GoStringUngarbler: Deobfuscating Strings in Garbled Binaries
Mandiant
Written by: Chuong Dong
Overview
In our day-to-day work, the FLARE team often encounters malware written in Go that is protected using garble. While recent advancements in Go analysis from tools like IDA Pro have simplified the analysis process, garble presents a set of unique challenges, including stripped binaries, function name mangling, and encrypted strings.
Garble's string encryption, while relatively straightforward, significantly hinders static analysis. In this blog post, we'll detail garble’s string transformations and the process of automatically deobfuscating them.
We're also introducing GoStringUngarbler, a command-line tool written in Python that automatically decrypts strings found in garble-obfuscated Go binaries. This tool can streamline the reverse engineering process by producing a deobfuscated binary with all strings recovered and shown in plain text, thereby simplifying static analysis, malware detection, and classification.
Garble Obfuscating Compiler
Before detailing the GoStringUngarbler tool, we want to briefly explain how the garble compiler modifies the build process of Go binaries. By wrapping around the official Go compiler, garble performs transformations on the source code during compilation through Abstract Syntax Tree (AST) manipulation using Go’s go/ast library. Here, the obfuscating compiler modifies program elements to obfuscate the produced binary while preserving the semantic integrity of the program. Once transformed by garble, the program’s AST is fed back into the Go compilation pipeline, producing an executable that is harder to reverse engineer and analyze statically.
While garble can apply a variety of transformations to the source code, this blog post will focus on its "literal" transformations. When garble is executed with the -literals flag, it transforms all literal strings in the source code and imported Go libraries into an obfuscated form. Each string is encoded and wrapped behind a decrypting function, thwarting static string analysis.
For each string, the obfuscating compiler can randomly apply one of the following literal transformations. We'll explore each in greater detail in subsequent sections.
-
Stack transformation: This method implements runtime encoding to strings stored directly on the stack.
-
Seed transformation: This method employs a dynamic seed-based encryption mechanism where the seed value evolves with each encrypted byte, creating a chain of interdependent encryption operations.
-
Split transformation: This method fragments the encrypted strings into multiple chunks, each to be decrypted independently in a block of a main switch statement.
Stack Transformation
The stack transformation in garble implements runtime encrypting techniques that operate directly on the stack, using three distinct transformation types: simple, swap, and shuffle. These names are taken directly from the garble’s source code. All three perform cryptographic operations with the string residing on the stack, but each differs in complexity and approach to data manipulation.
- Simple transformation: This transformation applies byte-by-byte encoding using a randomly generated mathematical operator and a randomly generated key of equal length to the input string.
- Swap transformation: This transformation applies a combination of byte-pair swapping and position-dependent encoding, where pairs of bytes are shuffled and encrypted using dynamically generated local keys.
- Shuffle transformation: This transformation applies multiple layers of encryption by encoding the data with random keys, interleaving the encrypted data with its keys, and applying a permutation with XOR-based index mapping to scatter the encrypted data and keys throughout the final output.
Simple Transformation
This transformation implements a straightforward byte-level encoding scheme at the AST level. The following is the implementation from the garble repository. In Figure 1 and subsequent code samples taken from the garble repository, comments were added by the author for readability.
// Generate a random key with the same length as the input string
key := make([]byte, len(data))
// Fill the key with random bytes
obfRand.Read(key)
// Select a random operator (XOR, ADD, SUB) to be used for encryption
op := randOperator(obfRand)
// Encrypt each byte of the data with the key using the random operator
for i, b := range key {
data[i] = evalOperator(op, data[i], b)
}Figure 1: Simple transformation implementation
The obfuscator begins by generating a random key of equal length to the input string. It then randomly selects a reversible arithmetic operator (XOR, addition, or subtraction) that will be used throughout the encoding process.
The obfuscation is performed by iterating through the data and key bytes simultaneously, applying the chosen operator between each corresponding pair to produce the encoded output.
Figure 2 shows the decompiled code produced by IDA of a decrypting subroutine of this transformation type.
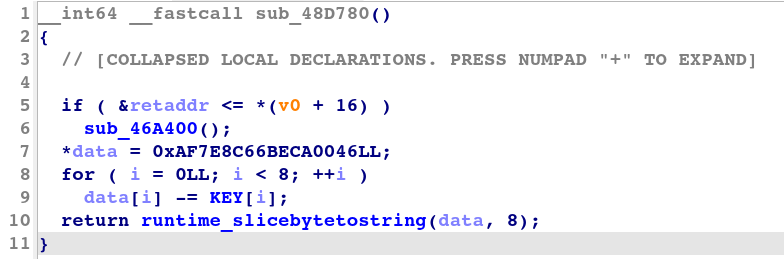
Figure 2: Decompiled code of a simple transformation decrypting subroutine
Swap Transformation
The swap transformation uses a byte-shuffling and encryption algorithm to encrypt a string literal. Figure 3 shows its implementation from the garble repository.
// Determines how many swap operations to perform based on data length
func generateSwapCount(obfRand *mathrand.Rand, dataLen int) int {
// Start with number of swaps equal to data length
swapCount := dataLen
// Calculate maximum additional swaps (half of data length)
maxExtraPositions := dataLen / 2
// Add a random amount if we can add extra positions
if maxExtraPositions > 1 {
swapCount += obfRand.Intn(maxExtraPositions)
}
// Ensure swap count is even by incrementing if odd
if swapCount%2 != 0 {
swapCount++
}
return swapCount
}
func (swap) obfuscate(obfRand *mathrand.Rand, data []byte)
*ast.BlockStmt {
// Generate number of swap operations to perform
swapCount := generateSwapCount(obfRand, len(data))
// Generate a random shift key
shiftKey := byte(obfRand.Uint32())
// Select a random reversible operator for encryption
op := randOperator(obfRand)
// Generate list of random positions for swapping bytes
positions := genRandIntSlice(obfRand, len(data), swapCount)
// Process pairs of positions in reverse order
for i := len(positions) - 2; i >= 0; i -= 2 {
// Generate a position-dependent local key for each pair
localKey := byte(i) + byte(positions[i]^positions[i+1]) + shiftKey
// Perform swap and encryption:
// - Swap positions[i] and positions[i+1]
// - Encrypt the byte at each position with the local key
data[positions[i]], data[positions[i+1]] = evalOperator(op,
data[positions[i+1]], localKey), evalOperator(op, data[positions[i]],
localKey)
}
...
Figure 3: Swap transformation implementation
The transformation begins by generating an even number of random swap positions, which is determined based on the data length plus a random number of additional positions (limited to half the data length). The compiler then randomly generates a list of random swap positions with this length.
The core obfuscation process operates by iterating through pairs of positions in reverse order, performing both a swap operation and encryption on each pair. For each iteration, it generates a position-dependent local encryption key by combining the iteration index, the XOR result of the current position pair, and a random shift key. This local key is then used to encrypt the swapped bytes with a randomly selected reversible operator.
Figure 4 shows the decompiled code produced by IDA of a decrypting subroutine of the swap transformation.
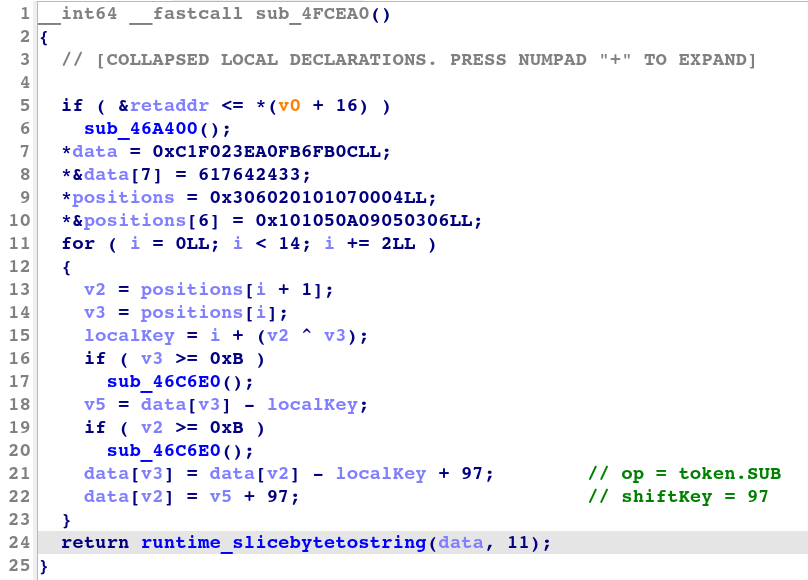
Figure 4: Decompiled code of a swap transformation decrypting subroutine
Shuffle Transformation
The shuffle transformation is the most complicated of the three stack transformation types. Here, garble applies its obfuscation by encrypting the original string with random keys, interleaving the encrypted data with its keys, and scattering the encrypted data and keys throughout the final output. Figure 5 shows the implementation from the garble repository.
// Generate a random key with the same length as the original string
key := make([]byte, len(data))
obfRand.Read(key)
// Constants for the index key size bounds
const (
minIdxKeySize = 2
maxIdxKeySize = 16
)
// Initialize index key size to minimum value
idxKeySize := minIdxKeySize
// Potentially increase index key size based on input data length
if tmp := obfRand.Intn(len(data)); tmp > idxKeySize {
idxKeySize = tmp
}
// Cap index key size at maximum value
if idxKeySize > maxIdxKeySize {
idxKeySize = maxIdxKeySize
}
// Generate a secondary key (index key) for index scrambling
idxKey := make([]byte, idxKeySize)
obfRand.Read(idxKey)
// Create a buffer that will hold both the encrypted data and the key
fullData := make([]byte, len(data)+len(key))
// Generate random operators for each position in the full data buffer
operators := make([]token.Token, len(fullData))
for i := range operators {
operators[i] = randOperator(obfRand)
}
// Encrypt data and store it with its corresponding key
// First half contains encrypted data, second half contains the key
for i, b := range key {
fullData[i], fullData[i+len(data)] = evalOperator(operators[i],
data[i], b), b
}
// Generate a random permutation of indices
shuffledIdxs := obfRand.Perm(len(fullData))
// Apply the permutation to scatter encrypted data and keys
shuffledFullData := make([]byte, len(fullData))
for i, b := range fullData {
shuffledFullData[shuffledIdxs[i]] = b
}
// Prepare AST expressions for decryption
args := []ast.Expr{ast.NewIdent("data")}
for i := range data {
// Select a random byte from the index key
keyIdx := obfRand.Intn(idxKeySize)
k := int(idxKey[keyIdx])
// Build AST expression for decryption:
// 1. Uses XOR with index key to find the real positions of data
and key
// 2. Applies reverse operator to decrypt the data using the
corresponding key
args = append(args, operatorToReversedBinaryExpr(
operators[i],
// Access encrypted data using XOR-ed index
ah.IndexExpr("fullData", &ast.BinaryExpr{X: ah.IntLit(shuffledIdxs[i]
^ k), Op: token.XOR, Y: ah.CallExprByName("int", ah.IndexExpr("idxKey",
ah.IntLit(keyIdx)))}),
// Access corresponding key using XOR-ed index
ah.IndexExpr("fullData", &ast.BinaryExpr{X:
ah.IntLit(shuffledIdxs[len(data)+i] ^ k), Op: token.XOR, Y:
ah.CallExprByName("int", ah.IndexExpr("idxKey", ah.IntLit(keyIdx)))}),
))
}Figure 5: Shuffle transformation implementation
Garble begins by generating two types of keys: a primary key of equal length to the input string for data encryption and a smaller index key (between two and 16 bytes) for index scrambling. The transformation process then occurs in the following four steps:
-
Initial encryption: Each byte of the input data is encrypted using a randomly generated reversible operator with its corresponding key byte.
-
Data interleaving: The encrypted data and key bytes are combined into a single buffer, with encrypted data in the first half and corresponding keys in the second half.
-
Index permutation: The key-data buffer undergoes a random permutation, scattering both the encrypted data and keys throughout the buffer.
-
Index encryption: Access to the permuted data is further obfuscated by XOR-ing the permuted indices with randomly selected bytes from the index key.
Figure 6 shows the decompiled code produced by IDA of a decrypting subroutine of the shuffle transformation.
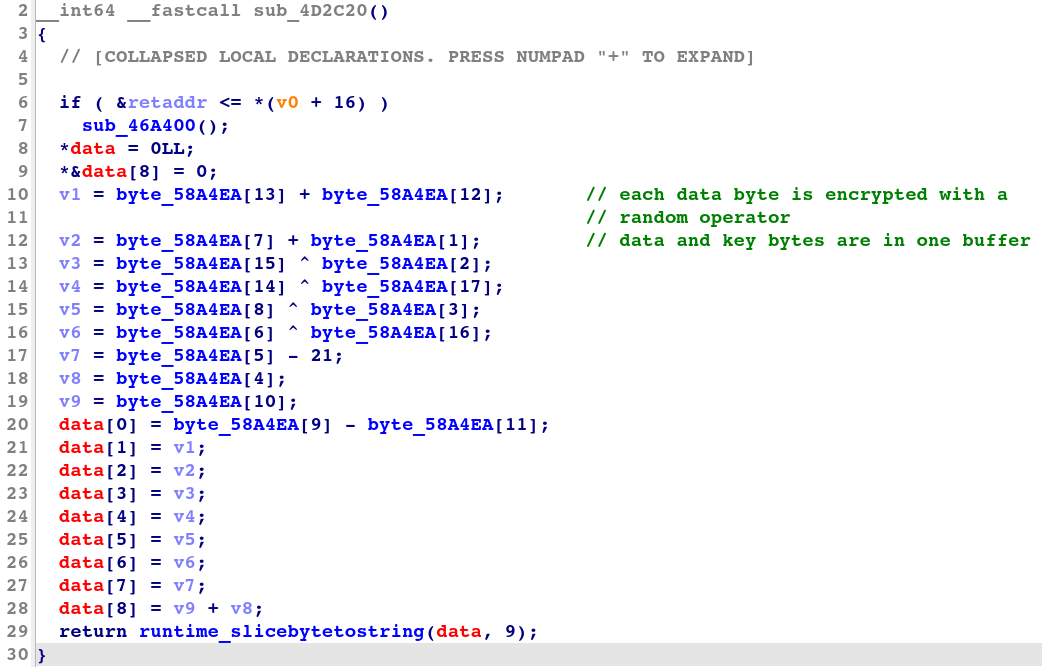
Figure 6: Decompiled code of a shuffle transformation decrypting subroutine
Seed Transformation
The seed transformation implements a chained encoding scheme where each byte’s encryption depends on the previous encryptions through a continuously updated seed value. Figure 7 shows the implementation from the garble repository.
// Generate random initial seed value
seed := byte(obfRand.Uint32())
// Store original seed for later use in decryption
originalSeed := seed
// Select a random reversible operator for encryption
op := randOperator(obfRand)
var callExpr *ast.CallExpr
// Encrypt each byte while building chain of function calls
for i, b := range data {
// Encrypt current byte using current seed value
encB := evalOperator(op, b, seed)
// Update seed by adding encrypted byte
seed += encB
if i == 0 {
// Start function call chain with first encrypted byte
callExpr = ah.CallExpr(ast.NewIdent("fnc"), ah.IntLit(int(encB)))
} else {
// Add subsequent encrypted bytes to function call chain
callExpr = ah.CallExpr(callExpr, ah.IntLit(int(encB)))
}
}
...Figure 7: Seed transformation implementation
Garble begins by randomly generating a seed value to be used for encryption. As the compiler iterates through the input string, each byte is encrypted by applying the random operator with the current seed, and the seed is updated by adding the encrypted byte. In this seed transformation, each byte’s encryption depends on the result of the previous one, creating a chain of dependencies through the continuously updated seed.
In the decryption setup, as shown in the IDA decompiled code in Figure 8, the obfuscator generates a chain of calls to a decrypting function. For each encrypted byte starting with the first one, the decrypting function applies the operator to decrypt it with the current seed and updates the seed by adding the encrypted byte to it. Because of this setup, subroutines of this transformation type are easily recognizable in the decompiler and disassembly views due to the multiple function calls it makes in the decryption process.
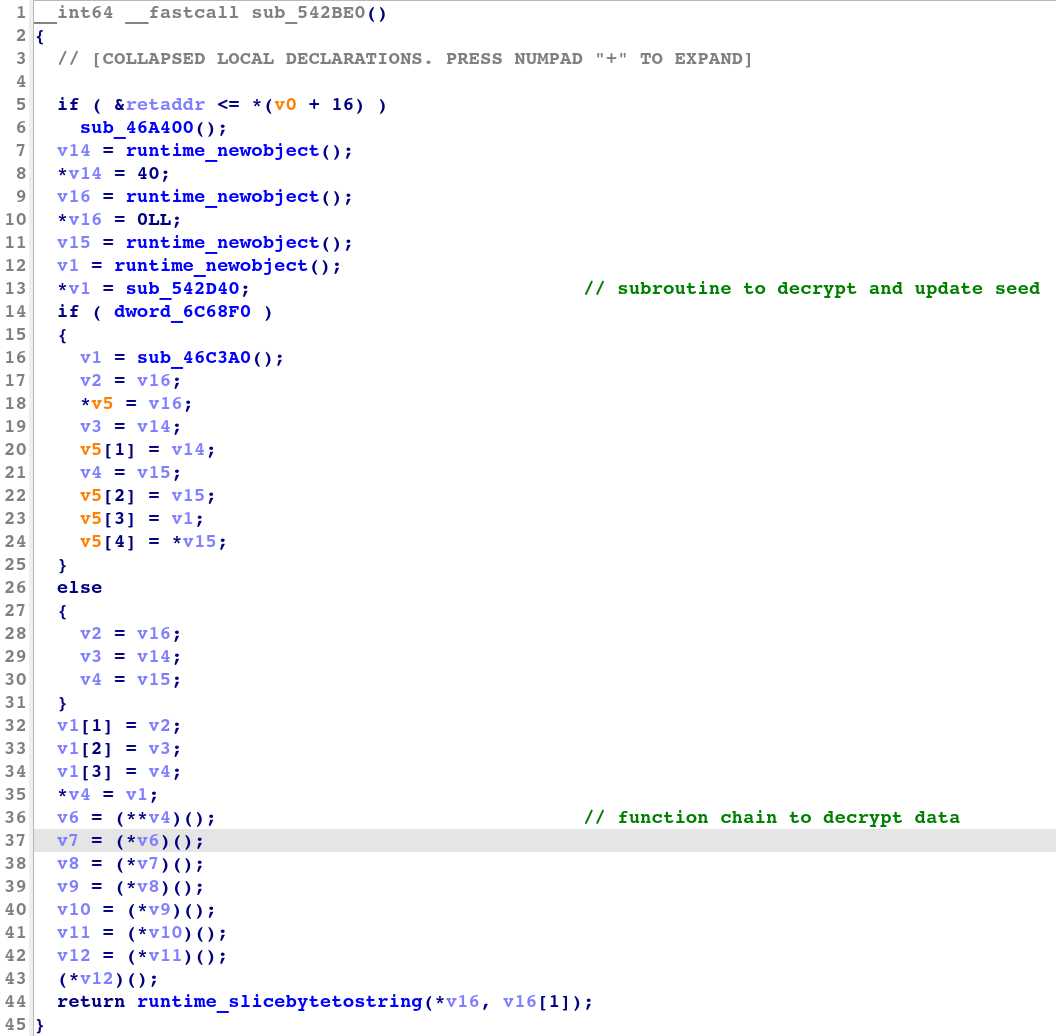
Figure 8: Decompiled code of a seed transformation decrypting subroutine

Figure 9: Disassembled code of a seed transformation decrypting subroutine
Split Transformation
The split transformation is one of the more sophisticated string transformation techniques by garble, implementing a multilayered approach that combines data fragmentation, encryption, and control flow manipulation. Figure 10 shows the implementation from the garble repository.
func (split) obfuscate(obfRand *mathrand.Rand, data []byte)
*ast.BlockStmt {
var chunks [][]byte
// For small input, split into single bytes
// This ensures even small payloads get sufficient obfuscation
if len(data)/maxChunkSize < minCaseCount {
chunks = splitIntoOneByteChunks(data)
} else {
chunks = splitIntoRandomChunks(obfRand, data)
}
// Generate random indexes for all chunks plus two special cases:
// - One for the final decryption operation
// - One for the exit condition
indexes := obfRand.Perm(len(chunks) + 2)
// Initialize the decryption key with a random value
decryptKeyInitial := byte(obfRand.Uint32())
decryptKey := decryptKeyInitial
// Calculate the final decryption key by XORing it with
position-dependent values
for i, index := range indexes[:len(indexes)-1] {
decryptKey ^= byte(index * i)
}
// Select a random reversible operator for encryption
op := randOperator(obfRand)
// Encrypt all data chunks using the selected operator and key
encryptChunks(chunks, op, decryptKey)
// Get special indexes for decrypt and exit states
decryptIndex := indexes[len(indexes)-2]
exitIndex := indexes[len(indexes)-1]
// Create the decrypt case that reassembles the data
switchCases := []ast.Stmt{&ast.CaseClause{
List: []ast.Expr{ah.IntLit(decryptIndex)},
Body: shuffleStmts(obfRand,
// Exit case: Set next state to exit
&ast.AssignStmt{
Lhs: []ast.Expr{ast.NewIdent("i")},
Tok: token.ASSIGN,
Rhs: []ast.Expr{ah.IntLit(exitIndex)},
},
// Iterate through the assembled data and decrypt each byte
&ast.RangeStmt{
Key: ast.NewIdent("y"),
Tok: token.DEFINE,
X: ast.NewIdent("data"),
Body: ah.BlockStmt(&ast.AssignStmt{
Lhs: []ast.Expr{ah.IndexExpr("data", ast.NewIdent("y"))},
Tok: token.ASSIGN,
Rhs: []ast.Expr{
// Apply the reverse of the encryption operation
operatorToReversedBinaryExpr(
op,
ah.IndexExpr("data", ast.NewIdent("y")),
// XOR with position-dependent key
ah.CallExpr(ast.NewIdent("byte"), &ast.BinaryExpr{
X: ast.NewIdent("decryptKey"),
Op: token.XOR,
Y: ast.NewIdent("y"),
}),
),
},
}),
},
),
}}
// Create switch cases for each chunk of data
for i := range chunks {
index := indexes[i]
nextIndex := indexes[i+1]
chunk := chunks[i]
appendCallExpr := &ast.CallExpr{
Fun: ast.NewIdent("append"),
Args: []ast.Expr{ast.NewIdent("data")},
}
...
// Create switch case for this chunk
switchCases = append(switchCases, &ast.CaseClause{
List: []ast.Expr{ah.IntLit(index)},
Body: shuffleStmts(obfRand,
// Set next state
&ast.AssignStmt{
Lhs: []ast.Expr{ast.NewIdent("i")},
Tok: token.ASSIGN,
Rhs: []ast.Expr{ah.IntLit(nextIndex)},
},
// Append this chunk to the collected data
&ast.AssignStmt{
Lhs: []ast.Expr{ast.NewIdent("data")},
Tok: token.ASSIGN,
Rhs: []ast.Expr{appendCallExpr},
},
),
})
}
// Final block creates the state machine loop structure
return ah.BlockStmt(
...
// Update decrypt key based on current state and counter
Body: ah.BlockStmt(
&ast.AssignStmt{
Lhs: []ast.Expr{ast.NewIdent("decryptKey")},
Tok: token.XOR_ASSIGN,
Rhs: []ast.Expr{
&ast.BinaryExpr{
X: ast.NewIdent("i"),
Op: token.MUL,
Y: ast.NewIdent("counter"),
},
},
},
// Main switch statement as the core of the state machine
&ast.SwitchStmt{
Tag: ast.NewIdent("i"),
Body: ah.BlockStmt(shuffleStmts(obfRand, switchCases...)...),
}),Figure 10: Split transformation implementation
The transformation begins by splitting the input string into chunks of varying sizes. Shorter strings are broken into individual bytes, while longer strings are divided into random-sized chunks of up to four bytes.
The transformation then constructs a decrypting mechanism using a switch-based control flow pattern. Rather than processing chunks sequentially, the compiler generates a randomized execution order through a series of switch cases. Each case handles a specific chunk of data, encrypting it with a position-dependent key derived from both the chunk's position and a global encryption key.
In the decryption setup, as shown in the IDA decompiled code in Figure 11, the obfuscator first collects the encrypted data by going through each chunk in their corresponding order. In the final switch case, the compiler performs a final pass to XOR-decrypt the encrypted buffer. This pass uses a continuously updated key that depends on both the byte position and the execution path taken through the switch statement to decrypt each byte.
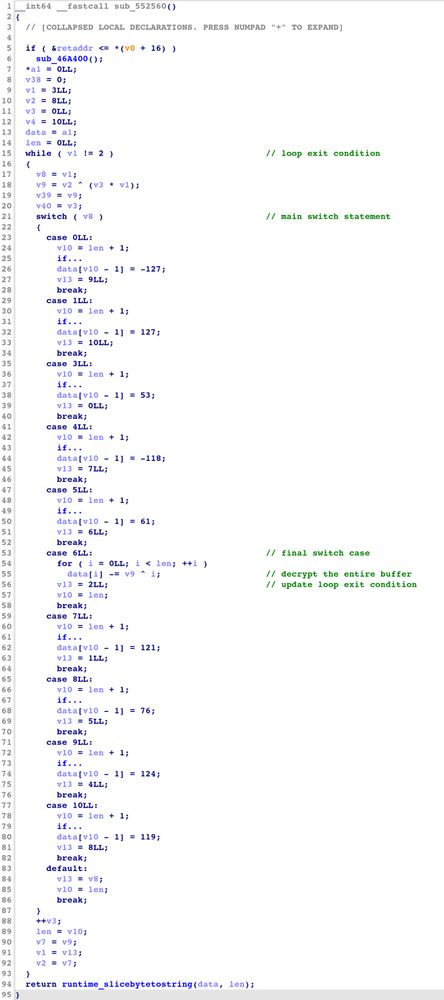
Figure 11: Decompiled code of a split transformation decrypting subroutine
GoStringUngarbler: Automatic String Deobfuscator
To systematically approach string decryption automation, we first consider how this can be done manually. From our experience, the most efficient manual approach leverages dynamic analysis through a debugger. Upon finding a decrypting subroutine, we can manipulate the program counter to target the subroutine's entry point, execute until the ret instruction, and extract the decrypted string from the return buffer.
To perform this process automatically, the primary challenge lies in identifying all decrypting subroutines introduced by garble's transformations. Our analysis revealed a consistent pattern—decrypted strings are always processed through Go's runtime_slicebytetostring function before being returned by the decrypting subroutine. This observation provides a reliable anchor point, allowing us to construct regular expression (regex) patterns to automatically detect these subroutines.
String Encryption Subroutine Patterns
Through analyzing the disassembled code, we have identified consistent instruction patterns for each string transformation variant. For each transformation on 64-bit binaries, rbx is used to store the decrypted string pointer, and rcx is assigned with the length of the decrypted string. The main difference between the transformations is the way these two registers are populated before the call to runtime_slicebytetostring.
# Go compiler v1.21 -> v1.23 (x64)
# Stack Transformation Epilogue Pattern
48 8D 5C ?? ?? lea rbx, [rsp+<num>] # decrypted string pointer
B9 ?? ?? ?? ?? mov ecx, <num> # decrypted string length
E8 ?? ?? ?? ?? call runtime_slicebytetostring
48 83 ?? ?? add rsp, <num> # epilogue clean up
5D pop rbp
C3 retn
---------------------------------------
# Split Transformation Epilogue Pattern
31 C0 xor eax, eax
48 89 ?? mov rbx, <reg> # decrypted string pointer
48 89 ?? mov rcx, <reg> # decrypted string length
E8 ?? ?? ?? ?? call runtime_slicebytetostring
48 83 ?? ?? add rsp, <num>
5D pop rbp
C3 retn
---------------------------------------
# Seed Transformation Epilogue Pattern
48 8B ?? mov rbx, [<reg>] # decrypted string pointer
48 8B ?? ?? mov rcx, [<reg>+8] # decrypted string length
31 C0 xor eax, eax
E8 ?? ?? ?? ?? call runtime_slicebytetostring
48 83 ?? ?? add rsp, <num>
5D pop rbp
C3 retnFigure 12: Epilogue patterns of garble’s decrypting subroutines
Through the assembly patterns in Figure 12, we develop regex patterns corresponding to each of garble's transformation types, which allows us to automatically identify string decrypting subroutines with high precision.
To extract the decrypted string, we must find the subroutine’s prologue and perform instruction-level emulation from this entry point until runtime_slicebytestring is called. For binaries of Go versions v1.21 to v1.23, we observe two main patterns of instructions in the subroutine prologue that perform the Go stack check.
# Go prologue pattern 1
49 3B ?? ?? cmp rsp, [<reg>+<num>]
0F 86 ?? ?? ?? ?? jbe <offset>
------------------------
# Go prologue pattern 2
49 3B ?? ?? cmp rsp, [<reg>+<num>]
76 ?? jbe short <offset>Figure 13: Prologue instruction patterns of Go subroutines
These instruction patterns in the Go prologue serve as reliable entry point markers for emulation. The implementation in GoStringUngarbler leverages these structural patterns to establish reliable execution contexts for the unicorn emulation engine, ensuring accurate string recovery across various garble string transformations.
Figure 14 shows the output of our automated extraction framework, where GoStringUngarbler is able to identify and emulate all decrypting subroutines.

Figure 14: GoStringUngarbler’s string extraction output
From these instruction patterns, we have derived a YARA rule for detecting samples that are obfuscated with garble’s literal transformation. The rule can be found in Mandiant's GitHub repository.
Deobfuscation: Subroutine Patching
While extracting obfuscated strings can aid malware detection through signature-based analysis, this alone is not useful for reverse engineers conducting static analysis. To aid reverse engineering efforts, we've implemented a binary deobfuscation approach leveraging the emulation results.
Although developing an IDA plugin would have streamlined our development process, we recognize that not all malware analysts have access to, or prefer to use, IDA Pro. To make our tool more accessible, we developed GoStringUngarbler as a standalone Python utility to process binaries protected by garble. The tool can deobfuscate and produce functionally identical executables with recovered strings stored in plain text, improving both reverse engineering analysis and malware detection workflows.
For each identified decrypting subroutine, we implement a strategic patching methodology, replacing the original code with an optimized stub while padding the remaining subroutine space with INT3 instructions (Figure 15).
xor eax, eax ; clear return register
lea rbx, <string addr> ; Load effective address of decrypted string
mov ecx, <string len> ; populate string length
call runtime_slicebytetostring ; convert slice to Go string
ret ; return the decrypted stringFigure 15: Function stub to patch over garble’s decrypting subroutines
Initially, we considered storing recovered strings within an existing binary section for efficient referencing from the patched subroutines. However, after examining obfuscated binaries, we found that there is not enough space within existing sections to consistently accommodate the deobfuscated strings. On the other hand, adding a new section, while feasible, would introduce unnecessary complexity to our tool.
Instead, we opt for a more elegant space utilization strategy by leveraging the inherent characteristics of garble's string transformations. In our tool, we implement in-place string storage by writing the decrypted string directly after the patched stub, capitalizing on the guaranteed available space from decrypting routines:
-
Stack transformation: The decrypting subroutine stores and processes encrypted strings on the stack, providing adequate space through their data manipulation instructions. The instructions originally used for pushing encrypted data onto the stack create a natural storage space for the decrypted string.
-
Seed transformation: For each character, the decrypting subroutine requires a call instruction to decrypt it and update the seed. This is more than enough space to store the decrypted bytes.
-
Split transformation: The decrypting subroutine contains multiple switch cases to handle fragmented data recovery and decryption. These extensive instruction sequences guarantee sufficient space for the decrypted string data.
Figure 16 and Figure 17 show the disassembled and decompiled output of our patching framework, where GoStringUngarbler has deobfuscated a decrypting subroutine to display the recovered original string.
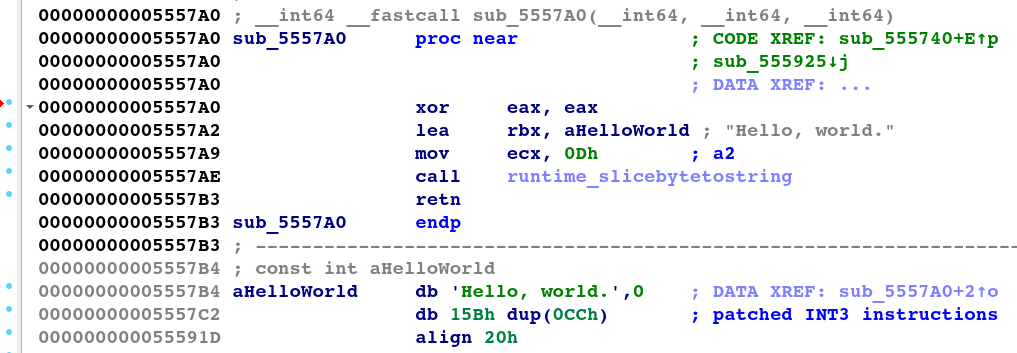
Figure 16: Disassembly view of a deobfuscated decrypting subroutine

Figure 17: Decompiled view of a deobfuscated decrypting subroutine
Downloading GoStringUngarbler
GoStringUngarbler is now available as an open-source tool in Mandiant's GitHub repository.
The installation requires Python3 and Python dependencies from the requirements.txt file.
Future Work
Deobfuscating binaries generated by garble presents a specific challenge—its dependence on the Go compiler for obfuscation means that the calling convention can evolve between Go versions. This change can potentially invalidate the regular expression patterns used in our deobfuscation process. To mitigate this, we've designed GoStringUngarbler with a modular plugin architecture. This allows for new plugins to be easily added with updated regular expressions to handle variations introduced by new Go releases. This design ensures the tool's long-term adaptability to future changes in garble’s output.
Currently, GoStringUngarbler primarily supports garble-obfuscated PE and ELF binaries compiled with Go versions 1.21 through 1.23. We are continuously working to expand this range as the Go compiler and garble are updated.
Acknowledgments
Special thanks to Nino Isakovic and Matt Williams for their review and continuous feedback throughout the development of GoStringUngarbler. Their insights and suggestions have been invaluable in shaping and refining the tool’s final implementation.
We are also grateful to the FLARE team members for their review of this blog post publication to ensure its technical accuracy and clarity.
Additional thanks to OALabs for their valuable insights from their initial research on garble’s string encryption.
Finally, we want to acknowledge the developers of garble for their outstanding work on this obfuscating compiler. Their contributions to the software protection field have greatly advanced both offensive and defensive security research on Go binary analysis.
