Advancing systems research: Synthesized Google storage I/O traces now available to the community
Phitchaya Mangpo Phothilimthana
Staff Research Scientist, Google DeepMind
Saurabh Kadekodi
Senior Research Scientist, Google
Designing large-scale distributed storage systems is a complex challenge, requiring deep insights into how storage hardware and software interact under real-world conditions. To empower researchers in this field, we recently released a collection of synthesized Google I/O traces for storage servers and disks. This release accompanies our paper, "Thesios: Synthesizing Accurate Counterfactual I/O Traces from I/O Samples," published at ASPLOS 2024.
What are I/O traces and why do they matter?
I/O traces are records of the input/output operations happening on storage devices and servers, and are crucial for understanding real-world storage behavior and performance. Representative I/O traces that capture the diverse patterns and demands of exascale data centers (such as Google’s) are especially valuable. By studying these traces, researchers can:
-
Gain deeper insights into storage system performance and bottlenecks
-
Build more accurate models and simulate realistic workloads
-
Develop targeted optimizations for more efficient and reliable storage systems
But obtaining high-quality I/O traces is challenging due to storage-system heterogeneity and the need to capture details while minimizing overhead. To address these issues, we developed a novel methodology called Thesios.
Introducing Thesios: a methodology for I/O trace synthesis
We developed the Thesios methodology to create accurate and representative I/O traces. Thesios achieves this by combining down-sampled I/O traces (which are routinely collected in Google's data centers) from multiple disks across multiple storage servers.
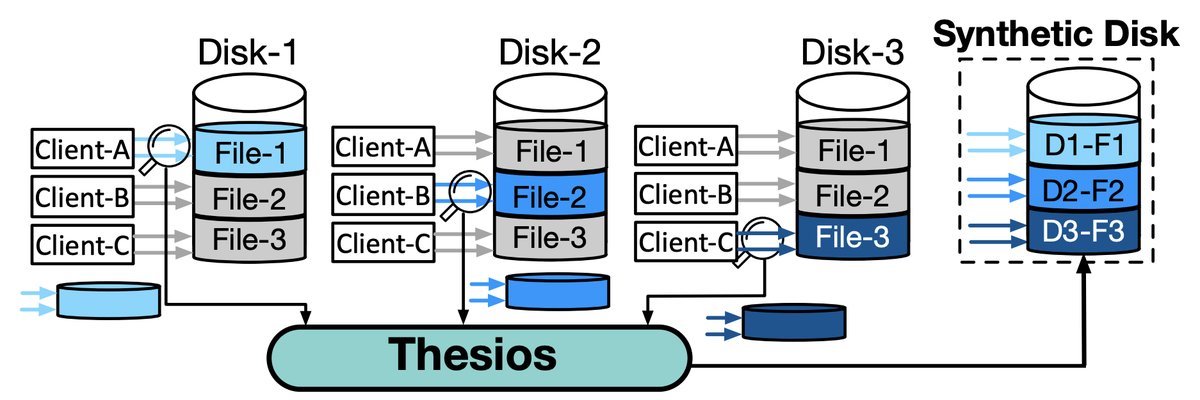
Thesios synthesizes a full-resolution I/O trace for a single disk by combining I/O samples from multiple independent disks.

Thesios requires (1) a sampling service that collects I/O samples, (2) an entity identifier that identifies similar disks, (3) a trace synthesizer that generates server-level traces by combining samples, and (4) a trace reorganizer that adjusts request ordering and latency to produce a disk-level trace.
The challenge? Storage systems are internally heterogeneous, so naively combining samples collected from disks varying in model, size, utilization, and other aspects will not result in a representative trace. Thesios intelligently accounts for this diversity, helping to ensure that the synthesized traces accurately reflect real-world conditions. Our results show remarkable accuracy relative to actual aggregated statistics that we’ve collected:
-
95-99.5% accuracy in read/write request numbers
-
90-97% accuracy in utilization
-
80-99.8% accuracy in read latency
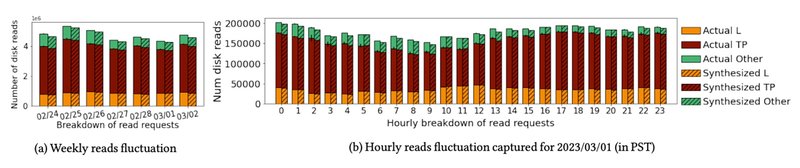
Total number of read operations and breakdown by latency-sensitive (L), throughput-oriented (TP) and other (O) requests of synthesized traces vs. the actual statistics. The traces synthesized by Thesios faithfully capture the fluctuation across days of the week, and hours of the day.
A unique capability of Thesios is the ability to synthesize counterfactual I/O traces for conducting data-driven “what-if'' studies. In our paper, we demonstrate how Thesios enables diverse counterfactual I/O-trace synthesis and analyses of hypothetical policy, hardware, and server changes via four example case studies:
-
Synthesizing I/O traces for disks with hypothetical capacities, utilization, and fullness
-
Experimenting with data segregation to form hot and cold disks by using different workload filtering criteria and analyzing the data segregation’s impacts on power consumption
-
Evaluating the impact on energy consumption and latency of deploying a low rotations-per-minute (RPM) disk
-
Estimating the impact on cache hits of increasing buffer cache size on a server
Why open-source these traces?
We have released two-month-long synthesized representative traces from three different Google storage clusters, containing approximately 2.5 billion I/O records. These traces include I/O operations from both user-facing and internal applications. Our goal is to fuel storage-systems research by sharing realistic workloads that we encountered in our large-scale data centers. We hope these traces will:
-
Inspire new optimizations and innovations in storage technology
-
Enable more accurate simulations and modeling of large-scale storage systems
-
Serve as a model for how industry can securely share production traces with academia, fostering collaboration and progress
We invite systems researchers to explore our Google I/O traces. We believe these traces offer a unique opportunity to delve into the complex world of large-scale storage and drive meaningful advancements. Download the traces and start your research today!
For a deeper dive into our methodology and the technical details, we encourage you to read our ASPLOS paper: Thesios: Synthesizing Accurate Counterfactual I/O Traces from I/O Samples.
The research in this post describes joint work with our colleagues Soroush Ghodrati, Selene Moon, and Martin Maas. We also extend special thanks to Larry Greenfield, Mustafa Uysal, Arif Merchant, Seth Pollen, and Partha Ranganathan for their help and feedback on the trace release.

