Introducing HPC VM images—pre-tuned for optimal performance
Pavan Kumar
Product Manager
Jason Zhang
Software Engineering Manager
Today, we’re excited to announce the Public Preview of a CentOS 7-based Virtual Machine (VM) image optimized for high performance computing (HPC) workloads, with a focus on tightly-coupled MPI workloads.
In 2020, we introduced several features and best-practice tunings to help achieve optimal MPI performance on Google Cloud. With these best practices, we demonstrated that MPI ping-pong latency falls into single-digits of microseconds (us) and small MPI messages are delivered in 10us or less.
Improved MPI performance translates directly to improved application scaling, expanding the set of HPC workloads that run efficiently on Google Cloud. However, building a VM image that includes these best practices requires systems expertise and knowledge of Google Cloud. Starting with an HPC-optimized image can make it easier to maintain an image.
The HPC VM image makes it easy and quick to instantiate VMs that are tuned to achieve optimal CPU and network performance on Google Cloud. The HPC VM image is available at no additional cost via the Google Cloud Marketplace.
Continue reading below for details about the HPC VM image and its benefits, or skip ahead to our documentation and quickstart guide to start creating instances using the HPC VM image today!
Benefits of using the HPC VM image
The HPC VM image is pre-configured and regularly maintained, providing the following advantages to HPC customers on Google Cloud:
Easily create HPC-ready VMs out-of the-box that incorporate our best practices for tightly-coupled HPC applications. You can quickly create HPC-ready VMs and always stay up-to-date with the latest tunings.
Networking optimizations for tightly-coupled workloads help reduce latency for small messages, and benefit applications that are heavily dependent on point-to-point and collective communications.
Compute optimizations for HPC workloads allow more predictable single-node high performance by reducing system jitter that can lead to performance variation.
Consistent and reproducible multi-node performance by using a set of tunings which have been tested across a range of HPC workloads.
Using the HPC VM image is simple and easy, as it is a drop-in replacement for the standard CentOS 7 image.
Customer story: Scaling SDPB solver using CloudyCluster and HPC VM image
Walter Landry is a research software engineer in the Caltech Particle Theory Group working with the international Bootstrap Collaboration. The collaboration uses SDPB, a semidefinite program solver, to study Quantum Field Theories, with application to a wide variety of problems in theoretical physics, such as early universe inflation, superconductors, quantum Hall fluids, and phase transitions.To expand the collaboration’s computation capabilities, Landry wanted to see how SDPB would scale on Google Cloud. Working with Omnibond CloudyCluster and leveraging the HPC VM image, Landry achieved comparable performance and scaling to an on-premises cluster at Yale, based on Intel Xeon Gold 6240 processors and Infiniband FDR.
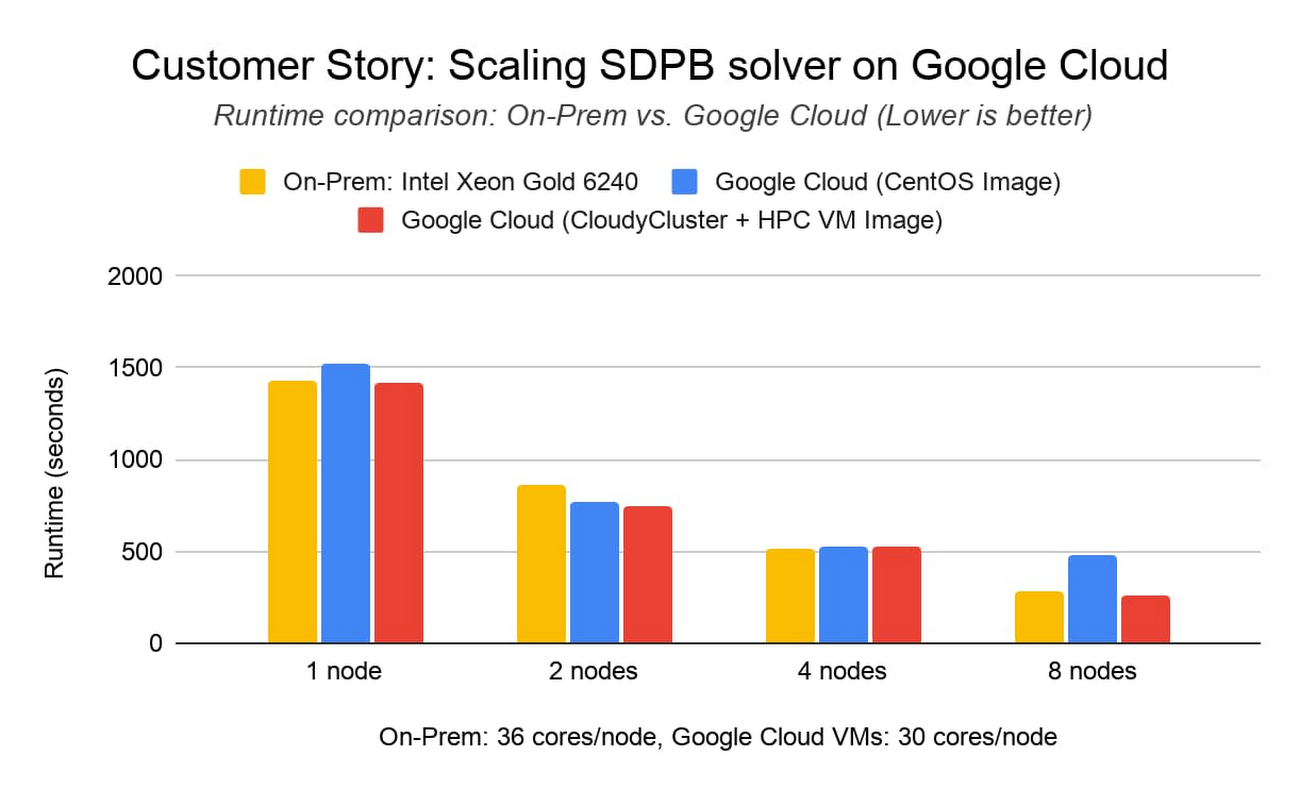
Google Cloud’s C2-Standard-60 instance type is based on the second-generation Intel Xeon Scalable Processor. The C2 family of instances can utilize placement policies to reduce inter-node latency, ideal for tightly-coupled MPI workloads. CloudyCluster leverages the HPC VM image and placement policy for the C2 family out of the box, making it seamless for the researcher. These tests show the ability to scale low latency workloads across many instances in Google Cloud.
If you would like to try out the HPC VM image with Omnibond CloudyCluster, an updated version of Omnibond CloudyCluster using the HPC VM image is available in the Google Cloud Marketplace. This version also comes complete with NSF funded Open OnDemand led by Ohio Supercomputer Center, making it easy for system administrators to provide web access to HPC resources.
What’s included in the HPC VM image?
Tunings and Optimizations
The current release of the HPC VM image focuses on tunings for tightly coupled HPC workloads and implements the following best-practices for optimal MPI application performance:
Disable Hyper-Threading: Intel Hyper-Threading is disabled by default in the HPC VM image. Turning off Hyper-Threading allows more predictable performance and can decrease execution time for some HPC jobs.
MPI collective tunings: The choice of MPI collective algorithms can have a significant impact on MPI application performance. HPC VM image includes recommended Intel MPI collective algorithms to use in the most common MPI job configurations.
Increase tcp_*mem settings: C2 machines can support up to 32 Gbps bandwidth, and they benefit from larger TCP memory than Linux defaults.
Enable busy polling: Busy polling can help reduce latency in the network receive path by allowing socket-layer code to poll the receive queue of a network device and by disabling network interrupts.
Raise user limits: Default limits on system resources—like open files and numbers of processes that any one user can use—are typically unnecessary for HPC jobs where compute nodes in a cluster aren’t shared between users.
Disable Linux firewalls, Disable SELinux: For Google Cloud CentOS Linux images, SELinux and firewall is turned on by default. HPC VM image disables Linux firewalls and SELinux to improve MPI performance.
Disable CPUIdle: C2 machines support CPU C-states to enter low-power mode and save energy. Disabling CPUIdle can help reduce jitter and provide consistent low latency.
The benefits of these tunings can vary from application to application and we recommend that you benchmark your applications to find the most efficient or cost-effective configuration.
Performance measurement using HPC benchmarks
We have compared the performance of the HPC VM image vs. the default CentOS 7 image across both the Intel MPI Benchmarks and real application benchmarks for Finite Element Analysis (ANSYS LS-DYNA), Computational Fluid Dynamics (ANSYS Fluent) and Weather Modeling (WRF).
The following versions of the HPC VM image and CentOS Image were used for the benchmarks in this section:
HPC VM image: hpc-centos-7-v20210119 (with --nomitigation applied and mpitune configs installed as suggested in the HPC VM image documentation)
CentOS Image: centos-7-v20200811
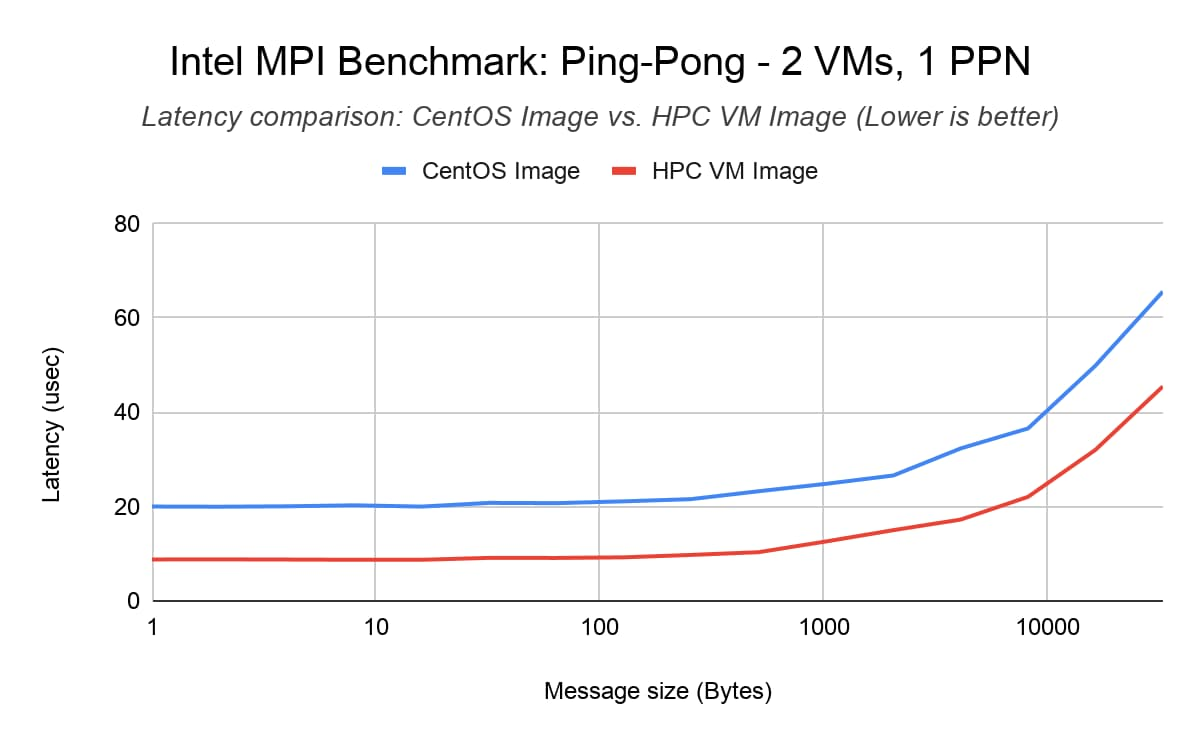
Intel MPI Benchmark (IMB) Ping-Pong
IMB Ping-Pong measures the ping-pong latency of transferring a fix-sized message between two ranks over a pair of VMs. On average, we saw that the HPC VM image reduces inter-node ping-pong latency by up to 50% compared to the default CentOS 7 Image (baseline).
Benchmark setup
2x C2-standard-60 VMs with compact placement policy
MPI Library: Intel MPI Library 2018 update 4
Command line: mpirun -genv I_MPI_PIN=1 -genv I_MPI_PIN_PROCESSOR_LIST=0 -hostfile <hostfile> -np 2 -ppn 1 IMB-MPI1 Pingpong -iter 50000
Results
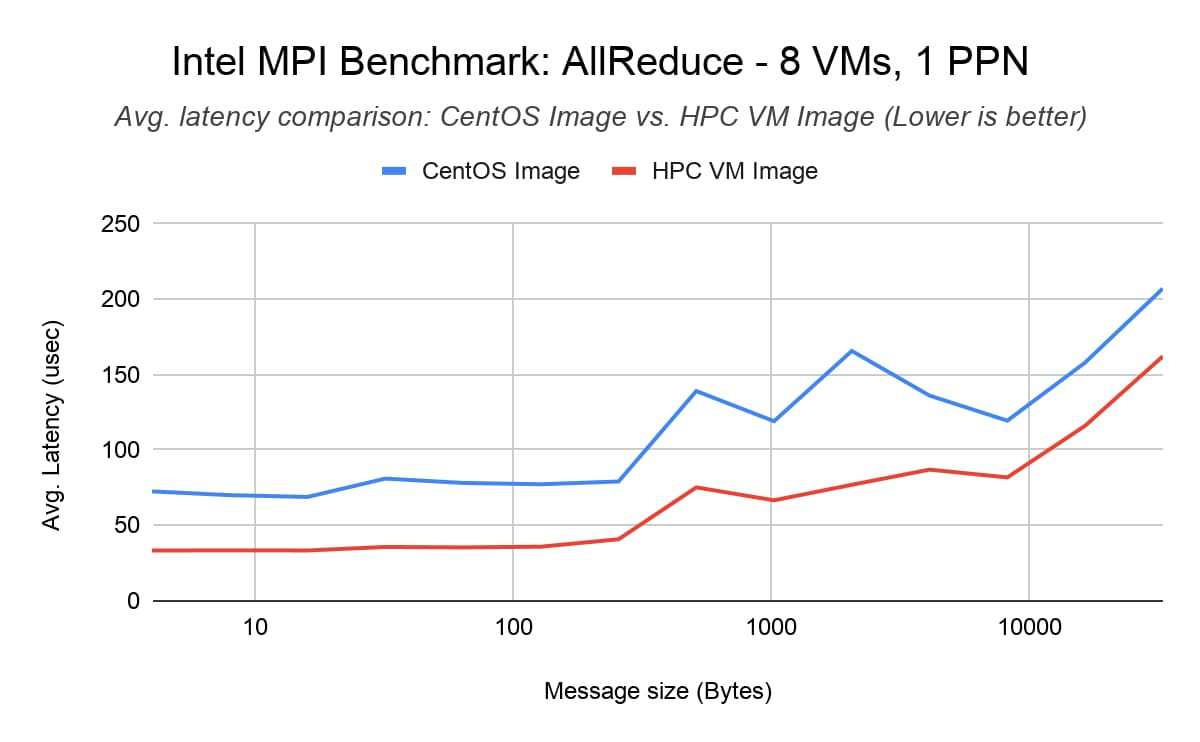
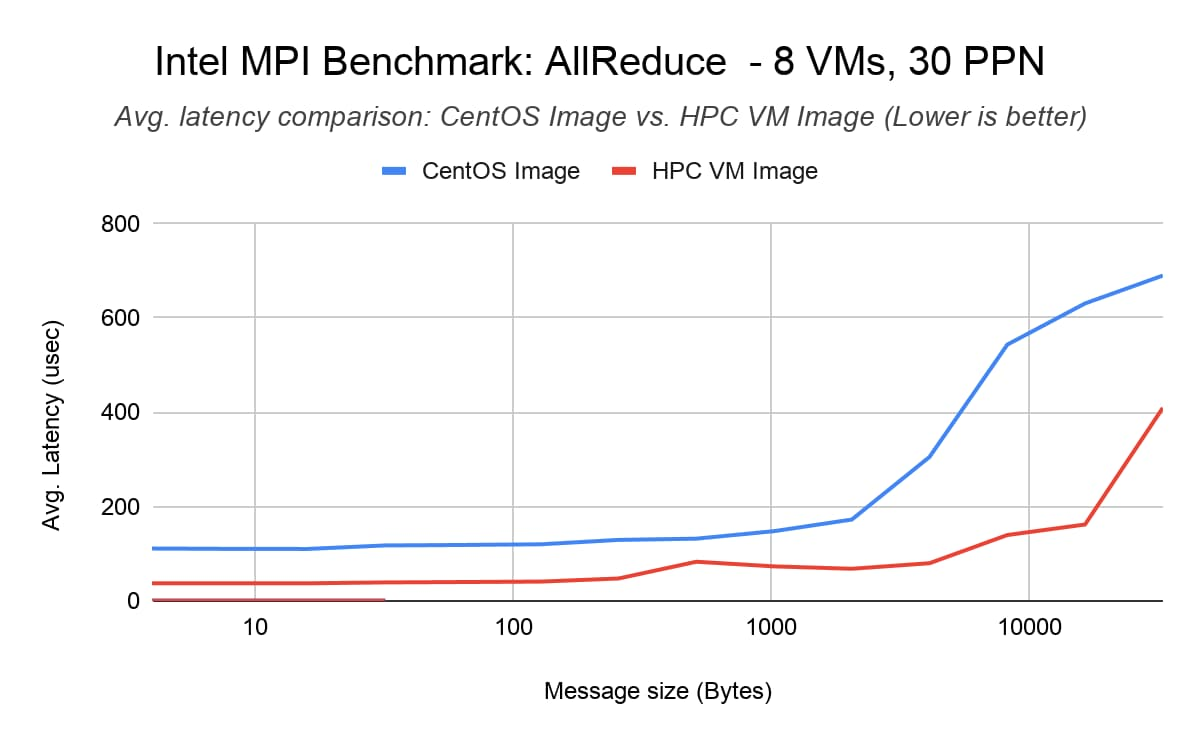
Intel MPI Benchmark (IMB) AllReduce
The IMB AllReduce benchmark measures the collective latency among multiple ranks across VMs. It reduces a vector of a fixed length with the MPI_SUM operation. We show 1 PPN (process-per-node) results to represent the case when we have a 1 MPI rank/node and 30 threads/rank and 30 PPN results where there are 30 MPI ranks/node and 1 thread/rank. We saw that the HPC VM image reduces AllReduce latency by up to 40% for 240 MPI ranks across 8 nodes (30 processes per node) compared to the default CentOS 7 image (baseline).
Benchmark setup
8x C2-standard-60 VMs with compact placement policy
MPI Library: Intel MPI Library 2018 update 4
Command line: mpirun -tune -genv I_MPI_PIN=1 -genv I_MPI_FABRICS ‘shm:tcp’ -hostfile <hostfile> -np <#vm*ppn> -ppn <ppn> IMB-MPI1 AllReduce -iter 50000 -npmin <#vm*ppn>
Results
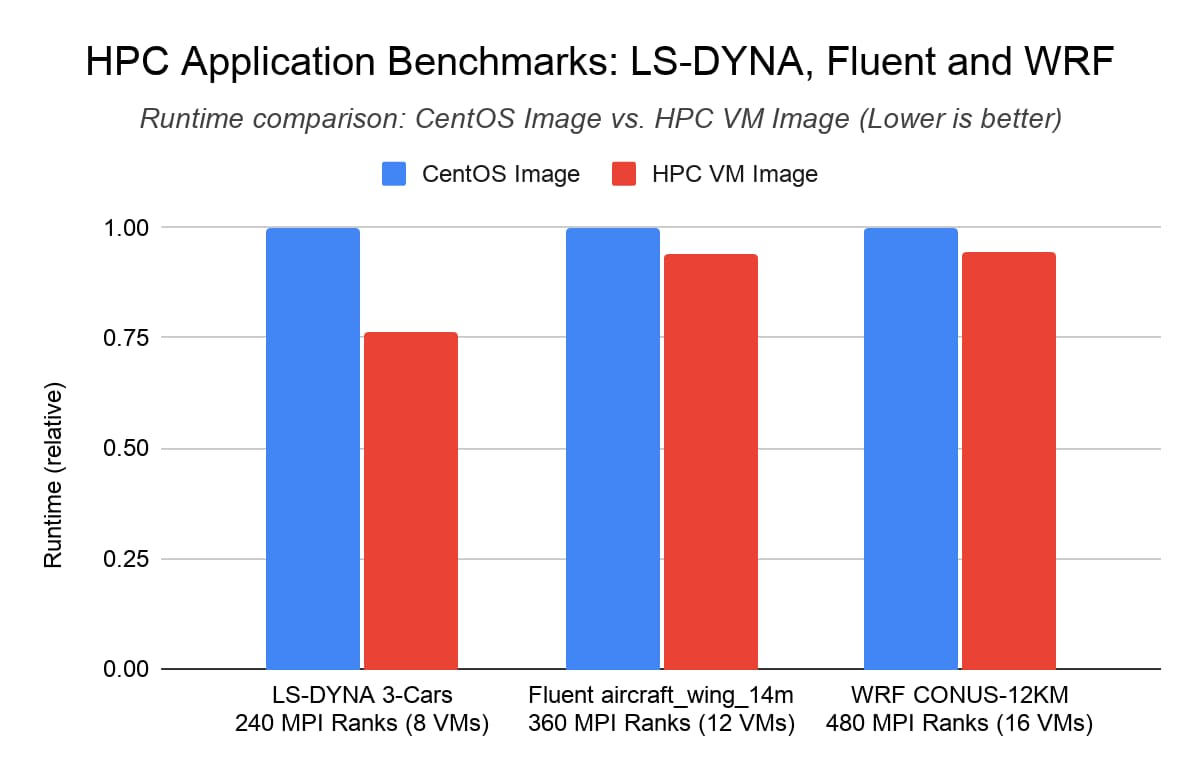
HPC application benchmarks: LS-DYNA, Fluent and WRF
At an application level, the HPC VM image yielded up to a 25% performance improvement to the ANSYS LS-DYNA “3 cars” vehicle collision simulation benchmark when running on 240 MPI ranks across 8 Intel Xeon processor based C2 instances. With ANSYS Fluent and WRF, we observed up to 6% performance improvement using the HPC VM image in comparison with the default CentOS Image.
Benchmark setup
ANSYS LS-DYNA (“3-cars” model): 8 C2-standard-60 VMs with compact placement policy, using the LS-DYNA MPP binary compiled with AVX-2
ANSYS Fluent (“aircraft_wing_14m” model): 12 C2-standard-60 VMs with compact placement policy
WRF V3 Parallel Benchmark (12 KM CONUS): 16 C2-standard-60 VMs with compact placement policy
MPI Library: Intel MPI Library 2018 update 4
Results
What’s next? SchedMD Slurm support and additional Linux distributions
We are continuing to work with our HPC partners to integrate the HPC VM image with partner offerings by default. Starting next month, HPC customers who use Slurm will be able to start HPC-ready clusters that make use of the HPC VM image by default (preview version is available here).
For customers who are looking for HPC Enterprise Linux options and support, SUSE is working with Google on a SUSE Enterprise HPC VM image that has been optimized for Google Cloud. If you’re interested in learning more about SUSE Enterprise HPC VM image, or have a requirement for additional integrations or Linux distributions, please contact us.
Get started today!
The HPC VM image is available in Preview for all customers through the Google Cloud Marketplace today. Check out our documentation and quickstart guide for more details on creating instances using the HPC VM image.
Special thanks to Jiuxing Liu, Tanner Love, Jian Yang, Hongbo Lu and Pallavi Phene for their contributions.
