Orchestrating your data workloads in Google Cloud
Rachael Deacon-Smith
Developer Advocate, Google
At its core, Data and Analytics allows us to make impactful decisions by deriving insights from our data. In the pursuit of making data meaningful, data scientists and engineers are often tasked with building end-to-end workflows to ingest, process and analyze data.
These workflows will usually involve multiple tasks, or services that need to be executed in a particular order. How do you know if and when the execution of a task has completed successfully, what should happen if one of the services in the workflow fails? You can imagine that as your workloads scale and become more complex these questions become more urgent and harder to solve.
This is where orchestration comes in! Orchestration is the automation, management and coordination of workflows. In this blog I’ll discuss how you can orchestrate your data workflows in Google Cloud.
Let’s start with an example
Let’s imagine that you have data across multiple buckets in Google Cloud Storage that you need to extract and transform before loading into, say, BigQuery, Google Cloud’s Data Warehouse. To do this, you could build data pipelines in Dataflow, Data Fusion, or Dataproc (our managed offering of Beam, CDAP and Spark respectively).

So where does orchestration come in? Let’s say we want to:
- Run the data pipeline that will transform our data every day at midnight.
- Validate that the data exists in Cloud Storage before running the pipeline.
- Execute a BigQuery job to create a View of the newly processed data.
- Delete the Cloud Storage bucket once the pipeline is complete.
- If any of the above fails, you want to be notified via slack.
This process needs to be coordinated as part of a wider workflow; it needs to be orchestrated.
It’s key to understand that orchestration is not about transforming or processing the data directly, but supporting and coordinating the services that do.
Which tool should I use?
Google Cloud Platform has a number of tools that can help you orchestrate your workflows in the Cloud, check out our first blog in this series, Choosing the right orchestrator, for a more in depth comparison of these products. Cloud Composer is your best bet when it comes to orchestrating your data driven (particularly ETL/ELT) workloads.
Cloud Composer is our fully managed orchestration tool used to author, schedule and monitor workflows. It is built on the popular and ever-growing open source Apache Airflow project.
The end goal is to build a workflow made up of tasks, your workflow is configured by creating a Directed Acyclic Graph (DAG) in python. A DAG is a one-direction flow of tasks with no cycles and each task is responsible for a discrete unit of work: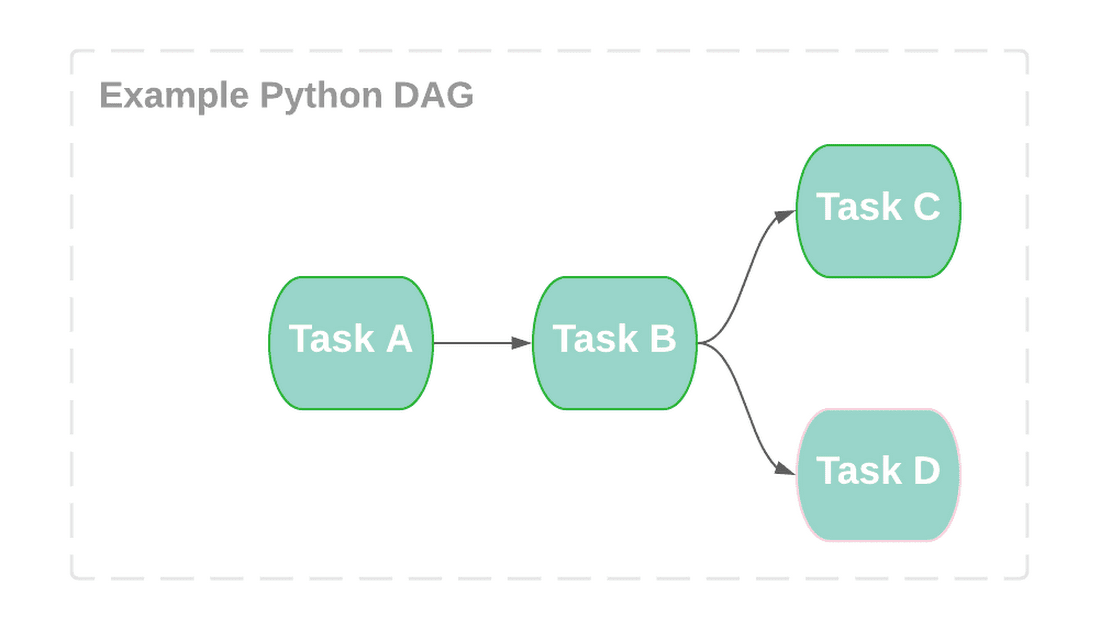
If your workflows are held together by a handful of cron jobs or ad hoc scripts with loose dependencies that only a handful of people know how to manage then you’ll appreciate the nature of DAGs. Your workflow can be simplified, centralized and collaborative by having your entire task execution in a central tool that everyone can contribute to, and track in the Airflow UI.
Why use Composer for orchestrating my data workflows?
Composer can support a whole range of different use cases but the majority of users are data engineers who are building workflows to orchestrate their data pipelines. They’ve chosen Composer because it helps overcome some of the challenges commonly faced when managing data workflows.
Being able to coordinate and interface with multiple services is paramount to any ETL or ELT workflow and engineers need to be able to do this reliably and securely. Thankfully, there are hundreds of operators and sensors that allow you to communicate with services across multiple cloud environments without having to write and maintain lots of code to call APIs directly.
As workflows scale in complexity, having sophisticated task management becomes more important. You can parallelize and branch tasks based on the state of previous tasks. It has built-in scheduling and features to handle unexpected behavior - for example, sending an email or notification on failure.
Composer takes the Airflow experience for engineers up a level by creating and maintaining the Airflow environment for you, taking care of the infrastructure needed to get your DAGs up and running. Not having to focus on infrastructure management in addition to being able to automate and delegate the repetitive tasks to Composer, means data engineers get time back to focus on actually building data pipelines and workflows.
Can I use Composer to process and transform my data?
Composer is not a data processing tool and shouldn’t be used to directly transform and process big data. It is not designed to pass large amounts of data from one task to the next and doesn’t have any sophisticated data processing parallelism or aggregation that is fundamental to handling big data. Composer is also better suited to orchestrating batch workloads over those that require super low latency as it can take a few seconds to start one task once another has finished.
But what about those data transfer operators?
It’s worth pointing out there are some transfer operators, like the Google Cloud Storage to BigQuery operator, that transfers data from one source to another.
So isn’t Composer being used here to transfer data? Not quite - under the hood Composer is just making a call to the BigQuery API to transfer the data, no data is downloaded, or transferred between the Composer workers - this is all delegated to BigQuery resources.
So how does Composer compare to Dataflow or DataFusion?
Services like Data Fusion, Dataflow and Dataproc are great for ingesting, processing and transforming your data. These services are designed to operate directly on big data and can build both batch and real time pipelines that support the performant aggregation (shuffling, grouping) and scaling of data. This is where you should build your data pipelines and you can use Composer to manage the execution of these services as part of a wider workflow.
Let’s revisit our example with Composer
You would first create DAG with tasks for each stage of your workflow. We’ll assume our data pipeline is in Dataflow:
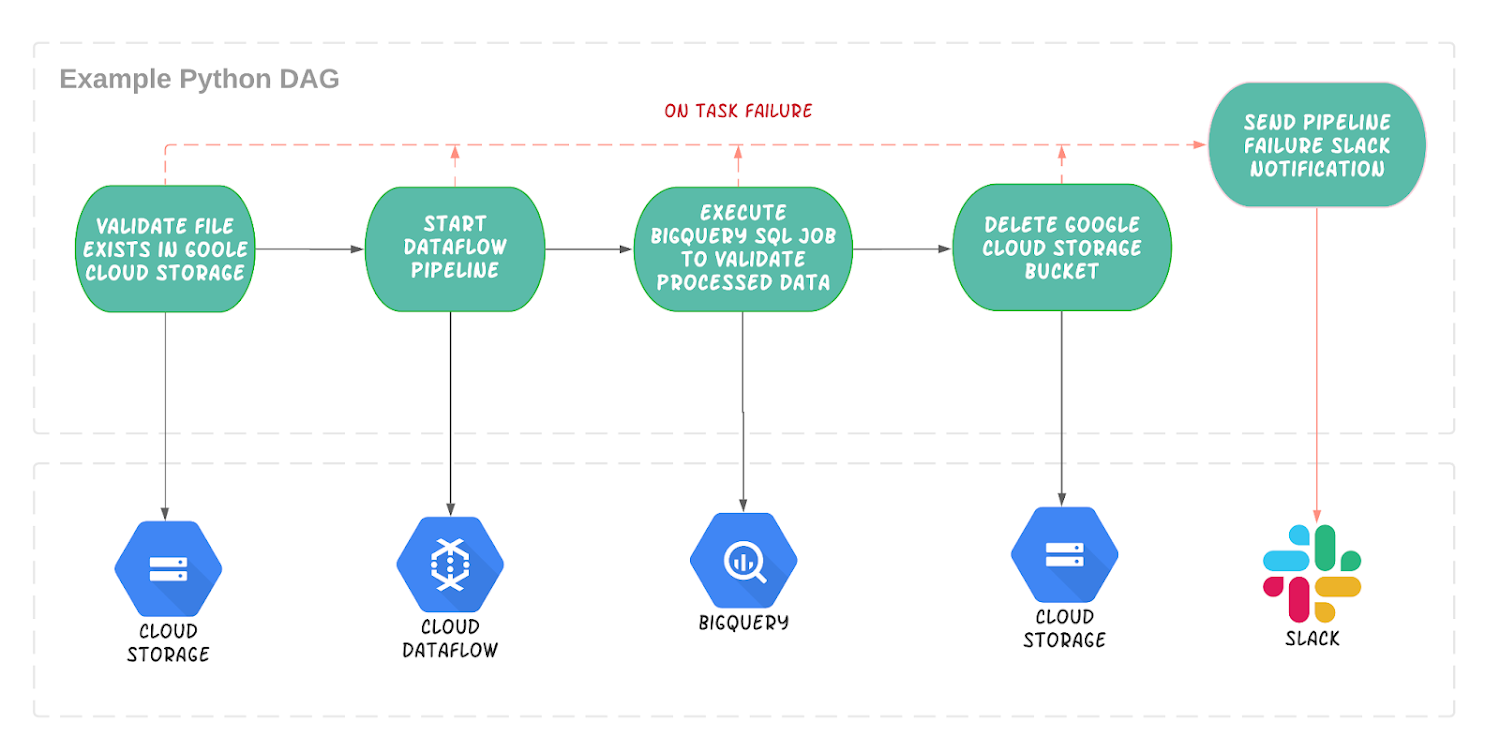
These tasks will execute one after the other and if any of the tasks fail an error notification will be posted on Slack, you can easily set up your Slack connection in the Airflow UI. As part of the DAG, you can define a schedule interval, in this case we simply wanted it to execute every day at midnight:
We can easily create these tasks using the Cloud Storage, BigQuery, Dataflow and Slack operators. Here is a snippet of the Cloud Storage sensor that simply checks for the existence of a file in a Google Cloud Storage bucket:
You can check out a code sample for this DAG here.
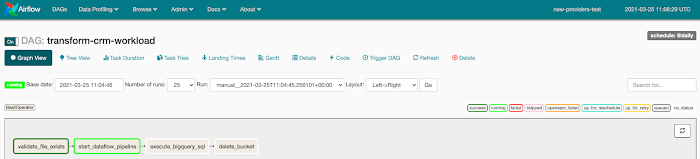
Once your DAG is complete, you just upload it to Google Cloud Storage so it can be executed from the Airflow UI. From here, it’s easy for your team to trigger, track and monitor the progress of your Composer workflow:
The ability to host your data on the cloud has encouraged data driven workloads to evolve and scale faster than ever. Data orchestration is becoming increasingly more important as engineers aspire to simplify and centralize the management of their tasks and services. By having Composer orchestrate these workflows and manage the underlying resources on their behalf, data engineers can focus their efforts on the more creative aspects of data engineering.
Want to learn more?
Register for our upcoming Open Source Live event focussed on Airflow or check out these tutorials and code samples to get started with Composer!