Creating custom financial indices with Dataflow and Apache Beam
Matt Tait
Technical Solutions Consultant, Google Cloud
James Tromans
Head of Web3 Engineering at Google Cloud
Financial institutions across the globe rely on real-time indices to inform real-time portfolio valuations, to provide benchmarks for other investments, and as a basis for passive investment instruments including exchange-traded products (ETPs). This reliance is growing—the index industry dramatically expanded in 2020, reaching revenues of $4.08 billion.
Today, indices are calculated and distributed by index providers with proximity and access to underlying asset data, and with differentiating real-time data processing capabilities. These providers offer subscriptions to real-time feeds of index prices and publish the constituents, calculation methodology, and update frequency for each index.
But as new assets, markets, and data sources have proliferated, financial institutions have developed new requirements. Financial institutions will need to quickly create bespoke and frequently updating indices that represent a specific actual or theoretical portfolio, with its unique constituents and weightings.
In other words, existing index providers and other financial institutions alike will need mechanisms for rapid creation of real-time indices. This blog post’s focus—an index publication pipeline collaboratively developed by CME Group and Google Cloud—is an example of such a mechanism.
The pipeline closely approximates a particular CME Group index benchmark, but with far greater frequency (in near real time vs. daily) than its official counterpart. It does so by leveraging open-source models such as Apache Beam and cloud-based technologies such as Dataflow, which automatically scales pipelines based on inbound data volume.

Machine learning’s production problem
In the past decade, advances in AI toolchains have enabled faster ML model training -- and yet a majority of ML models are still not making it into production. As organizations endeavor to develop their ML capabilities, they soon realize that a real-world ML system consists of a small amount of ML code embedded in a network of complex and large ancillary components. Each component brings its own development and operational challenges, which are met by bringing a DevOps methodology to the ML system, commonly referred to as MLOps (Machine Learning Operations). To apply ML to business problems, a firm must develop continuous delivery and automation pipelines for ML.
This index publication collaboration is instructive because it demonstrates MLOps best practices for just such a pipeline. One Apache Beam pipeline, suited for operating on both batch and streaming data, extracts insights and packages them for downstream consumers. These consumers may include ML pipelines that, thanks to Apache Beam, require only one code path for inference across batch and real-time data sources. The pipeline is run inside Google Cloud’s Dataflow execution engine, greatly simplifying management of underlying compute resources.
But the collaboration’s value is not constrained to the ML and data science realm. The project shows that consumers of the Apache Beam pipeline’s insights may also include traditional business intelligence dashboards and reporting tools. It also demonstrates the simplicity and economy of cloud-based time series data such as CME Smart Stream, which is metered by the hour, quickly and automatically provisioned, and consumable at a per-product-code (not per-feed) level.
A focus on real-time processing for financial services
To illustrate the above points, the collaboration applies data engineering and MLOps best practices to a financial services problem. We chose the financial services domain because many financial institutions do not yet have real-time market data processing or MLOps capabilities today, owing to a significant gap on either side of their ML/AI objectives.
Upstream from ML/AI models, financial institutions often experience a data engineering gap. For many financial institutions, batch processes have sufficiently addressed business requirements. As a result, the temporal nature of the time series data underlying these processes is deemphasized. For example, the original purpose of most trade booking systems was to capture a trade and ensure that it found its way to the middle and back office for settlement. It was not built with ML/AI in mind, and its underlying data therefore has not been packaged for consumption by ML/AI processes.
And downstream from ML/AI models, financial institutions often encounter the aforementioned “ML production problem.”
As ML/AI becomes ever more strategic, these two gaps have left many financial institutions in a conundrum—unable to train ML models for lack of properly packaged time series data, and unmotivated to package time series data for lack of ML models. By recreating a key energy market index using open-source libraries and cloud-based tools, this collaboration demonstrates that for the financial services domain a solution to this conundrum is more accessible today than ever.
Creating a new index
We modeled our new index after one of CME Group’s many index benchmarks. The particular index expresses the value of a basket of three New York Mercantile Exchange—listed energy futures as a single price. Today, CME Group publishes the index at the end of the day by calculating the settlement price of each underlying futures contract, and then weighing and summing these values.
While CME Group does not currently publish this index in real time, this collaboration aims to create a near real-time solution leveraging Google Cloud capabilities and CME Group market data delivered via CME Smart Stream. However, in order to publish the value so frequently—every five seconds, with 40-second publish latency—this collaboration’s pipeline has to solve a number of challenges in near-real time.
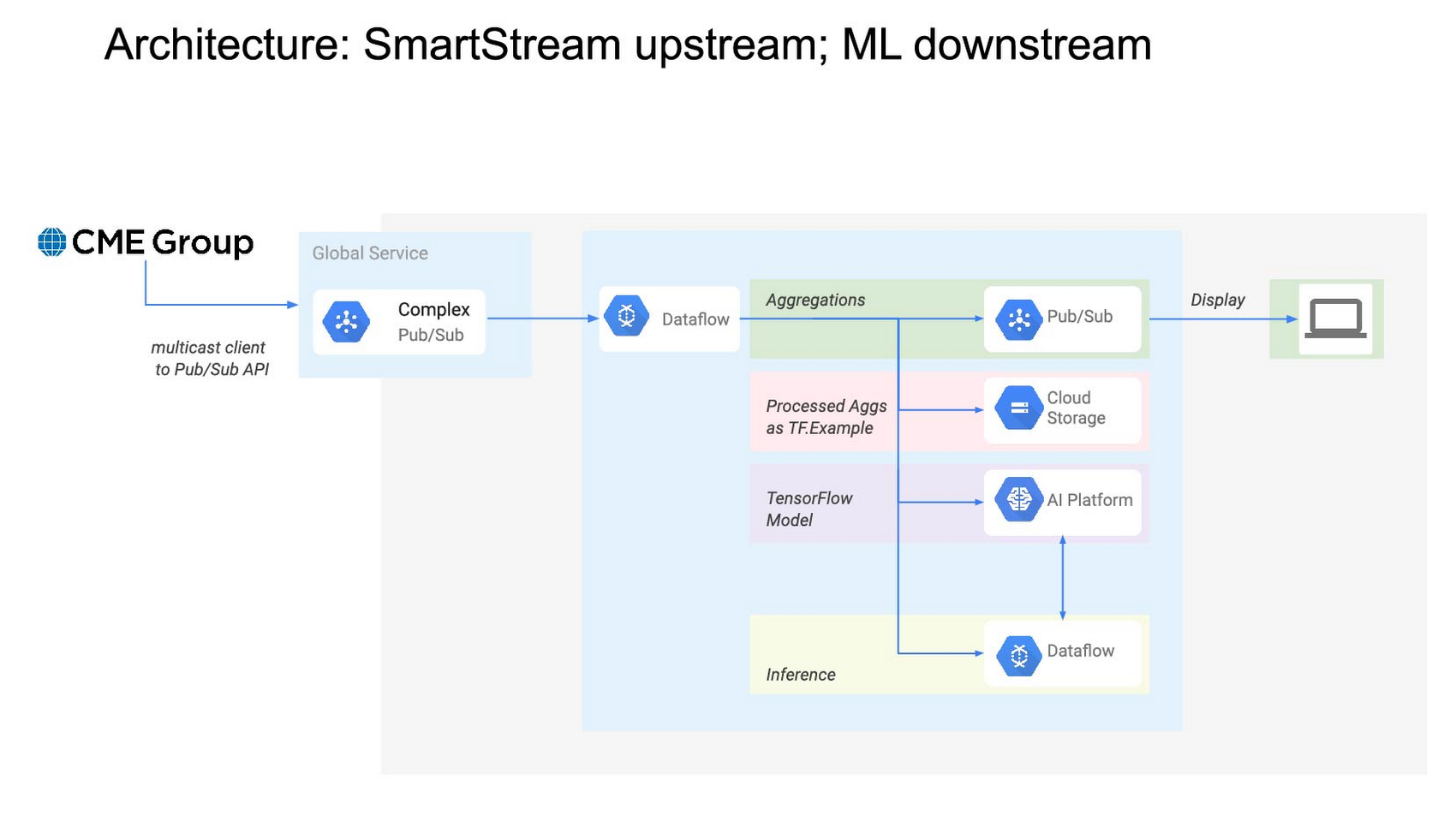
First, the pipeline must process sparse data from three separate trades feeds in memory to create open-high-low-close (OHLC) bars. More specifically, for five-second windows for each of the three front-month (and sometimes second-month) energy contracts, a bar must be produced. This is solved by using the Apache Beam library to implement functions which, when executed on Dataflow, automatically scale out as input load increases. The bars must be time-aligned across the underlying feeds, which is greatly simplified by Beam’s watermark feature. And for intervals in which no tick data is observed, the Beam library is used to pull forward the last value received, yielding perfect gap-free bars for downstream processors.
Second, the pipeline must calculate volume-weighted average price (VWAP) in near real-time for each front-month contract. The VWAP calculations are also written using the Beam API and executed on Dataflow. Each of these functions requires visibility of each element in the time window, so the functions cannot be arbitrarily scaled out. Nonetheless, this is tractable because their input—OHLC bars—is manageably small.
Third, the pipeline must replicate CME Group’s specific settlement price methodology for each contract. The rules specify whether to use VWAP or another source as price, depending on certain conditions. They also specify how to weigh combinations of monthly contracts during a roll period. The pipeline again encapsulates these requirements as an Apache Beam class, and joins the separate price streams at the correct time boundary.
The end result is a new stream publishing bespoke index data to a Google Cloud Pub/Sub topic thousands of times daily, enabling AI models as well as traditional industry index usage, dashboards, and other tools to assist real-time decision making. The stream’s pipeline uses open source libraries that solve common time series problems out-of-the box, and cloud-based services to reduce the user’s operational and scaling burden.
The importance of cloud-based data
The promise of cloud-based pipeline execution services cannot be realized using legacy data access patterns, which often require market data users to colocate and configure servers and network gear. Such patterns inject expense and scaling complexity into the pipeline’s overall operation, diverting resources from the adoption of MLOps best practices. Instead, a newer, cloud-based access pattern—in which resources subscribe to data streams inexpensively, rapidly and programatically—is necessary.
In 2018, CME Group identified the customer need for accessible futures and options market data. CME Group collaborated with Google Cloud to launch CME Smart Stream, which distributes CME Group’s real-time market data across Google Cloud’s global infrastructure with sub-second latency. Any customer with a CME Group data usage license and a Google Cloud project can consume this data for an hourly usage fee, without purchasing and configuring servers and network gear.
CME Smart Stream met this index pipeline’s requirements for cost-effective, cloud-based streaming data, but this is just one use case. Since the launch of a CME Smart Stream offering on Google Cloud, globally dispersed firms have adopted the solution. For example, Coin Metrics has been using the offering to better inform its customers in the crypto markets. According to CME Group, Smart Stream has become popular with new customers as the fastest, simplest way to access CME Group’s market data from anywhere in the world.
Adapt the design pattern to your needs
By combining cloud-based data, open-source libraries, and cloud-based pipeline execution services, we created a real-time index using the same constituents as its end-of-day counterpart. Additionally, financial institutions will find this approach addresses many other challenges—real-time valuation of a large set of portfolios; benchmark creation for new ETPs; or external publication of new indices.
Give it a try
This approach is available to help you meet your organization’s needs. Please review our user guide, whose Tutorials section provides a step-by-step guide to constructing a simple Apache Beam pipeline to generate metrics on streaming data in real-time, and connecting a new data source to the pipeline. We’ll be discussing this topic in CME Group’s webinar End-to-End Market Data Solutions in the Cloud at 10:30 am ET on June 16th.


