Repurposing Neural Networks to Generate Synthetic Media for Information Operations
Mandiant
Written by: Philip Tully, Lee Foster
FireEye’s Data Science and Information Operations Analysis teams released this blog post to coincide with our Black Hat USA 2020 Briefing, which details how open source, pre-trained neural networks can be leveraged to generate synthetic media for malicious purposes. To summarize our presentation, we first demonstrate three successive proof of concepts for how machine learning models can be fine-tuned in order to generate customizable synthetic media in the text, image, and audio domains. Next, we illustrate examples in which synthetically generated media have been weaponized for information operations (IO), as detected on the front lines by Mandiant Threat Intelligence. Finally, we outline challenges in detecting synthetically generated content, and lay out potential paths forward in a future where synthetically generated media will increasingly look, speak, and write like us.
Background: Synthetic Media, Generative Models, and Transfer Learning
Synthetic media is by no means a new development; methods for manipulating media for specific agendas are as old as the media themselves. In the 1930’s, the chief of the Soviet secret police was photographed walking alongside Joseph Stalin before being retouched out of an official press photo, after he himself was arrested and executed during the Great Purge. Digital graphic manipulation like this became prominent with the advent of Photoshop. Then later in the 2010’s, the term “deepfake” was coined. While deepfake videos, including techniques like face swapping and lip syncing, are concerning in the long term, this blog post focuses on more basic, but we argue more believable, synthetic media generation advancements in the text, static image, and audio domains. Machine learning approaches for creating synthetic media are underpinned by generative models, which have been effectively misused to fabricate high volume submissions to federal public comment websites and clone a voice to trick an executive into handing over $240,000.
The pre-training required to produce models capable of synthetic media generation can cost thousands of dollars, take weeks or months of time, and require access to expensive GPU clusters. However, the application of transfer learning can drastically reduce the amount of time and effort involved. In transfer learning, we start from a large generic model that has been pre-trained for an initial task where copious data is available. We then leverage the model’s acquired knowledge to train it further on a different, smaller dataset so that it excels at a subsequent, related task. This process of training the model further is referred to as fine-tuning, which typically requires less resources compared to pre-training from scratch. You can think of this in more relatable terms—if you’re a professional tennis player, you don’t need to completely relearn how to swing a racket in order to excel at badminton.
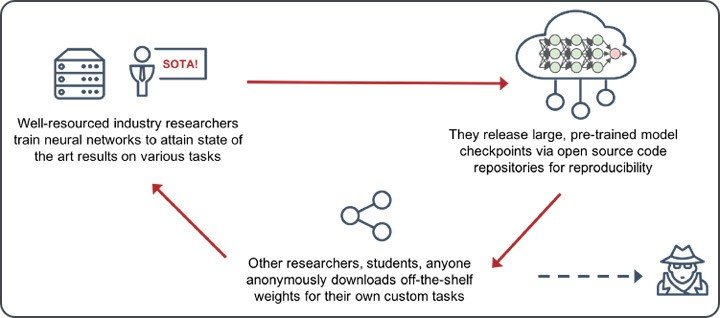
Figure 1: The culture of machine learning research has given rise to a rich open source model ecosystem.
In practice though, the benefits of transfer learning are only realized when people share their pre-trained models. As illustrated by Figure 1, it turns out that it’s commonplace for well-resourced industry and academic researchers to release their model checkpoints when their state of the art (SOTA) work gets accepted into a top-tier conference. Code is typically released in the form of GitHub repositories with extensive HOWTO guides and well-documented READMEs. This allows anyone to easily reproduce figures from the initial papers, and potentially use this source code as a starting point for their own research or projects. This process plays out on loop, ensuring a healthy, self-reinforcing model supply chain and ultimately a quicker pace of scientific innovation. However, while this emergent model sharing ecosystem beneficially lowers the barrier to entry for non-experts, it also gives a leg up to those seeking to leverage open source models for malicious purposes.
Just how much has this barrier to entry been lowered though? Fine-tuning can be performed in a fraction of the time, cost, data size, and compute compared to training models from scratch. Whether it's a cloud hosted notebook with GPU access, or a cloud GPU instance reservation for just a single day, we're talking on the order of just tens of dollars to fine-tune one of these models. Skill-wise, fine-tuning is not necessarily trivial, but it’s also not “brain surgery”—authors or other open source contributors often release additional code and tutorials for how to fine-tune.
The pre-trained models covered here were each released just within the last year, so the demonstrations in the next section should be seen through the lens of the present moment in time. However, open source releases are accelerating, and the bar for generating credible synthetic content will likely lower even further in the years to come.
See No Evil
As a first proof of concept, we’ll demonstrate how StyleGAN2 can be fine-tuned in order to generate custom portraits to impersonate a target individual. StyleGAN2, like its predecessor StyleGAN, is architected as a generative adversarial neural network (or GAN). GANs consist of 2 underlying networks that are pitted against each other (hence “adversarial”) - a generator, which generates new instances of data, and a discriminator, which evaluates these instances for authenticity by deciding whether each one belongs to the actual training dataset or not. If you generate images from pre-trained StyleGAN2 off-the-shelf, it outputs random, high quality, and highly diverse images that appear in a similar orientation as the images that it was pre-trained on. These images are not present in StyleGAN2’s original training set, but are completely fabricated from the generative model—these people in fact do not exist, and never have.
StyleGAN2 can also be fine-tuned on private datasets to generate outputs for custom tasks that the user of the open source model can control. As illustrated in Figure 2, we downloaded a few hundred images of Tom Hanks from online image search services, cropped them so that they were each face-centered and 512x512 pixels as required by the pre-trained model, and simply continued training StyleGAN2 by pointing it at this new smaller dataset using a slightly smaller learning rate. After less than a day of fine-tuning on a single GPU, we then used the fine-tuned StyleGAN2 model to generate arbitrarily many fake images of Mr. Hanks, which exhibit a high level of resemblance to his authentic online images. In theory, we could collect cropped images from any target of our choosing and perform the same exercise to generate arbitrarily many fake images of them.

Figure 2: By fine-tuning StlyeGAN2, we can cheaply generate fake portraits (e.g. three images on the right) belonging to a target of our choice, at scale, from freely available images of them on the Internet (e.g. three images on the bottom left).
Hear No Evil
As a second proof of concept, we’ll switch to the audio domain where we demonstrate how SV2TTS can be fine-tuned on audio samples in order to impersonate the voice of a target individual. SV2TTS is a complex, 3-stage model that can perform Voice Cloning—or text-to-speech from arbitrary text inputs to captured reference speech in real time. SV2TTS is comprised of three underlying neural networks – first, the speaker encoder is trained on thousands of speakers in order to learn an abstract representation of human speech and squeeze it into a compressed embedding of floating point values. Then the Synthesizer, which is based on Google’s TacoTron2, takes text as input and returns a mel spectrogram, a numerical representation of an individual’s voice. Lastly, the vocoder, based on DeepMind’s WaveNet, takes the mel spectrogram and converts it into an output waveform that can be heard and comprehended.
While pre-trained SV2TTS can be used to generate speech using arbitrary text from one of a few hundred or so voices, as shown in Figure 3 it can also be fine-tuned to generate speech in an arbitrary voice using arbitrary text. All we need to do is collect some audio samples, which are freely available to record via the Internet, load up a few of the resulting M4A files into the pre-trained SV2TTS model, and use it as a feature extractor to synthesize new speech waveforms. Using Mr. Hanks again as an example, we demonstrate the result of this process on a few pieces of input text that were chosen by us to resemble cell-phone quality commentary that is thematically representative of the types of narratives we see pushed in IO campaigns. While the specific examples here are somewhat robotic and show signs of inauthenticity, the timbre of the voice is (in our subjective view) similar to that of Mr. Hanks. Neither the text nor the voices exist in any of the original SVT2TTS training datasets. It's worth noting that we didn’t even need a GPU to do this – the pre-trained model was fine-tuned locally using a basic laptop’s CPU cores, which also suggests that quality improvements are possible with greater resourcing.

Figure 3: By fine-tuning SV2TTS, we can generate cell-phone quality speech audio from arbitrary targets using recorded audio or video files of them on the Internet (e.g. the three sample clips at the bottom left), then after fine-tuning make that speaker dictate arbitrary custom text that we control (see Sample 1, Sample 2 and Sample 3.).
Speak No Evil
Our last proof of concept is in the text domain, where we demonstrate how GPT-2 can be fine-tuned in order to generate custom social media posts reflecting narratives pushed in a social media IO campaign. GPT-2 is an open source neural network that was trained on the causal language modeling task, whose objective is to predict the next word in a sentence from previous context. A pre-trained model ends up being capable of language generation: if the model can predict the next word accurately, it can be used in turn to predict the following word, and then so on and so forth until eventually, the model produces fully coherent sentences and paragraphs.
The pre-trained GPT-2 model’s outputs display relatively formal grammar, punctuation, and structure that corresponds to the text present within their original prosaic dataset. To make GPT-2's generations appear more like posts we might expect to encounter scrolling through social media, with their shorter length, informal grammar, erratic punctuation, and syntactic quirks, we fine-tuned it on a new language modeling task using additional training data. This data consisted of open source social media posts from accounts operated by Russia’s famed Internet Research Agency or IRA “troll factory.” We fine-tuned GPT-2 on a single GPU for a few hours by processing these social media posts through the pre-trained model, whose activations were then fed through adjustable weights into a linear output layer. The resulting fake posts are short yet biting, express outrage regarding political issues, and contain idiosyncrasies like hashtags and emojis that positionally manifest at the end of the generated text.

Figure 4: By fine-tuning GPT-2, we can generate social media posts depicting semantic styles regularly exhibited by actual users. The three text samples on the right were produced by the model after fine-tuning.
Synthetic Media in the Wild
IO actors use various tactics that would be readily conducive to synthetic media augmentation. For example, one influence campaign we uncovered and dubbed "Distinguished Impersonator" involves falsifying journalist personas and reaching out to real-world experts and political figures to disingenuously solicit audio and video interviews that advance an Iranian political agenda. Another commonly used tactic is the development of cross-platform online personas that are used to infiltrate target groups or disseminate fabricated content to specific audiences, such as in the "Ghostwriter" campaign that has leveraged website compromises and used multiple well-developed personas to disseminate fabricated content aligned with Russian security interests. And other very common techniques include the use of appropriated photos of real individuals to backstop false personas, and the repeated use of identical text on social media to "astroturf" political commentary. Synthetic media has real potential to exacerbate the use and effectiveness of such tactics.
Indeed, we already frequently uncover false personas and networks of inauthentic social media accounts using artificially generated profile photos, and this use is widespread. For example, we’ve uncovered large networks of inauthentic social media accounts pushing pro-China narratives surrounding the Hong Kong democracy protests and the COVID-19 pandemic making significant use of artificially generated photos. We identified inauthentic accounts using synthetic profile photos in a recent operation that appeared designed to support government officials in a region of Argentina. And in a social media-driven influence operation that promoted pro-Cuban government and anti-US narratives, the operators behind one network of inauthentic accounts didn’t even bother to fully crop out the text box placed by the “thispersondoesnotexist” image generation tool stating that the images were generated with StyleGAN2, prior to use. The examples of artificially generated images we’ve seen actively used in IO campaigns presented in Figure 5 illustrate a common format observed, including closely cropped headshots with blurred backgrounds, anomalies around the ears, neck, and shoulders, difficulties with fully rendering accessories such as glasses and earrings, and phantom hair strings being generated outside a credible area.
But we can readily envision an escalation of this tactic, in which convincing personas are created using artificially generated profile photos trained on images of real people from a target group or geography that correspond to, say, a particular minority group, and are then used to instigate political conflict or incite animosity and violence. The use of synthetically generated audio interviews in a campaign resembling Distinguished Impersonator trained on a real political expert’s voice, would lower an actor’s burden by removing the need to convincingly engage in direct outreach to real people, which would also make attribution more difficult for investigators by reducing available investigative leads such as contact details and modes of communication between actor and target. And synthetic media would drastically lower barriers for actors seeking to disseminate diverse text-based content at scale, reducing the effort required to create a large corpus of written content and the need to repeatedly reuse snippets of identical text.

Figure 5: Suspected artificially generated profile photos we’ve seen actively used in IO campaigns, along with example markers of inauthenticity that often clue us into images being artificially generated.
Evading Detection
Synthetic media doesn’t need to be overwhelmingly credible to have its desired effect. People are used to consuming short, authoritative, error-riddled social media text at speed without dwelling too much on its linguistic features or origin. Users are accustomed to consuming poor-quality audio and video snippets, and the majority of users aren’t going to give a social media account’s profile image more than a cursory glance as they scroll through their feed and ingest written content at rapid speed. The quality bar does not need to be exceedingly high when it comes to synthetic generations; it only needs to be “good enough” for even just a subset of vocal users to not question it in a world characterized by rapid, high-volume information consumption.
The unifying theme behind the various potential IO applications discussed in the previous section is that they would materially help threat actors scale campaigns at low cost and better evade detection. Fine-tuning in particular presents a problem for blue teams, as it allows threat actors to better evade classifiers and detection models that are built for pre-trained outputs. This is worrisome as a would-be threat actor’s fine-tuning datasets would likely be private and unknown to the defender at test time. This concept is illustrated by the text-based detection experiments we conducted in Figure 6. After releasing GPT-2, OpenAI released source code along with a fine-tuned classifier based on RoBERTa, which does not share the same architecture or tokenizer as GPT-2, that can reliably discriminate between GPT-2's own output generations and its original pre-training data of high-Karma Reddit posts.
We used this RoBERTa model first to verify the findings that one can reliably differentiate between fabricated, GPT-2 generated text and the authentic GPT-2 pre-training dataset. When we performed the same exercise using the classifier to try to differentiate our fine-tuned IO text generations (i.e. those previously discussed in Figure 4), the accuracy significantly dropped. The fact that the pre-trained score distribution is skewed towards 1 means the detection model for pre-trained generations, with a classification threshold of 0.5, can easily classify the generations as “fake.” This results in an accuracy score of over 97% for the detection model, as shown in blue in Figure 6. However, detection accuracy dipped to around 78% for fine-tuned generations as the distribution of scores output by the classifier shifts closer to chance, as shown in red. So if threat actors were to fine-tune on a custom dataset they themselves collated, this could present a problematic asymmetry between the data used to create the synthetic generations and the data blue teams would have access to—or even knowledge of—with which to build a commensurate detection model. Text with shorter length was previously shown to be more difficult for detection models to classify, and while our tweet-inspired experiments corroborate this finding, further research is required to disentangle how different datasets, model complexities, input lengths, and hyperparameters will contribute to this effect in the cat-and-mouse future of generators versus detectors.

Figure 6: The first plot shows the scores returned by the detection models, and the second plot shows accuracies resulting from those scores.
Conclusion
Synthetic media generation continues to become cheaper, both monetarily and in terms of the computing power required, easier, more pervasive, and their outputs ever more credible. Image generation capabilities and even commercial services are already moving beyond merely headshots and facial generations to full-body shots and advanced video generations, and end users will enjoy increasing control over and ease of content generation, both through being able to steer generations towards particular attributes at more granular levels, and by being able to use an increasing amount of both free and commercial low-code or no-code applications for content creation.
This blog post highlights the need for the research community to continue to focus attention on the development of technical detection and mitigation capabilities for synthetic media, given its ready applicability to current information operations tactics. Multiple avenues of research can and should be pursued, including statistical approaches to detection like machine learning classifiers and model watermarking, as well as the signature-based identification of fingerprints and forensic indicators (e.g. Figure 5). Secondly, there’s the human aspect to all of this, including the importance of ensuring communities of researchers from different disciplines coalesce around approaches to overcoming the detection challenges, threat modeling how synthetic media may be deployed in future IO campaigns so that any potential effects can be pre-emptively addressed, and encouraging commercial providers of synthetic media generation capabilities to acknowledge and account for the potential abuse of their services by threat actors. Outside of community efforts, there also remains the need for raising awareness and educating consumers of social media and other content about the risks of synthetic media in a responsible manner that doesn’t misrepresent the threat, as well developing legal and regulatory approaches to dealing with information operations and synthetic media.
