UM-Bridge: leveraging Kubernetes for scalable Uncertainty Quantification in the cloud
Dr. Anne Reinarz
Assistant Professor, Durham University
Dr. Linus Seelinger
Postdoctoral Researcher, Heidelberg University
Simulation and uncertainty
Numerical simulation is an established tool driving innovation in many fields of science and engineering, helping to predict real-world processes using mathematical models. For example, engineers can obtain mechanical simulation results through CAD software, and inference plays a vital role in medical imaging. In these scenarios, it is common to encounter uncertainty in data, and a purely deterministic approach to modeling may not capture the full complexity of the system being studied.
Uncertainty can arise due to various factors, including measurement errors, incomplete information, and the inherent stochastic nature of certain processes. When simulating physical processes, uncertain data clearly imply uncertain predictions and inferences. Incorporating uncertainty into the analysis allows researchers understand the limitations of their models, and quantify the risks associated with different outcomes. Understanding the likelihood of certain scenarios is important, for example, in the assessment of nuclear waste disposal, in tsunami early-warning systems, or considering random material defects when designing aircraft wings.
Complex problems, complex software
As such, Uncertainty Quantification (UQ) presents numerous challenges, both in terms of mathematics and technical aspects. Even very simple UQ problems can require enormous computational effort. We therefore need efficient UQ algorithms that produce good results from relatively few simulation runs, state-of-the-art numerical solvers, and high-performance computing (HPC) resources, all combined in one application.
Further, due to fundamentally different requirements, the UQ and numerical simulation communities tend to use very different tools, resulting in incompatible programming languages, build systems, parallelization schemes, etc. And when large simulation software is extended to incorporate uncertainty, it’s usually done monolithically, resulting in extremely complex software. For example, general climate models can easily exceed 500,000 lines of code. This means that advanced UQ methods can only be coupled with advanced models by very large, interdisciplinary teams.
So how can we make the overall complexity manageable and thus make UQ methods more accessible?
UM-Bridge: Breaking down complexity in UQ
We developed UM-Bridge1 (the UQ and Modeling Bridge) as a unified interface for numerical models that is accessible from any programming language or framework, introducing a service-based abstraction of mathematical models. In UM-Bridge, UQ and model code are two independent applications, passing model evaluation requests through an HTTP-based protocol. This architecture is possible, since many UQ algorithms treat the model as a mathematical function mapping a parameter vector to model outcome vector, possibly with derivatives. (The same holds for many optimization and ML algorithms operating on mathematical models as well!)
There are native UM-Bridge integrations for a number of languages and frameworks, making calling a model as easy as a regular function call in the respective language. Due to the service-based architecture and unified interface, any UM-Bridge client may connect to any UM-Bridge supporting model, regardless of the respective programming language or framework.
Linking the UQ ecosystem and cloud
UQ algorithms themselves tend to be rather inexpensive computationally; it’s typically the many numerical model evaluations that increase costs. We can therefore run a parallelized UQ algorithm on a single machine, offloading heavy model computations to a cloud cluster via UM-Bridge. A cluster-side load balancer receives these parallel model evaluation requests and distributes them between a (potentially large) number of independent model instances.
Many UQ packages already support single-node parallelism, but not multi-node. Those that do are typically limited to a specific technology like MPI or Ray, in turn limiting compatibility with arbitrary model codes. The new architecture, seen below, is particularly attractive since any of these UQ codes can now transparently offload model computations to clusters.
We chose Google Kubernetes Engine on Google Cloud as a scientific computing platform to implement our UM-bridge framework as it provides the features we need to match our requirements: a containerized environment to orchestrate our workloads, and advanced load balancing features for task distribution.
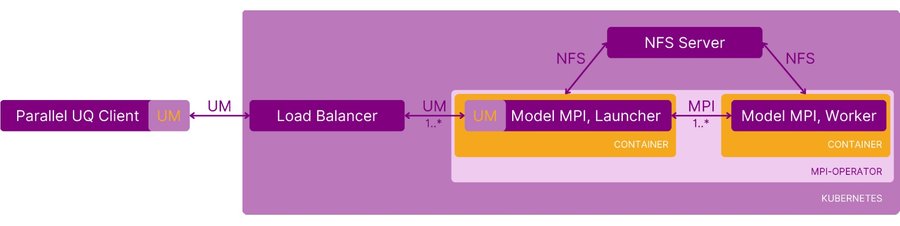
For a load balancer, we employ HAProxy configured to ensure that only one request is passed to one model instance at a time. Each model instance may itself be parallelized across multiple nodes (and therefore containers) via MPI, which we support as a special case, making use of kubeflow's mpi-operator. Finally, some GKE-specific optimizations run on compact placement clusters, which reduces latency between nodes, and we disable simultaneous multithreading (SMT) for consistent performance.
We publish our setup as a reproducible configuration that can be applied to any Kubernetes cluster that supports arbitrary UM-Bridge model containers. UM-Bridge therefore bridges the gap between UQ packages and cloud clusters, not only removing integration issues between UQ and the model, but also eliminating the need for dedicated HPC UQ codes.
Applications
We have successfully run this Kubernetes setup to solve a number of UQ problems, three of which have been published2. The client-side ranges from a sparse grids code that’s been trivially parallelized through Matlab's 'parfor' loop, to a Python UQ code parallelized via Ray. Likewise, we build our models using several different tools, including Fortran and code-generated C++. Thanks to UM-Bridge and Kubernetes, it was easy to combine the tools.
Our largest application of this approach was Bayesian inference of the source location of the 2011 Tohoku tsunami, based on available buoy data. We used a hierarchical UQ method, which we accelerated through fast approximate models. Nevertheless, we had to run over 3000 simulations with different source locations, comparing results to measured data. We offloaded heavy simulation runs to a 5600 vCPUs GKE cluster using 100 c2d-highcpu-56 VMs. In this application, we ran 100 simulations in parallel with each simulation using one node’s 56 vCPUs fully.
Compared to a more traditional, previous approach involving an MPI parallel UQ code and the running the model on a bare-metal HPC cluster3, we reduced development time to just a few days instead of months. UM-Bridge, containerization and Kubernetes solved the technical issues we previously faced, so we could focus entirely on the UQ problem itself.
Conclusion
UM-Bridge enables UQ even in complex applications by introducing a microservice-inspired architecture, and we were able to successfully demonstrate its scalability on a large GKE Standard cluster. Full support for containers and our general-purpose Kubernetes setup made Kubernetes an attractive option for performing large-scale UQ.
You can find docs, tutorials and our Kubernetes setup at https://um-bridge-benchmarks.readthedocs.io. This includes the tsunami model above as part of the UM-Bridge benchmark library.
We are actively building a community around UM-Bridge and UQ applications, so feel free to contact us. Let's make UQ as ubiquitous as deterministic numerical simulation is today!
1. UM-Bridge
2. Scaling up on GKE
3. Large-scale UQ on conventional HPC cluster