig for a Service port is specified in the Service annotation, but the actual BackendConfig resource couldn't be found.
To evaluate a Kubernetes event, run the following command:
kubectl get event
The following example output indicates your BackendConfig was not found:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
To resolve this issue, ensure you have not created the BackendConfig resource in the wrong namespace or misspelled its reference in the Service annotation.
Ingress security policy not found
After the Ingress object is created, if the security policy isn't properly associated with the LoadBalancer Service, evaluate the Kubernetes event to see if there is a configuration mistake. If your BackendConfig specifies a security policy that does not exist, a warning event is periodically emitted.
To evaluate a Kubernetes event, run the following command:
kubectl get event
The following example output indicates your security policy was not found:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
To resolve this issue, specify the correct security policy name in your BackendConfig.
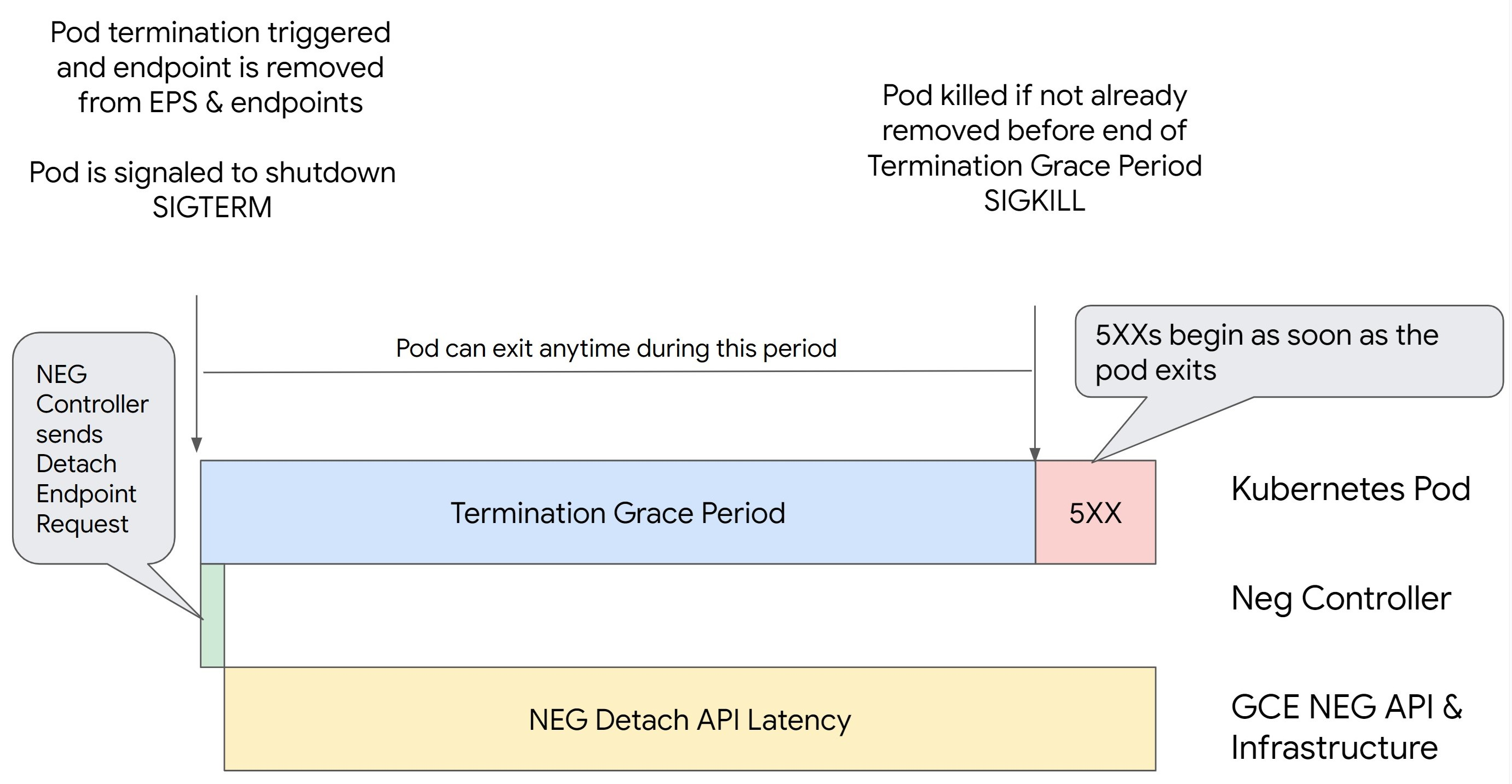
Addressing 500 series errors with NEGs during workload scaling in GKE
Symptom:
When you use GKE provisioned NEGs for load balancing, you might experience 502 or 503 errors for the services during the workload scale down. 502 errors occur when Pods are terminated before existing connections close, while the 503 errors occur when traffic is directed to deleted Pods.
This issue can affect clusters if you are using GKE managed load balancing products that use NEGs, including Gateway, Ingress, and standalone NEGs. If you frequently scale your workloads, your cluster is at a higher risk of being affected.
Diagnosis:
Removing a Pod in Kubernetes without draining its endpoint and removing it from
the NEG first leads to 500 series errors. To avoid issues during Pod
termination, you must consider the order of operations. The following images
display scenarios when BackendService Drain Timeout is unset and
BackendService Drain Timeout is set with BackendConfig.
Scenario 1: BackendService Drain Timeout is unset.
The following image displays a scenario where the BackendService Drain Timeout is
unset.
Scenario 2: BackendService Drain Timeout is set.
The following image displays a scenario where the BackendService Drain Timeout is set.

The exact time the 500 series errors occur depends on the following factors:
NEG API detach latency: The NEG API detach latency represents the current time taken for the detach operation to finalize in Google Cloud. This is influenced by a variety of factors outside Kubernetes, including the type of load balancer and the specific zone.
Drain latency: Drain latency represents the time taken for the load balancer to start directing traffic away from a particular part of your system. Once drain is initiated, the load balancer stops sending new requests to the endpoint, however there is still a latency in triggering drain (Drain Latency) which can cause temporary 503 errors if the Pod no longer exists.
Health check configuration: More sensitive health check thresholds mitigate the duration of 503 errors as it can signal the load balancer to stop sending requests to endpoints even if the detach operation has not finished.
Termination grace period: The termination grace period determines the maximum amount of time a Pod is given to exit. However, a Pod can exit before the termination grace period completes. If a Pod takes longer than this period, the Pod is forced to exit at the end of this period. This is a setting on the Pod and needs to be configured in the workload definition.
Potential resolution:
To prevent those 5XX errors, apply the following settings. The timeout values are suggestive and you might need to adjust them for your specific application. The following section guides you through the customization process.
The following image displays how to keep the Pod alive with preStopHook:

To avoid 500 series errors, perform the following steps:
Set the
BackendService Drain Timeoutfor your service to 1 minute.For Ingress Users, see set the timeout on the BackendConfig.
For Gateway Users, see configure the timeout on the GCPBackendPolicy.
For those managing their BackendServices directly when using Standalone NEGs, see set the timeout directly on the Backend Service.
Extend the
terminationGracePeriodon the Pod.Set the
terminationGracePeriodSecondson the Pod to 3.5 minutes. When combined with the recommended settings, this allows your Pods a 30 to 45 second window for a graceful shutdown after the Pod's endpoint has been removed from the NEG. If you require more time for the graceful shutdown, you can extend the grace period or follow the instructions mentioned in the Customize timeouts section.The following
BackendConfigmanifest specifies a connection draining timeout of 210 seconds (3.5 minutes):apiVersion: v1 kind: BackendConfig metadata: name: my-backendconfig spec: terminationGracePeriodSeconds: 210 containers: - name: my-app image: my-app-image:latest ports: - containerPort: 80Apply a
preStopHookto all containers.Apply a
preStopHookthat will ensure the Pod is alive for 120 seconds longer while the Pod's endpoint is drained in the load balancer and the endpoint is removed from the NEG.apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: my-app # Container configuration details... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"]
Customize timeouts
To ensure Pod continuity and prevent 500 series errors, the Pod must be alive
until the endpoint is removed from the NEG. Specially to prevent 502 and 503 errors,
consider implementing a combination of timeouts and a preStopHook.
To keep the Pod alive longer during the shutdown process, add a preStopHook to
the Pod. Run the preStopHook before a Pod is signaled to exit, so the
preStopHook can be used to keep the Pod around until its corresponding endpoint
is removed from the NEG.
To extend the duration that a Pod remains active during the shutdown process,
insert a preStopHook into the Pod configuration as follows:
spec:
containers:
- name: my-app
...
lifecycle:
preStopHook:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
You can configure timeouts and related settings to manage the graceful shutdown
of Pods during workload scale downs. You can adjust timeouts based on specific
use cases. We recommend that you start with longer timeouts and reduce the
duration as necessary. You can customize the timeouts by configuring
timeout-related parameters and the preStopHook in the following ways:
Backend Service Drain Timeout
The Backend Service Drain Timeout parameter is unset by default and has no
effect. If you set the Backend Service Drain Timeout parameter and activate
it, the load balancer stops routing new requests to the endpoint and waits
the timeout before terminating existing connections.
You can set the Backend Service Drain Timeout parameter by using the
BackendConfig with Ingress, the GCPBackendPolicy with Gateway or manually on
the BackendService with standalone NEGs. The timeout should be 1.5 to 2 times
longer than the time it takes to process a request. This ensures if a request
came in right before the drain was initiated, it will complete before the
timeout completes. Setting the Backend Service Drain Timeout parameter to a
value greater than 0 helps mitigate 503 errors because no new requests are sent
to endpoints scheduled for removal. For this timeout to be effective, you must
use it in conjunction with the preStopHook to ensure that the Pod remains
active while the drain occurs. Without this combination, existing requests that
didn't complete will receive a 502 error.
preStopHook time
The preStopHook must delay Pod shut down sufficiently for both Drain
latency and backend service drain timeout to complete, ensuring proper
connection drainage and endpoint removal from the NEG before the Pod is shut
down.
For optimal results, ensure your preStopHook execution time is less than
or equal to the sum of the Backend Service Drain Timeout and Drain Latency.
This can be calculated using the formula:
preStopHook >= Backend Service Drain Timeout + Drain Latency
We recommend setting the Drain Latency to 1 minute. If 500 errors persist, estimate the total occurrence duration and add double that time to the latency. This ensures that your Pod has enough time to drain gracefully before being removed from the service. You can adjust this value if it's too long for your specific use case.
Alternatively, you can estimate the timing by examining the deletion timestamp from the Pod and the timestamp when the endpoint was removed from the NEG in the Cloud Audit Logs.
Termination Grace Period parameter
You must configure the terminationGracePeriod parameter to allow sufficient
time for the preStopHook to finish and for the Pod to complete a graceful
shutdown.
By default, when not explicitly set, the terminationGracePeriod is 30 seconds.
You can calculate the optimal terminationGracePeriod using the formula:
terminationGracePeriod >= preStopHook Time + Pod shutdown time
To define terminationGracePeriod within the Pod's configuration as follows:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
NEG not found when creating an Internal Ingress resource
The following error might occur when you create an internal Ingress in GKE:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
This error occurs because Ingress for internal Application Load Balancers requires Network Endpoint Groups (NEGs) as backends.
In Shared VPC environments or clusters with Network Policies enabled,
add the annotation cloud.google.com/neg: '{"ingress": true}' to the Service
manifest.
504 Gateway Timeout: upstream request timeout
The following error might occur when you access a Service from an internal Ingress in GKE:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
This error occurs because traffic sent to internal Application Load Balancers are proxied by envoy proxies in the proxy-only subnet range.
To allow traffic from the proxy-only subnet range,
create a firewall rule
on the targetPort of the Service.
Error 400: Invalid value for field 'resource.target'
The following error might occur when you access a Service from an internal Ingress in GKE:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
To resolve this issue, create a proxy-only subnet.
Error during sync: error running load balancer syncing routine: loadbalancer does not exist
One of the following errors might occur when the GKE control plane upgrades or when you modify an Ingress object:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
Or:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
To resolve these issues, try the following steps:
- Add the
hostsfield in thetlssection of the Ingress manifest, then delete the Ingress. Wait five minutes for GKE to delete the unused Ingress resources. Then, recreate the Ingress. For more information, see The hosts field of an Ingress object. - Revert the changes you made to the Ingress. Then, add a certificate using an annotation or Kubernetes Secret.
External Ingress produces HTTP 502 errors
Use the following guidance to troubleshoot HTTP 502 errors with external Ingress resources:
- Enable logs for each backend service associated with each GKE Service that is referenced by the Ingress.
- Use status details to identify causes for HTTP 502 responses. Status details that indicate the HTTP 502 response originated from the backend require troubleshooting within the serving Pods, not the load balancer.
Unmanaged instance groups
You might experience HTTP 502 errors with external Ingress resources if your external Ingress uses unmanaged instance group backends. This issue occurs when all of the following conditions are met:
- The cluster has a large total number of nodes among all node pools.
- The serving Pods for one or more Services that are referenced by the Ingress are located on only a few nodes.
- Services referenced by the Ingress use
externalTrafficPolicy: Local.
To determine if your external Ingress uses unmanaged instance group backends, do the following:
Go to the Ingress page in the Google Cloud console.
Click the name of your external Ingress.
Click the name of the Load balancer. The Load balancing details page displays.
Check the table in the Backend services section to determine if your external Ingress uses NEGs or instance groups.
To resolve this issue, use one of the following solutions:
- Use a VPC-native cluster.
- Use
externalTrafficPolicy: Clusterfor each Service referenced by the external Ingress. This solution causes you to lose the original client IP address in the packet's sources. - Use the
node.kubernetes.io/exclude-from-external-load-balancers=trueannotation. Add the annotation to the nodes or node pools that do not run any serving Pod for any Service referenced by any external Ingress orLoadBalancerService in your cluster.
Use load balancer logs to troubleshoot
You can use internal passthrough Network Load Balancer logs and external passthrough Network Load Balancer logs to troubleshoot issues with load balancers and correlate traffic from load balancers to GKE resources.
Logs are aggregated per-connection and exported in near real time. Logs are generated for each GKE node involved in the data path of a LoadBalancer Service, for both ingress and egress traffic. Log entries include additional fields for GKE resources, such as: - Cluster name - Cluster location - Service name - Service namespace - Pod name - Pod namespace
Pricing
There are no additional charges for using logs. Based on how you ingest logs, standard pricing for Cloud Logging, BigQuery, or Pub/Sub apply. Enabling logs has no effect on the performance of the load balancer.
Use diagnostic tools to troubleshoot
The check-gke-ingress diagnostic tool inspects Ingress resources for common
misconfigurations. You can use the check-gke-ingress tool in the following
ways:
- Run the
gcpdiagcommand-line tool on your cluster. Ingress results appear in the check rulegke/ERR/2023_004section. - Use the
check-gke-ingresstool alone or as a kubectl plugin by following the instructions in check-gke-ingress.