Prescriptions for healthcare data management systems on GCP
Mike Pope
Technical Editor, GCP Platform-wide docs
Like many other industries, healthcare has seen rapid adoption of cloud-based resources in order to do things like store, process, and analyze vast amounts of data. However, given the healthcare industry’s complexity, many healthcare organizations have found it particularly challenging to create cloud-based solutions.
Beyond the technical challenges of implementing highly scalable and highly available systems, a critical consideration for any healthcare solution is also how to work with protected health information (PHI). Regulations around the world (for example, HIPAA in the United States) dictate how patient information must be handled and stored. In addition, while it's important for healthcare organizations to be able to share data across the industry, they use a large variety of data formats and schemas. This can make it complex to combine data types.
To tackle this challenge, Google has built a number of healthcare-specific products that use common healthcare data formats, such as FHIR, HL7v2, and DICOM. In addition, to make it easier to understand and design healthcare data-management systems on Google Cloud Platform (GCP), we've published a number of solutions documents that address the issues that are important to the industry. These documents give you background in some of the issues that you might face when implementing healthcare solutions, along with prescriptive guidance on how to move your healthcare systems and data to GCP.
Building out a healthcare solution
Building out a GCP-based system for your healthcare data involves a lot of components and moving parts. Understanding all the pieces and assembling them yourself takes time and study. It's especially important that your system has the controls that are required in order to help align with data-privacy concerns.
To get you started, the GCP Cloud Healthcare team has created the Google Cloud Healthcare Data Protection Toolkit—a set of scripts and procedures that walk you through the process and that do a lot of the work. The toolkit is available as an open source project under an Apache Licence, Version 2 on the GCP GitHub repository.
To put the toolkit into context and show how it fits into a full healthcare system, we've published a pair of accompanying solutions. The first is Architecture: HIPAA-aligned Cloud Healthcare by Adrish Sannyasi, a Google Cloud solutions consultant. This document provides background on the unique concerns for creating healthcare solutions and shows you the architecture that the toolkit and accompanying solutions help you build:
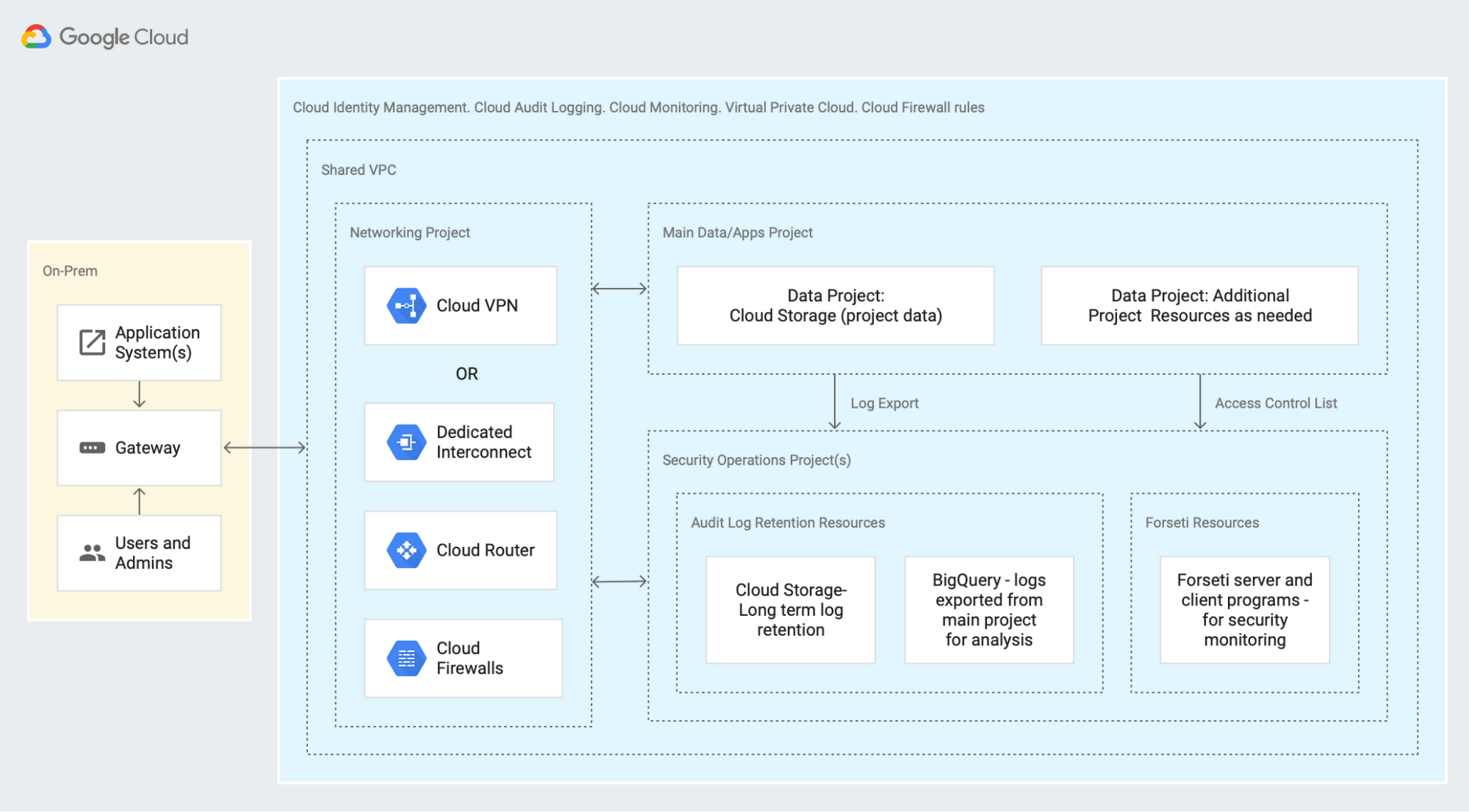
As the document notes, this is not a final, production-ready system; it's a reference architecture that's designed to illustrate the components you need and how they fit together. The expectation is that you'd use this as a base for creating an architecture that incorporates your own requirements and usage.
The document also delves into different facets of a full healthcare solution. It describes security and permissions, connectivity with your on-premises system, and logging and monitoring—all from the perspective of what's necessary for a system that aligns with healthcare concerns.
From there, you can turn to the related solution Setting up a HIPAA-aligned project. This document provides detailed instructions for using the toolkit to build out an instance of the reference architecture. The tutorial walks you through every step, from creating a new project all the way through checking BigQuery logs to check for suspicious activity. When you're done, you'll not only have exercised the toolkit, but you'll have a system that you can extend to meet your own needs.
Ingesting medical records
In the last few years, the Fast Healthcare Interoperability Resources (FHIR) standard has emerged as a way to store and share medical records. FHIR defines both a way to represent data (JSON, XML, RDF) and a protocol for sharing records (REST, HTML).
We recently published a solution that explains in detail how you can use the Cloud Healthcare API to work with FHIR in GCP. In Importing FHIR clinical data into the cloud using the Cloud Healthcare API, we lay out the benefits of a Cloud Healthcare API FHIR store. For example, the store can become a source for other GCP-based apps or for analysis in BigQuery and for machine learning. The API can also help with de-identifying data if you want to use it for apps that require anonymous data.The solution then gets into the details of how to load (ingest) data into GCP, covering the following scenarios:
Near real-time ingestion, which loads one record at a time.
Bundled ingestion, in which you pass a set of records to be ingested. These can either be a simple batch of individual records, or a set of records that you ingest using transactions in order to have an all-or-nothing import of related records.
Batch ingestion, in which the import process reads a series of prepared files from Cloud Storage.
The solution explores additional options, such as automating the ingestion process, using Cloud Functions to pre- or post-process records, using Cloud Pub/Sub to create subscriptions that watch events on buckets or other data stores, and using Cloud Dataflow to work with streaming data.
The solution explicitly notes where you should be careful with security and permissions. For example, it lays out the Cloud IAM roles that the Cloud Healthcare API uses for creating and managing the data, and what permissions those roles need.
De-identifying medical data
Finally, healthcare information isn't used only for patient care. For example, medical images that help medical professionals diagnose patients are also valuable to researchers as data. But clearly, privacy concerns mean that researchers should not share or publish their research in a way that shows patient information. Therefore, any personally identifying information (PII) and protected health information (PHI) should be removed from the data before publication.
In GCP, researchers can perform this process, known as de-identification, by using the Cloud Healthcare API. The following image shows an x-ray after it's been de-identified: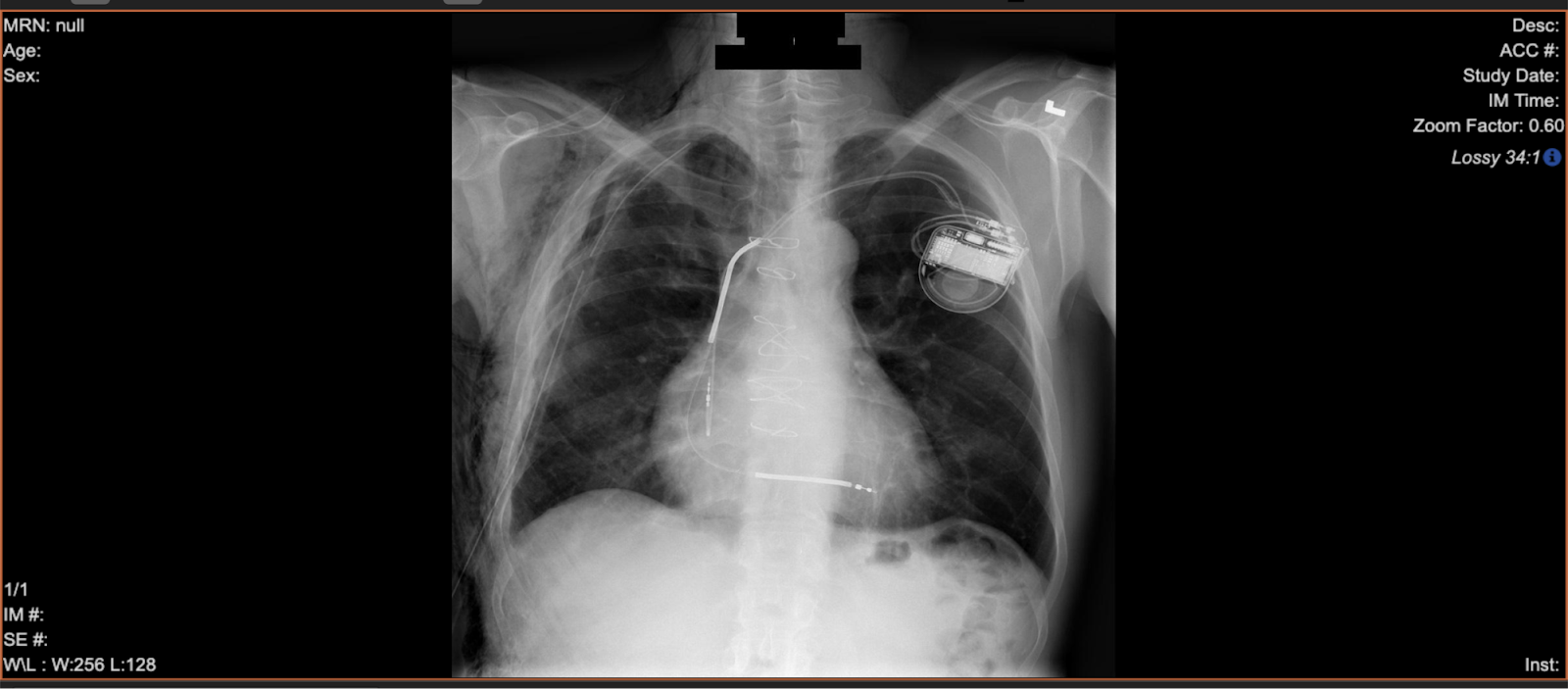
We have two solutions that describe the de-identification process. De-identification of medical images through the Cloud Healthcare API is an overview that covers how the process works, including what GCP services you can use to ingest images, and how to store them before and after you de-identify them. The solution also discusses how to use DICOM tag keywords to specify what data to de-identify.
A second solution, Using the Cloud Healthcare API to de-identify medical images, is a step-by-step tutorial that shows you how to de-identify data using the Cloud Healthcare API on your own DICOM dataset. The tutorial discusses two use cases. In the first, you leave only the minimum amount of data in the images. The second use case involves removing and modifying metadata and redacting any text in the images. This de-identification process maintains medically or scientifically relevant information.
The tutorial not only shows you how to invoke the API to perform these tasks, but also explains details like how to set appropriate permissions to allow the API access to the data.
Check out our Google Cloud healthcare solutions page to learn more.



